


Hoe verstaan 'n backend-ontwikkelaar dat 'n SQL-navraag goed sal werk op 'n "prod"? In groot of vinnig groeiende maatskappye het nie almal toegang tot die “produk” nie. En met toegang kan nie alle versoeke pynloos nagegaan word nie, en die skep van 'n kopie van die databasis neem dikwels ure. Om hierdie probleme op te los, het ons 'n kunsmatige DBA geskep - Joe. Dit is reeds suksesvol in verskeie maatskappye geïmplementeer en help meer as 'n dosyn ontwikkelaars.
Video:

Hi almal! My naam is Anatoly Stansler. Ek werk vir 'n maatskappy . Ons is daartoe verbind om die ontwikkelingsproses te bespoedig deur die vertragings wat verband hou met die werk van Postgres van ontwikkelaars, DBA's en QA's te verwyder.
Ons het wonderlike kliënte en vandag sal 'n deel van die verslag gewy word aan sake wat ons ontmoet het terwyl ons met hulle gewerk het. Ek sal praat oor hoe ons hulle gehelp het om nogal ernstige probleme op te los.

Wanneer ons komplekse hoë-lading migrasies ontwikkel en doen, vra ons onsself die vraag: "Sal hierdie migrasie opstyg?". Ons gebruik hersiening, ons gebruik die kennis van meer ervare kollegas, DBA-kundiges. En hulle kan sê of dit sal vlieg of nie.
Maar miskien sal dit beter wees as ons dit self op volgrootte kopieë kan toets. En vandag sal ons net praat oor watter benaderings tot toetsing nou is en hoe dit beter gedoen kan word en met watter instrumente. Ons sal ook praat oor die voor- en nadele van sulke benaderings, en wat ons hier kan regmaak.
Wie het al ooit indekse direk op prod gemaak of enige veranderinge aangebring? Nogal 'n bietjie van. En vir wie het dit daartoe gelei dat data verlore gegaan het of daar stilstand was? Dan ken jy hierdie pyn. Dank God daar is rugsteun.

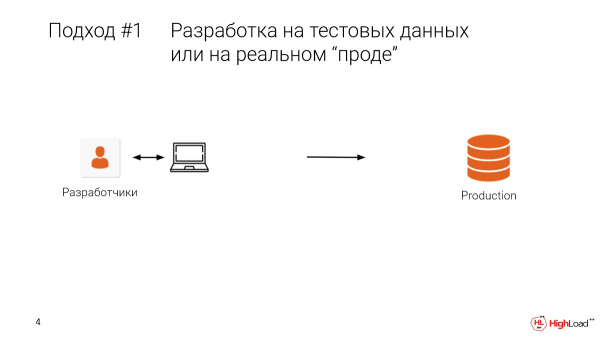
Die eerste benadering is toetsing in prod. Of, wanneer 'n ontwikkelaar op 'n plaaslike masjien sit, het hy toetsdata, daar is 'n soort beperkte keuse. En ons rol uit om te prikkel, en ons kry hierdie situasie.

Dit maak seer, dis duur. Dit is waarskynlik die beste om nie.
En wat is die beste manier om dit te doen?
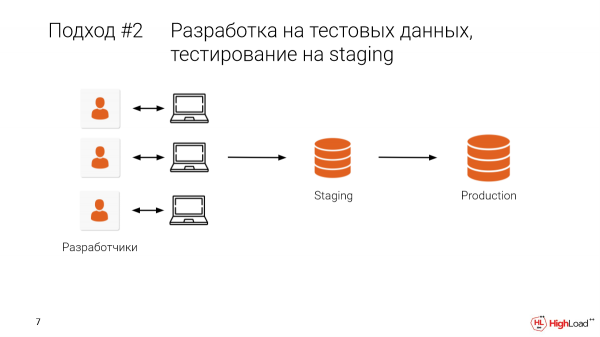
Kom ons neem opvoering en kies 'n deel van die produk daar. Of op sy beste, kom ons neem 'n ware prod, al die data. En nadat ons dit plaaslik ontwikkel het, sal ons ook nagaan vir verhoog.
Dit sal ons in staat stel om sommige van die foute te verwyder, d.w.s. verhoed dat hulle op prod.
Wat is die probleme?
- Die probleem is dat ons hierdie opvoering met kollegas deel. En baie dikwels gebeur dit dat jy 'n soort verandering maak, bam - en daar is geen data nie, die werk is in die drein. Staging was multi-terabyte. En jy moet lank wag dat dit weer opstaan. En ons besluit om dit môre te finaliseer. Dit is dit, ons het 'n ontwikkeling.
- En natuurlik het ons baie kollegas wat daar werk, baie spanne. En dit moet met die hand gedoen word. En dit is ongerieflik.

En dit is die moeite werd om te sê dat ons net een poging, een skoot het, as ons 'n paar veranderinge aan die databasis wil maak, raak die data aan, verander die struktuur. En as iets verkeerd geloop het, as daar 'n fout in die migrasie was, sal ons nie vinnig terugrol nie.
Dit is beter as die vorige benadering, maar daar is steeds 'n groot waarskynlikheid dat 'n soort fout na produksie gaan.
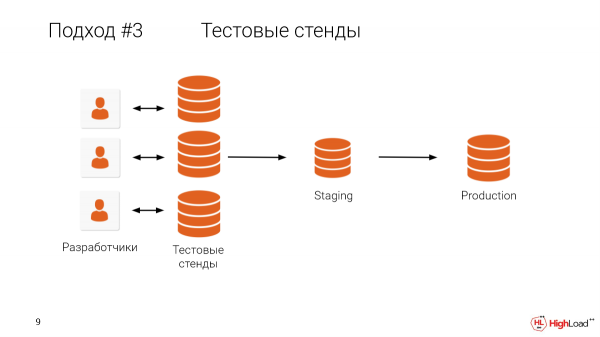
Wat verhoed ons om elke ontwikkelaar 'n toetsbank, 'n volgrootte kopie te gee? Ek dink dit is duidelik wat in die pad kom.
Wie het 'n databasis groter as 'n teragreep? Meer as die helfte van die kamer.
En dit is duidelik dat die hou van masjiene vir elke ontwikkelaar, wanneer daar so 'n groot produksie is, baie duur is, en buitendien neem dit 'n lang tyd.
Ons het kliënte wat besef het dat dit baie belangrik is om alle veranderinge op volgrootte kopieë te toets, maar hul databasis is minder as 'n teragreep, en daar is geen hulpbronne om 'n toetsbank vir elke ontwikkelaar te hou nie. Daarom moet hulle die stortings plaaslik na hul masjien aflaai en op hierdie manier toets. Dit neem baie tyd.

Selfs as jy dit binne die infrastruktuur doen, is dit reeds baie goed om een teragreep data per uur af te laai. Maar hulle gebruik logiese stortings, hulle laai plaaslik van die wolk af. Vir hulle is die spoed sowat 200 gigagrepe per uur. En dit neem nog tyd om van die logiese stortplek af om te draai, die indekse op te rol, ens.
Maar hulle gebruik hierdie benadering omdat dit hulle in staat stel om die prod betroubaar te hou.
Wat kan ons hier doen? Kom ons maak toetsbanke goedkoop en gee elke ontwikkelaar sy eie toetsbank.
En dit is moontlik.
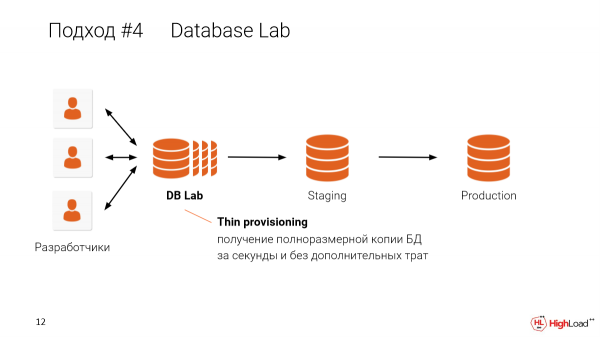
En in hierdie benadering, wanneer ons dun klone vir elke ontwikkelaar maak, kan ons dit op een masjien deel. Byvoorbeeld, as jy 'n 10TB-databasis het en dit aan 10 ontwikkelaars wil gee, hoef jy nie XNUMX x XNUMXTB-databasisse te hê nie. Jy het net een masjien nodig om dun geïsoleerde kopieë te maak vir elke ontwikkelaar wat een masjien gebruik. Ek sal jou bietjie later vertel hoe dit werk.

Werklike voorbeeld:
DB - 4,5 teragrepe.
Ons kan onafhanklike kopieë in 30 sekondes kry.
Jy hoef nie te wag vir 'n toetsstand nie en hang af van hoe groot dit is. Jy kan dit binne sekondes kry. Dit sal heeltemal geïsoleerde omgewings wees, maar wat data onder mekaar deel.
Dit is wonderlik. Hier praat ons van magie en 'n parallelle heelal.

In ons geval werk dit met die OpenZFS-stelsel.

OpenZFS is 'n kopieer-op-skryf-lêerstelsel wat foto's en klone uit die boks ondersteun. Dit is betroubaar en skaalbaar. Sy is baie maklik om te bestuur. Dit kan letterlik in twee spanne ontplooi word.
Daar is ander opsies:
lvm,
Berging (byvoorbeeld, Pure Storage).
Die databasislaboratorium waarvan ek praat, is modulêr. Kan met behulp van hierdie opsies geïmplementeer word. Maar vir nou het ons op OpenZFS gefokus, want daar was spesifiek probleme met LVM.
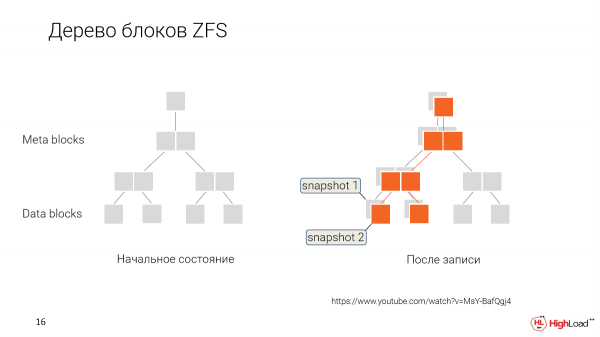
Hoe dit werk? In plaas daarvan om die data te oorskryf elke keer as ons dit verander, stoor ons dit deur eenvoudig te merk dat hierdie nuwe data van 'n nuwe tydstip af is, 'n nuwe momentopname.
En in die toekoms, wanneer ons wil terugrol of ons 'n nuwe kloon van een of ander ouer weergawe wil maak, sê ons net: "OK, gee ons hierdie blokke data wat so gemerk is."
En hierdie gebruiker sal met so 'n datastel werk. Hy sal hulle geleidelik verander, sy eie kiekies maak.
En ons sal tak. Elke ontwikkelaar in ons geval sal die geleentheid hê om sy eie kloon te hê wat hy redigeer, en die data wat gedeel word, sal tussen almal gedeel word.
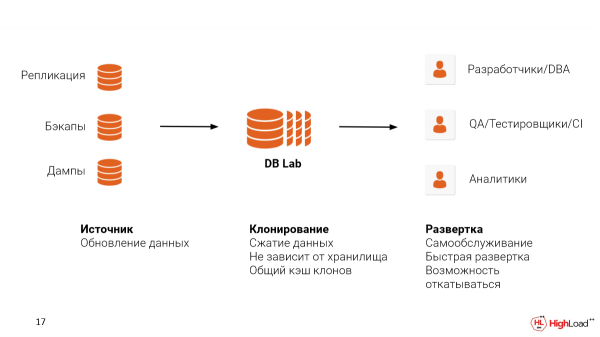
Om so 'n stelsel tuis te implementeer, moet u twee probleme oplos:
Die eerste is die bron van die data, waar jy dit vandaan sal neem. U kan replikasie met produksie opstel. Jy kan reeds die rugsteun gebruik wat jy gekonfigureer het, hoop ek. WAL-E, WAL-G of Kroegman. En selfs as jy 'n soort wolk-oplossing soos RDS of Cloud SQL gebruik, kan jy logiese stortings gebruik. Maar ons raai jou steeds aan om rugsteun te gebruik, want met hierdie benadering sal jy ook die fisiese struktuur van die lêers behou, wat jou in staat sal stel om selfs nader aan die maatstawwe te wees wat jy in produksie sal sien om daardie probleme wat bestaan op te spoor.
Die tweede is waar u die databasislaboratorium wil huisves. Dit kan Wolk wees, dit kan op die perseel wees. Dit is belangrik om hier te sê dat ZFS datakompressie ondersteun. En dit doen dit nogal goed.
Stel jou voor dat vir elke so 'n kloon, afhangende van die bewerkings wat ons met die basis doen, 'n soort dev sal groei. Hiervoor sal dev ook spasie nodig hê. Maar as gevolg van die feit dat ons 'n basis van 4,5 teragrepe geneem het, sal ZFS dit saampers tot 3,5 teragrepe. Dit kan verskil na gelang van die instellings. En ons het nog plek vir dev.
So 'n stelsel kan vir verskillende gevalle gebruik word.
Dit is ontwikkelaars, DBA's vir navraagvalidering, vir optimalisering.
Dit kan in QA-toetsing gebruik word om 'n spesifieke migrasie te toets voordat ons dit uitrol na prod. En ons kan ook spesiale omgewings vir QA verhoog met regte data, waar hulle nuwe funksionaliteit kan toets. En dit sal sekondes neem in plaas van ure te wag, en dalk dae in sommige ander gevalle waar dun kopieë nie gebruik word nie.
En nog 'n geval. As die maatskappy nie 'n ontledingstelsel opgestel het nie, kan ons 'n dun kloon van die produkbasis isoleer en dit aan lang navrae of spesiale indekse gee wat in analise gebruik kan word.

Met hierdie benadering:
Lae waarskynlikheid van foute op die "prod", omdat ons al die veranderinge op volgrootte data getoets het.
Ons het 'n kultuur van toetsing, want nou hoef jy nie ure vir jou eie staanplek te wag nie.
En daar is geen hindernis nie, geen wag tussen toetse nie. Jy kan eintlik gaan kyk. En dit sal beter op hierdie manier wees namate ons die ontwikkeling versnel.
Daar sal minder herfaktorering wees. Minder foute sal in prod beland. Ons sal hulle later minder herfaktoriseer.
Ons kan onomkeerbare veranderinge omkeer. Dit is nie die standaardbenadering nie.
- Dit is voordelig omdat ons die hulpbronne van die toetsbanke deel.
Reeds goed, maar wat anders kan versnel word?

Danksy so 'n stelsel kan ons die drempel om in te gaan vir so 'n toets aansienlik verminder.
Nou is daar 'n bose kringloop waar 'n ontwikkelaar 'n kenner moet word om toegang tot regte volgrootte data te kry. Hy moet met sulke toegang vertrou word.
Maar hoe om te groei as dit nie daar is nie. Maar wat as jy net 'n baie klein stel toetsdata tot jou beskikking het? Dan sal jy geen werklike ervaring kry nie.
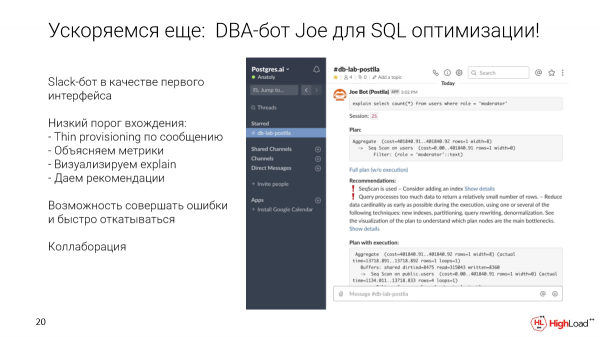
Hoe om uit hierdie kring te kom? As die eerste koppelvlak, gerieflik vir ontwikkelaars van enige vlak, het ons die Slack-bot gekies. Maar dit kan enige ander koppelvlak wees.
Wat laat dit jou toe om te doen? Jy kan 'n spesifieke navraag neem en dit na 'n spesiale kanaal vir die databasis stuur. Ons sal outomaties 'n dun kloon binne sekondes ontplooi. Kom ons voer hierdie versoek uit. Ons versamel maatstawwe en aanbevelings. Kom ons wys 'n visualisering. En dan sal hierdie kloon bly sodat hierdie navraag op een of ander manier geoptimaliseer kan word, indekse kan byvoeg, ens.
En ook Slack gee ons geleenthede vir samewerking buite die boks. Aangesien dit net 'n kanaal is, kan jy hierdie versoek net daar in die draad vir so 'n versoek begin bespreek, ping jou kollegas, DBA's wat binne die maatskappy is.

Maar daar is natuurlik probleme. Omdat dit die regte wêreld is, en ons 'n bediener gebruik wat baie klone op een slag huisves, moet ons die hoeveelheid geheue en SVE-krag wat vir die klone beskikbaar is, saamdruk.
Maar vir hierdie toetse om aanneemlik te wees, moet jy op een of ander manier hierdie probleem oplos.
Dit is duidelik dat die belangrike punt dieselfde data is. Maar ons het dit reeds. En ons wil dieselfde konfigurasie bereik. En ons kan so 'n byna identiese konfigurasie gee.
Dit sal gaaf wees om dieselfde hardeware as in produksie te hê, maar dit kan verskil.
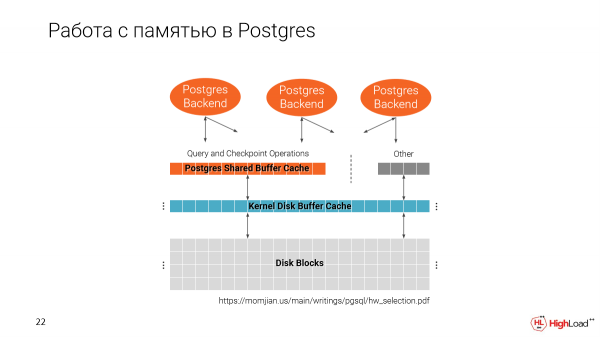
Kom ons onthou hoe Postgres met geheue werk. Ons het twee caches. Een van die lêerstelsel en een inheemse Postgres, dit wil sê Shared Buffer Cache.
Dit is belangrik om daarop te let dat die Shared Buffer Cache toegewys word wanneer Postgres begin, afhangende van watter grootte jy in die konfigurasie spesifiseer.
En die tweede kas gebruik alle beskikbare spasie.
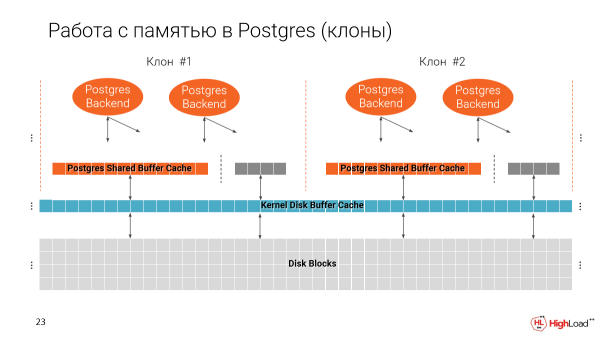
En wanneer ons verskeie klone op een masjien maak, blyk dit dat ons die geheue geleidelik vul. En op 'n goeie manier is Shared Buffer Cache 25% van die totale hoeveelheid geheue wat op die masjien beskikbaar is.
En dit blyk dat as ons nie hierdie parameter verander nie, ons slegs 4 gevalle op een masjien sal kan laat loop, dit wil sê 4 van al sulke dun klone. En dit is natuurlik sleg, want ons wil baie meer van hulle hê.
Maar aan die ander kant word Buffer Cache gebruik om navrae vir indekse uit te voer, dit wil sê, die plan hang af van hoe groot ons kas is. En as ons net hierdie parameter neem en dit verminder, dan kan ons planne baie verander.
Byvoorbeeld, as ons 'n groot kas op prod het, sal Postgres verkies om 'n indeks te gebruik. En indien nie, dan sal daar SeqScan wees. En wat sou die punt wees as ons planne nie saamval nie?
Maar hier kom ons tot die gevolgtrekking dat die plan in Postgres in werklikheid nie afhang van die spesifieke grootte wat in die gedeelde buffer in die plan gespesifiseer word nie, dit hang af van die effektiewe_kas_grootte.

Effective_cache_size is die geskatte hoeveelheid kas wat vir ons beskikbaar is, dit wil sê die som van Buffer Cache en lêerstelselkas. Dit word gestel deur die config. En hierdie geheue word nie toegeken nie.
En as gevolg van hierdie parameter, kan ons Postgres soort van mislei, sê dat ons eintlik baie data beskikbaar het, selfs al het ons nie hierdie data nie. En dus sal die planne heeltemal saamval met produksie.
Maar dit kan die tydsberekening beïnvloed. En ons optimaliseer navrae deur tydsberekening, maar dit is belangrik dat tydsberekening van baie faktore afhang:
Dit hang af van die vrag wat tans op prod.
Dit hang af van die eienskappe van die masjien self.
En dit is 'n indirekte parameter, maar in werklikheid kan ons presies optimaliseer volgens die hoeveelheid data wat hierdie navraag sal lees om die resultaat te kry.
En as jy wil hê die tydsberekening moet naby wees aan wat ons in prod sal sien, dan moet ons die meeste soortgelyke hardeware neem en moontlik selfs meer sodat al die klone pas. Maar dit is 'n kompromie, dit wil sê jy sal dieselfde planne kry, jy sal sien hoeveel data 'n spesifieke navraag sal lees en jy sal kan aflei of hierdie navraag goed (of migrasie) of sleg is, dit moet nog geoptimaliseer word .
Kom ons kyk hoe Joe spesifiek geoptimaliseer is.
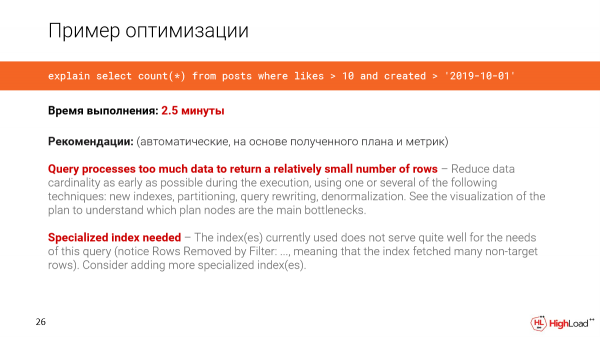
Kom ons neem 'n versoek van 'n regte stelsel. In hierdie geval is die databasis 1 teragreep. En ons wil die aantal vars plasings tel wat meer as 10 laaiks gehad het.
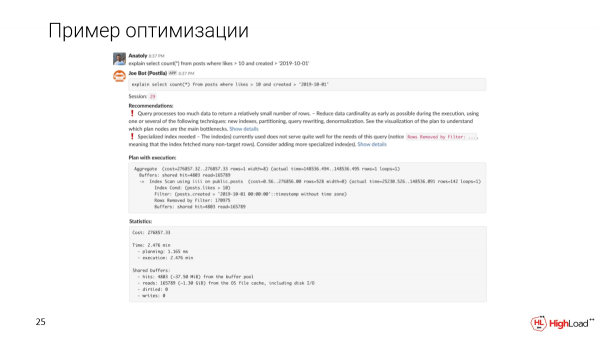
Ons skryf 'n boodskap aan die kanaal, 'n kloon is vir ons ontplooi. En ons sal sien dat so 'n versoek binne 2,5 minute voltooi sal word. Dit is die eerste ding wat ons raaksien.
B Joe sal jou outomatiese aanbevelings wys op grond van die plan en statistieke.
Ons sal sien dat die navraag te veel data verwerk om 'n relatief klein aantal rye te kry. En 'n soort gespesialiseerde indeks is nodig, aangesien ons opgemerk het dat daar te veel gefiltreerde rye in die navraag is.
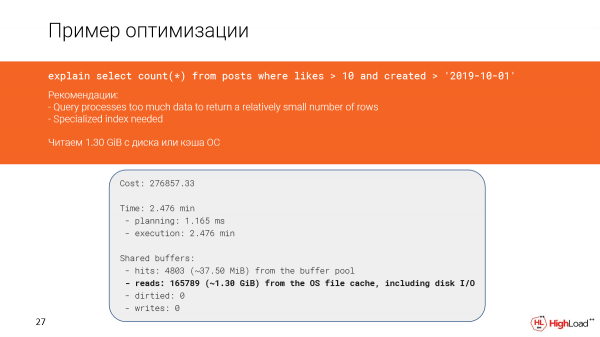
Kom ons kyk van nader na wat gebeur het. Inderdaad, ons sien dat ons byna een en 'n half gigagrepe data van die lêerkas of selfs vanaf skyf gelees het. En dit is nie goed nie, want ons het net 142 reëls gekry.
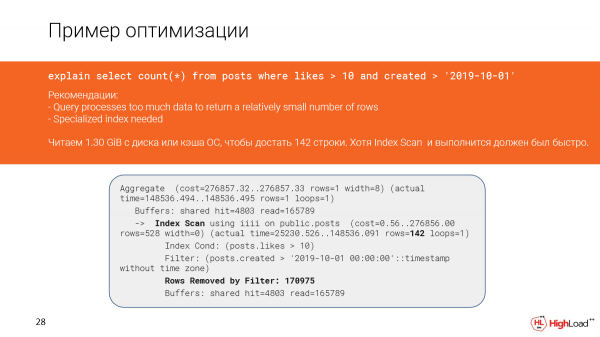
En, wil dit voorkom, ons het 'n indeksskandering hier en moes vinnig uitgewerk het, maar aangesien ons te veel reëls uitgefiltreer het (ons moes hulle tel), het die versoek stadig uitgewerk.
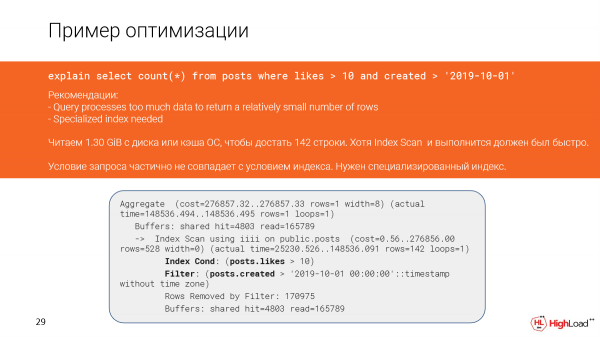
En dit het in die plan gebeur as gevolg van die feit dat die voorwaardes in die navraag en die voorwaardes in die indeks gedeeltelik nie ooreenstem nie.
Kom ons probeer om die indeks meer presies te maak en kyk hoe die navraaguitvoering daarna verander.
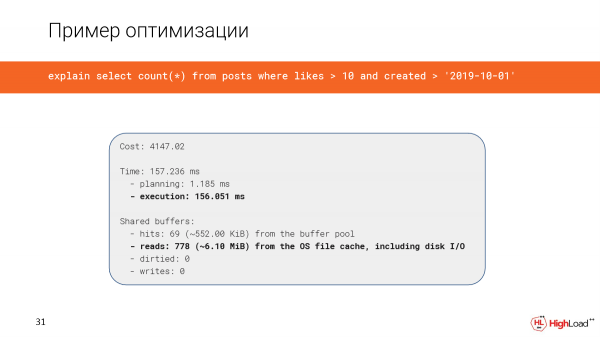
Die skepping van die indeks het nogal lank geneem, maar nou gaan ons die navraag na en sien dat die tyd in plaas van 2,5 minute slegs 156 millisekondes is, wat goed genoeg is. En ons lees net 6 megagrepe se data.
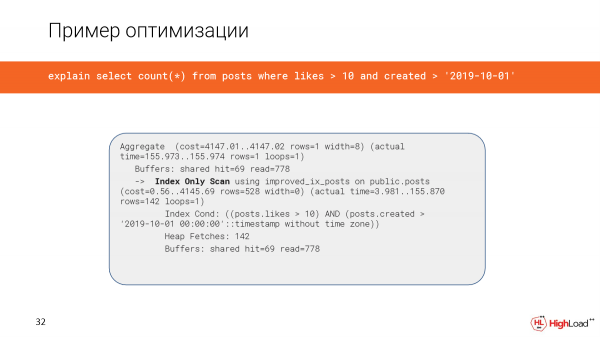
En nou gebruik ons slegs indeksskandering.
Nog 'n belangrike storie is dat ons die plan op 'n meer verstaanbare manier wil aanbied. Ons het visualisering geïmplementeer deur gebruik te maak van Flame Graphs.
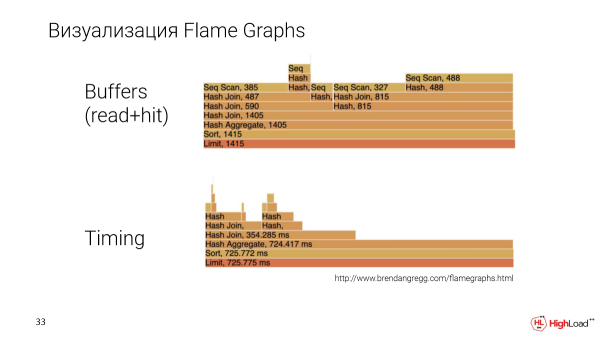
Dit is 'n ander versoek, meer intens. En ons bou vlamgrafieke volgens twee parameters: dit is die hoeveelheid data wat 'n spesifieke nodus in die plan en tydsberekening getel het, dit wil sê die uitvoeringstyd van die nodus.
Hier kan ons spesifieke nodusse met mekaar vergelyk. En dit sal duidelik wees watter van hulle meer of minder neem, wat gewoonlik moeilik is om in ander weergawemetodes te doen.
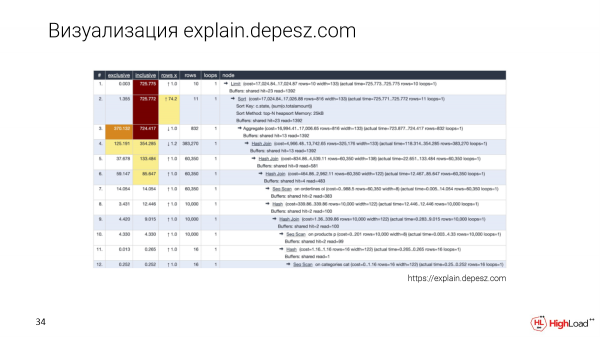
Natuurlik weet almal van explain.depesz.com. 'n Goeie kenmerk van hierdie visualisering is dat ons die teksplan stoor en ook 'n paar basiese parameters in 'n tabel plaas sodat ons kan sorteer.
En ontwikkelaars wat nog nie in hierdie onderwerp gedelf het nie, gebruik ook explain.depesz.com, want dit is makliker vir hulle om uit te vind watter maatstawwe belangrik is en watter nie.
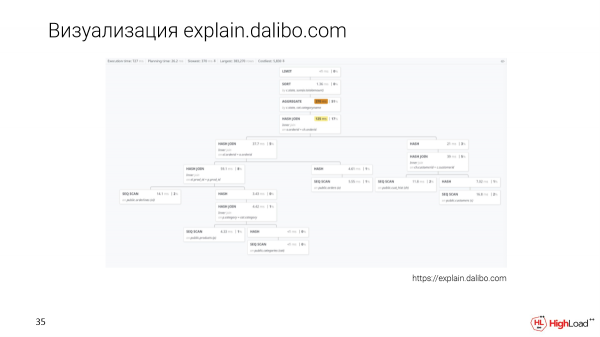
Daar is 'n nuwe benadering tot visualisering - dit is explain.dalibo.com. Hulle doen 'n boomvisualisering, maar dit is baie moeilik om nodusse met mekaar te vergelyk. Hier kan jy die struktuur goed verstaan, maar as daar 'n groot versoek is, sal jy heen en weer moet blaai, maar ook 'n opsie.
samewerking
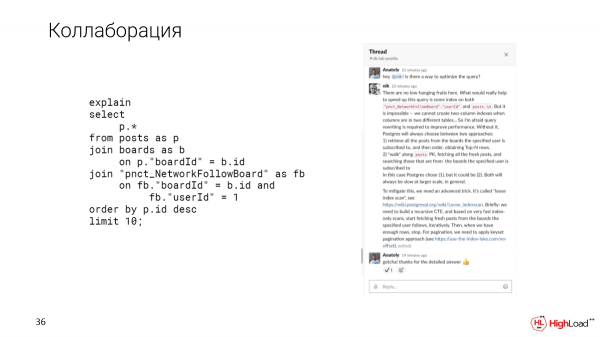
En, soos ek gesê het, Slack gee ons die geleentheid om saam te werk. Byvoorbeeld, as ons 'n komplekse navraag teëkom wat nie duidelik is hoe om te optimaliseer nie, kan ons hierdie probleem met ons kollegas in 'n draad in Slack uitklaar.

Dit lyk vir ons of dit belangrik is om op volgrootte data te toets. Om dit te doen, het ons die Update Database Lab-nutsding gemaak, wat in oopbron beskikbaar is. Jy kan ook die Joe-bot gebruik. Jy kan dit dadelik neem en dit by jou plek implementeer. Alle gidse is daar beskikbaar.
Dit is ook belangrik om daarop te let dat die oplossing self nie revolusionêr is nie, want daar is Delphix, maar dit is 'n ondernemingsoplossing. Dit is heeltemal toe, dit is baie duur. Ons spesialiseer spesifiek in Postgres. Dit is almal oopbronprodukte. Sluit by ons aan!
Dit is waar ek eindig. Dankie!
vrae
Hallo! Dankie vir die verslag! Baie interessant, veral vir my, want ek het 'n tyd gelede omtrent dieselfde probleem opgelos. En so het ek 'n aantal vrae. Hopelik kry ek ten minste 'n deel daarvan.
Ek wonder hoe jy die plek vir hierdie omgewing bereken? Die tegnologie beteken dat jou klone onder sekere omstandighede tot die maksimum grootte kan groei. Rofweg gesproke, as jy 'n tien teragreep databasis en 10 klone het, dan is dit maklik om 'n situasie te simuleer waar elke kloon 10 unieke data weeg. Hoe bereken jy hierdie plek, dit is daardie delta waaroor jy gepraat het, waarin hierdie klone sal lewe?
Goeie vraag. Dit is belangrik om tred te hou met spesifieke klone hier. En as 'n kloon 'n te groot verandering het, begin dit groei, dan kan ons eers 'n waarskuwing aan die gebruiker hieroor uitreik, of hierdie kloon onmiddellik stop sodat ons nie 'n mislukkingsituasie het nie.
Ja, ek het 'n geneste vraag. Dit wil sê, hoe verseker jy die lewensiklus van hierdie modules? Ons het hierdie probleem en 'n hele aparte storie. Hoe gebeur dit?
Daar is 'n paar ttl vir elke kloon. Basies het ons 'n vaste ttl.
Wat, indien nie 'n geheim nie?
1 uur, dit wil sê ledig - 1 uur. As dit nie gebruik word nie, dan slaan ons dit. Maar daar is geen verrassing hier nie, aangesien ons die kloon binne sekondes kan verhoog. En as jy dit weer nodig het, dan asseblief.
Ek stel ook belang in die keuse van tegnologieë, want ons gebruik byvoorbeeld verskeie metodes parallel om een of ander rede. Hoekom ZFS? Hoekom het jy nie LVM gebruik nie? Jy het genoem dat daar probleme met LVM was. Wat was die probleme? Na my mening is die mees optimale opsie met berging, wat prestasie betref.
Wat is die grootste probleem met ZFS? Die feit dat jy op dieselfde gasheer moet loop, dit wil sê alle gevalle sal binne dieselfde bedryfstelsel leef. En in die geval van berging, kan jy verskillende toerusting koppel. En die bottelnek is net daardie blokke wat op die stoorstelsel is. En die vraag oor die keuse van tegnologie is interessant. Hoekom nie LVM nie?
Ons kan spesifiek LVM by die vergadering bespreek. Wat berging betref, is dit net duur. Ons kan ZFS enige plek ontplooi. Jy kan dit op jou masjien ontplooi. Jy kan eenvoudig die bewaarplek aflaai en ontplooi. ZFS kan amper enige plek geïnstalleer word, as ons praat oor Linux Ons praat daaroor. So, ons kry 'n baie buigsame oplossing. En ZFS self bied baie uit die boks. Jy kan soveel data daarin laai as wat jy wil, 'n groot aantal skywe koppel, en dit het kiekies. En, soos ek reeds gesê het, dit is maklik om te administreer. Dit lyk dus baie aangenaam om te gebruik. Dit is bewys, dit bestaan al vir baie jare. Dit het 'n baie groot gemeenskap wat groei. ZFS is 'n baie betroubare oplossing.
Nikolai Samokhvalov: Mag ek verder kommentaar lewer? My naam is Nikolay, ons werk saam met Anatoly. Ek stem saam dat berging wonderlik is. En sommige van ons kliënte het Pure Storage ens.
Anatoly het korrek opgemerk dat ons op modulariteit gefokus is. En in die toekoms kan jy een koppelvlak implementeer - neem 'n momentopname, maak 'n kloon, vernietig die kloon. Dit is alles maklik. En berging is cool, as dit is.
Maar ZFS is beskikbaar vir almal. DelPhix is al genoeg, hulle het 300 kliënte. Hiervan het Fortune 100 50 kliënte, dit wil sê hulle is op NASA gerig, ens. Dit is tyd dat almal hierdie tegnologie kry. En dit is hoekom ons 'n oopbron-kern het. Ons het 'n koppelvlakdeel wat nie oopbron is nie. Dit is die platform wat ons sal wys. Maar ons wil hê dit moet vir almal toeganklik wees. Ons wil 'n rewolusie maak sodat alle toetsers ophou om op skootrekenaars te raai. Ons moet SELECT skryf en dadelik sien dat dit stadig is. Hou op om te wag dat die DBA jou daarvan vertel. Hier is die hoofdoel. En ek dink dat ons almal hiertoe sal kom. En ons maak hierdie ding vir almal om te hê. Daarom ZFS, want dit sal oral beskikbaar wees. Dankie aan die gemeenskap vir die oplossing van probleme en vir 'n oopbronlisensie, ens.*
Groete! Dankie vir die verslag! My naam is Maxim. Ons het met dieselfde kwessies te doen gehad. Hulle het op hul eie besluit. Hoe deel jy hulpbronne tussen hierdie klone? Elke kloon kan op enige gegewe tydstip sy eie ding doen: die een toets een ding, 'n ander 'n ander, iemand bou 'n indeks, iemand het 'n swaar werk. En as jy nog steeds kan verdeel deur SVE, dan deur IO, hoe verdeel jy? Dit is die eerste vraag.
En die tweede vraag gaan oor die ongelykheid van die erwe. Kom ons sê ek het ZFS hier en alles is cool, maar die kliënt op prod het nie ZFS nie, maar ext4, byvoorbeeld. Hoe in hierdie geval?
Die vrae is baie goed. Ek het hierdie probleem 'n bietjie genoem met die feit dat ons hulpbronne deel. En die oplossing is dit. Stel jou voor dat jy op die verhoog toets. Jy kan ook terselfdertyd so 'n situasie hê dat iemand een vrag gee, iemand anders. En gevolglik sien jy onverstaanbare statistieke. Selfs dieselfde probleem kan met prod. Wanneer jy een of ander versoek wil nagaan en sien dat daar een of ander probleem daarmee is - dit werk stadig, dan was die probleem eintlik nie in die versoek nie, maar in die feit dat daar 'n soort parallelle las is.
En daarom is dit hier belangrik om te fokus op wat die plan sal wees, watter stappe ons in die plan sal neem en hoeveel data ons hiervoor sal insamel. Die feit dat ons skywe byvoorbeeld met iets gelaai sal word, dit sal spesifiek die tydsberekening beïnvloed. Maar ons kan skat hoe gelaai hierdie versoek is deur die hoeveelheid data. Dit is nie so belangrik dat daar terselfdertyd een of ander teregstelling sal wees nie.
Ek het twee vrae. Dit is baie cool goed. Was daar gevalle waar produksiedata krities is, soos kredietkaartnommers? Is daar reeds iets gereed of is dit 'n aparte taak? En die tweede vraag - is daar so iets vir MySQL?
Oor die data. Ons sal verduistering doen totdat ons dit doen. Maar as jy presies Joe ontplooi, as jy nie toegang gee aan ontwikkelaars nie, dan is daar geen toegang tot die data nie. Hoekom? Want Joe wys nie data nie. Dit wys net statistieke, planne en dit is dit. Dit is doelbewus gedoen, want dit is een van die vereistes van ons kliënt. Hulle wou in staat wees om te optimaliseer sonder om almal toegang te gee.
Oor MySQL. Hierdie stelsel kan gebruik word vir enigiets wat toestand op skyf stoor. En aangesien ons Postgres doen, doen ons nou eers al die outomatisering vir Postgres. Ons wil die verkryging van data vanaf 'n rugsteun outomatiseer. Ons konfigureer Postgres korrek. Ons weet hoe om planne te laat pas, ens.
Maar aangesien die stelsel uitbreidbaar is, kan dit ook vir MySQL gebruik word. En daar is sulke voorbeelde. Yandex het 'n soortgelyke ding, maar hulle publiseer dit nêrens nie. Hulle gebruik dit binne Yandex.Metrica. En daar is net 'n storie oor MySQL. Maar die tegnologieë is dieselfde, ZFS.
Dankie vir die verslag! Ek het ook 'n paar vrae. Jy het genoem dat kloning vir analise gebruik kan word, byvoorbeeld om bykomende indekse daar te bou. Kan jy 'n bietjie meer vertel oor hoe dit werk?
En ek sal dadelik die tweede vraag vra oor die ooreenkoms van die erwe, die ooreenkoms van die planne. Die plan hang ook af van die statistieke wat deur Postgres ingesamel word. Hoe los jy hierdie probleem op?
Volgens die ontleding is daar geen spesifieke gevalle nie, want ons het dit nog nie gebruik nie, maar daar is so 'n geleentheid. As ons van indekse praat, stel jou dan voor dat 'n navraag 'n tabel met honderde miljoene rekords en 'n kolom jaag wat gewoonlik nie in prod geïndekseer is nie. En ons wil 'n paar data daar bereken. As hierdie versoek na prod gestuur word, is daar 'n moontlikheid dat dit eenvoudig op prod sal wees, want die versoek sal vir 'n minuut daar verwerk word.
Ok, kom ons maak 'n dun kloon wat nie vreeslik is om vir 'n paar minute te stop nie. En om dit gemakliker te maak om die analise te lees, sal ons indekse byvoeg vir daardie kolomme waarin ons in data belangstel.
Die indeks sal elke keer geskep word?
Jy kan dit so maak dat ons aan die data raak, momentopnames maak, dan sal ons van hierdie momentopname herstel en nuwe versoeke stuur. Dit wil sê, jy kan dit so maak dat jy nuwe klone met reeds aangehegte indekse kan verhoog.
Wat die vraag oor statistieke betref, as ons herstel vanaf 'n rugsteun, as ons replikasie doen, dan sal ons statistieke presies dieselfde wees. Omdat ons die hele fisiese datastruktuur het, dit wil sê, ons sal die data saambring soos dit is met al die statistiekmaatstawwe.
Hier is nog 'n probleem. As jy 'n wolkoplossing gebruik, is slegs logiese stortings daar beskikbaar, want Google, Amazon laat jou nie toe om 'n fisiese kopie te neem nie. Daar sal 'n probleem wees.
Dankie vir die aanbieding. Twee goeie vrae is hier geopper oor MySQL en hulpbrondeling. Maar in wese kom dit alles neer op die feit dat dit nie 'n onderwerp vir spesifieke DBMS'e is nie, maar vir die lêerstelsel as geheel. En gevolglik moet hulpbrondelingskwessies ook van daar af aangespreek word, nie net in Postgres nie, maar in die lêerstelsel self. bediener, byvoorbeeld.
My vraag is 'n bietjie anders. Dit is nader aan die meerlaagse databasis, waar daar verskeie lae is. Byvoorbeeld, ons stel 'n tien teragreep beeldopdatering op, ons repliseer. En ons gebruik hierdie oplossing spesifiek vir databasisse. Replikasie is aan die gang, data word opgedateer. Daar is 100 werknemers wat parallel hier werk, wat voortdurend hierdie verskillende skote loods. Wat om te doen? Hoe om seker te maak dat daar geen konflik is nie, dat hulle een geloods het, en dan het die lêerstelsel verander, en hierdie foto's het almal verdwyn?
Hulle sal nie gaan nie, want dit is hoe ZFS werk. Ons kan die lêerstelselveranderings wat as gevolg van replikasie kom, apart in een draad hou. En hou die klone wat ontwikkelaars gebruik op ouer weergawes van die data. En dit werk vir ons, alles is in orde hiermee.
Dit blyk dat die opdatering as 'n bykomende laag sal plaasvind, en alle nuwe foto's sal reeds weggaan, gebaseer op hierdie laag, reg?
Van vorige lae wat van vorige replikasies was.
Die vorige lae sal afval, maar hulle sal na die ou laag verwys, en sal hulle nuwe beelde neem van die laaste laag wat in die opdatering ontvang is?
Oor die algemeen, ja.
Dan sal ons as gevolg daarvan tot 'n vy van lae hê. En met verloop van tyd sal hulle saamgepers moet word?
Ja alles is reg. Daar is 'n venster. Ons hou weeklikse kiekies. Dit hang af van watter hulpbron jy het. As jy die vermoë het om baie data te stoor, kan jy foto's vir 'n lang tyd stoor. Hulle sal nie op hul eie weggaan nie. Daar sal geen datakorrupsie wees nie. As die kiekies verouderd is, soos dit vir ons lyk, dit wil sê dit hang af van die beleid in die maatskappy, dan kan ons dit eenvoudig uitvee en spasie vrymaak.
Hallo, dankie vir die verslag! Vraag oor Joe. Jy het gesê dat die kliënt nie almal toegang tot die data wou gee nie. Streng gesproke, as 'n persoon die resultaat van Verduidelik Analiseer het, dan kan hy die data loer.
Dit is so. Ons kan byvoorbeeld skryf: "SELECT FROM WHERE email = to that". Dit wil sê, ons sal nie die data self sien nie, maar ons kan 'n paar indirekte tekens sien. Dit moet verstaan word. Maar aan die ander kant is dit alles daar. Ons het 'n log-oudit, ons het beheer oor ander kollegas wat ook sien wat die ontwikkelaars doen. En as iemand dit probeer doen, dan sal die veiligheidsdiens na hulle toe kom en aan hierdie kwessie werk.
Goeie middag Dankie vir die verslag! Ek het 'n kort vraag. As die maatskappy nie Slack gebruik nie, is daar nou enige binding daaraan, of is dit moontlik vir ontwikkelaars om gevalle te ontplooi om 'n toetstoepassing aan die databasisse te koppel?
Nou is daar 'n skakel na Slack, dit wil sê daar is geen ander boodskapper nie, maar ek wil regtig ook ondersteuning vir ander boodskappers maak. Wat kan jy doen? Jy kan DB Lab ontplooi sonder Joe, gaan met die hulp van die REST API of met die hulp van ons platform en skep klone en verbind met PSQL. Maar dit kan gedoen word as jy gereed is om jou ontwikkelaars toegang tot die data te gee, want daar sal nie meer enige skerm wees nie.
Ek het nie hierdie laag nodig nie, maar ek het so 'n geleentheid nodig.
Dan ja, dit kan gedoen word.
Bron: will.com
