

26 февраля мы проводили митап Apache Ignite GreenSource, где выступали контрибьютеры open source проекта . Важным событием в жизни этого сообщества стала перестройка компонента , который позволяет развернуть пользовательские микросервисы прямо в кластере Ignite. Об этом непростом процессе на митапе рассказал , программный инженер и уже более двух лет контрибьютер Apache Ignite.
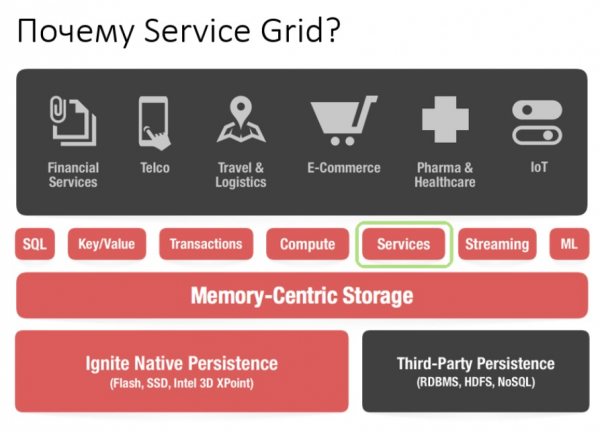
Начнем с того, что такое Apache Ignite вообще. Это база данных, которая представляет собой распределенное Key/Value хранилище с поддержкой SQL, транзакционности и кэширования. Кроме того, Ignite позволяет развернуть пользовательские сервисы прямо в кластере Ignite. Разработчику становятся доступны все инструменты, которые предоставляет Ignite — распределенные структуры данных, Messaging, Streaming, Compute и Data Grid. Например, при использовании Data Grid пропадает проблема с администрированием отдельной инфраструктуры под хранилище данных и, как следствие, вытекающие из этого накладные расходы.
Используя API Service Grid, можно задеплоить сервис, просто указав в конфигурации схему деплоя и, соответственно, сам сервис.
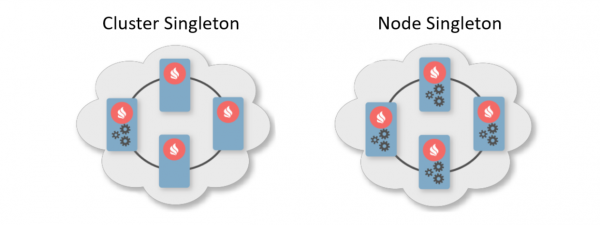
Обычно схема деплоя — это указание количества инстансов, которое должно быть развернуто на узлах кластера. Есть две типичные схемы деплоя. Первая — это Cluster Singleton: в любой момент времени в кластере гарантированно будет доступен один экземпляр пользовательского сервиса. Вторая — Node Singleton: на каждом узле кластера развернуто по одному экземпляру сервиса.
Также пользователь может указать количество инстансов сервиса во всем кластере и определить предикат для фильтрации подходящих узлов. При таком сценарии Service Grid сам рассчитает оптимальное распределение для развертывания сервисов.
Кроме того, существует такая фича как Affinity Service. Affinity — это функция, которая определяет связь ключей с партициями и связь партий с узлами в топологии. По ключу можно определить primary-узел, на котором хранятся данные. Таким образом можно ассоциировать ваш собственный сервис с ключом и кэшем affinity-функции. В случае изменения affinity-функции произойдет автоматический редеплой. Так сервис будет всегда размещен рядом с данными, которыми он должен манипулировать, и, соответственно, снизить накладные расходы на доступ к информации. Такую схему можно назвать своего рода коллоцированными вычислениями.
Теперь, когда мы разобрали, в чем прелесть Service Grid, расскажем о его истории развития.
Что было раньше
Прошлая реализация Service Grid базировалась на транзакционном реплицированном системном кэше Ignite. Под словом «кэш» в Ignite подразумевается хранилище. То есть это не что-то временное, как можно подумать. Несмотря на то, что кэш реплицируемый и каждая нода содержит весь набор данных, внутри кэш имеет партиционированное представление. Это связано с оптимизацией хранилищ.
Что происходило, когда пользователь хотел задеплоить сервис?
- Все узлы в кластере подписывались на обновление данных в хранилище с помощью встроенного механизма Continuous Query.
- Нода-инициатор под read-committed транзакцией делала в базу запись, которая содержала конфигурацию сервиса, включая сериализованный инстанс.
- При получении уведомления о новой записи координатор рассчитывал распределение исходя из конфигурации. Полученный объект записывался обратно в базу.
- Если узел входил в распределение, координатор должен был его задеплоить.
Что нас не устраивало
В какой-то момент мы пришли к выводу: так работать с сервисами нельзя. Причин было несколько.
Если во время деплоя происходила какая-то ошибка, то о ней можно было узнать только из логов того узла, где все произошло. Существовал только асинхронный деплой, так что после возвращения пользователю управления от метода деплоя нужно было некоторое дополнительное время для старта сервиса — и в это время пользователь ничем управлять не мог. Чтобы развивать Service Grid дальше, пилить новые фичи, привлекать новых пользователей и делать всем жизнь проще, нужно что-то менять.
При проектировании нового Service Grid мы в первую очередь хотели предоставить гарантию синхронного деплоя: как только пользователю вернулось управление от API, он сразу может пользоваться сервисами. Также хотелось дать инициатору возможность обрабатывать ошибки деплоя.
Кроме того, хотелось облегчить реализацию, а именно уйти от транзакций и ребалансировки. Несмотря на то, что кэш реплицируемый и балансировки нет, во время большого деплоймента с множеством нод возникали проблемы. При изменении топологии нодам необходимо обмениваться информацией, и при большом деплойменте эти данные могут весить очень много.
Когда топология была нестабильна, координатору требовалось пересчитывать распределение сервисов. Да и в целом, когда приходится работать с транзакциями на нестабильной топологии, это может привести к сложно-прогнозируемым ошибкам.
Проблемы
Какие же глобальные перемены без сопутствующих проблем? Первой из них стало изменение топологии. Нужно понимать, что в любой момент, даже в момент деплоя сервиса, узел может войти в кластер или выйти из него. Более того, если в момент деплоя узел войдет в кластер, потребуется консистентно передать всю информацию о сервисах в новый узел. И речь идет не только о том, что уже было развернуто, но и о текущих и будущих деплоях.
Это лишь одна из проблем, которые можно собрать в отдельный список:
- Как задеплоить статически сконфигурированные сервисы при старте узла?
- Выход узла из кластера – что делать если узел хостил сервисы?
- Что делать если сменился координатор?
- Что делать если клиент переподключился к кластеру?
- Надо ли обработать запросы активации / деактивации и как?
- А что, если вызвали дестрой кэша, а у нас завязаны на него аффинити-сервисы?
И это далеко не все.
Решение
В качестве целевого мы выбрали подход Event Driven с реализацией коммуникации процессов с помощью сообщений. В Ignite уже реализовано два компонента, которые позволяют узлам пересылать сообщения между собой, — communication-spi и discovery-spi.
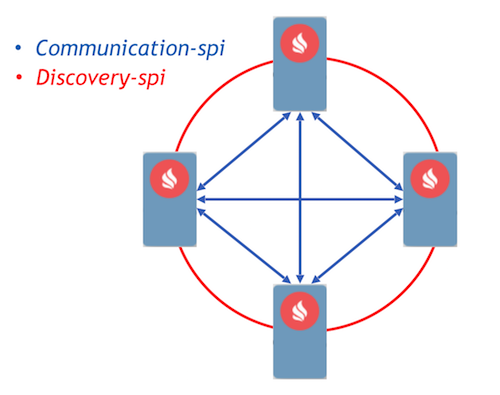
Communication-spi позволяет нодам напрямую общаться и пересылать сообщения. Он хорошо подходит для пересылки большого объема данных. Discovery-spi позволяет отправить сообщение всем узлам в кластере. В стандартной реализации это делается по топологии «кольцо». Также есть интеграция с Zookeeper, в этом случае используется топология «звезда». Еще стоит отметить важный момент: discovery-spi предоставляет гарантии того, что сообщение точно будет доставлено в правильном порядке всем узлам.
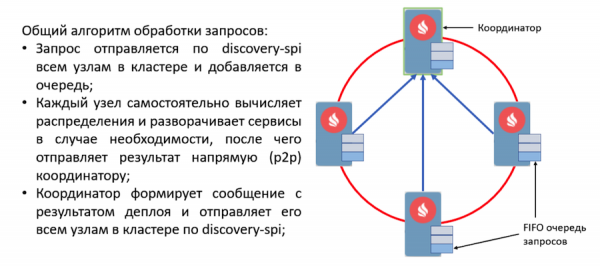
Рассмотрим протокол деплоя. Все пользовательские запросы на деплой и раздеплой посылаются по discovery-spi. Это дает следующие гарантии:
- Запрос будет получен всеми узлами в кластере. Это позволит продолжить обработку запроса при смене координатора. Также это значит, что за одно сообщение у каждого узла появятся все необходимые метаданные, такие как конфигурация сервиса и его сериализованный инстанс.
- Строгий порядок доставки сообщений позволяет разрешать конфликты конфигураций и конкурирующих запросов.
- Так как вход узла в топологию обрабатывается тоже по discovery-spi, на новый узел попадут все необходимые для работы с сервисами данные.
При получении запроса узлы в кластере валидируют его и формируют задачи на обработку. Эти задачи складываются в очередь и затем обрабатываются в другом потоке отдельным воркером. Это реализовано таким образом, потому что деплой может занимать значительное время и задерживать дорогой discovery-поток недопустимо.
Все запросы из очереди обрабатываются деплоймент-менеджером. У него есть специальный воркер, который вытаскивает задачу из этой очереди и инициализирует ее, чтобы начать развертывание. После этого происходят следующие действия:
- Каждый узел самостоятельно рассчитывает распределение благодаря новой детерминированной assignment-функции.
- Узлы формируют сообщение с результатами деплоя и отправляют его координатору.
- Координатор агрегирует все сообщения и формирует результат всего процесса деплоя, который отправляется по discovery-spi всем узлам в кластере.
- При получении результата процесс деплоя завершается, после чего задача удаляется из очереди.
Новый event-driven дизайн: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Если в момент развертывания произошла ошибка, узел сразу же включает эту ошибку в сообщение, которое направляет координатору. После агрегации сообщений координатор будет иметь информацию обо всех ошибках во время деплоя и отправит это сообщение по discovery-spi. Информация об ошибках будет доступна на любом узле в кластере.
По этому алгоритму работы обрабатываются все важные события в Service Grid. Например, смена топологии — это тоже сообщение по discovery-spi. И в целом, если сравнивать с тем, что было, протокол получился достаточно легковесным и надежным. Настолько, чтобы обработать любую ситуацию во время деплоя.
Что будет дальше
Теперь о планах. Любая крупная доработка в проекте Ignite выполняется как инициатива на улучшение Ignite, так называемый IEP. У редизайна Service Grid тоже есть IEP — со стебным названием «Замена масла в Сервис Гриде». Но по факту мы поменяли не масло в двигателе, а двигатель целиком.
Задачи в IEP мы разделили на 2 фазы. Первая — крупная фаза, которая заключается в переделке протокола деплоя. Она уже влита в мастер, можно попробовать новый Service Grid, который появится в версии 2.8. Вторая фаза включает в себя множество других задач:
- Горячий редеплой
- Версионирование сервисов
- Повышение отказоустойчивости
- Тонкий клиент
- Инструменты мониторинга и подсчета различных метрик
Напоследок можем посоветовать вам Service Grid для построения отказоустойчивых систем высокой доступности. А также приглашаем к нам в и поделиться своим опытом. Ваш опыт реально важен для сообщества, он поможет понять, куда двигаться дальше, как в будущем развивать компонент.
Источник: habr.com






