

О методике мы рассказывали в статьи, в этой мы тестируем HTTPS, но в более реалистичных сценариях. Для тестирования был получен сертификат Let’s Encrypt, включено сжатие Brotli на 11.
На этот раз попробуем воспроизвести сценарий развертывания сервера на VDS или в качестве виртуальной машины на хосте с типовым процессором. Для этого устанавливали лимит в:
- 25% — Что в пересчете на частоту ~ 1350МГц
- 35% -1890Мгц
- 41% — 2214Мгц
- 65% — 3510Мгц
Количество единовременных подключений сократилось с 500 до 1, 3, 5, 7 и 9,
Результаты:
Задержки:
TTFB специально был вынесен качестве отдельного теста, потому что HTTPD Tools для каждого отдельного запроса создаёт как-бы нового пользователя. Этот тест все еще достаточно оторван от реальности, потому что пару страниц пользователь все равно кликнет, и в реальности главную роль сыграет TTFP.
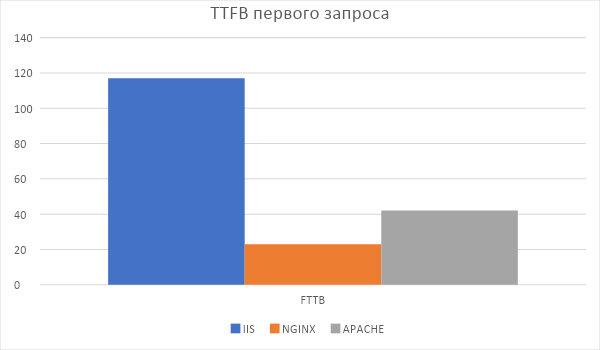
Первый, вообще самый первый запрос после первого старта виртуальной машины IIS отрабатывает в среднем за 120 мс.
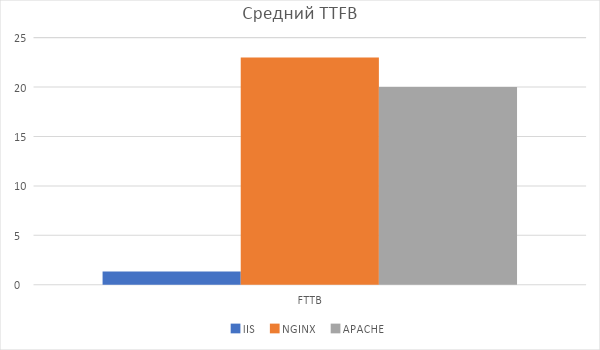
Все последующие запросы показывают TTFP в 1.5 мс. Apache и Nginx в этом отстают. Лично автор считает этот тест самым показательным и выбирал бы победителя только по нему.
Результат не является удивительным, так как IIS кэширует уже сжатый статический контент и не пережимает его каждый раз, как к нему обратились.
Время потраченное на одного клиента
Для оценки производительности достаточно и теста с 1 единовременным подключением.
К примеру, IIS завершил тестирование длинной в 5000 пользователей за 40 секунд, это 123 запроса в секунду.
В графиках ниже приведено время до полной передачи контента сайта. Это доля запросов, выполненных в определенное время. В нашем случае 80% всех запросов было обработано за 8мс на IIS и за 4.5мс на Apache и Nginx, а интервал до 8 миллисекунд выполнились 98% всех запросов на Apache и Nginx.
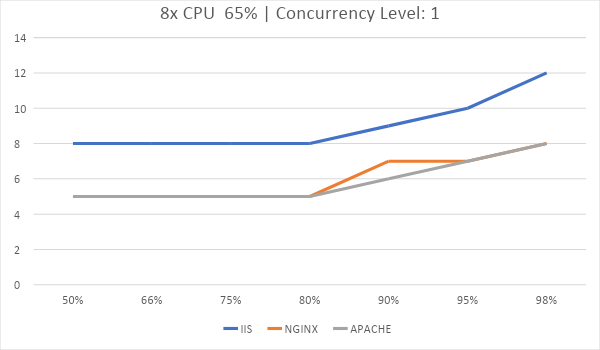
Время, за которое 5000 запросов были обработаны:
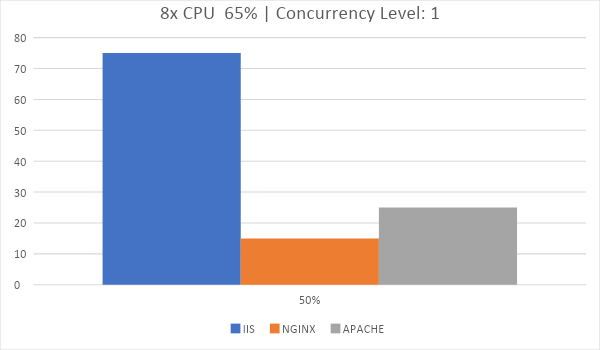
Время, за которое 5000 запросов были обработаны:
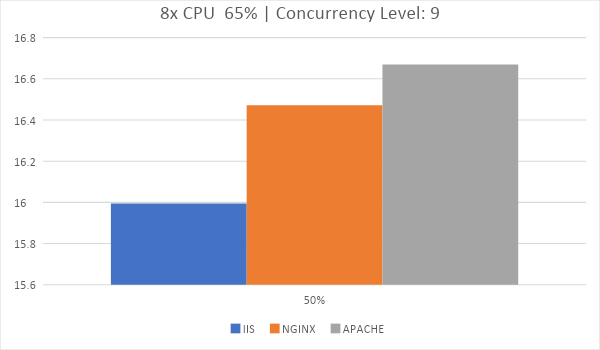
Если у вас есть виртуальная машина с 3.5Ггц ЦП и 8 ядрами, то выбирайте то, что хотите. Все веб серверы очень похожи в данном тестировании. О том, какой веб сервер выбрать для каждого хоста поговорим ниже.
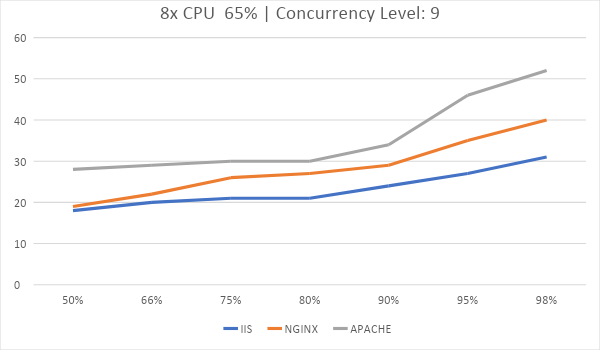
Когда речь идет чуть более реальной ситуации, все веб серверы идут нос к носу.
Throughput:
График задержек от количества одновременных подключений. Ровнее и ниже – лучше. Последние 2% были выкинуты из графиков потому, что они сделают их нечитаемыми.
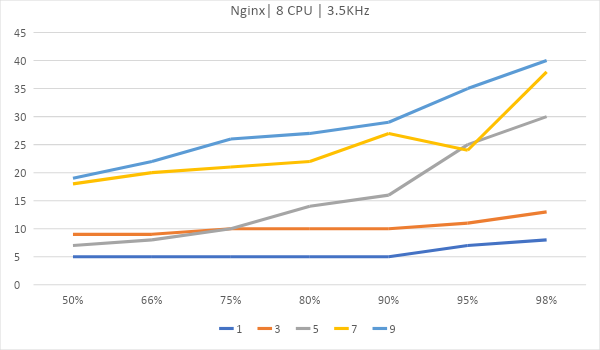
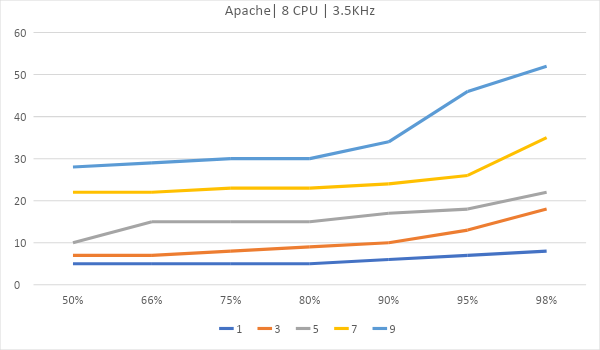
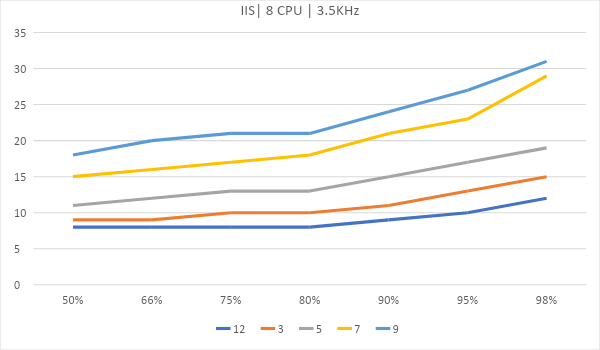
Теперь рассмотрим вариант, где сервер размещается на виртуальном хостинге. Возьмем 4 ядра по 2.2ГГц и одно ядро на 1.8Ггц.
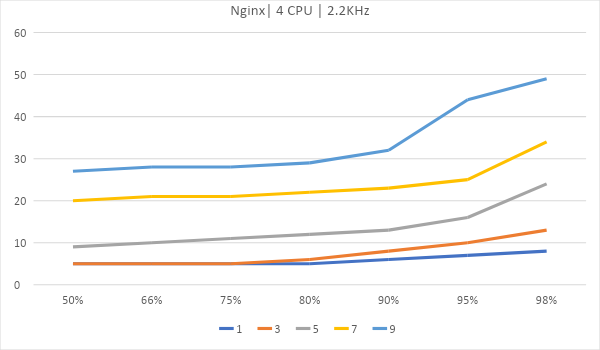
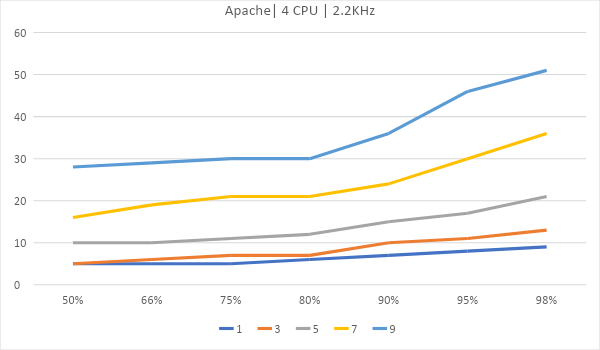
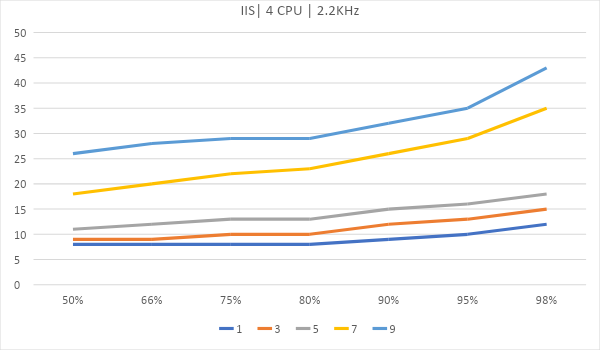
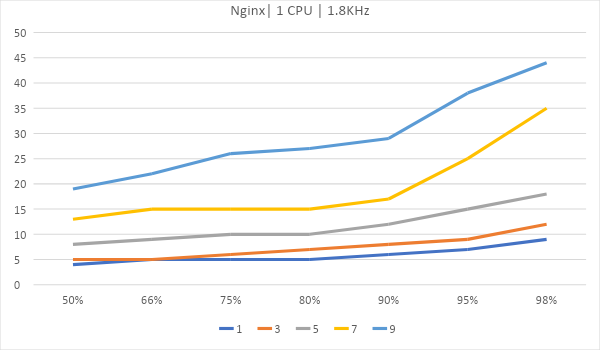
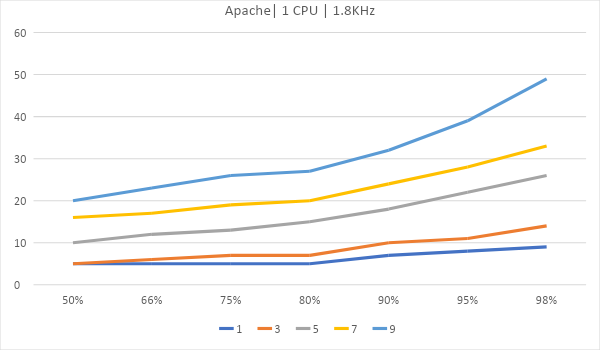
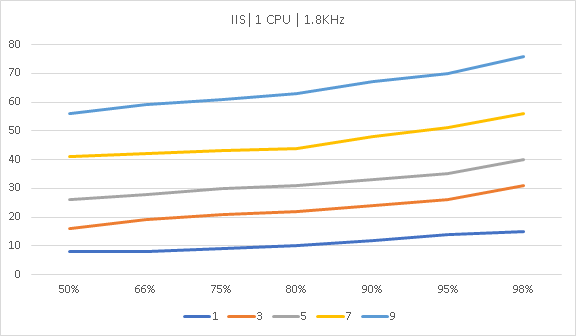
Как масштабируются
Если вы когда-либо видали, как выглядят ВАХ электровакуумных триодов, пентодов и так далее, эти графики будут для вас знакомы. Именно это мы и пытаемся поймать – насыщение. Предел, когда сколько ядер не кидай, рост производительности не будет заметен.
Ранее весь челленж состоял в том, чтобы обработать 98% запросов имея наименьшую задержку по всем запросам, как можно ровнее держать кривую. Теперь с помощью построения другой кривой, найдем оптимальную рабочую точку для каждого из серверов.
Для этого возьмем показатель Requests per second (RPR). По горизонтали частота, по вертикали — количество запросов, обработанных за секунду, линии – количество ядер.
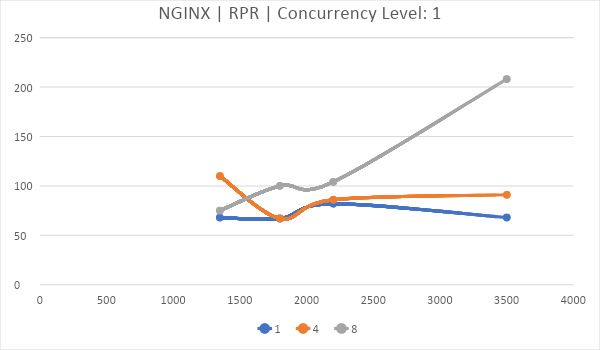
Показана корреляция насколько хорошо Nginx обрабатывает запросы один за другим. 8 ядер в таком тестировании показывают себя лучше.
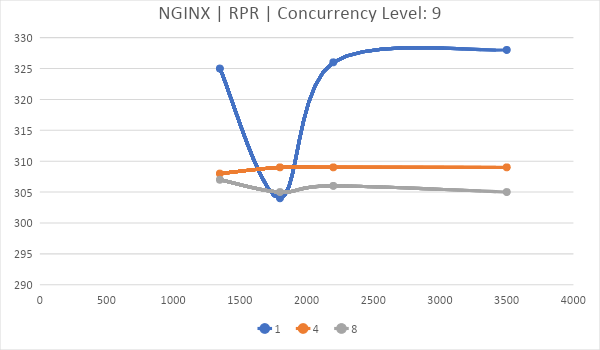
На этом графике прекрасно видно, насколько лучше (не на много) Nginx работает на одном ядре. Если у вас Nginx, стоит задуматься об уменьшении количества ядер до одного, если вы хостите только статику.
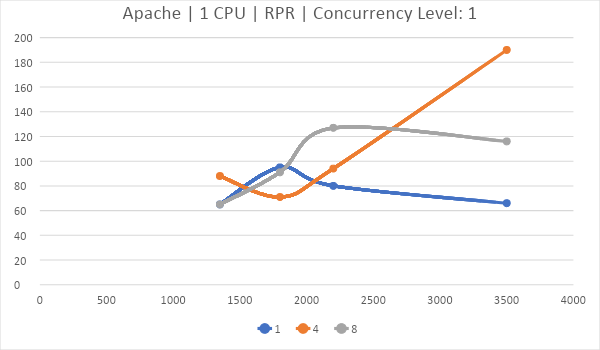
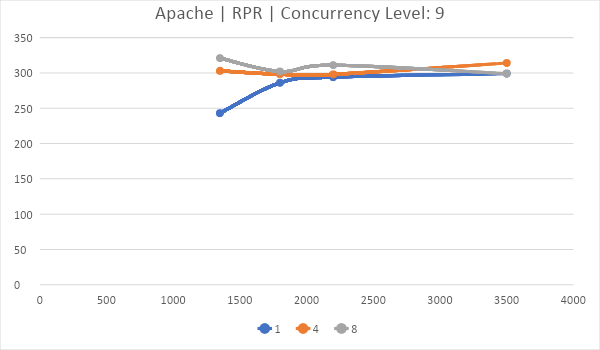
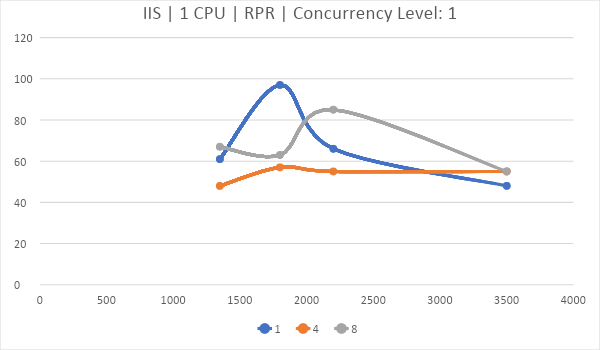
IIS хоть и имеет самый низкий TTFB по мнению DevTools в Chrome, умудряется проиграть и Nginx и Apache в серьезной борьбе со стресс тестом от Apache Foundation.
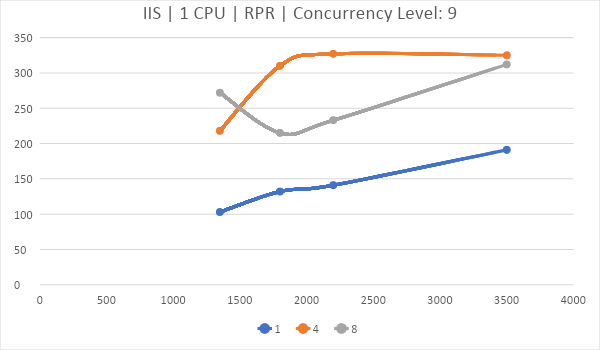
Вся кривизна графиков воспроизводится железно.
Своего рода вывод:
Да, Apache железно работает хуже на 1 и 8 ядрах, а на 4 работает чуть лучше.
Да, Nginx на 8 ядрах обрабатывает лучше запросы один за другим, на 1 и 4 ядрах и хуже работает, когда соединений много.
Да, IIS предпочитает 4 ядра для многопоточной нагрузки и предпочитает 8 ядер для однопоточной. В конечном итоге IIS оказался чуть быстрее всех на 8 ядрах под высокой нагрузкой, хотя все серверы шли вровень.
Это не ошибка измерения, погрешность тут не более +-1мс. в задержках и не более +- 2-3 запроса в секунду для RPR.
Результаты, когда 8 ядер проявляют себя хуже, вовсе не удивительны, много ядер и SMT/Hyperthreading сильно ухудшают производительность, если у нас есть временные рамки, за которые мы должны завершить весь пайплайн.
Источник: habr.com
