

Эта история о том, как мы используем контейнеры в продуктовой среде, в особенности под Kubernetes. Статья посвящена сбору метрик и логов с контейнеров, а также билду образов.

Мы из финтех-компании Exness, которая занимается разработкой сервисов для онлайн-трейдинга и финтех-продуктов для B2B и В2С. В нашем R&D много разных команд, в отделе разработки 100 + сотрудников.
Мы представляем команду, которая отвечает за платформу для сбора и запуска кода нашими разработчиками. В частности, мы отвечаем за сбор, хранение и предоставление метрик, логов, и событий из приложений. В настоящее время мы оперируем примерно тремя тысячами Docker-контейнеров в продуктовой среде, поддерживаем наше big data-хранилище на 50 Тб и предоставляем архитектурные решения, которые строятся вокруг нашей инфраструктуры: Kubernetes, Rancher и различные публичные cloud-провайдеры.
Наша мотивация
Что горит? Никто не может ответить. Где очаг? Понять трудно. Когда загорелось? Выяснить можно, но не сразу.

Почему одни контейнеры стоят, а другие упали? Какой контейнер стал тому виной? Ведь снаружи контейнеры одинаковые, а внутри у каждого свой Neo.

Наши разработчики — грамотные ребята. Они делают хорошие сервисы, которые приносят компании прибыль. Но бывают факапы, когда контейнеры с приложениями идут вразброд. Один контейнер потребляет слишком много CPU, другой — сеть, третий — операции ввода-вывода, четвёртый вообще непонятно, что делает с сокетами. Всё это падает, и корабль тонет.
Агенты
Чтобы понять что происходит внутри, мы решили ставить агентов прямо в контейнеры.

Эти агенты — сдерживающие программы, которые поддерживают контейнеры в таком состоянии, чтобы они не сломали друг друга. Агенты стандартизированы, и это позволяет стандартизировать подход к обслуживанию контейнеров.
В нашем случае агенты должны предоставлять логи в стандартном формате, тегированные и с тротлингом. Также они должны предоставлять нам стандартизированные метрики, расширяемые с точки зрения бизнес-приложений.
Под агентами также подразумеваются утилиты для эксплуатации и обслуживания, умеющие работать в разных системах оркестрирования, поддерживающие разные images (Debian, Alpine, Centos и т. д.).
Наконец, агенты должны поддерживать простой CI/CD, включающий в себя Docker-файлы. Иначе корабль развалится, потому что контейнеры начнут поставляться по «кривым» рельсам.
Процесс сборки и устройство целевого image
Чтобы всё было стандартизировано и управляемо, необходимо придерживаться какого-то стандартного процесса сборки. Поэтому мы решили собирать контейнеры контейнерами — такая вот рекурсия.
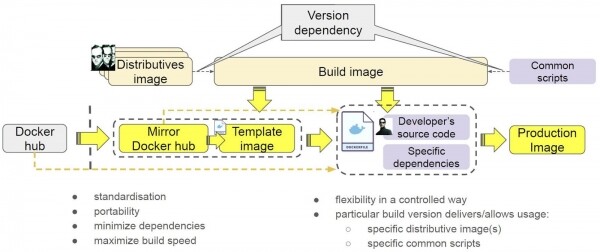
Здесь контейнеры представлены сплошными контурами. Заодно решили положить в них дистрибутивы, чтобы «жизнь малиной не казалась». Зачем это было сделано, мы расскажем ниже.
В результате получился инструмент для сборки — контейнер определенной версии, который ссылается на определенные версии дистрибутивов и определенные версии скриптов.
Как мы его применяем? У нас есть Docker Hub, в котором лежит контейнер. Мы зеркалируем его внутрь своей системы, чтобы избавиться от внешних зависимостей. Получился контейнер, помеченный жёлтым цветом. Мы создаём шаблон, чтобы установить в контейнер все необходимые нам дистрибутивы и скрипты. После этого мы собираем готовый к эксплуатации образ: разработчики кладут в него код и какие-то свои особые зависимости.
Чем хорош такой подход?
- Во-первых, полный версионный контроль инструментов сборки – контейнер сборки, версии скриптов и дистрибутивов.
- Во-вторых, мы добились стандартизации: одинаковым образом создаём шаблоны, промежуточные и готовые к эксплуатации image.
- В-третьих, контейнеры обеспечивают нам портируемость. Сегодня мы используем Gitlab, а завтра перейдём на TeamCity или Jenkins и точно так же сможем запускать наши контейнеры.
- В-четвёртых, минимизация зависимостей. Мы неслучайно положили в контейнер дистрибутивы, ведь это позволяет не скачивать их каждый раз из Интернета.
- В-пятых, повысилась скорость сборки – наличие локальных копий образов позволяют не тратить время на скачивание, так как есть локальный образ.
Иными словами, мы добились контролируемого и гибкого процесса сборки. Мы используем одинаковые средства для сборки любых контейнеров с полным версионированием.
Как работает наша процедура сборки
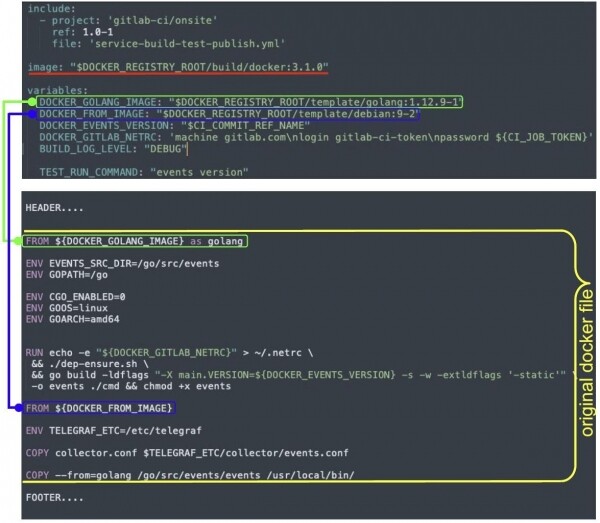
Сборка запускается одной командой, процесс выполняется в образе (выделен красным). У разработчика есть Docker-файл (выделен жёлтым), мы его рендерим, подменяя переменные значениями. И попутно добавляем header’ы и footer’ы — это наши агенты.
Header добавляет дистрибутивы из соответствующих образов. А footer устанавливает внутрь наши сервисы, настраивает запуск рабочей нагрузки, логирования и прочих агентов, подменяет entrypoint и т.д.
Мы долго думали, ставить ли супервизор. В конце концов, решили, что он нам нужен. Выбрали S6. Супервизор обеспечивает управление контейнером: позволяет подключаться к нему в случае падения основного процесса и обеспечивает ручное управление контейнером без его пересоздания. Логи и метрики — это процессы, исполняемые внутри контейнера. Их тоже надо как-то контролировать, и мы это делаем с помощью супервизора. Наконец, S6 берёт на себя выполнение housekeeping, обработку сигналов и прочие задачи.
Поскольку у нас применяются разные системы оркестрации, после сборки и запуска контейнер должен понять, в какой среде он находится, и действовать по ситуации. Например:
Это позволяет нам собрать один образ и запускать его в разных системах оркестрации, причем запускаться он будет с учетом специфики этой системы оркестрации.
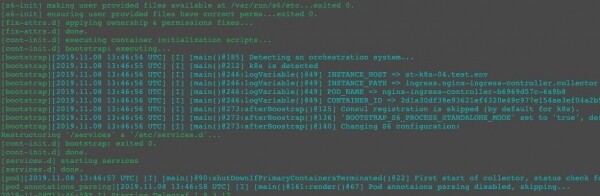
Для одного и того же контейнера мы получаем разные процессные деревья в Docker и Kubernetes:
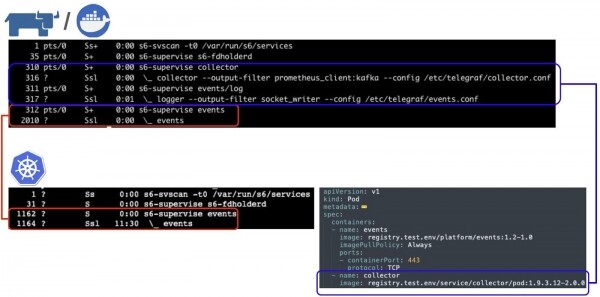
Полезная нагрузка исполняется под супервизором S6. Обратите внимание на collector и events — это наши агенты, отвечающие за логи и метрики. В Kubernetes их нет, а в Docker есть. Почему?
Если посмотреть спецификацию «пода» (здесь и далее – Kubernetes pod), то мы увидим, что контейнер events исполняется в поде, в котором есть отдельный контейнер collector, выполняющий функцию сбора метрик и логов. Мы можем использовать возможности Kubernetes: запуск контейнеров в одном поде, в едином процессном и/или сетевом пространствах. Фактически внедрять своих агентов и выполнять какие-то функции. И если этот же контейнер запустится в Docker, он получит на выходе все те же самые возможности, то есть сможет доставлять логи и метрики, так как агенты будут запущены внутри.
Метрики и логи
Доставка метрик и логов — сложная задача. С её решением связано несколько аспектов.
Инфраструктура создаётся для исполнения полезной нагрузки, а не массовой доставки логов. То есть этот процесс должен выполняться с минимальными требованиями к ресурсам контейнеров. Мы стремимся помочь нашим разработчикам: «Возьмите контейнер Docker Hub, запустите, и мы сможем доставить логи».
Второй аспект — ограничение объема логов. Если в нескольких контейнерах возникает ситуация всплеска объема логов (приложение в цикле выводит stack-trace), возрастает нагрузка на CPU, каналы связи, систему обработки логов, и это влияет на работу хоста в целом и другие контейнеры на хосте, то иногда это приводит к «падению» хоста.
Третий аспект — необходимо из коробки поддерживать как можно больше методик сбора метрик. От чтения файлов и опроса Prometheus-endpoint до использования специфических протоколов приложений.
И последний аспект — необходимо минимизировать потребление ресурсов.
Мы выбрали open-source решение на Go под названием Telegraf. Это универсальный коннектор, который поддерживает больше 140 видов входных каналов (input plugins) и 30 видов выходных (output plugins). Мы его доработали и сейчас мы расскажем, как он используется у нас на примере Kubernetes.
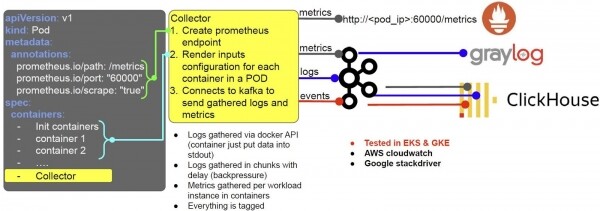
Допустим, разработчик развертывает нагрузку, и Kubernetes получает запрос на создание пода. В этот момент для каждого пода автоматически создается контейнер под названием Collector (мы используем mutation webhook). Collector — это наш агент. На старте, этот контейнер настраивает себя на работу c Prometheus и системой сбора логов.
- Для этого он использует аннотации пода, и в зависимости от её содержимого, создаёт, скажем, конечную точку end-point Prometheus;
- На основании спецификации пода и специфичных настроек контейнеров решает, как доставлять логи.
Логи мы собираем через Docker API: разработчикам достаточно положить их в stdout или stderr, а дальше Collector разберется. Логи собираются chunk’ами с некоторой задержкой, чтобы предотвратить возможную перегрузку хоста.
Метрики собираются по экземплярам рабочей нагрузки (процессам) в контейнерах. Всё помечается тегами: namespace, под и так далее, а затем конвертируется в формат Prometheus – и становится доступно для сбора (кроме логов). Также, логи, метрики и события мы отправляем в Kafka и далее:
- Логи доступны в Graylog (для визуального анализа);
- Логи, метрики, события отправляются в Clickhouse для долгосрочного хранения.
Точно так же всё работает в AWS, только мы заменяем Graylog с Kafka на Cloudwatch. Отправляем туда логи, и всё получается очень удобно: сразу понятно, к кому кластеру и контейнеру они относятся. То же самое верно и для Google Stackdriver. То есть наша схема работает как on-premise с Kafka, так и в облаке.
Если же у нас нет Kubernetes с подами, схема получается немного сложнее, но работает по тем же принципам.
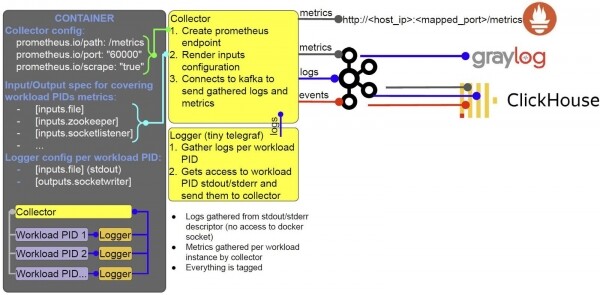
Внутри контейнера исполняются такие же процессы, они оркестрируются с помощью S6. Все те же самые процессы запущены внутри одного контейнера.
В итоге
Мы создали цельное решение для сборки и запуска образов в эксплуатацию, с опциями сбора и доставкой логов и метрик:
- Разработали стандартизированный подход к сборке образов, на его основе разработали CI-шаблоны;
- Агенты для сбора данных — это наши расширения Telegraf. Мы их хорошо обкатали в production;
- Применяем mutation webhook для внедрения контейнеров с агентами в подах;
- Интегрировались в экосистему Kubernetes/Rancher;
- Можем исполнять одинаковые контейнеры в разных системах оркестрации и получать ожидаемый нами результат;
- Создали полностью динамическую конфигурацию управления контейнерами.
Соавтор: Илья Прудников
Источник: habr.com
