


Hi almal! My naam is Oleg Sidorenkov, ek werk by DomClick as 'n infrastruktuur spanleier. Ons gebruik die Cube al vir meer as drie jaar te koop, en gedurende hierdie tyd het ons baie verskillende interessante oomblikke daarmee beleef. Vandag sal ek jou vertel hoe jy, met die regte benadering, selfs meer prestasie uit vanielje Kubernetes vir jou cluster kan druk. Bestendig gereed!
Julle weet almal baie goed dat Kubernetes 'n skaalbare oopbronstelsel vir houerorkestrasie is; wel, of 5 binaries wat toor deur die lewensiklus van jou mikrodienste in 'n bedieneromgewing te bestuur. Boonop is dit 'n redelik buigsame instrument wat soos 'n Lego-konstruktor saamgestel kan word vir maksimum aanpassing vir verskillende take.
En alles blyk in orde te wees: gooi bedieners in die cluster, soos vuurmaakhout in 'n vuurkas, en ken nie hartseer nie. Maar as jy vir die omgewing is, dan sal jy dink: “Hoe kan ek die vuur in die stoof hou en spyt wees oor die bos?”. Met ander woorde, hoe om maniere te vind om infrastruktuur te verbeter en koste te verminder.
1. Bly op hoogte van span- en toepassingshulpbronne

Een van die mees banale maar effektiewe metodes is die bekendstelling van versoeke/limiete. Skei toepassings volgens naamruimtes en naamruimtes deur ontwikkelingspanne. Stel die toepassing in voordat waardes ontplooi word vir die verbruik van verwerkertyd, geheue, kortstondige berging.
resources:
requests:
memory: 2Gi
cpu: 250m
limits:
memory: 4Gi
cpu: 500mUit ondervinding het ons tot die gevolgtrekking gekom: dit is nie die moeite werd om versoeke van perke met meer as twee keer op te blaas nie. Die groepgrootte word bereken op grond van versoeke, en as jy die toepassing op 'n verskil in hulpbronne stel, byvoorbeeld met 5-10 keer, stel jou dan voor wat met jou nodus sal gebeur wanneer dit met peule gevul word en skielik 'n vrag ontvang. Niks goed nie. Op 'n minimum, smoor, en as 'n maksimum, sê totsiens aan die werker en kry 'n sikliese las op die res van die nodusse nadat die peule begin beweeg.
Daarbenewens, met die hulp limitranges jy kan hulpbronwaardes vir die houer aan die begin stel - minimum, maksimum en verstek:
➜ ~ kubectl describe limitranges --namespace ops
Name: limit-range
Namespace: ops
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 10 100m 100m 2
Container ephemeral-storage 12Mi 8Gi 128Mi 4Gi -
Container memory 64Mi 40Gi 128Mi 128Mi 2Onthou om die naamruimtehulpbronne te beperk sodat een opdrag nie al die hulpbronne van die groepie kan neem nie:
➜ ~ kubectl describe resourcequotas --namespace ops
Name: resource-quota
Namespace: ops
Resource Used Hard
-------- ---- ----
limits.cpu 77250m 80
limits.memory 124814367488 150Gi
pods 31 45
requests.cpu 53850m 80
requests.memory 75613234944 150Gi
services 26 50
services.loadbalancers 0 0
services.nodeports 0 0Soos jy kan sien uit die beskrywing resourcequotas, as die ops-opdrag peule wil ontplooi wat nog 10 cpu sal verbruik, sal die skeduleerder nie toelaat dat dit gedoen word nie en sal 'n fout uitreik:
Error creating: pods "nginx-proxy-9967d8d78-nh4fs" is forbidden: exceeded quota: resource-quota, requested: limits.cpu=5,requests.cpu=5, used: limits.cpu=77250m,requests.cpu=53850m, limited: limits.cpu=10,requests.cpu=10Om 'n soortgelyke probleem op te los, kan jy 'n instrument skryf, byvoorbeeld, as , wat die toestand van bevelhulpbronne kan stoor en pleeg.
2. Kies die beste lêerberging
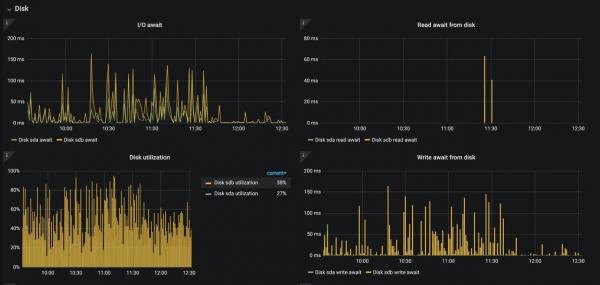
Hier wil ek graag die onderwerp van aanhoudende volumes en die skyfsubstelsel van Kubernetes-werkknooppunte aanraak. Ek hoop dat niemand die "Cube" op die HDD in produksie gebruik nie, maar soms is selfs 'n gewone SSD reeds nie genoeg nie. Ons het so 'n probleem gehad dat die logs die skyf doodmaak deur I / O-operasies, en daar is nie baie oplossings hier nie:
Gebruik hoëprestasie-SSD's of skakel oor na NVMe (as jy jou eie hardeware bestuur).
Verlaag die vlak van aanteken.
Doen "slim" balansering van peule wat die skyf verkrag (
podAntiAffinity).
Die skermkiekie hierbo wys wat onder nginx-ingress-controller met 'n skyf gebeur wanneer toegangslogs geaktiveer is (~ 12k logs/sek). So 'n toestand kan natuurlik lei tot die agteruitgang van alle toepassings op hierdie nodus.
Wat PV betref, helaas, ek het nie alles probeer nie. Aanhoudende volumes. Gebruik die beste opsie wat jou pas. Dit het histories in ons land gebeur dat 'n klein deel van dienste RWX-volumes benodig, en lank gelede het hulle NFS-berging vir hierdie taak begin gebruik. Goedkoop en ... genoeg. Natuurlik het ons saam met hom kak geëet – wees gesond, maar ons het geleer hoe om hom te tune, en sy kop is nie meer seer nie. En indien moontlik, skakel oor na S3-voorwerpberging.
3. Bou geoptimaliseerde beelde

Dit is die beste om houer-geoptimaliseerde beelde te gebruik sodat Kubernetes dit vinniger kan haal en meer doeltreffend kan uitvoer.
Optimalisering beteken dat beelde:
bevat slegs een toepassing of voer slegs een funksie uit;
klein grootte, omdat groot beelde erger oor die netwerk versend word;
gesondheids- en gereedheidseindpunte hê wat Kubernetes kan gebruik om aksie te neem in die geval van stilstand;
gebruik houervriendelike bedryfstelsels (soos Alpine of CoreOS) wat meer bestand is teen konfigurasiefoute;
gebruik multi-stadium bou sodat jy slegs saamgestelde toepassings kan ontplooi en nie die meegaande bronne nie.
Daar is baie gereedskap en dienste wat jou toelaat om beelde dadelik na te gaan en te optimaliseer. Dit is belangrik om hulle altyd op datum en veilig te hou. As gevolg hiervan kry jy:
Verminderde netwerklading op die hele groepering.
Verminderde houer opstarttyd.
Kleiner grootte van u hele Docker-register.
4. Gebruik 'n DNS-kas

As ons praat oor hoë vragte, dan sonder om die DNS-stelsel van die groepering in te stel, is die lewe redelik gemeen. Eens op 'n tyd het die Kubernetes-ontwikkelaars hul kube-dns-oplossing ondersteun. Dit is ook in ons land geïmplementeer, maar hierdie sagteware het nie besonder ingeskakel nie en het nie die vereiste prestasie gelewer nie, alhoewel, dit blyk, die taak eenvoudig is. Toe verskyn coredns, waarna ons oorgeskakel het en nie hartseer geken het nie, later het dit die standaard DNS-diens in K8s geword. Op 'n stadium het ons tot 40 duisend rps na die DNS-stelsel gegroei, en hierdie oplossing was ook nie genoeg nie. Maar, deur 'n gelukkige kans, het Nodelocaldns uitgekom, oftewel node local cache, aka .
Waarom gebruik ons dit? In die kern Linux Daar is 'n fout wat, wanneer veelvuldige versoeke deur 'n Conntrack NAT oor UDP gemaak word, 'n wedlooptoestand vir inskrywings in die Conntrack-tabelle veroorsaak, en sommige verkeer deur die NAT gaan verlore (elke sprong deur die Diens is 'n NAT). Nodelocaldns los hierdie probleem op deur NAT uit te skakel en die verbinding na TCP op te gradeer vir stroomop DNS, sowel as plaaslike kasgeheue van DNS-versoeke na stroomop DNS (insluitend 'n kort 5-sekonde negatiewe kasgeheue).
5. Skaal peule horisontaal en vertikaal outomaties
Kan jy met vertroue sê dat al jou mikrodienste gereed is vir 'n twee- tot drievoudige toename in vrag? Hoe om hulpbronne behoorlik aan u toepassings toe te wys? Om 'n paar peule aan die gang te hou wat die werklading oorskry, kan oorbodig wees, en om hulle rug-aan-rug te hou, kan stilstand wees as gevolg van 'n skielike toename in verkeer na die diens. Die goue middeweg help om die spel van vermenigvuldiging te bereik soos dienste soos и .
VPA laat jou toe om die versoeke/limiete van jou houers outomaties in 'n peul te verhoog gebaseer op werklike gebruik. Hoe kan dit nuttig wees? As jy Pods het wat om een of ander rede nie horisontaal afgeskaal kan word nie (wat nie heeltemal betroubaar is nie), dan kan jy probeer om VPA te vertrou om sy hulpbronne te verander. Die kenmerk daarvan is 'n aanbevelingstelsel gebaseer op historiese en huidige data van metrieke bediener, so as jy nie versoeke/limiete outomaties wil verander nie, kan jy eenvoudig die aanbevole hulpbronne vir jou houers monitor en die instellings optimaliseer om SVE en geheue te bespaar in die cluster.
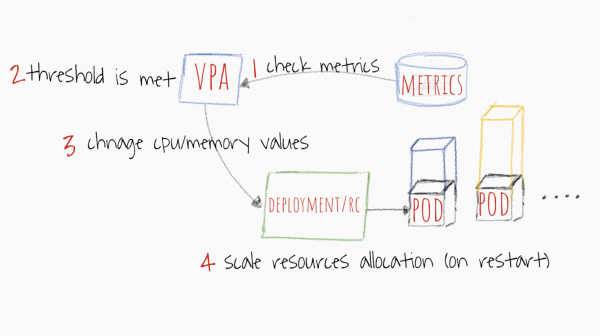 Beeld geneem vanaf https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Beeld geneem vanaf https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Die skeduleerder in Kubernetes is altyd gebaseer op versoeke. Watter waarde jy ook al daar plaas, die skeduleerder sal op grond daarvan 'n geskikte nodus soek. Die limietwaarde word deur die kublet benodig om te weet wanneer om 'n peul te versmoor of dood te maak. En aangesien die enigste belangrike parameter die versoekwaarde is, sal VPA daarmee werk. Wanneer jy jou aansoek vertikaal skaal, definieer jy wat versoeke moet wees. En wat sal dan met perke gebeur? Hierdie parameter sal ook proporsioneel afgeskaal word.
Hier is byvoorbeeld die tipiese peulinstellings:
resources:
requests:
memory: 250Mi
cpu: 200m
limits:
memory: 500Mi
cpu: 350mDie aanbevelingsenjin bepaal dat jou toepassing 300m SVE en 500Mi benodig om behoorlik te werk. Jy sal hierdie instellings kry:
resources:
requests:
memory: 500Mi
cpu: 300m
limits:
memory: 1000Mi
cpu: 525mSoos hierbo genoem, is dit proporsionele skaal gebaseer op die versoeke/limiete-verhouding in die manifes:
SVE: 200m → 300m: verhouding 1:1.75;
Geheue: 250Mi → 500Mi: 1:2 verhouding.
Met betrekking tot HPA, dan is die werkingsmeganisme meer deursigtig. Drempels word gestel vir maatstawwe soos verwerker en geheue, en as die gemiddelde van alle replikas die drempel oorskry, dan skaal die toepassing met +1 peul totdat die waarde onder die drempel val, of totdat die maksimum aantal replikas bereik is.
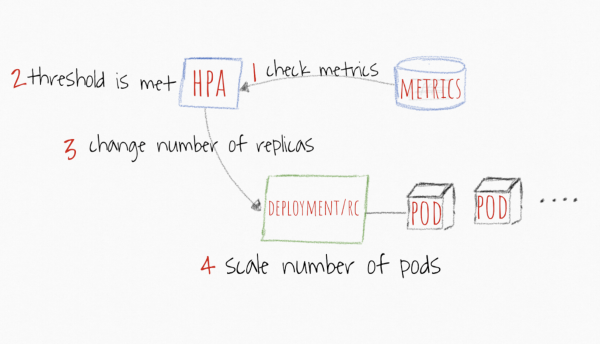 Beeld geneem vanaf https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Beeld geneem vanaf https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Benewens die gewone maatstawwe soos SVE en Geheue, kan jy drempels op jou pasgemaakte Prometheus-maatstawwe stel en daarmee werk as jy voel dit is die mees akkurate manier om te bepaal wanneer om jou toepassing te skaal. Sodra die toepassing onder die gespesifiseerde metrieke drempel stabiliseer, sal HPA begin om die peule af te skaal tot die minimum aantal replikas of totdat die vrag die gespesifiseerde drempel bereik.
6. Moenie vergeet van Node-affiniteit en Pod-affiniteit nie

Nie alle nodusse loop op dieselfde hardeware nie, en nie alle peule hoef rekenaar-intensiewe toepassings te laat loop nie. Kubernetes laat jou toe om die spesialisering van nodusse en peule te spesifiseer Node Affiniteit и Peul-affiniteit.
As jy nodusse het wat geskik is vir rekenaar-intensiewe bedrywighede, dan is dit vir maksimum doeltreffendheid beter om toepassings aan die toepaslike nodusse te bind. Om dit te doen, gebruik nodeSelector met nodus etiket.
Kom ons sê jy het twee nodusse: een met CPUType=HIGHFREQ en 'n groot aantal vinnige kerne, 'n ander met MemoryType=HIGHMEMORY meer geheue en vinniger werkverrigting. Die maklikste manier is om 'n pod-ontplooiing aan 'n nodus toe te wys HIGHFREQdeur by die afdeling by te voeg spec 'n keurder soos hierdie:
…
nodeSelector:
CPUType: HIGHFREQ'n Meer duur en spesifieke manier om dit te doen, is om te gebruik nodeAffinity in die veld affinity afdeling spec. Daar is twee opsies:
requiredDuringSchedulingIgnoredDuringExecution: harde instelling (skeduleerder sal slegs peule op spesifieke nodusse ontplooi (en nêrens anders nie));preferredDuringSchedulingIgnoredDuringExecution: sagte instelling (die skeduleerder sal probeer om na spesifieke nodusse te ontplooi, en as dit misluk, sal dit probeer om na die volgende beskikbare nodus te ontplooi).
Jy kan 'n spesifieke sintaksis spesifiseer vir die bestuur van nodus etikette, byvoorbeeld, In, NotIn, Exists, DoesNotExist, Gt of Lt. Onthou egter dat komplekse metodes in lang lyste etikette besluitneming in kritieke situasies sal vertraag. Met ander woorde, moenie te ingewikkeld maak nie.
Soos hierbo genoem, laat Kubernetes jou toe om die binding van huidige peule in te stel. Dit wil sê, jy kan sekere peule laat saamwerk met ander peule in dieselfde beskikbaarheidsone (relevant vir wolke) of nodusse.
В podAffinity velde affinity afdeling spec dieselfde velde is beskikbaar as in die geval van nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution и preferredDuringSchedulingIgnoredDuringExecution. Die enigste verskil is dit matchExpressions sal peule bind aan 'n nodus wat reeds 'n peul met daardie etiket laat loop.
Meer Kubernetes bied 'n veld podAntiAffinity, wat, in teenstelling, nie 'n peul aan 'n nodus met spesifieke peule bind nie.
Oor uitdrukkings nodeAffinity Dieselfde raad kan gegee word: probeer om die reëls eenvoudig en logies te hou, moenie die peulspesifikasie met 'n komplekse stel reëls probeer oorlaai nie. Dit is baie maklik om 'n reël te skep wat nie ooreenstem met die voorwaardes van die groepering nie, wat ekstra las op die skeduleerder plaas en algehele prestasie verneder.
7. Vlekke en verdraagsaamhede
Daar is 'n ander manier om die skeduleerder te bestuur. As jy 'n groot groep met honderde nodusse en duisende mikrodienste het, is dit baie moeilik om te verhoed dat sekere peule deur sekere nodusse gehuisves word.
Die meganisme van besoedeling - verbiedende reëls - help hiermee. U kan byvoorbeeld verhoed dat sekere nodusse in sekere scenario's peule laat loop. Gebruik die opsie om smaak op 'n spesifieke nodus toe te pas taint in kubectl. Spesifiseer sleutel en waarde en vlek dan soos NoSchedule of NoExecute:
$ kubectl taint nodes node10 node-role.kubernetes.io/ingress=true:NoScheduleDit is ook opmerklik dat die besoedelingsmeganisme drie hoofeffekte ondersteun: NoSchedule, NoExecute и PreferNoSchedule.
NoSchedulebeteken dat totdat daar 'n ooreenstemmende inskrywing in die peulspesifikasie istolerations, kan dit nie na die nodus ontplooi word nie (in hierdie voorbeeldnode10).PreferNoSchedule- vereenvoudigde weergaweNoSchedule. In hierdie geval sal die skeduleerder probeer om nie peule toe te ken wat nie 'n ooreenstemmende inskrywing het nie.tolerationsper nodus, maar dit is nie 'n harde limiet nie. As daar geen hulpbronne in die groepie is nie, sal die peule op hierdie nodus begin ontplooi.NoExecute- hierdie effek veroorsaak 'n onmiddellike ontruiming van peule wat nie 'n bypassende inskrywing het nietolerations.
Vreemd genoeg kan hierdie gedrag ongedaan gemaak word deur die tolerasiemeganisme te gebruik. Dit is gerieflik wanneer daar 'n "verbode" nodus is en jy net infrastruktuurdienste daarop moet plaas. Hoe om dit te doen? Laat slegs daardie peule toe waarvoor daar 'n geskikte verdraagsaamheid is.
Hier is hoe die peulspesifikasie sou lyk:
spec:
tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Equal"
value: "true"
effect: "NoSchedule"Dit beteken nie dat die peul tydens die volgende herontplooiing presies hierdie nodus sal tref nie, dit is nie die Node Affinity-meganisme nie en nodeSelector. Maar deur verskeie kenmerke te kombineer, kan u 'n baie buigsame skeduleerderopstelling bereik.
8. Stel Pod-ontplooiingsprioriteit
Net omdat jy pod-tot-node-bindings opgestel het, beteken dit nie dat alle peule met dieselfde prioriteit behandel moet word nie. Byvoorbeeld, jy wil dalk sommige Pods voor ander ontplooi.
Kubernetes bied verskillende maniere om Pod Prioriteit en Preemption te stel. Die instelling bestaan uit verskeie dele: voorwerp PriorityClass en veldbeskrywings priorityClassName in die peul-spesifikasie. Oorweeg 'n voorbeeld:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 99999
globalDefault: false
description: "This priority class should be used for very important pods only"Ons skep PriorityClass, gee dit 'n naam, beskrywing en waarde. Die hoër value, hoe hoër die prioriteit. Die waarde kan enige 32-bis heelgetal kleiner as of gelyk aan 1 000 000 000 wees. Hoër waardes word gereserveer vir missiekritieke stelselpeule, wat tipies nie vooruitgesien kan word nie. Die uitsetting sal slegs plaasvind as die hoë-prioriteit peul nêrens het om om te draai nie, dan sal van die peule van 'n spesifieke nodus ontruim word. As hierdie meganisme te rigied vir jou is, kan jy die opsie byvoeg preemptionPolicy: Never, en dan sal daar geen voorrang wees nie, die peul sal die eerste in die tou wees en wag vir die skeduleerder om gratis hulpbronne daarvoor te vind.
Vervolgens skep ons 'n peul waarin ons die naam spesifiseer priorityClassName:
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
priorityClassName: high-priority
Jy kan soveel prioriteitsklasse skep as wat jy wil, alhoewel dit aanbeveel word om nie hiermee meegevoer te raak nie (sê, beperk jouself tot lae, medium en hoë prioriteit).
Dus, indien nodig, kan u die doeltreffendheid van die implementering van kritieke dienste verhoog, soos nginx-ingress-controller, coredns, ens.
9. Optimaliseer jou ETCD-groepering

ETCD kan die brein van die hele groep genoem word. Dit is baie belangrik om die werking van hierdie databasis op 'n hoë vlak te handhaaf, aangesien die spoed van bedrywighede in die "Cube" daarvan afhang. 'n Redelike standaard, en terselfdertyd 'n goeie oplossing sou wees om 'n ETCD-kluster op die meesternodusse te hou om 'n minimum vertraging na kube-apiserver te hê. As dit nie moontlik is nie, plaas dan die ETCD so na as moontlik, met goeie bandwydte tussen deelnemers. Let ook op hoeveel nodusse van ETCD kan uitval sonder om die groep te benadeel.
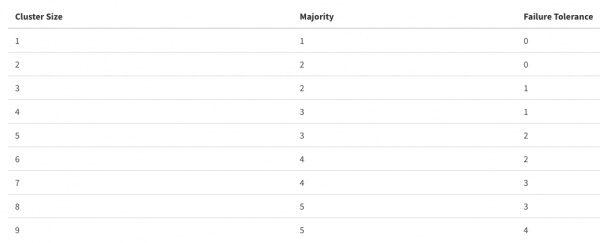
Hou in gedagte dat 'n buitensporige toename in die aantal deelnemers in die groep fouttoleransie kan verhoog ten koste van prestasie, alles moet in moderering wees.
As ons praat oor die opstel van die diens, is daar 'n paar aanbevelings:
Het goeie hardeware, gebaseer op die grootte van die groep (jy kan lees ).
Pas 'n paar parameters aan as jy 'n groep tussen 'n paar DC's versprei het of jou netwerk en skywe laat veel te wense oor (jy kan lees ).
Gevolgtrekking
Hierdie artikel beskryf die punte waaraan ons span probeer voldoen. Dit is nie 'n stap-vir-stap beskrywing van aksies nie, maar opsies wat nuttig kan wees om die bokoste van 'n groepering te optimaliseer. Dit is duidelik dat elke groepering uniek is op sy eie manier, en insteloplossings kan baie verskil, so dit sal interessant wees om terugvoer van jou te kry: hoe monitor jy jou Kubernetes-kluster, hoe verbeter jy sy werkverrigting. Deel jou ervaring in die kommentaar, dit sal interessant wees om dit te weet.
Bron: will.com
