

В данной статье я расскажу о ситуации, которая недавно произошла с одним из серверов нашего облака VPS, поставив меня в тупик на несколько часов. Я около 15 лет занимаюсь конфигурированием и траблшутингом серверов Linux, но данный случай совершенно не укладывается в мою практику — я сделал несколько ложных предположений и слегка отчаялся до того, как смог правильно определить причину проблемы и решить ее.
Преамбула
Мы эксплуатируем облако средних размеров, которое строим на типовых серверах следующего конфига — 32 ядра, 256 GB RAM и NVMe накопитель PCI-E Intel P4500 размером 4TB. Нам очень нравится эта конфигурация, поскольку она позволяет не думать о недостатке IO, обеспечив корректное ограничение на уровне типов инстансов (экземпляров) VM. Поскольку NVMe Intel обладает впечатляющей производительностью, мы можем одновременно обеспечить как полное предоставление IOPS машинам, так и резервное копирование хранилища на сервер резервных копий с нулевым IOWAIT.
Мы относимся к тем самым староверам, которые не используют гиперконвергентные SDN и прочие стильные, модные, молодежные штуки для хранения томов VM, считая, что чем проще система, тем проще ее траблшутить в условиях "главный гуру уехал в горы". В итоге, мы храним тома VM в формате QCOW2 в XFS или EXT4, которая развернута поверх LVM2.
Использовать QCOW2 нас вынуждает еще и продукт, который мы используем для оркестрации — Apache CloudStack.
Для выполнения резервного копирования мы снимаем полный образ тома, как снимок LVM2 (да, мы знаем, что снимки LVM2 тормозные, но Intel P4500 нас выручает и здесь). Мы делаем lvmcreate -s .. и с помощью dd отправляем резервную копию на удаленный сервер с хранилищем ZFS. Здесь мы все же слегка прогрессивные — все же ZFS умеет хранить данные в сжатом виде, а мы можем их быстро восстанавливать с помощью DD или доставать отдельные тома VM с помощью mount -o loop ....
Можно, конечно, снимать и не полный образ тома LVM2, а монтировать файловую систему в режиме
ROи копировать сами образы QCOW2, однако, мы сталкивались с тем, что XFS от этого становилось плохо, причем не сразу, а непрогнозируемо. Мы очень не любим, когда хосты-гипервизоры "залипают" внезапно в выходные, ночью или праздники из-за ошибок, которые непонятно когда произойдут. Поэтому для XFS мы не используем монтирование снимков в режимеROдля извлечения томов, а просто копируем весь том LVM2.
Скорость резервного копирования на сервер резервных копий определяется в нашем случае производительностью сервера бэкапа, которая составляет около 600-800 MB/s для несжимаемых данных, дальнейший ограничитель — канал 10Gbit/s, которым подключен сервер резервных копий к кластеру.
При этом на один сервер резервных копий одновременно заливают резервные копии 8 серверов гипервизоров. Таким образом, дисковая и сетевая подсистемы сервера резервных копий, являясь более медленными, не дают перегрузить дисковые подсистемы хостов-гипервизоров, поскольку просто не в состоянии обработать, скажем, 8 GB/сек, которые непринужденно могут выдать хосты-гипервизоры.
Вышеописанный процесс копирования очень важен для дальнейшего повествования, включая и детали — использование быстрого накопителя Intel P4500, использование NFS и, вероятно, использование ZFS.
История о резервном копировании
На каждом узле-гипервизоре у нас есть небольшой раздел SWAP размером 8 GB, а сам узел-гипервизор мы "раскатываем" с помощью DD из эталонного образа. Для системного тома на серверах мы используем 2xSATA SSD RAID1 или 2xSAS HDD RAID1 на аппаратном контроллере LSI или HP. В общем, нам совершенно без разницы, что там внутри, поскольку системный том у нас работает в режиме "почти readonly", кроме SWAP-а. А поскольку у нас очень много RAM на сервере и она на 30-40% свободна, то мы про SWAP не думаем.
Процесс создания резервной копии. Выглядит эта задача примерно так:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapОбратите внимание на ionice -c3, по факту эта штука для NVMe устройств совершенно бесполезна, поскольку планировщик IO для них установлен как:
cat /sys/block/nvme0n1/queue/scheduler
[none] Однако, у нас есть ряд legacy-узлов с обычными SSD RAID-ами, для них это актуально, вот и переезжает AS IS. В общем, это просто интересный кусочек кода, который объясняет тщетность ionice в случае такой конфигурации.
Обратите внимание на флаг iflag=direct для DD. Мы используем direct IO мимо буферного кэша, чтобы не делать лишних замещений буферов IO при чтении. Однако, oflag=direct мы не делаем, поскольку мы встречали проблемы с производительностью ZFS при его использовании.
Эта схема используется нами успешно в течение нескольких лет без проблем.
И тут началось… Мы обнаружили, что для одного из узлов перестало выполняться резервное копирование, а предыдущее выполнилось с чудовищным IOWAIT под 50%. При попытке понять почему не происходит копирование мы столкнулись с феноменом:
Volume group "images" not foundНачали думать про "конец пришел Intel P4500", однако, перед тем как выключить сервер для замены накопителя, было необходимо все же выполнить резервное копирование. Починили LVM2 с помощью восстановления метаданных из бэкапа LVM2:
vgcfgrestore imagesЗапустили резервное копирование и увидели вот такую картину маслом:
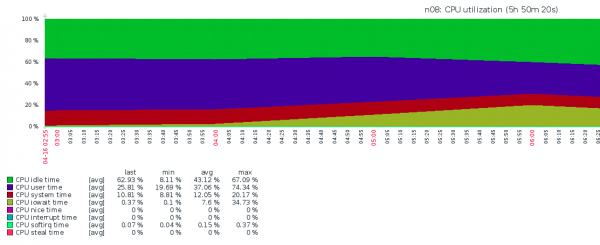
Опять очень сильно загрустили — было понятно, что так жить нельзя, поскольку все VPS-ки будут страдать, а значит будем страдать и мы. Что происходило, совершенно непонятно — iostat показывал жалкие IOPS-ы и высочайший IOWAIT. Идей, кроме как "давайте заменим NVMe" не было, но вовремя произошло озарение.
Разбор ситуации по шагам
Исторический журнал. Несколько дней ранее на данном сервере потребовалось создать большую VPS-ку со 128 GB RAM. Памяти вроде как хватало, но для подстраховки выделили еще 32 GB для раздела подкачки. VPS была создана, успешно решила свою задачу и инцидент забыт, а SWAP-раздел остался.
Особенности конфигурации. Для всех серверов облака параметр vm.swappiness был установлен в значение по-умолчанию 60. А SWAP был создан на SAS HDD RAID1.
Что происходило (по мнению редакции). При резервном копировании DD выдавал много данных для записи, которые помещались в буферы RAM перед записью в NFS. Ядро системы, руководствуясь политикой swappiness, перемещало много страниц памяти VPS в область подкачки, которая находилась на медленном томе HDD RAID1. Это приводило к тому, что IOWAIT очень сильно рос, но не за счет IO NVMe, а за счет IO HDD RAID1.
Как проблема была решена. Был отключен раздел подкачки 32GB. Это заняло 16 часов, о том, как и почему так медленно отключается SWAP можно почитать отдельно. Были изменены параметры swappiness на значение равное 5 во всем облаке.
Как бы этого могло не случиться. Во-первых, если бы SWAP был на SSD RAID или NVMe устройстве, во-вторых, если бы не было NVMe-устройства, а было бы более медленное устройство, которое бы не выдавало такой объем данных — по иронии, проблема случилось от того, что NVMe слишком быстрый.
После этого все стало работать как и раньше — с нулевым IOWAIT.
Источник: habr.com
