


Уверен, что заголовок вызвал здоровую реакцию — “ну опять началось…” Но позвольте завладеть вашим вниманием на 5-10 минут, и я постараюсь не обмануть ожидания.
Структура статьи будет такова: берется стереотипное утверждение и раскрывается “природа” возникновения этого стереотипа. Надеюсь, это позволит взглянуть на выбор парадигмы обмена данными в ваших проектах под новым углом.
Для того, чтобы была ясность в том, что такое RPC, предлагаю рассматривать стандарт . C REST ясности нет. И не должно быть. Все, что нужно знать о REST — он неотличим от .
RPC запросы быстрее и эффективнее, потому, что позволяют делать batch-запросы.
Речь идет о том, что в RPC можно в одном запросе выполнить вызов сразу нескольких процедур. Например, создать пользователя, добавить ему аватар и в том же запросе подписать его на какие-то топики. Всего один запрос, а сколько пользы!
Действительно, если у вас будет всего одна нода backend, это будет казаться быстрее при batch-запросе. Потому, что три REST запроса потребуют в три раза больше ресурсов от одной ноды на установку соединений.
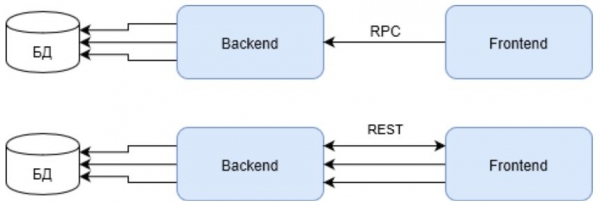
Обратите внимание, что первый запрос в случае с REST должен вернуть идентификатор пользователя, для выполнения последующих запросов. Что также негативно влияет на общий результат.
Но такие инфраструктуры можно встретить, разве что, в in-house решениях и Enterprise. В крайнем случае, в небольших WEB проектах. А вот полноценные WEB решения, да еще и именуемые HighLoad так строить не стоит. Их инфраструктура должна отвечать критериям высокой доступности и нагруженности. И картина меняется.
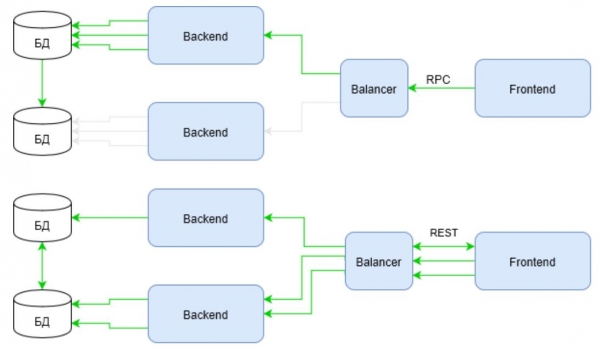
Зеленым отмечены каналы активности инфраструктуры при том же сценарии. Обратите внимание, как ведет себя RPC теперь. Запрос использует инфраструктуру только по одному плечу от балансировщика к backend. В то время, как REST все также проигрывает в первом запросе, но наверстывает упущенное используя всю инфраструктуру.
Достаточно в сценарий ввести не два запроса на обогащение, а, скажем, пять или десять… и ответ на вопрос “кто выигрывает теперь?” становится неочевиден.
Предлагаю глянуть еще шире на проблему. На схеме видно, как используются каналы инфраструктуры, но инфраструктура не ограничивается каналами. Важной составляющей высоконагруженной инфраструктуры являются кэши. Давайте теперь получим какой-то артефакт пользователя. Несколько раз. Скажем 32 раза.
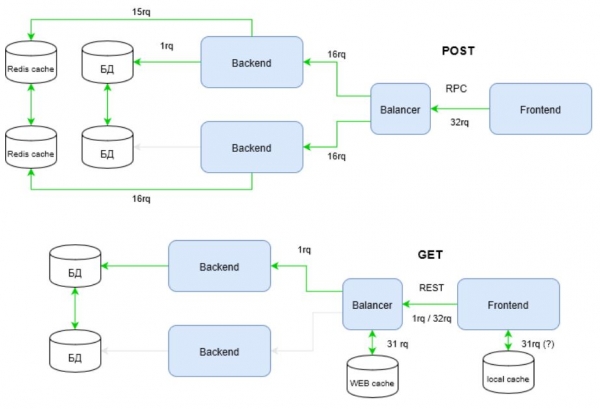
Посмотрите, как заметно “поправилась” инфраструктура на RPC для того, чтобы отвечать требованиям высокой нагрузки. Все дело в том, что REST использует всю мощь HTTP протокола в отличие от RPC. На приведенной схеме эта мощь реализуется через метод запроса — GET.
У HTTP методов, помимо прочего, есть стратегии кеширования. Познакомиться с ними можно в документации на . Для RPC используются POST запросы, которые не считаются идемпотентными, то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться очередная копия этого комментария) ().
Следовательно, RPC не в состоянии эффективно использовать инфраструктурные кэши. Это приводит к тому, что приходится “завозить” софтовые кэши. На схеме в этой роли представлен Redis. Софтовый кэш, в свою очередь, требует от разработчика дополнительный кодовый слой и заметные изменения в архитектуре.
Давайте теперь посчитаем, сколько же запросов “родил” REST и RPC в рассматриваемой инфраструктуре?
Запросы
Входящие
к backend
к СУБД
к софт-кэшу (Redis)
ИТОГО
REST
1/32*
1
1
0
3 / 35
RPC
32
32
1
31
96
[*] в лучшем случае (если локальный кэш используется) 1 запрос (один!), в худшем 32 входящих запроса.
В сравнении с первой схемой разница разительная. Теперь становится очевидным выигрыш REST. Но предлагаю не останавливаться на достигнутом. Развитая инфраструктура включает в себя CDN. Часто он же решает вопрос противодействия DDoS и DoS атакам. Получим:
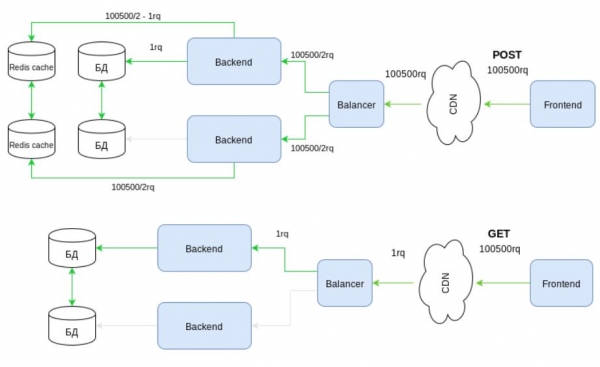
Тут для RPC все становится совсем плачевно. RPC просто не в состоянии делегировать работу с нагрузкой CDN. Остается надеяться только на системы противодействия атакам.
Можно ли на этом закончить? И опять, нет. Методы HTTP, как выше уже говорилось, имеют свою “магию”. И неспроста метод GET является тотально используемым в Internet. Обратите внимание на то, что этот метод способен обращаться к части контента, способен ставить условия, которые смогут интерпретировать инфраструктурные элементы еще до передачи управления вашему коду и т.д. Все это позволяет создавать гибкие, управляемые инфраструктуры, способные переваривать действительно большие потоки запросов. А в RPC этот метод… игнорируется.
Так почему так устойчив миф о том, что batch запросы (RPC) быстрее? Лично мне кажется, что большинство проектов просто не достигают такого уровня развития, когда REST способен показать свою силу. Более того, в небольших проектах, он охотнее показывает свою слабость.
Выбор REST или RPC это не волевой выбор отдельного человека в проекте. Этот выбор должен отвечать требованиям проекта. Если проект способен выжать из REST все то, что он действительно может, и это действительно нужно, то REST будет отличным выбором.
Но если на то, чтобы получить все профиты REST, нужно будет нанять в проект девопсов, для оперативного масштабирования инфраструктуры, админов для управления инфраструктурой, архитектора для проектирования всех слоев WEB сервиса… а проект, при этом, продает три пачки маргарина в день… я бы остановился на RPC, т.к. этот протокол более утилитарный. Он не потребует глубоких знаний работы кэшей и инфраструктуры, а сфокусирует разработчика на простых и понятных вызовах нужных ему процедур. Бизнес будет доволен.
RPC запросы надежнее, потому, что могут выполнять batch-запросы в рамках одной транзакции
Это свойство RPC является несомненным плюсом, т.к. легко удерживать БД в консистентном состоянии. А вот с REST выходит все сложнее. Запросы могут приходить непоследовательно на разные ноды backend.
Этот “недостаток” REST является обратной стороной его преимущества описанного выше — способность эффективно использовать все ресурсы инфраструктуры. Если инфраструктура спроектирована плохо, а тем более, если спроектирована плохо архитектура проекта и БД в частности, то это действительно большая боль.
Но так ли надежны batch-запросы как кажутся? Давайте рассмотрим кейс: создаем пользователя, обогащаем его профиль каким-то описанием и отсылаем ему SMS с секретом для завершения регистрации. Т.е. три вызова в одном batch-запросе.
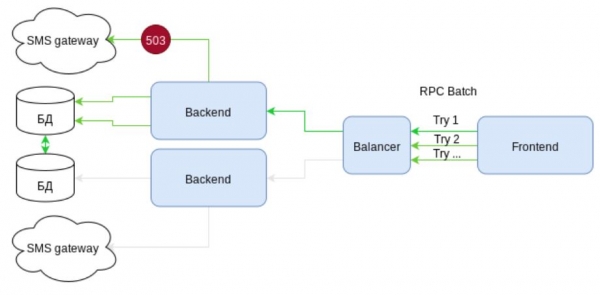
Рассмотрим схему. На ней представлена инфраструктура с элементами высокой доступности. Есть два независимых канала связи с SMS шлюзами. Но… что мы видим? При отправке SMS возникает ошибка 503 — сервис временно недоступен. Т.к. отправка SMS упакована в batch-запрос, то весь запрос должен откатиться. Действия в СУБД аннулируются. Клиент получает ошибку.
Следующая попытка — лотерея. Либо запрос опять попадет на ту же ноду и опять вернет ошибку, либо повезет, и он выполнится. Но главное, что как минимум один раз наша инфраструктура уже потрудилась зря. Нагрузка была, а профита нет.
Хорошо, давайте представим, что мы напряглись (!) и продумали вариант, когда запрос может успешно выполниться частично. А остаток, мы вновь попытаемся выполнить через какой-то интервал времени (Какой? Решает фронт?). Но лотерея так и осталась. Запрос на отправку SMS с вероятностью 50/50 вновь провалится.
Согласитесь, со стороны клиента, сервис не кажется таким надежным как хотелось бы… а что REST?
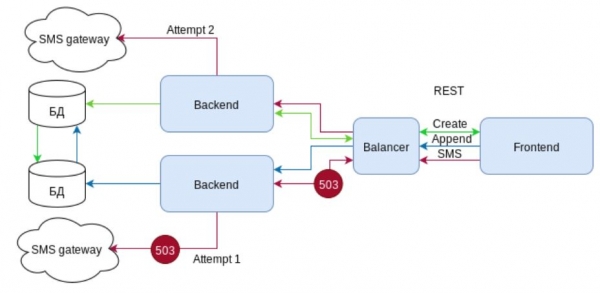
REST опять использует “магию” HTTP, но теперь с кодами ответов. При возникновении ошибки 503 на SMS шлюзе, backend транслирует эту ошибку балансировщику. Балансировщик получая эту ошибку, и не разрывая соединение с клиентом направляет запрос на другую ноду, которая успешно отрабатывает запрос. Т.е. клиент получает ожидаемый результат, а инфраструктура подтверждает свое высокое звание “восокодоступной”. Пользователь счастлив.
И опять это не все. Балансировщик не просто получил код ответа 503. Этот код при ответе, по стандарту, желательно снабдить заголовком “Retry-After». Заголовок дает понять балансировщику, что не стоит беспокоить эту ноду по этому роуту в течении заданного времени. И следующие запросы на отправку SMS будут направляться сразу на ноду, у которой нет проблем с SMS шлюзом.
Как мы видим, надежность JSON-RPC переоценена. Действительно, легче организовать консистентность в БД. Но жертвой, в таком случае, станет надежность системы в целом.
Вывод во многом аналогичен предыдущему. Когда инфраструктура проста, очевидность JSON-RPC несомненно его плюс. Если проект предполагает высокую доступность с высокой нагруженностью, REST смотрится более верным, хотя и более сложным решением.
Порог входа в REST ниже
Я думаю, что выше проведенный анализ, развенчивающий устоявшиеся стереотипы о RPC наглядно показал, что порог входа в REST несомненно выше, чем в RPC. Связанно это с необходимостью глубокого понимания работы HTTP, а также, с необходимостью обладать достаточными знаниями о существующих инфраструктурных элементах, которые можно и нужно применять в WEB проектах.
Так почему многие думают, что REST попроще будет? Лично мое мнение заключается в том, что эта кажущаяся простота исходит из самих манифестов REST. Т.е. REST это не протокол, а концепция… у REST нет стандарта, есть некоторые рекомендации… REST не сложнее HTTP. Кажущаяся свобода и анархия манит “свободных художников”.
Несомненно, REST не сложнее HTTP. Но сам HTTP это хорошо продуманный протокол, который доказал свою состоятельность десятилетиями. Если нет глубокого понимания самого HTTP, то и о REST судить нельзя.
А вот о RPC — можно. Достаточно взять его спецификацию. Так нужен ли вам ? Или все же хитрый REST? Решать вам.
Искренне надеюсь, что я не потратил ваше время зря.
Источник: habr.com
