

Ek stel voor jy lees die transkripsie van die lesing "Hadoop. ZooKeeper" uit die reeks "Metodes vir verspreide verwerking van groot volumes data in Hadoop"
Wat is ZooKeeper, sy plek in die Hadoop-ekosisteem. Onwaarhede oor verspreide rekenaars. Diagram van 'n standaardverspreide stelsel. Moeilikheid om verspreide stelsels te koördineer. Tipiese koördinasie probleme. Die beginsels agter die ontwerp van ZooKeeper. ZooKeeper-datamodel. znode vlae. Sessies. Kliënt API. Primitiewe (konfigurasie, groeplidmaatskap, eenvoudige slotte, leierverkiesing, sluiting sonder kudde-effek). ZooKeeper argitektuur. ZooKeeper DB. ZAB. Versoek hanteerder.


Vandag praat ons oor ZooKeeper. Hierdie ding is baie nuttig. Dit, soos enige Apache Hadoop-produk, het 'n logo. Dit beeld 'n man uit.
Voor dit het ons hoofsaaklik gepraat oor hoe data daar verwerk kan word, hoe om dit te stoor, dit wil sê hoe om dit op een of ander manier te gebruik en daarmee te werk. En vandag wil ek 'n bietjie praat oor die bou van verspreide toepassings. En ZooKeeper is een van daardie dinge wat jou toelaat om hierdie saak te vereenvoudig. Dit is 'n soort diens wat bedoel is vir 'n soort koördinering van die interaksie van prosesse in verspreide stelsels, in verspreide toepassings.
Die behoefte aan sulke toepassings word elke dag meer en meer, dit is waaroor ons kursus gaan. Aan die een kant laat MapReduce en hierdie klaargemaakte raamwerk jou toe om hierdie kompleksiteit gelyk te maak en die programmeerder te bevry van die skryf van primitiewe soos interaksie en koördinering van prosesse. Maar aan die ander kant waarborg niemand dat dit in elk geval nie gedoen sal moet word nie. MapReduce of ander klaargemaakte raamwerke vervang nie altyd sommige gevalle wat nie met behulp hiervan geïmplementeer kan word nie. Insluitend MapReduce self en 'n klomp ander Apache-projekte, dit is in werklikheid ook verspreide toepassings. En om skryf makliker te maak, het hulle ZooKeeper geskryf.
Soos alle Hadoop-verwante toepassings, is dit ontwikkel deur Yahoo! Dit is nou ook 'n amptelike Apache-toepassing. Dit is nie so aktief ontwikkel soos HBase nie. As jy na JIRA HBase gaan, dan is daar elke dag 'n klomp foutverslae, 'n klomp voorstelle om iets te optimaliseer, dit wil sê die lewe in die projek is voortdurend aan die gang. En ZooKeeper, aan die een kant, is 'n relatief eenvoudige produk, en aan die ander kant verseker dit die betroubaarheid daarvan. En dit is redelik maklik om te gebruik, en daarom het dit 'n standaard geword in toepassings binne die Hadoop-ekosisteem. So ek het gedink dit sal nuttig wees om dit te hersien om te verstaan hoe dit werk en hoe om dit te gebruik.
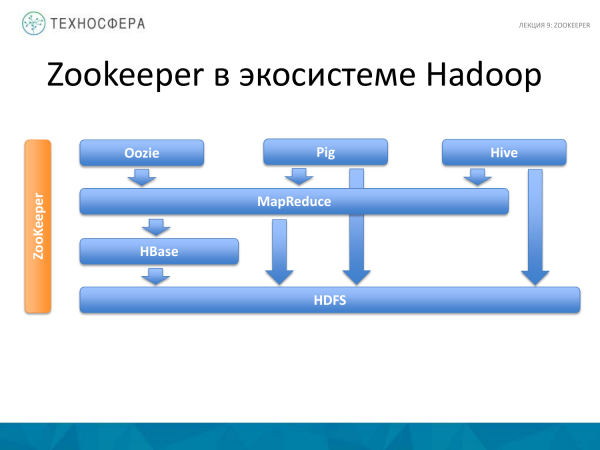
Hierdie is 'n foto van een of ander lesing wat ons gehad het. Ons kan sê dat dit ortogonaal is tot alles wat ons tot dusver oorweeg het. En alles wat hier aangedui word, werk in een of ander mate saam met ZooKeeper, dit wil sê, dit is 'n diens wat al hierdie produkte gebruik. Nóg HDFS nóg MapReduce skryf hul eie soortgelyke dienste wat spesifiek vir hulle sal werk. Gevolglik word ZooKeeper gebruik. En dit vergemaklik ontwikkeling en sommige dinge wat met foute verband hou.

Waar kom dit alles vandaan? Dit wil voorkom asof ons twee toepassings parallel op verskillende rekenaars geloods het, hulle met 'n tou of in 'n maas verbind het, en alles werk. Maar die probleem is dat die Netwerk onbetroubaar is, en as jy die verkeer gesnuif het of gekyk het na wat daar op 'n lae vlak gebeur, hoe kliënte op die Netwerk interaksie het, kan jy dikwels sien dat sommige pakkies verlore is of weer gestuur word. Dit is nie verniet dat TCP-protokolle uitgevind is nie, wat jou toelaat om 'n sekere sessie te vestig en die aflewering van boodskappe te waarborg. Maar in elk geval, selfs TCP kan jou nie altyd red nie. Alles het 'n time-out. Die netwerk kan eenvoudig vir 'n rukkie afval. Dit kan dalk net knip. En dit alles lei daartoe dat u nie daarop kan staatmaak dat die netwerk betroubaar is nie. Dit is die belangrikste verskil van die skryf van parallelle toepassings wat op een rekenaar of op een superrekenaar loop, waar daar geen Netwerk is nie, waar daar 'n meer betroubare data-uitruilbus in die geheue is. En dit is 'n fundamentele verskil.
Onder andere, wanneer die netwerk gebruik word, is daar altyd 'n sekere latency. Die skyf het dit ook, maar die Netwerk het meer daarvan. Latency is 'n mate van vertragingstyd, wat óf klein óf redelik beduidend kan wees.
Die netwerktopologie is besig om te verander. Wat is topologie - dit is die plasing van ons netwerktoerusting. Daar is datasentrums, daar is rakke wat daar staan, daar is kerse. Dit alles kan weer gekoppel word, geskuif word, ens. Dit alles moet ook in ag geneem word. IP-name verander, die roetes waardeur ons verkeer beweeg, verander. Dit moet ook in ag geneem word.
Die netwerk kan ook verander wat toerusting betref. Uit die praktyk kan ek sê dat ons netwerkingenieurs baie daarvan hou om periodiek iets op die kerse op te dateer. Skielik het 'n nuwe firmware uitgekom en hulle was nie besonder geïnteresseerd in een of ander Hadoop-kluster nie. Hulle het hul eie werk. Vir hulle is die belangrikste ding dat die netwerk werk. Gevolglik wil hulle iets weer daar oplaai, 'n flits op hul hardeware doen, en die hardeware verander ook van tyd tot tyd. Dit alles moet op een of ander manier in ag geneem word. Dit alles beïnvloed ons verspreide toepassing.
Gewoonlik glo mense wat om een of ander rede met groot hoeveelhede data begin werk dat die internet onbeperk is. As daar 'n lêer van verskeie teragrepe daar is, kan jy dit na jou bediener of rekenaar neem en dit oopmaak met behulp van kat en kyk. Nog 'n fout is in Vim kyk na die logs. Moet dit nooit doen nie, want dit is sleg. Omdat Vim alles probeer buffer, laai alles in die geheue, veral wanneer ons deur hierdie log begin beweeg en iets soek. Dit is dinge wat vergeet word, maar die moeite werd is om te oorweeg.

Dit is makliker om een program te skryf wat op een rekenaar met een verwerker loop.
Wanneer ons stelsel groei, wil ons dit alles paralleliseer, en dit nie net op 'n rekenaar paralleliseer nie, maar ook op 'n groep. Die vraag ontstaan: hoe om hierdie saak te koördineer? Ons toepassings het dalk nie eers met mekaar interaksie nie, maar ons het verskeie prosesse parallel op verskeie bedieners uitgevoer. En hoe om te monitor dat alles goed gaan met hulle? Hulle stuur byvoorbeeld iets oor die internet. Hulle moet iewers oor hul toestand skryf, byvoorbeeld in 'n soort databasis of logboek, dan hierdie log versamel en dan iewers analiseer. Boonop moet ons in ag neem dat die proses gewerk het en gewerk het, skielik het 'n fout daarin verskyn of dit het neergestort, hoe vinnig sal ons dit dan uitvind?
Dit is duidelik dat dit alles vinnig gemonitor kan word. Dit is ook goed, maar monitering is 'n beperkte ding wat jou toelaat om sekere dinge op die hoogste vlak te monitor.
Wanneer ons wil hê ons prosesse moet met mekaar begin omgaan, byvoorbeeld om vir mekaar data te stuur, dan ontstaan die vraag ook - hoe sal dit gebeur? Sal daar een of ander rastoestand wees, sal hulle mekaar oorskryf, sal die data reg aankom, sal enigiets langs die pad verlore gaan? Ons moet 'n soort protokol ontwikkel, ens.
Koördinering van al hierdie prosesse is nie 'n triviale ding nie. En dit dwing die ontwikkelaar om af te gaan na 'n selfs laer vlak, en skryf stelsels óf van nuuts af, óf nie heeltemal van nuuts af nie, maar dit is nie so eenvoudig nie.
As jy met 'n kriptografiese algoritme vorendag kom of dit selfs implementeer, gooi dit dan dadelik weg, want heel waarskynlik sal dit nie vir jou werk nie. Dit sal heel waarskynlik 'n klomp foute bevat waarvoor jy vergeet het om voorsiening te maak. Moet dit nooit vir iets ernstigs gebruik nie, want dit sal heel waarskynlik onstabiel wees. Want al die algoritmes wat bestaan, is al baie lank deur tyd getoets. Dit word deur die gemeenskap geknou. Hierdie is 'n aparte onderwerp. En dit is dieselfde hier. As dit moontlik is om nie self 'n soort prosessinchronisasie te implementeer nie, is dit beter om dit nie te doen nie, want dit is redelik ingewikkeld en lei jou op die wankelrige pad om voortdurend na foute te soek.
Vandag praat ons oor ZooKeeper. Aan die een kant is dit 'n raamwerk, aan die ander kant is dit 'n diens wat die lewe vir die ontwikkelaar makliker maak en die implementering van logika en koördinering van ons prosesse soveel as moontlik vereenvoudig.
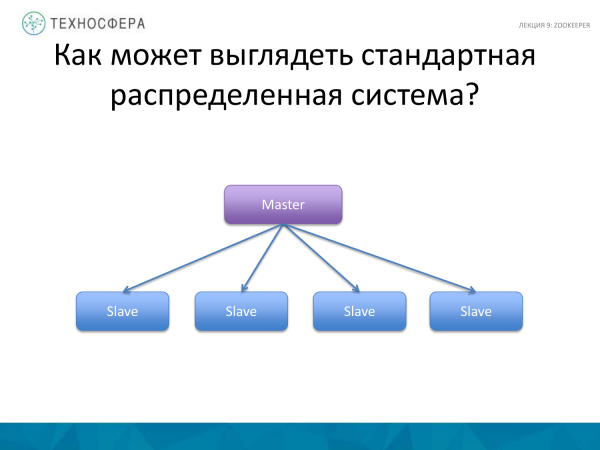
Kom ons onthou hoe 'n standaard verspreide stelsel kan lyk. Dit is waaroor ons gepraat het - HDFS, HBase. Daar is 'n Meesterproses wat werkers en slaweprosesse bestuur. Hy is verantwoordelik vir die koördinering en verspreiding van take, die herbegin van werkers, die bekendstelling van nuwes en die verspreiding van die vrag.
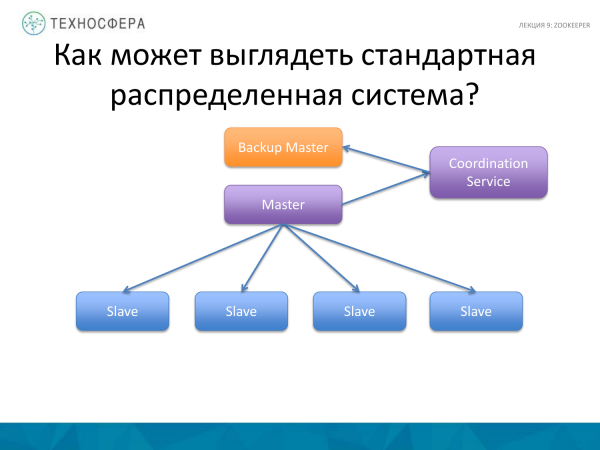
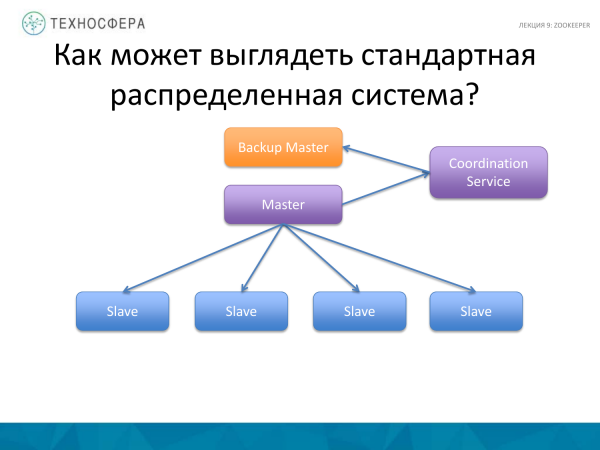
'n Meer gevorderde ding is die Koördineringsdiens, dit wil sê, skuif die koördineringstaak self na 'n aparte proses, en voer 'n soort rugsteun- of stanby-meester parallel uit, want die Meester kan misluk. En as die Meester val, dan sal ons stelsel nie werk nie. Ons hardloop rugsteun. Sommige verklaar dat die Meester na rugsteun gerepliseer moet word. Dit kan ook aan die Koördineringsdiens toevertrou word. Maar in hierdie diagram is die Meester self verantwoordelik vir die koördinering van die werkers hier is die diens besig om data-replikasie-aktiwiteite te koördineer.
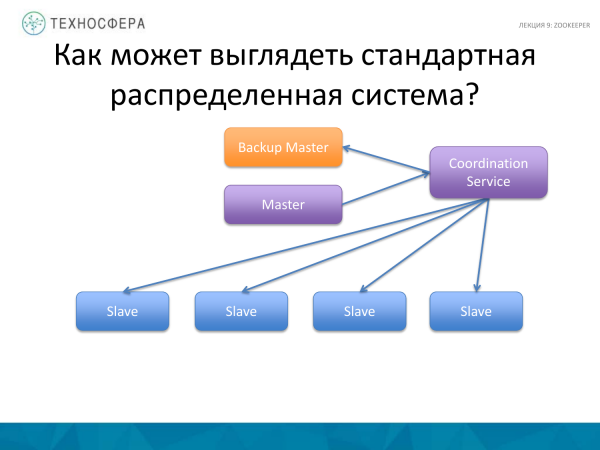
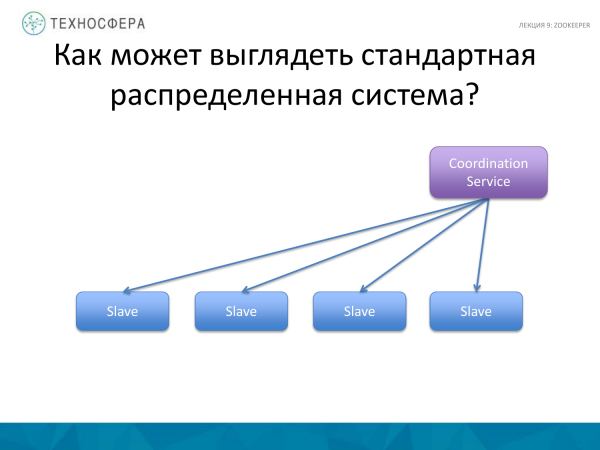
'n Meer gevorderde opsie is wanneer alle koördinasie deur ons diens hanteer word, soos gewoonlik gedoen word. Hy neem verantwoordelikheid om seker te maak alles werk. En as iets nie werk nie, vind ons dit uit en probeer om hierdie situasie te omseil. Ons sit in elk geval met 'n Meester wat op een of ander manier met slawe omgaan en data, inligting, boodskappe, ens. deur een of ander diens kan stuur.
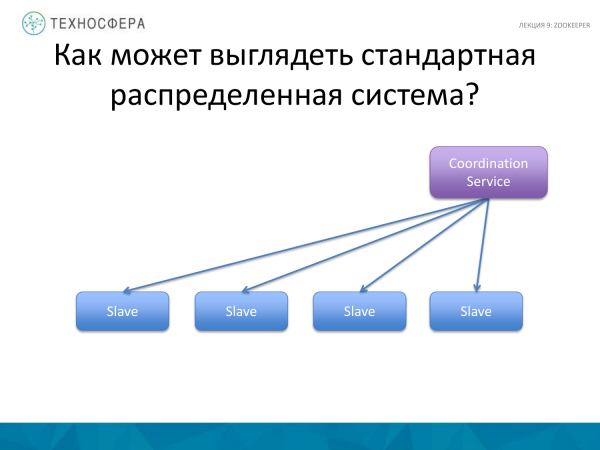
Daar is 'n selfs meer gevorderde skema, wanneer ons nie 'n Meester het nie, is alle nodusse meesterslawe, verskillend in hul gedrag. Maar hulle moet steeds met mekaar omgaan, so daar is nog 'n diens oor om hierdie aksies te koördineer. Waarskynlik, Cassandra, wat op hierdie beginsel werk, pas by hierdie skema.
Dit is moeilik om te sê watter van hierdie skemas beter werk. Elkeen het sy eie voor- en nadele.
En dit is nie nodig om saam met die Meester vir sommige dinge bang te wees nie, want, soos die praktyk toon, is hy nie so vatbaar om voortdurend te dien nie. Die belangrikste ding hier is om die regte oplossing te kies om hierdie diens op 'n aparte kragtige nodus aan te bied, sodat dit genoeg hulpbronne het, sodat gebruikers, indien moontlik, nie toegang daartoe het nie, sodat hulle nie per ongeluk hierdie proses doodmaak nie. Maar terselfdertyd is dit in so 'n skema baie makliker om werkers vanuit die Meester-proses te bestuur, dit wil sê hierdie skema is eenvoudiger vanuit die oogpunt van implementering.
En hierdie skema (hierbo) is waarskynlik meer kompleks, maar meer betroubaar.

Die grootste probleem is gedeeltelike mislukkings. Byvoorbeeld, wanneer ons 'n boodskap oor die Netwerk stuur, vind 'n soort ongeluk plaas, en die een wat die boodskap gestuur het, sal nie weet of sy boodskap ontvang is en wat aan die ontvanger se kant gebeur het nie, sal nie weet of die boodskap korrek verwerk is nie , dit wil sê hy sal geen bevestiging ontvang nie.
Gevolglik moet ons hierdie situasie verwerk. En die eenvoudigste ding is om hierdie boodskap weer te stuur en te wag totdat ons 'n antwoord ontvang. In hierdie geval word dit nie in ag geneem of die toestand van die ontvanger verander het nie. Ons kan 'n boodskap stuur en dieselfde data twee keer byvoeg.
ZooKeeper bied maniere om sulke weieringe te hanteer, wat ook ons lewens makliker maak.

Soos 'n bietjie vroeër genoem, is dit soortgelyk aan die skryf van multi-draad programme, maar die belangrikste verskil is dat in verspreide toepassings wat ons op verskillende masjiene bou, die enigste manier om te kommunikeer die Netwerk is. In wese is dit 'n gedeelde-niks-argitektuur. Elke proses of diens wat op een masjien loop, het sy eie geheue, sy eie skyf, sy eie verwerker, wat dit met niemand deel nie.
As ons 'n multi-draad program op een rekenaar skryf, dan kan ons gedeelde geheue gebruik om data uit te ruil. Ons het 'n konteksskakelaar daar, prosesse kan wissel. Dit beïnvloed prestasie. Aan die een kant is daar nie so iets in die program op 'n cluster nie, maar daar is probleme met die Netwerk.

Gevolglik is die hoofprobleme wat ontstaan wanneer verspreide stelsels geskryf word, konfigurasie. Ons skryf 'n soort aansoek. As dit eenvoudig is, dan hardkodeer ons allerhande nommers in die kode, maar dit is ongerieflik, want as ons besluit dat in plaas van 'n time-out van 'n halwe sekonde ons 'n time-out van een sekonde wil hê, dan moet ons die toepassing hersaamstel en rol alles weer uit. Dit is een ding wanneer dit op een masjien is, wanneer jy dit net kan herbegin, maar as ons baie masjiene het, moet ons voortdurend alles kopieer. Ons moet probeer om die toepassing konfigureerbaar te maak.
Hier praat ons van statiese konfigurasie vir stelselprosesse. Dit is nie heeltemal nie, miskien vanuit die bedryfstelsel-oogpunt, dit kan 'n statiese konfigurasie vir ons prosesse wees, dit wil sê dit is 'n konfigurasie wat nie eenvoudig geneem en opgedateer kan word nie.
Daar is ook 'n dinamiese konfigurasie. Dit is die parameters wat ons op die vlug wil verander sodat dit daar opgetel word.
Wat is die probleem hier? Ons het die konfigurasie opgedateer, dit uitgerol, so wat? Die probleem is dalk dat ons aan die een kant die config uitgerol het, maar van die nuwe ding vergeet het, die config het daar gebly. Tweedens, terwyl ons uitrol, is die konfigurasie op sommige plekke opgedateer, maar nie op ander nie. En sommige prosesse van ons toepassing wat op een masjien loop, is herbegin met 'n nuwe konfigurasie, en iewers met 'n ou een. Dit kan daartoe lei dat ons verspreide toepassing inkonsekwent is vanuit 'n konfigurasie-perspektief. Hierdie probleem is algemeen. Vir 'n dinamiese konfigurasie is dit meer relevant omdat dit impliseer dat dit dadelik verander kan word.
Nog 'n probleem is groeplidmaatskap. Ons het altyd een of ander stel werkers, ons wil altyd weet wie van hulle leef, wie van hulle is dood. As daar 'n Meester is, dan moet hy verstaan watter werkers na kliënte herlei kan word sodat hulle berekeninge uitvoer of met data werk, en watter nie. ’n Probleem wat voortdurend opduik, is dat ons moet weet wie in ons groep werk.
Nog 'n tipiese probleem is leierverkiesings, wanneer ons wil weet wie in beheer is. Een voorbeeld is replikasie, wanneer ons 'n proses het wat skryfbewerkings ontvang en dit dan onder ander prosesse herhaal. Hy sal die leier wees, almal anders sal hom gehoorsaam, sal hom volg. Dit is nodig om 'n proses te kies sodat dit vir almal ondubbelsinnig is, sodat dit nie blyk dat twee leiers gekies word nie.
Daar is ook wedersyds uitsluitende toegang. Die probleem hier is meer kompleks. Daar is iets soos 'n mutex, wanneer jy multi-threaded programme skryf en toegang tot een of ander hulpbron wil hê, byvoorbeeld 'n geheuesel, moet beperk en uitgevoer word deur slegs een draad. Hier kan die hulpbron iets meer abstrak wees. En verskillende toepassings van verskillende nodusse van ons Netwerk behoort slegs eksklusiewe toegang tot 'n gegewe hulpbron te kry, en nie sodat almal dit kan verander of iets daar kan skryf nie. Dit is die sogenaamde slotte.
ZooKeeper laat jou toe om al hierdie probleme in een of ander mate op te los. En ek sal met voorbeelde wys hoe dit jou toelaat om dit te doen.

Daar is geen blokkerende primitiewe nie. Wanneer ons iets begin gebruik, sal hierdie primitiewe nie wag dat enige gebeurtenis plaasvind nie. Heel waarskynlik sal hierdie ding asynchroon werk, waardeur prosesse nie kan hang terwyl hulle vir iets wag nie. Dit is 'n baie nuttige ding.
Alle kliëntversoeke word in die volgorde van die algemene tou verwerk.
En kliënte het die geleentheid om kennisgewing te ontvang oor veranderinge in een of ander staat, oor veranderinge in data, voordat die kliënt die veranderde data self sien.

ZooKeeper kan in twee modusse werk. Die eerste is alleenstaande, op 'n enkele nodus. Dit is gerieflik vir toetsing. Dit kan ook in trosmodus werk, op enige aantal nodusse. bedienersAs ons 'n 100-masjiengroep het, hoef dit nie noodwendig op 100 masjiene te loop nie. Dit is genoeg om 'n paar masjiene toe te ken waar ZooKeeper kan loop. En dit hou by die beginsel van hoë beskikbaarheid. ZooKeeper stoor 'n volledige kopie van die data op elke lopende instansie. Ek sal later verduidelik hoe dit dit doen. Dit versnipper of partisioneer nie die data nie. Aan die een kant is dit 'n nadeel, want ons kan nie veel stoor nie, maar aan die ander kant is dit onnodig. Dit is nie daarvoor ontwerp nie; dit is nie 'n databasis nie.
Data kan aan die kliëntkant gekas word. Dit is 'n standaardbeginsel sodat ons nie die diens onderbreek nie en dit nie met dieselfde versoeke laai nie. 'n Slim kliënt weet gewoonlik hiervan en kas dit.
Iets het byvoorbeeld hier verander. Daar is 'n soort toepassing. 'n Nuwe leier is verkies, wat byvoorbeeld verantwoordelik is vir die verwerking van skryfbedrywighede. En ons wil die data herhaal. Een oplossing is om dit in 'n lus te plaas. En ons bevraagteken voortdurend ons diens – het iets verander? Die tweede opsie is meer optimaal. Dit is 'n horlosiemeganisme wat jou toelaat om kliënte in kennis te stel dat iets verander het. Dit is 'n goedkoper metode in terme van hulpbronne en geriefliker vir kliënte.

Kliënt is die gebruiker wat ZooKeeper gebruik.
Bediener is die ZooKeeper-proses self.
Znode is die sleutel ding in ZooKeeper. Alle znodes word in die geheue gestoor deur ZooKeeper en is georganiseer in die vorm van 'n hiërargiese diagram, in die vorm van 'n boom.
Daar is twee tipes operasies. Die eerste is dateer/skryf, wanneer een of ander operasie die toestand van ons boom verander. Die boom is algemeen.
En dit is moontlik dat die kliënt nie een versoek voltooi nie en ontkoppel word, maar 'n sessie kan vestig waardeur dit met ZooKeeper interaksie het.

ZooKeeper se datamodel lyk soos 'n lêerstelsel. Daar is 'n standaard wortel en dan het ons gegaan asof deur die gidse wat van die wortel af gaan. En dan die katalogus van die eerste vlak, tweede vlak. Dit is alles znodes.
Elke znode kan sommige data stoor, gewoonlik nie baie groot nie, byvoorbeeld 10 kilogrepe. En elke znode kan 'n sekere aantal kinders hê.

Znodes kom in verskeie tipes voor. Hulle kan geskep word. En wanneer ons 'n znode skep, spesifiseer ons die tipe waaraan dit behoort te behoort.
Daar is twee tipes. Die eerste is die kortstondige vlag. Znode leef binne 'n sessie. Die kliënt het byvoorbeeld 'n sessie gevestig. En solank hierdie sessie lewendig is, sal dit bestaan. Dit is nodig om nie iets onnodig te produseer nie. Dit is ook geskik vir oomblikke wanneer dit vir ons belangrik is om dataprimitiewe binne 'n sessie te stoor.
Die tweede tipe is opeenvolgende vlag. Dit verhoog die teller op pad na die znode. Ons het byvoorbeeld 'n gids gehad met toepassing 1_5. En toe ons die eerste nodus geskep het, het dit p_1 ontvang, die tweede - p_2. En wanneer ons hierdie metode elke keer noem, gaan ons die volle pad verby, wat slegs 'n deel van die pad aandui, en hierdie nommer word outomaties verhoog omdat ons die nodustipe aandui - opeenvolgend.
Gereelde znode. Sy sal altyd lewe en die naam hê wat ons haar vertel.

Nog 'n nuttige ding is die horlosievlag. As ons dit installeer, kan die kliënt inteken op sommige gebeurtenisse vir 'n spesifieke nodus. Ek sal jou later met 'n voorbeeld wys hoe dit gedoen word. ZooKeeper stel self die kliënt in kennis dat die data op die nodus verander het. Kennisgewings waarborg egter nie dat sommige nuwe data aangekom het nie. Hulle sê bloot iets het verander, so jy moet nog data later met aparte oproepe vergelyk.
En soos ek reeds gesê het, die volgorde van die data word bepaal deur kilogrepe. Dit is nie nodig om groot teksdata daar te stoor nie, want dit is nie 'n databasis nie, dit is 'n aksiekoördinasiebediener.

Laat ek jou 'n bietjie oor sessies vertel. As ons verskeie bedieners het, kan ons deursigtig van een bediener na 'n ander oorskakel. bediener, deur die sessie-ID te gebruik. Dit is nogal gerieflik.
Elke sessie het 'n soort time-out. 'n Sessie word gedefinieer deur of die kliënt iets na die bediener stuur tydens daardie sessie. As hy niks tydens die uitteltyd versend het nie, val die sessie af, of die kliënt kan dit self sluit.

Dit het nie soveel kenmerke nie, maar jy kan verskillende dinge met hierdie API doen. Die oproep wat ons gesien het skep 'n znode en neem drie parameters. Dit is die pad na die znode, en dit moet volledig vanaf die wortel gespesifiseer word. En dit is ook 'n paar data wat ons daarheen wil oordra. En die tipe vlag. En na die skepping gee dit die pad terug na die znode.
Tweedens kan jy dit uitvee. Die truuk hier is dat die tweede parameter, benewens die pad na die znode, die weergawe kan spesifiseer. Gevolglik sal daardie znode uitgevee word as sy weergawe wat ons oorgedra het gelykstaande is aan die een wat werklik bestaan.
As ons nie hierdie weergawe wil nagaan nie, slaag ons eenvoudig die "-1" argument.

Derdens, dit kyk na die bestaan van 'n znode. Wys waar as die nodus bestaan, anders vals.
En dan verskyn vlaghorlosie, wat jou toelaat om hierdie nodus te monitor.
Jy kan hierdie vlag selfs op 'n nie-bestaande nodus stel en 'n kennisgewing ontvang wanneer dit verskyn. Dit kan ook nuttig wees.
Nog 'n paar uitdagings is kry Data. Dit is duidelik dat ons data via znode kan ontvang. Jy kan ook vlaghorlosie gebruik. In hierdie geval sal dit nie installeer as daar geen nodus is nie. Daarom moet jy verstaan dat dit bestaan, en dan data ontvang.

Daar is ook Stel Data. Hier gee ons weergawe. En as ons dit deurgee, sal die data op die znode van 'n sekere weergawe opgedateer word.
Jy kan ook "-1" spesifiseer om hierdie tjek uit te sluit.
Nog 'n nuttige metode is kry Kinders. Ons kan ook 'n lys kry van alle znodes wat daaraan behoort. Ons kan dit monitor deur vlagwag te stel.
En metode sync laat toe dat alle veranderinge gelyktydig gestuur word, om sodoende te verseker dat hulle gestoor word en alle data heeltemal verander is.
As ons analogieë met gereelde programmering teken, dan wanneer jy metodes soos skryf gebruik, wat iets op skyf skryf, en nadat dit 'n antwoord aan jou teruggestuur het, is daar geen waarborg dat jy die data op skyf geskryf het nie. En selfs wanneer die bedryfstelsel vol vertroue is dat alles geskryf is, is daar meganismes in die skyf self waar die proses deur lae buffers gaan, en eers daarna word die data op die skyf geplaas.

Meestal word asynchrone oproepe gebruik. Dit laat die kliënt toe om parallel met verskillende versoeke te werk. Jy kan die sinchrone benadering gebruik, maar dit is minder produktief.
Die twee bewerkings waaroor ons gepraat het, is opdateer/skryf, wat data verander. Dit is create, setData, sync, delete. En lees is bestaan, getData, getChildren.
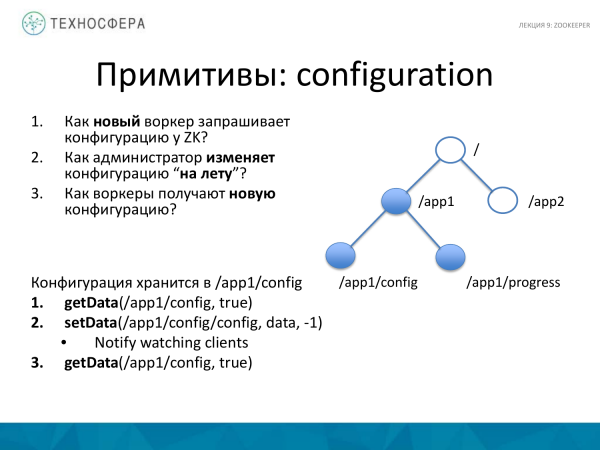
Nou 'n paar voorbeelde van hoe jy primitiewe kan maak om in 'n verspreide stelsel te werk. Byvoorbeeld, wat verband hou met die konfigurasie van iets. 'n Nuwe werker het verskyn. Ons het die masjien bygevoeg en die proses begin. En daar is die volgende drie vrae. Hoe vra dit ZooKeeper vir konfigurasie? En as ons die konfigurasie wil verander, hoe verander ons dit? En nadat ons dit verander het, hoe kry daardie werkers wat ons gehad het dit?
ZooKeeper maak dit relatief maklik. Byvoorbeeld, daar is ons znode boom. Daar is 'n knooppunt vir ons toepassing hier, ons skep 'n bykomende knoop daarin, wat data van die konfigurasie bevat. Dit mag of nie afsonderlike parameters wees nie. Aangesien die grootte klein is, is die konfigurasiegrootte gewoonlik ook klein, so dit is heel moontlik om dit hier te stoor.
Jy gebruik die metode kry Data om die konfigurasie vir die werker van die nodus af te kry. Stel op waar. As hierdie nodus om een of ander rede nie bestaan nie, sal ons daaroor ingelig word wanneer dit verskyn, of wanneer dit verander. As ons wil weet dat iets verander het, dan stel ons dit waar. En as die data in hierdie nodus verander, sal ons daarvan weet.
Stel Data. Ons stel die data, stel "-1", dit wil sê ons kontroleer nie die weergawe nie, ons neem aan dat ons altyd een konfigurasie het, ons hoef nie baie konfigurasies te stoor nie. As jy baie moet stoor, sal jy nog 'n vlak moet byvoeg. Hier glo ons dat daar net een is, so ons werk net die nuutste een op, so ons kyk nie na die weergawe nie. Op hierdie oomblik ontvang alle kliënte wat voorheen ingeteken het 'n kennisgewing dat iets in hierdie nodus verander het. En nadat hulle dit ontvang het, moet hulle ook weer die data aanvra. Die kennisgewing is dat hulle nie die data self ontvang nie, maar slegs kennisgewing van veranderinge. Hierna moet hulle vir nuwe data vra.
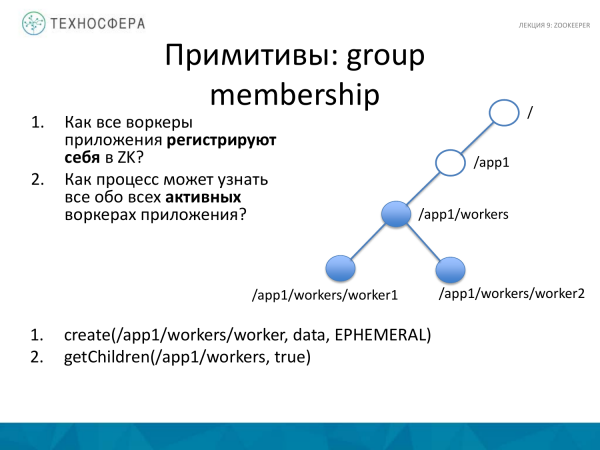
Die tweede opsie vir die gebruik van die primitiewe is groep lidmaatskap. Ons het 'n verspreide toepassing, daar is 'n klomp werkers en ons wil verstaan dat hulle almal in plek is. Daarom moet hulle self registreer dat hulle werk in ons aansoek. En ons wil ook uitvind, hetsy uit die Meester-proses of iewers anders, van al die aktiewe werkers wat ons tans het.
Hoe doen ons dit? Vir die toepassing skep ons 'n werkersnodus en voeg 'n subvlak daar by met behulp van die skepmetode. Ek het 'n fout op die skyfie. Hier het jy nodig opeenvolgend spesifiseer, dan sal alle werkers een vir een geskep word. En die toepassing, wat alle data oor die kinders van hierdie nodus versoek, ontvang al die aktiewe werkers wat bestaan.
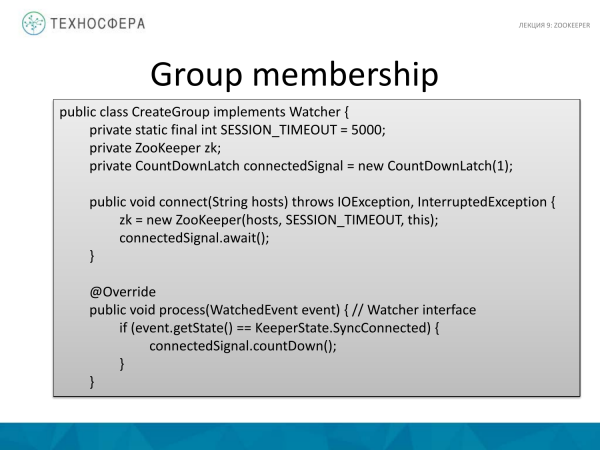

Dit is so 'n verskriklike implementering van hoe dit in Java-kode gedoen kan word. Kom ons begin van die einde af, met die hoofmetode. Dit is ons klas, kom ons skep sy metode. As die eerste argument gebruik ons gasheer, waar ons verbind, dit wil sê ons stel dit as 'n argument. En die tweede argument is die naam van die groep.
Hoe vind die verbinding plaas? Dit is 'n eenvoudige voorbeeld van die API wat gebruik word. Alles is relatief eenvoudig hier. Daar is 'n standaardklas ZooKeeper. Ons gee gashere daaraan. En stel die uitteltyd, byvoorbeeld, op 5 sekondes. En ons het 'n lid genaamd connectedSignal. In wese skep ons 'n groep langs die oorgedra pad. Ons skryf nie data daar nie, alhoewel iets geskryf kon gewees het. En die nodus hier is van die aanhoudende tipe. In wese is dit 'n gewone gereelde nodus wat heeltyd sal bestaan. Dit is waar die sessie geskep word. Dit is die implementering van die kliënt self. Ons kliënt sal periodieke boodskappe stuur wat aandui dat die sessie lewendig is. En wanneer ons die sessie beëindig, roep ons naby en dis dit, die sessie val af. Dit is ingeval iets vir ons afval, sodat ZooKeeper daarvan uitvind en die sessie afsny.
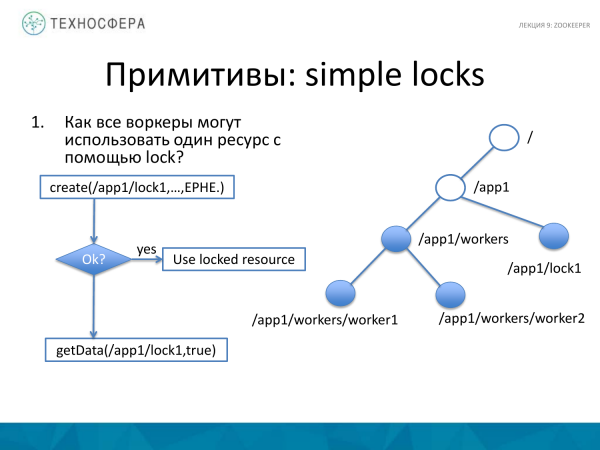
Hoe om 'n hulpbron te sluit? Hier is alles 'n bietjie meer ingewikkeld. Ons het 'n stel werkers, daar is 'n hulpbron wat ons wil sluit. Om dit te doen, skep ons 'n aparte nodus, byvoorbeeld, genaamd lock1. As ons dit kon skep, dan het ons 'n slot hier gekry. En as ons dit nie kon skep nie, dan probeer die werker om Data van hier af te kry, en aangesien die nodus reeds geskep is, dan plaas ons 'n waarnemer hier en die oomblik wat die toestand van hierdie nodus verander, sal ons daarvan weet. En ons kan probeer om tyd te hê om dit te herskep. As ons hierdie node weggeneem het, hierdie slot weggeneem het, sal ons dit laat vaar nadat ons nie meer die slot nodig het nie, aangesien die node slegs binne die sessie bestaan. Gevolglik sal dit verdwyn. En 'n ander kliënt, binne die raamwerk van 'n ander sessie, sal die slot op hierdie nodus kan neem, of liewer, hy sal 'n kennisgewing ontvang dat iets verander het en hy kan probeer om dit betyds te doen.
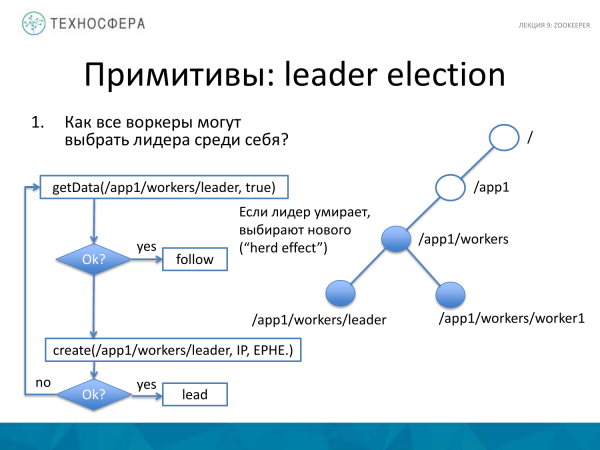
Nog 'n voorbeeld van hoe jy die hoofleier kan kies. Dit is 'n bietjie meer ingewikkeld, maar ook relatief eenvoudig. Wat gaan hier aan? Daar is 'n hoofnodus wat al die werkers saamvoeg. Ons probeer data oor die leier kry. As dit suksesvol gebeur het, dit wil sê ons het 'n paar data ontvang, dan begin ons werker hierdie leier volg. Hy glo daar is reeds 'n leier.
As die leier om een of ander rede gesterf het, byvoorbeeld, afgeval het, dan probeer ons om 'n nuwe leier te skep. En as ons daarin slaag, dan word ons werker die leier. En as iemand op hierdie oomblik daarin geslaag het om 'n nuwe leier te skep, dan probeer ons verstaan wie dit is en volg hom dan.
Hier ontstaan die sogenaamde kudde-effek, dit wil sê die kudde-effek, want wanneer 'n leier sterf, sal die een wat eerste in tyd is die leier word.
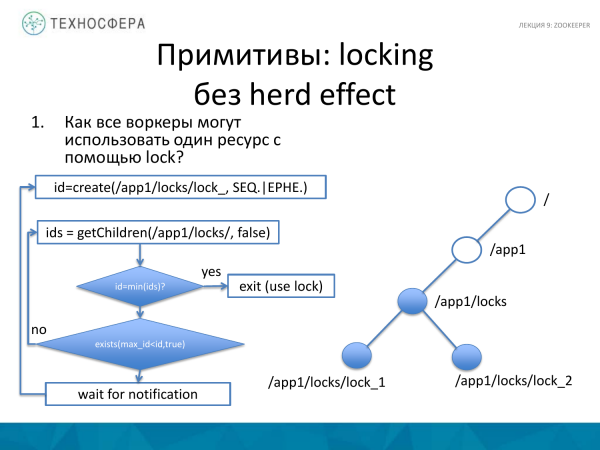
Wanneer jy 'n hulpbron vaslê, kan jy probeer om 'n effens ander benadering te gebruik, wat soos volg is. Ons wil byvoorbeeld 'n slot kry, maar sonder die hert-effek. Dit sal bestaan uit die feit dat ons toepassing lyste van alle nodus-ID's vir 'n reeds bestaande nodus met 'n slot versoek. En as voor dit die nodus waarvoor ons 'n slot geskep het, die kleinste is van die stel wat ons ontvang het, beteken dit dat ons die slot vasgevang het. Ons kyk of ons 'n slot ontvang het. As 'n tjek sal daar 'n voorwaarde wees dat die ID wat ons ontvang het toe ons 'n nuwe slot geskep het, minimaal is. En as ons dit ontvang het, dan werk ons verder.
As daar 'n sekere ID is wat kleiner is as ons slot, dan plaas ons 'n waarnemer op hierdie gebeurtenis en wag vir kennisgewing totdat iets verander. Dit wil sê, ons het hierdie slot ontvang. En totdat dit val, sal ons nie die minimum ID word nie en sal ons nie die minimum slot ontvang nie, en dus sal ons in staat wees om aan te meld. En as hierdie voorwaarde nie nagekom word nie, dan gaan ons dadelik hierheen en probeer om hierdie slot weer te kry, want iets het dalk in hierdie tyd verander.
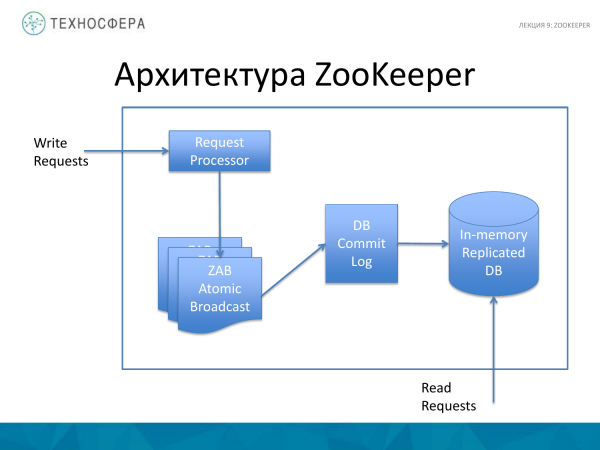
Waaruit bestaan ZooKeeper? Daar is 4 hoof dinge. Dit is die verwerking van prosesse - Versoek. En ook ZooKeeper Atomic Broadcast. Daar is 'n Commit Log waar alle bewerkings aangeteken word. En die In-memory Replicated DB self, dit wil sê die databasis self waar hierdie hele boom gestoor word.
Dit is opmerklik dat alle skryfbewerkings deur die Versoekverwerker gaan. En leesbewerkings gaan direk na die In-memory-databasis.

Die databasis self is volledig gerepliseer. Alle gevalle van ZooKeeper stoor 'n volledige kopie van die data.
Om die databasis na 'n ongeluk te herstel, is daar 'n Commit-logboek. Standaardpraktyk is dat voordat data in die geheue kom, dit daar geskryf word sodat as dit ineenstort, hierdie log teruggespeel kan word en die stelseltoestand herstel kan word. En periodieke kiekies van die databasis word ook gebruik.

ZooKeeper Atomic Broadcast is 'n ding wat gebruik word om gerepliseerde data in stand te hou.
ZAB kies intern 'n leier vanuit die oogpunt van die ZooKeeper-nodus. Ander nodusse word haar volgelinge en verwag 'n paar aksies van haar. As hulle inskrywings ontvang, stuur hulle almal aan na die leier. Hy doen eers ’n skryf-operasie en stuur dan ’n boodskap oor wat verander het aan sy volgelinge. Dit moet in werklikheid atomies uitgevoer word, d.w.s. die opname en uitsaai van die hele ding moet atomies uitgevoer word, waardeur datakonsekwentheid gewaarborg word.
 Dit verwerk slegs skryfversoeke. Sy hooftaak is dat dit die operasie in 'n transaksionele opdatering omskep. Dit is 'n spesiaal gegenereerde versoek.
Dit verwerk slegs skryfversoeke. Sy hooftaak is dat dit die operasie in 'n transaksionele opdatering omskep. Dit is 'n spesiaal gegenereerde versoek.
En hier is dit opmerklik dat die idempotensie van opdaterings vir dieselfde operasie gewaarborg is. Wat dit is? Hierdie ding, as dit twee keer uitgevoer word, sal dieselfde toestand hê, dit wil sê die versoek self sal nie verander nie. En dit moet gedoen word sodat jy in geval van 'n ongeluk die operasie kan herbegin en sodoende die veranderinge wat op die oomblik afgeval het, terugrol. In hierdie geval sal die toestand van die stelsel dieselfde word, dit wil sê dit behoort nie die geval te wees dat 'n reeks van dieselfde, byvoorbeeld opdateringsprosesse, gelei het tot verskillende finale toestande van die stelsel nie.








Bron: will.com
