

Verby is die dae toe jy nie hoef te bekommer oor die optimalisering van databasiswerkverrigting nie. Tyd staan nie stil nie. Elke nuwe tegnologie-entrepreneur wil die volgende Facebook skep, terwyl hulle probeer om al die data te versamel wat hulle in die hande kan kry. Besighede het hierdie data nodig om modelle beter op te lei wat hulle help om geld te maak. In sulke omstandighede moet programmeerders API's skep wat hulle in staat stel om vinnig en betroubaar met groot hoeveelhede inligting te werk.
As jy al vir 'n geruime tyd toepassings- of databasis-agtergronde ontwerp het, het jy waarskynlik kode geskryf om gepagineerde navrae uit te voer. Byvoorbeeld, soos volg:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Hoe dit is?
Maar as dit is hoe jy jou paginering gedoen het, is ek jammer om te sê dat jy dit nie op die mees doeltreffende manier gedoen het nie.
Wil jy teen my beswaar maak? . , и Hulle gebruik reeds die tegnieke waaroor ek vandag wil praat.
Noem ten minste een backend-ontwikkelaar wat nog nooit gebruik het nie OFFSET и LIMIT gepagineerde navrae uit te voer. In MVP (Minimum Viable Product) en in projekte waar klein hoeveelhede data gebruik word, is hierdie benadering baie toepaslik. Dit "werk net", so te sê.
Maar as jy van nuuts af betroubare en doeltreffende stelsels moet skep, moet jy vooraf sorg vir die doeltreffendheid om navraag te doen na die databasisse wat in sulke stelsels gebruik word.
Vandag sal ons praat oor die probleme met algemeen gebruikte (te slegte) implementerings van gepagineerde navraag-enjins, en hoe om hoë werkverrigting te bereik wanneer sulke navrae uitgevoer word.
Wat is fout met OFFSET en LIMIT?
Soos reeds gesê, OFFSET и LIMIT Hulle presteer goed in projekte wat nie met groot hoeveelhede data hoef te werk nie.
Die probleem ontstaan wanneer die databasis tot so 'n grootte groei dat dit nie meer in die bediener se geheue pas nie. Wanneer u egter met hierdie databasis werk, moet u gepagineerde navrae gebruik.
Vir hierdie probleem om homself te manifesteer, moet daar 'n situasie wees waarin die DBMS 'n ondoeltreffende volledige tabelskandering-operasie op elke gepagineerde navraag gebruik (terwyl invoeg- en uitveebewerkings kan voorkom, en ons het nie verouderde data nodig nie!).
Wat is 'n "voltabelskandering" (of "opeenvolgende tabelskandering", Sekwensiële skandering)? Dit is 'n operasie waartydens die DBMS opeenvolgend elke ry van die tabel lees, dit wil sê die data wat daarin vervat is, en dit nagaan vir voldoening aan 'n gegewe voorwaarde. Dit is bekend dat hierdie tipe tabelskandering die stadigste is. Die feit is dat wanneer dit uitgevoer word, baie invoer/afvoer bewerkings uitgevoer word wat die bediener se skyfsubstelsel behels. Die situasie word vererger deur die vertraging wat geassosieer word met die werk met data wat op skywe gestoor is, en die feit dat die oordrag van data van skyf na geheue 'n hulpbron-intensiewe operasie is.
Byvoorbeeld, jy het rekords van 100000000 gebruikers en jy voer 'n navraag met die konstruk OFFSET 50000000. Dit beteken dat die DBBS al hierdie rekords sal moet laai (en ons het dit nie eers nodig nie!), dit in die geheue moet plaas, en daarna, sê, 20 resultate moet neem wat in LIMIT.
Kom ons sê dit kan so lyk: "kies rye van 50000 tot 50020 van 100000". Dit wil sê, die stelsel sal eers 50000 XNUMX rye moet laai om die navraag te voltooi. Sien jy hoeveel onnodige werk sy sal moet doen?
As jy my nie glo nie, kyk na die voorbeeld wat ek geskep het met die kenmerke .
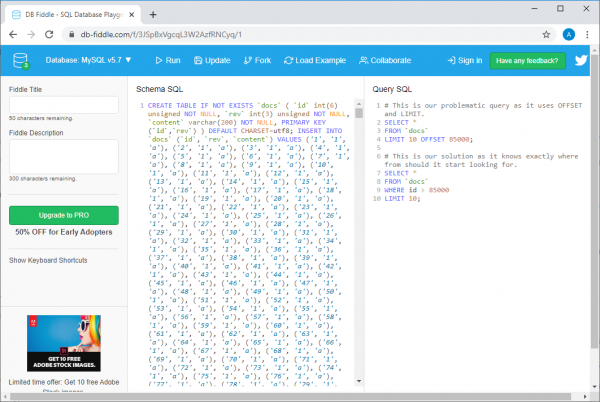
Voorbeeld by db-fiddle.com
Daar, aan die linkerkant, in die veld Schema SQL, daar is kode wat 100000 XNUMX rye in die databasis invoeg, en aan die regterkant, in die veld Query SQL, twee navrae word gewys. Die eerste, stadige een, lyk so:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
En die tweede, wat 'n effektiewe oplossing vir dieselfde probleem is, is soos volg:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Om aan hierdie versoeke te voldoen, klik net op die knoppie Run aan die bokant van die bladsy. Nadat ons dit gedoen het, vergelyk ons inligting oor die uitvoeringstyd van die navraag. Dit blyk dat die uitvoering van 'n oneffektiewe navraag minstens 30 keer langer neem as om die tweede een uit te voer (hierdie tyd verskil van lopie tot lopie; die stelsel kan byvoorbeeld rapporteer dat die eerste navraag 37 ms geneem het om te voltooi, maar die uitvoering van die sekonde - 1 ms).
En as daar meer data is, sal alles nog erger lyk (om daarvan oortuig te wees, kyk na my met 10 miljoen rye).
Wat ons sopas bespreek het, behoort jou 'n bietjie insig te gee in hoe databasisnavrae eintlik verwerk word.
Neem asseblief kennis dat hoe hoër die waarde OFFSET — hoe langer die versoek sal neem om te voltooi.
Wat moet ek gebruik in plaas van die kombinasie van OFFSET en LIMIT?
In plaas van 'n kombinasie OFFSET и LIMIT Dit is die moeite werd om 'n struktuur te gebruik wat volgens die volgende skema gebou is:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Dit is navraaguitvoering met wysergebaseerde paginering.
In plaas daarvan om huidiges plaaslik te stoor OFFSET и LIMIT en stuur dit met elke versoek, moet jy die laaste ontvangde primêre sleutel stoor (gewoonlik is dit ID) En LIMIT, gevolglik sal navrae soortgelyk aan bogenoemde verkry word.
Hoekom? Die punt is dat deur die identifiseerder van die laaste geleesde ry eksplisiet te spesifiseer, vertel jy jou DBBS waar dit moet begin soek vir die nodige data. Boonop sal die soektog, danksy die gebruik van die sleutel, doeltreffend uitgevoer word, sal die stelsel nie afgelei hoef te word deur lyne buite die gespesifiseerde reeks nie.
Kom ons kyk na die volgende prestasievergelyking van verskeie navrae. Hier is 'n ondoeltreffende navraag.
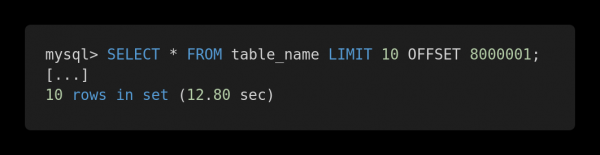
Stadige versoek
En hier is 'n geoptimaliseerde weergawe van hierdie versoek.
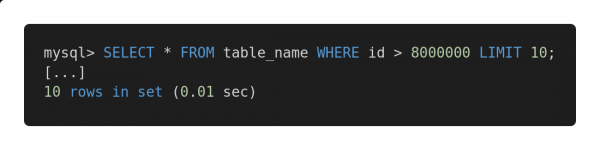
Vinnige versoek
Albei navrae gee presies dieselfde hoeveelheid data terug. Maar die eerste een neem 12,80 sekondes om te voltooi, en die tweede een neem 0,01 sekondes. Voel jy die verskil?
Moontlike probleme
Vir die voorgestelde navraagmetode om effektief te werk, moet die tabel 'n kolom (of kolomme) hê wat unieke, opeenvolgende indekse bevat, soos 'n heelgetalidentifiseerder. In sommige spesifieke gevalle kan dit die sukses van die gebruik van sulke navrae bepaal om die spoed van werk met die databasis te verhoog.
Wanneer u navrae saamstel, moet u natuurlik die spesifieke argitektuur van die tabelle in ag neem en daardie meganismes kies wat die beste op die bestaande tabelle sal werk. Byvoorbeeld, as jy in navrae met groot volumes verwante data moet werk, sal jy dit dalk interessant vind artikel.
As ons gekonfronteer word met die probleem om 'n primêre sleutel te mis, byvoorbeeld, as ons 'n tabel het met 'n baie-tot-baie-verwantskap, dan is die tradisionele benadering van gebruik OFFSET и LIMIT, is gewaarborg om ons te pas. Maar die gebruik daarvan kan potensieel stadige navrae tot gevolg hê. In sulke gevalle sal ek aanbeveel om 'n outo-inkrementerende primêre sleutel te gebruik, selfs al is dit net nodig om gepagineerde navrae te hanteer.
As jy belangstel in hierdie onderwerp - , и - verskeie nuttige materiale.
Resultate van
Die belangrikste gevolgtrekking wat ons kan maak, is dat, maak nie saak van watter grootte databasisse ons praat nie, dit altyd nodig is om die spoed van navraaguitvoering te ontleed. Deesdae is die skaalbaarheid van oplossings uiters belangrik, en as alles korrek ontwerp is vanaf die begin van die werk aan 'n sekere stelsel, kan dit in die toekoms die ontwikkelaar van baie probleme red.
Hoe ontleed en optimaliseer jy databasisnavrae?
Bron: will.com
