

Hoe jy besigheidsvereistes in spesifieke datastrukture kan vertaal deur die voorbeeld van die ontwerp van 'n boodskapperdatabasis van nuuts af te gebruik.
- Deel 1: ontwerp van die basisraam

Ons basis sal nie so groot en verspreid wees nie, of , maar “sodat dit was”, maar dit was goed - funksioneel, vinnig en pas op een bediener PostgreSQL - sodat jy byvoorbeeld 'n aparte instansie van die diens iewers aan die kant kan ontplooi.
Daarom sal ons nie die kwessies van versplintering, replikasie en geo-verspreide stelsels aanraak nie, maar sal fokus op stroombaanoplossings binne die databasis.
Stap 1: Sommige besigheidsbesonderhede
Ons sal nie ons boodskappe abstrak ontwerp nie, maar sal dit in die omgewing integreer . Dit wil sê, ons mense korrespondeer nie “net nie”, maar kommunikeer met mekaar in die konteks van die oplossing van sekere besigheidsprobleme.
En wat is die take van 'n besigheid? .. Kom ons kyk na die voorbeeld van Vasily, die hoof van die ontwikkelingsafdeling.
- "Nikolai, vir hierdie taak het ons vandag 'n pleister nodig!"
Dit beteken dat korrespondensie in die konteks van sommige gevoer kan word die dokument. - "Kolya, gaan jy vanaand na Dota?"
Dit wil sê, selfs een paar gespreksgenote kan gelyktydig kommunikeer oor verskeie onderwerpe. - "Peter, Nikolay, kyk in die aanhangsel vir die pryslys vir die nuwe bediener."
So, een boodskap kan hê verskeie ontvangers. In hierdie geval kan die boodskap bevat Aangehegte lêers. - "Semyon, kyk ook."
En daar moet 'n geleentheid wees om bestaande korrespondensie aan te gaan nooi 'n nuwe lid.
Kom ons stilstaan by hierdie lys van “vanselfsprekende” behoeftes vir nou.
Sonder om die toegepaste besonderhede van die probleem en die beperkings wat daaraan gegee word te verstaan, ontwerp effektief databasisskema om dit op te los is byna onmoontlik.
Stap 2: Minimale logiese kring
Tot dusver werk alles baie soortgelyk aan e-poskorrespondensie - 'n tradisionele besigheidshulpmiddel. Ja, "algoritmies" is baie besigheidsprobleme soortgelyk aan mekaar, daarom sal die gereedskap om dit op te los struktureel soortgelyk wees.
Kom ons maak die reeds verkryde logiese diagram van entiteitsverwantskappe reg. Om ons model makliker te verstaan, sal ons die mees primitiewe vertoonopsie gebruik sonder die komplikasies van UML- of IDEF-notasies:
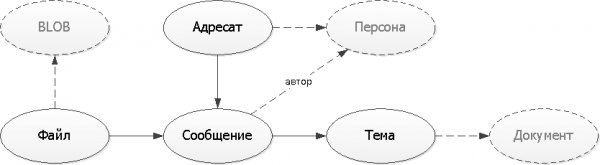
In ons voorbeeld is die persoon, dokument en binêre "liggaam" van die lêer "eksterne" entiteite wat onafhanklik bestaan sonder ons diens. Daarom sal ons hulle bloot in die toekoms as 'n paar skakels "êrens" deur UUID beskou.
Teken diagramme so eenvoudig as moontlik - meeste van die mense aan wie jy hulle sal wys is nie kundiges in die lees van UML/IDEF nie. Maar maak seker om te teken.
Stap 3: Skets die tabelstruktuur
Oor tabel- en veldnameDie "Russiese" name van velde en tabelle kan anders behandel word, maar dit is 'n kwessie van smaak. Omdat die daar is geen buitelandse ontwikkelaars nie, en PostgreSQL laat ons toe om name selfs in hiërogliewe te gee, as hulle in aanhalingstekens ingesluit, dan verkies ons om voorwerpe ondubbelsinnig en duidelik te benoem sodat daar geen verskille is nie.
Aangesien baie mense gelyktydig boodskappe aan ons skryf, kan sommige van hulle dit selfs doen vanlyn, dan is die eenvoudigste opsie gebruik UUID's as identifiseerders nie net vir eksterne entiteite nie, maar ook vir alle voorwerpe binne ons diens. Boonop kan hulle selfs aan die kliëntkant gegenereer word - dit sal ons help om boodskappe te stuur wanneer die databasis tydelik onbeskikbaar is, en die waarskynlikheid van 'n botsing uiters laag is.
Die konseptabelstruktuur in ons databasis sal soos volg lyk:
Tabelle: RU
CREATE TABLE "Тема"(
"Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "Сообщение"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "Автор"
uuid
, "ДатаВремя"
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат"(
"Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл"(
"Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);Tabelle: EN
CREATE TABLE theme(
theme
uuid
PRIMARY KEY
, document
uuid
, title
text
);
CREATE TABLE message(
message
uuid
PRIMARY KEY
, theme
uuid
, author
uuid
, dt
timestamp
, body
text
);
CREATE TABLE message_addressee(
message
uuid
, person
uuid
, PRIMARY KEY(message, person)
);
CREATE TABLE message_file(
file
uuid
PRIMARY KEY
, message
uuid
, content
uuid
, filename
text
);Die eenvoudigste ding wanneer 'n formaat beskryf word, is om die verbindingsgrafiek te begin "ontwikkel". uit tabelle waarna nie verwys word nie hulself aan niemand nie.
Stap 4: Vind uit wat nie vanselfsprekend is nie
Dit is dit, ons het 'n databasis ontwerp waarin jy perfek kan skryf en op een of ander manier lees.
Kom ons plaas onsself in die skoene van die gebruiker van ons diens – wat wil ons daarmee maak?
- Laaste boodskappe
Dit chronologies gesorteer 'n register van "my" boodskappe gebaseer op verskeie kriteria. Waar ek een van die ontvangers is, waar ek die skrywer is, waar hulle vir my geskryf het en ek nie geantwoord het nie, waar hulle my nie geantwoord het nie, ... - Deelnemers van die korrespondensie
Wie neem selfs aan hierdie lang, lang gesels deel?
Ons struktuur stel ons in staat om albei hierdie probleme "in die algemeen" op te los, maar nie vinnig nie. Die probleem is dat vir sortering binne die eerste taak nie in staat om indeks te skep nie, geskik vir elkeen van die deelnemers (en jy sal al die rekords moet onttrek), en om die tweede een op te los wat jy nodig het onttrek alle boodskappe oor hierdie onderwerp.
Onbedoelde gebruikertake kan vetgedruk word kruis oor produktiwiteit.
Stap 5: Slim denormalisering
Albei ons probleme sal opgelos word deur bykomende tabelle waarin ons sal deel van die data te dupliseer, wat nodig is om op hulle indekse te vorm wat geskik is vir ons take.
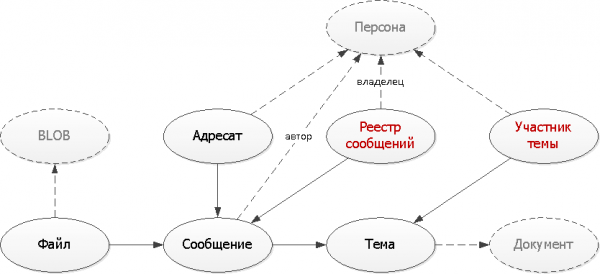
Tabelle: RU
CREATE TABLE "РеестрСообщений"(
"Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
CREATE TABLE "УчастникТемы"(
"Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);Tabelle: EN
CREATE TABLE message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
CREATE INDEX ON message_registry(owner, registry, dt DESC);
CREATE TABLE theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);Hier het ons twee tipiese benaderings toegepas wat gebruik word wanneer hulptabelle geskep word:
- Vermenigvuldiging van rekords
Deur een aanvanklike boodskaprekord te gebruik, skep ons verskeie opvolgrekords in verskillende tipes registers vir verskillende eienaars – beide vir die sender en vir die ontvanger. Maar elkeen van die registers val nou op die indeks - ons sal immers in 'n tipiese geval net die eerste bladsy wil sien. - Unieke rekords
Elke keer as jy 'n boodskap binne 'n spesifieke onderwerp stuur, is dit genoeg om te kyk of so 'n inskrywing reeds bestaan. Indien nie, voeg dit by ons "woordeboek".
In die volgende deel van die artikel sal ons praat oor in die struktuur van ons databasis.
Bron: will.com
