

Ek ken baie Data Scientists - en ek is seker self een van hulle - wat op GPU-masjiene werk, plaaslik of virtueel, wat in die wolk geleë is, hetsy deur 'n Jupyter Notebook of deur 'n soort Python-ontwikkelingsomgewing. Ek het vir 2 jaar as 'n KI/ML-ontwikkelaardeskundige gewerk en presies dit gedoen, terwyl ek data op 'n gewone bediener of werkstasie voorberei het, en opleiding op 'n virtuele masjien met 'n GPU in Azure uitgevoer het.
Natuurlik het ons almal gehoor - 'n spesiale wolkplatform vir masjienleer. Maar na 'n eerste blik op , blyk dit dat Azure ML meer probleme vir jou sal skep as wat dit oplos. Byvoorbeeld, in die tutoriaal wat hierbo genoem word, word opleiding op Azure ML vanaf 'n Jupyter Notebook geloods, terwyl voorgestel word dat die opleidingskrip self geskep en geredigeer word as 'n tekslêer in een van die selle - terwyl dit nie outo-voltooiing, sintaksis gebruik nie uitlig, en ander voordele van 'n normale ontwikkelingsomgewing. Om hierdie rede het ons vir 'n lang tyd nie Azure ML ernstig in ons werk gebruik nie.
Ek het egter onlangs 'n manier ontdek om Azure ML effektief in my werk te begin gebruik! Stel u belang in die besonderhede?

Die belangrikste geheim is . Dit laat jou toe om opleidingsskrifte direk in VS-kode te ontwikkel en die omgewing ten volle te benut – en jy kan selfs die skrif plaaslik laat loop en dit dan eenvoudig na opleiding in 'n Azure ML-groepering stuur met 'n paar kliks. Gerieflik, is dit nie?
Deur dit te doen, kry u die volgende voordele deur Azure ML te gebruik:
- Jy kan die meeste van die tyd plaaslik op jou masjien werk in 'n gerieflike IDE, en gebruik GPU slegs vir modelopleiding. Terselfdertyd kan die poel opleidingshulpbronne outomaties aanpas by die vereiste las, en deur die minimum aantal nodusse op 0 te stel, kan u outomaties die virtuele masjien "op aanvraag" begin in die teenwoordigheid van opleidingstake.
- Jy kan stoor alle leeruitkomste op een plek, insluitend die behaalde statistieke en die gevolglike modelle - dit is nie nodig om met 'n soort stelsel of bestelling vorendag te kom om al die resultate te stoor nie.
- In hierdie geval, Veelvuldige mense kan aan dieselfde projek werk - hulle kan dieselfde rekenaargroepering gebruik, alle eksperimente sal in tou gesit word, en hulle kan ook die resultate van mekaar se eksperimente sien. Een so 'n scenario is die gebruik van Azure ML in die onderrig van Deep Learningin plaas daarvan om vir elke student 'n virtuele masjien met 'n GPU te gee, kan jy een groep skep wat deur almal sentraal gebruik sal word. Boonop kan 'n algemene tabel van resultate met modelakkuraatheid as 'n goeie mededingende element dien.
- Met Azure ML kan jy maklik 'n reeks eksperimente uitvoer, byvoorbeeld vir hiperparameter optimalisering - dit kan gedoen word met 'n paar reëls kode, dit is nie nodig om 'n reeks eksperimente met die hand uit te voer nie.
Ek hoop ek het jou oortuig om Azure ML te probeer! Hier is hoe om te begin:
- Maak seker dat u geïnstalleer het , sowel as uitbreidings и
- Kloon die bewaarplek - dit bevat 'n demo-kode vir die opleiding van 'n handgeskrewe syferherkenningsmodel op die MNIST-datastel.
- Maak die gekloonde bewaarplek in Visual Studio Code oop.
- Lees verder!
Azure ML Workspace en Azure ML Portal
Azure ML is georganiseer rondom die konsep werksarea - werkspasie. Data kan in die werkspasie gestoor word, eksperimente word daarheen gestuur vir opleiding, opleidingsresultate word ook daar gestoor - die gevolglike maatstawwe en modelle. Jy kan deur sien wat binne die werkspasie is - en van daar af kan jy baie bewerkings uitvoer, wat wissel van die laai van data tot die monitering van eksperimente en die implementering van modelle.
U kan 'n werkspasie deur die webkoppelvlak skep (Cm. ), of gebruik die Azure CLI-opdragreël ():
az extension add -n azure-cli-ml
az group create -n myazml -l northeurope
az ml workspace create -w myworkspace -g myazmlSommige word ook met die werkspasie geassosieer rekenaarhulpbronne (Bereken). Sodra jy 'n skrif geskep het om die model op te lei, kan jy stuur eksperiment vir uitvoering na die werkspasie, en spesifiseer teiken te bereken - in hierdie geval sal die skrip verpak word, in die verlangde rekenaaromgewing uitgevoer word, en dan sal al die resultate van die eksperiment in die werkspasie gestoor word vir verdere ontleding en gebruik.
Leerskrif vir MNIST
Oorweeg die klassieke probleem met behulp van die MNIST-datastel. Net so kan jy in die toekoms enige van jou opleidingsskrifte laat loop.
Daar is 'n skrif in ons bewaarplek train_local.py, wat ons die eenvoudigste lineêre regressiemodel oplei deur die SkLearn-biblioteek te gebruik. Natuurlik verstaan ek dat dit nie die beste manier is om die probleem op te los nie – ons gebruik dit as voorbeeld, as die maklikste.
Die skrip laai eers die MNIST-data van OpenML af en gebruik dan die klas LogisticRegression om die model op te lei, en druk dan die gevolglike akkuraatheid:
mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Overall accuracy:', acc)Jy kan die skrip op jou rekenaar laat loop en die resultaat binne 'n paar sekondes kry.
Begin die skrip in Azure ML
As ons die opleidingskrip deur Azure ML laat loop, sal ons twee hoofvoordele hê:
- Opleiding op 'n arbitrêre rekenaarhulpbron, wat as 'n reël meer produktief is as die plaaslike rekenaar. Terselfdertyd sal Azure ML self sorg om ons skrif met al die lêers van die huidige gids in 'n dokhouer te pak, die vereiste afhanklikhede te installeer en dit vir uitvoering te stuur.
- Skryf resultate na 'n enkele register binne 'n Azure ML-werkspasie. Om voordeel te trek uit hierdie kenmerk, moet ons 'n paar reëls kode by ons skrif voeg om die gevolglike akkuraatheid op te teken:
from azureml.core.run import Run
...
try:
run = Run.get_submitted_run()
run.log('accuracy', acc)
except:
passDie ooreenstemmende weergawe van die skrif word genoem train_universal.py (dit is 'n bietjie meer uitgeslape as wat dit hierbo geskryf is, maar nie veel nie). Hierdie skrip kan beide plaaslik en op 'n afgeleë rekenaarhulpbron uitgevoer word.
Om dit in Azure ML vanaf VS-kode te laat loop, moet jy die volgende doen:
Maak seker dat die Azure-uitbreiding aan jou intekening gekoppel is. Kies die Azure-ikoon in die kieslys aan die linkerkant. As jy nie gekoppel is nie, sal 'n kennisgewing in die onderste regterhoek verskyn (), deur te klik waarop jy deur die blaaier kan ingaan. Jy kan ook klik Ctrl-Shift-P om die VS-kode opdragreël te bel, en tik Azure Teken aan.
Daarna, in die Azure-afdeling (ikoon aan die linkerkant), vind die afdeling MASJIENLEER:
Hier behoort jy verskillende groepe voorwerpe binne die werkspasie te sien: rekenaarhulpbronne, eksperimente, ens.
- Gaan na die lys van lêers, regskliek op die skrif
train_universal.pyen kies Azure ML: Begin as eksperiment in Azure.
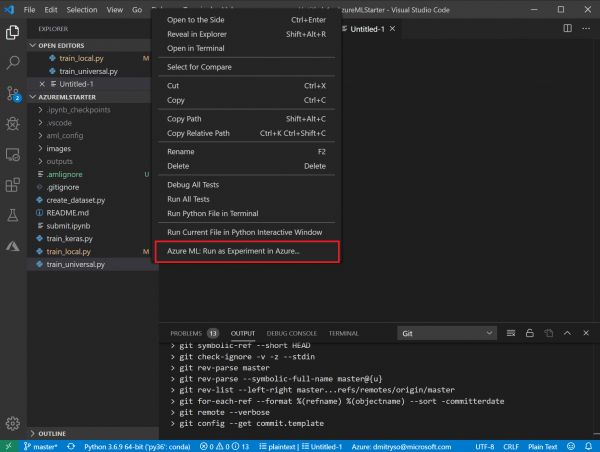
- Dit sal gevolg word deur 'n reeks dialoogvensters in die opdragreëlarea van VS-kode: bevestig die intekening en Azure ML-werkspasie wat u gebruik, en kies Skep nuwe eksperiment:



Kies om 'n nuwe rekenaarhulpbron te skep Skep nuwe rekenaar:
- Bereken bepaal die rekenaarhulpbron waarop opleiding sal plaasvind. U kan 'n plaaslike rekenaar of 'n AmlCompute-wolkkluster kies. Ek beveel aan om 'n skaalbare groep masjiene te skep
STANDARD_DS3_v2, met 'n minimum aantal masjiene van 0 (en 'n maksimum van 1 of meer, afhangende van jou aptyt). Dit kan gedoen word deur die VS-kode-koppelvlak, of voorheen deur .

- Bereken bepaal die rekenaarhulpbron waarop opleiding sal plaasvind. U kan 'n plaaslike rekenaar of 'n AmlCompute-wolkkluster kies. Ek beveel aan om 'n skaalbare groep masjiene te skep
Vervolgens moet u 'n konfigurasie kies Bereken konfigurasie, wat die parameters definieer van die houer wat vir opleiding geskep is, veral al die nodige biblioteke. In ons geval, aangesien ons Scikit Learn gebruik, kies ons SkLeer, en bevestig dan net die voorgestelde lys biblioteke deur Enter te druk. As jy enige bykomende biblioteke gebruik, moet hulle hier gespesifiseer word.


Dit sal 'n venster oopmaak met 'n JSON-lêer wat die eksperiment beskryf. Daarin kan u sommige parameters regstel - byvoorbeeld die naam van die eksperiment. Klik daarna op die skakel Dien eksperiment in reg binne hierdie lêer:


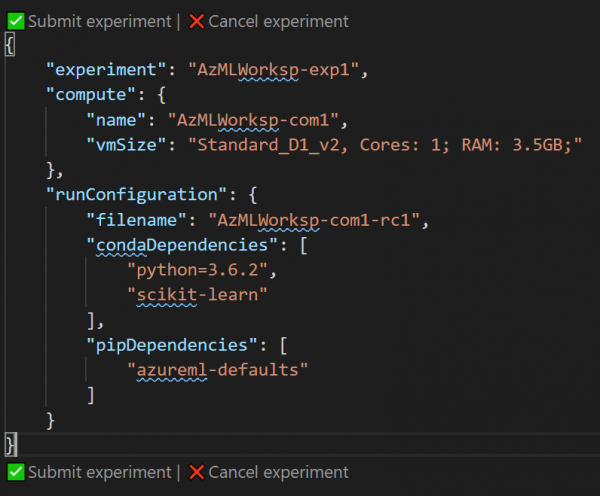
- Nadat u 'n eksperiment deur VS-kode suksesvol ingedien het, sal u aan die regterkant van die kennisgewingarea 'n skakel sien na , waar jy die status en resultate van die eksperiment kan naspoor.
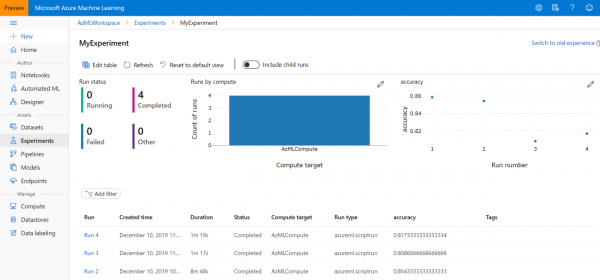
Vervolgens kan u dit altyd in die afdeling vind Eksperimente , of in die afdeling Azure-masjienleer in die lys van eksperimente:
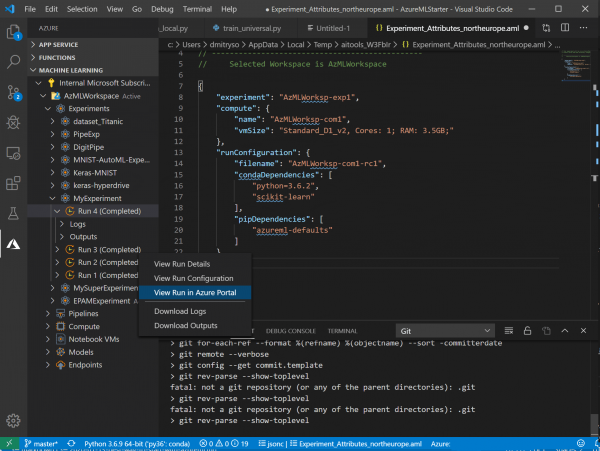
- As jy daarna 'n paar regstellings aan die kode gemaak het of die parameters verander het, sal die herbegin van die eksperiment baie vinniger en makliker wees. Deur met die rechtermuisknop op 'n lêer te klik, sal jy 'n nuwe menu-item sien Herhaal laaste lopie - kies dit net, en die eksperiment sal dadelik begin:
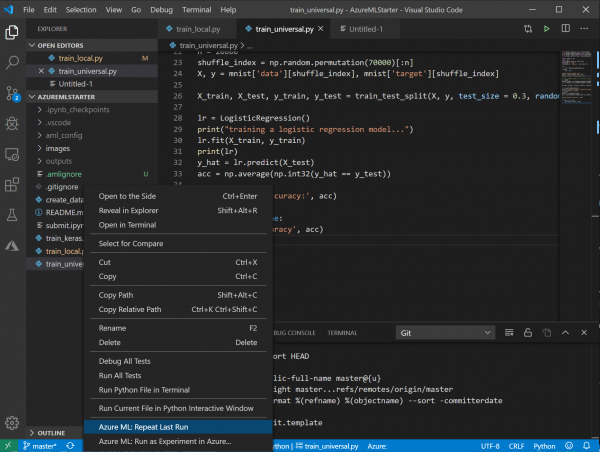
U kan altyd die resultate van statistieke van alle bekendstellings op die Azure ML Portal vind, dit hoef nie neer te skryf nie.
Nou weet jy dat die uitvoer van eksperimente met Azure ML eenvoudig en pynloos is, en jy kry 'n aantal goeie voordele om dit te doen.
Maar jy kan ook die nadele sien. Dit het byvoorbeeld aansienlik langer geneem om die skrip te laat loop. Natuurlik neem dit tyd om die skrip in 'n houer te verpak en dit op die bediener te ontplooi. As die groep terselfdertyd tot 'n grootte van 0 nodusse gesny is, sal dit selfs meer tyd neem om die virtuele masjien te begin, en dit alles is baie opvallend wanneer ons eksperimenteer op eenvoudige take soos MNIST, wat binne 'n paar sekondes opgelos word . In die werklike lewe, wanneer opleiding etlike ure, of selfs dae of weke duur, word hierdie bykomende tyd egter onbeduidend, veral teen die agtergrond van die baie hoër werkverrigting wat 'n rekenaarkluster kan lewer.
Wat is volgende?
Ek hoop dat u, nadat u hierdie artikel gelees het, Azure ML in u werk kan en sal gebruik om skrifte uit te voer, rekenaarhulpbronne te bestuur en resultate sentraal te stoor. Azure ML kan jou egter nog meer voordele gee!
Binne die werkspasie kan jy data stoor en sodoende 'n gesentraliseerde bewaarplek vir al jou take skep, wat maklik is om toegang te verkry. Boonop kan u eksperimente uitvoer nie vanaf Visual Studio Code nie, maar deur die API te gebruik - dit kan veral nuttig wees as u hiperparameteroptimalisering moet uitvoer en die skrip baie keer met verskillende parameters moet hardloop. Boonop is spesiale tegnologie in Azure ML ingebou , wat jou toelaat om meer moeilike soektogte en optimalisering van hiperparameters te doen. Ek sal in my volgende pos oor hierdie moontlikhede praat.
Nuttige hulpbronne
Om meer te wete te kom oor Azure ML, kan u die volgende Microsoft Learn-kursusse nuttig vind:
Bron: will.com
