


Эта статья продолжает наш про миграцию RabbitMQ и посвящена MongoDB. Поскольку мы обслуживаем множество кластеров Kubernetes и MongoDB, пришли к естественной необходимости мигрировать данные из одной инсталляции в другую и делать это без простоя. Основные сценарии прежние: перенос MongoDB из виртуального/железного сервера в Kubernetes или же перенос MongoDB в рамках одного кластера Kubernetes (из одного пространства имён в другое).
Наш рецепт предназначен для случаев, когда функционирует старый кластер MongoDB (например, из 3 узлов и находящийся либо уже в K8s, либо на старых серверах), с которым работает приложение, размещённое в Kubernetes:
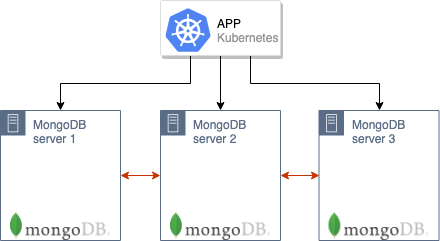
Как мы будем переводить такой кластер в новый production в Kubernetes?
Теория
Общий алгоритм миграции аналогичен описанному в ситуации с RabbitMQ.
Важно отметить, что для возможности переезда требуется, чтобы серверы с MongoDB и Kubernetes находились в одной сети. Узлы кластера MongoDB будут общаться между собой по IP старых серверов (где находятся старые инсталляции MongoDB) и по DNS-именам pod’ов с MongoDB в K8s. Поэтому на железных серверах (со старыми инсталляциями) потребуется пробросить маршруты до pod’ов, а затем настроить их на использование DNS-сервера, работающего в Kubernetes (или же прописать нужные имена в /etc/hosts, хотя в общем случае такой возможности лучше избегать).
Следующий шаг — поднять кластер MongoDB в pod’ах Kubernetes. В нашем случае кластер БД состоит из 3 узлов и каждый узел располагается в отдельном pod’е K8s — впрочем, их число может быть и другим. В ConfigMap’е надо указать адрес мастера MongoDB из старой инсталляции: тогда узлы MongoDB, находящиеся в pod’ах в K8s, сразу начнут синхронизацию с ним.
После того, как все pod’ы поднимутся, образуется кластер MongoDB из 6 узлов:
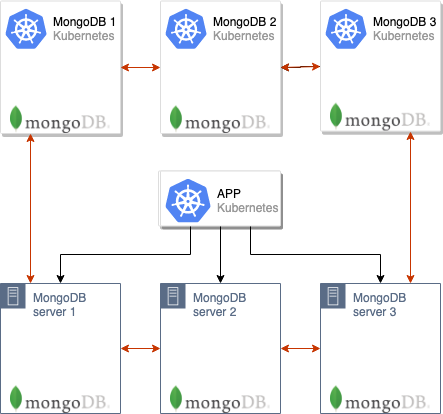
Обратите внимание, что pod’ы будут долго подниматься, поскольку каждый pod запускается по очереди, а в момент запуска синхронизирует данные с мастера.
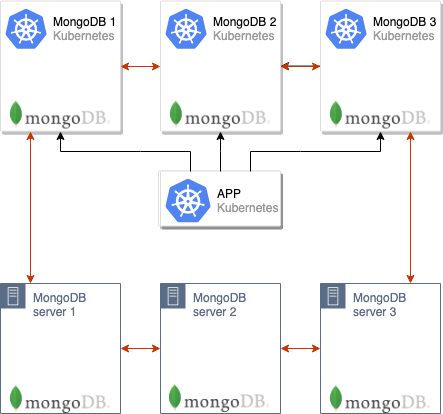
После этого можно переключить приложение на использование новых серверов MongoDB:
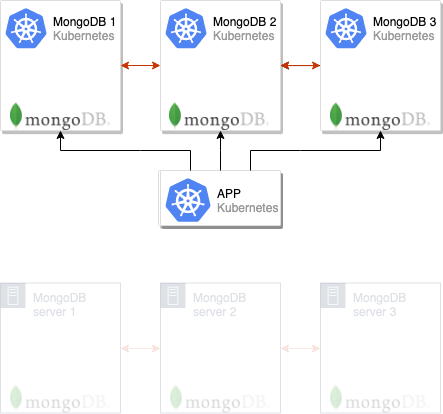
И останется лишь удалить старые узлы из кластера MongoDB, после чего переезд можно считать завершённым:
Такую схему мы часто применяем в production и для удобства её использования реализовали в рамках модуля к (эту утилиту мы ), что позволяет распространять типовые конфигурации MongoDB по многим кластерам. Публикацию своих модулей мы планируем провести в скором времени, а пока представляем отдельные инструкции, с которыми можно попробовать предлагаемое решение в действии и без использования addon-operator.
Пробуем на практике
Требования
Реквизиты:
- Кластер Kubernetes (подойдет и minikube);
- Кластер MongoDB (может быть и развернут на bare metal, и сделан как обычный кластер в Kubernetes из официального Helm-чарта).
В описанном ниже примере старый кластер с MongoDB будет назван mongo-old и установлен в том же кластере Kubernetes, где в дальнейшем мы установим и новый (mongo-new).
Готовим старый кластер
1. Для примера, демонстрирующего описанную схему в действии, создадим «старый» (т.е. подлежащий миграции) кластер MongoDB прямо в Kubernetes (в реальности он может находиться и на отдельных серверах вне K8s). Для этого скачаем Helm-чарт:
helm fetch --untar stable/mongodb-replicaset… и немного отредактируем его, настроив авторизацию:
auth:
enabled: true
adminUser: mongo
adminPassword: pa33w0rd
# metricsUser: metrics
# metricsPassword: password
# key: keycontent
# existingKeySecret:
# existingAdminSecret:
# exisitingMetricsSecret: Также в values.yaml можно настроить сертификаты и многое другое.
2. Установим чарт:
helm install . --name mongo-old --namespace mongo-oldПосле этого будет запущена тестовая «старая» инсталляция MongoDB:
kubectl --namespace=mongo-old get pods 
Зайдем в pod с её мастером и создадим тестовую базу:
kubectl --namespace=mongo-old exec -ti mongo-old-mongodb-replicaset-0 mongo
use admin
db.auth('mongo','password')
use music
db.artists.insert({ artistname: "The Tea Party" })
show dbs 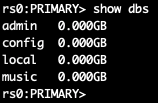
Заходя в разные pod’ы, я выяснил, что мастером является mongo-old-mongodb-replicaset-0. Впрочем, для более удобного решения этого вопроса после установки Helm-чарта выводится команда, как определить MASTER_POD. В моем случае (для mongo-old из 3 узлов) она выглядит вот так:
for ((i = 0; i < 3; ++i)); do kubectl exec --namespace mongo-old mongo-old-mongodb-replicaset-$i -- sh -c 'mongo --eval="printjson(rs.isMaster())"'; doneНа этом подготовка старой инсталляции MongoDB, данные которой будут переноситься, готова.
Миграция кластера MongoDB
Теперь развернём новую инсталляцию MongoDB, которая будет находиться в Kubernetes и использоваться приложением в production.
NB: Обращаю внимание, что должна использоваться такая же версия MongoDB, что и раньше. В ином случае есть риск получить проблемы совместимости.
По аналогии с предыдущим разделом (где мы имитировали «старую» инсталляции MongoDB), возьмем уже упомянутый Helm-чарт (командой helm fetch) и настроим авторизацию, а также другие параметры, если они используются. Кроме того, исправим файл init/on-start.sh, временно добавив в него на 165 строке адрес мастера, полученный на предыдущем этапе (или же известный вам по инсталляции MongoDB на отдельных серверах):
peers='mongo-old-mongodb-replicaset-0.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017'Мы готовы к созданию новой инсталляции MongoDB:
helm install . --name mongo-new --namespace mongo-newДожидаемся, пока стартуют все pod’ы (если данных много, то их запуск может длиться часами):

Теперь делаем exec в новый pod и смотрим список баз:
kubectl --namespace=mongo-new exec -ti mongo-new-mongodb-replicaset-0 mongo 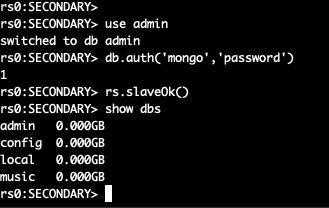
Два кластера MongoDB объединены в один, состоящий из 6 узлов.
На данный момент уже можно переключать приложение на новый кластер, но для завершения миграции осталось несколько шагов.
Из файла init/on-start.sh в новой инсталляции убираем добавленную нами строку:
peers='mongo-old-mongodb-replicaset-0.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017'Теперь зайдем в старый мастер кластера и «свергнем» его — тогда в кластере будет назначен новый мастер. Заходим в pod с мастером MongoDB:
kubectl --namespace=mongo-old exec -ti mongo-old-mongodb-replicaset-0 mongo
use admin
db.auth('mongo','password')После этого меняем приоритеты у узлов и меняем мастера:
cfg = rs.conf()
cfg.members[5].priority = 2
rs.reconfig(cfg)
rs.stepDown(120)Текущий узел перестал быть мастером — произойдут выборы нового. Поскольку мы поменяли приоритеты, мастером станет нужный нам узел.
NB: По умолчанию у всех узлов MongoDB приоритет равен 1. Выше мы поднимаем до 2 приоритет у нужного нам узла. Таким образом, общим мастером точно становится член нового кластера. Подробнее о том, как устроены эти механизмы в MongoDB, можно почитать в .
Отключим старую инсталляцию MongoDB, после чего зайдем в мастер новой и удалим старые узлы:
rs.remove("mongo-old-mongodb-replicaset-0.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017")
rs.remove("mongo-old-mongodb-replicaset-1.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017")
rs.remove("mongo-old-mongodb-replicaset-2.mongo-old-mongodb-replicaset.mongo-old.svc.cluster.local:27017")После этого миграцию можно считать законченной: мы успешно переключились со старого кластера MongoDB на новый!
Итоги
Описанная схема подходит практически для всех случаев, когда нужно перенести MongoDB или просто переехать в новый кластер.
Пожалуй, главный нюанс при переносе — это необходимость проброса IP-адресов новых pod’ов на серверы старой инсталляции MongoDB, если она находится вне K8s, и правильного их наименования в DNS (или /etc/hosts). В примере эти шаги не потребовались, поскольку миграция происходила между разными пространствами имён одного и того же Kubernetes-кластера.
P.S.
Читайте также в нашем блоге:
- «»;
- «»;
- «».
Источник: habr.com
