

Haai Habr!
Ons herinner u daaraan dat na aanleiding van die boek oor ons het 'n ewe interessante werk oor die biblioteek gepubliseer .

Vir nou leer die gemeenskap net die grense van hierdie kragtige instrument. So, 'n artikel is onlangs gepubliseer, waarvan die vertaling ons graag wil voorstel. Uit sy eie ervaring vertel die skrywer hoe om Kafka Streams in 'n verspreide databerging te verander. Lekker lees!
Apache-biblioteek wêreldwyd in ondernemings gebruik vir verspreide stroomverwerking bo-op Apache Kafka. Een van die ondergewaardeerde aspekte van hierdie raamwerk is dat dit jou toelaat om plaaslike staat geproduseer op grond van draadverwerking te stoor.
In hierdie artikel sal ek jou vertel hoe ons maatskappy dit reggekry het om hierdie geleentheid winsgewend te gebruik wanneer 'n produk vir wolktoepassingsekuriteit ontwikkel is. Met behulp van Kafka Streams het ons gedeelde staatsmikrodienste geskep, wat elkeen dien as 'n foutverdraagsame en hoogs beskikbare bron van betroubare inligting oor die toestand van voorwerpe in die stelsel. Vir ons is dit 'n stap vorentoe, beide in terme van betroubaarheid en gemak van ondersteuning.
As jy belangstel in 'n alternatiewe benadering wat jou toelaat om 'n enkele sentrale databasis te gebruik om die formele toestand van jou voorwerpe te ondersteun, lees dit, dit sal interessant wees...
Waarom ons gedink het dit is tyd om die manier waarop ons werk met gedeelde toestand te verander
Ons moes die toestand van verskeie voorwerpe in stand hou op grond van agentverslae (byvoorbeeld: was die webwerf aangeval)? Voordat ons na Kafka Streams migreer, het ons dikwels staatgemaak op 'n enkele sentrale databasis (+ diens API) vir staatsbestuur. Hierdie benadering het sy nadele: die handhawing van konsekwentheid en sinchronisasie word 'n ware uitdaging. Die databasis kan 'n bottelnek word of in beland en ly aan onvoorspelbaarheid.
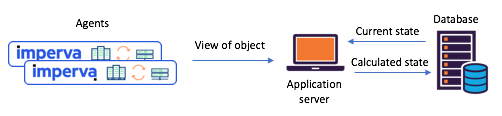
Figuur 1: 'n Tipiese gesplete toestand scenario gesien voor die oorgang na
Kafka en Kafka Streams: agente kommunikeer hul sienings via API, opgedateerde toestand word bereken deur middel van 'n sentrale databasis
Ontmoet Kafka Streams, wat dit maklik maak om gedeelde staatsmikrodienste te skep
Ongeveer 'n jaar gelede het ons besluit om ons gedeelde staatscenario's deeglik te bekyk om hierdie kwessies aan te spreek. Ons het dadelik besluit om Kafka Streams te probeer – ons weet hoe skaalbaar, hoogs beskikbaar en foutverdraagsaam dit is, watter ryk stroomfunksionaliteit dit het (transformasies, insluitend statiges). Net wat ons nodig gehad het, om nie te praat van hoe volwasse en betroubaar die boodskapstelsel in Kafka geword het nie.
Elkeen van die statige mikrodienste wat ons geskep het, is gebou op 'n Kafka Streams-instansie met 'n redelik eenvoudige topologie. Dit het bestaan uit 1) 'n bron 2) 'n verwerker met 'n aanhoudende sleutel-waarde stoor 3) 'n wasbak:
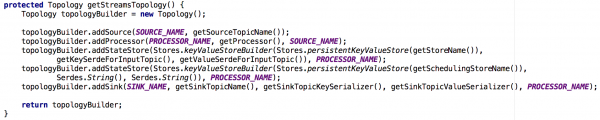
Figuur 2: Die verstektopologie van ons stroomgevalle vir stateful mikrodienste. Let daarop dat hier ook 'n bewaarplek is wat beplanningsmetadata bevat.
In hierdie nuwe benadering stel agente boodskappe saam wat in die brononderwerp ingevoer word, en verbruikers - byvoorbeeld 'n poskennisgewingdiens - ontvang die berekende gedeelde toestand deur die wasbak (afvoeronderwerp).
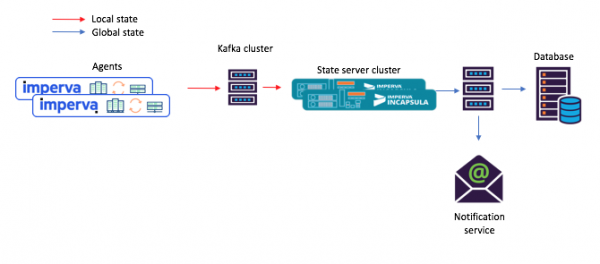
Figuur 3: Nuwe voorbeeldtaakvloei vir 'n scenario met gedeelde mikrodienste: 1) die agent genereer 'n boodskap wat by die Kafka-brononderwerp uitkom; 2) 'n mikrodiens met gedeelde toestand (met behulp van Kafka Streams) verwerk dit en skryf die berekende toestand na die finale Kafka-onderwerp; waarna 3) verbruikers die nuwe staat aanvaar
Haai, hierdie ingeboude sleutelwaardewinkel is eintlik baie nuttig!
Soos hierbo genoem, bevat ons gedeelde staatstopologie 'n sleutelwaarde-stoor. Ons het verskeie opsies gevind om dit te gebruik, en twee daarvan word hieronder beskryf.
Opsie #1: Gebruik 'n sleutelwaarde-winkel vir berekeninge
Ons eerste sleutelwaarde-stoor het die hulpdata bevat wat ons vir berekeninge benodig het. Byvoorbeeld, in sommige gevalle is die gedeelde staat bepaal deur die beginsel van "meerderheidstemme". Die bewaarplek kan al die jongste agentverslae oor die status van een of ander voorwerp bevat. Dan, wanneer ons 'n nuwe verslag van een of ander agent ontvang het, kon ons dit stoor, verslae van alle ander agente oor die toestand van dieselfde voorwerp uit berging haal en die berekening herhaal.
Figuur 4 hieronder wys hoe ons die sleutel/waarde stoor aan die verwerker se verwerkingsmetode blootgestel het sodat die nuwe boodskap dan verwerk kon word.
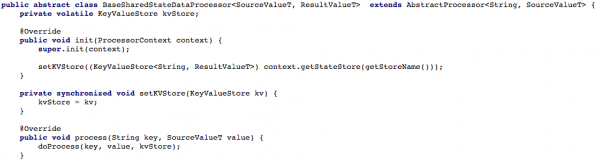
Illustrasie 4: Ons maak toegang tot die sleutelwaarde-stoor oop vir die verwerker se verwerkingsmetode (hierna moet elke skrip wat met gedeelde toestand werk die metode implementeer doProcess)
Opsie #2: Skep 'n CRUD API bo-op Kafka Streams
Nadat ons ons basiese taakvloei vasgestel het, het ons begin om 'n RESTful CRUD API vir ons gedeelde staatsmikrodienste te skryf. Ons wou in staat wees om die toestand van sommige of alle voorwerpe te herwin, asook die toestand van 'n voorwerp te stel of te verwyder (nuttig vir backend-ondersteuning).
Om alle Get State API's te ondersteun, het ons dit vir 'n lang tyd in 'n ingeboude sleutelwaarde-winkel gestoor wanneer ons die toestand tydens verwerking moes herbereken. In hierdie geval word dit redelik eenvoudig om so 'n API te implementeer met 'n enkele geval van Kafka Streams, soos in die lys hieronder getoon:
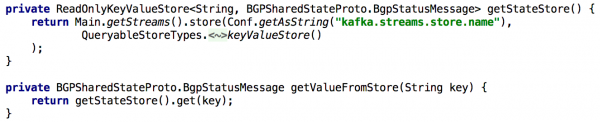
Figuur 5: Gebruik die ingeboude sleutel-waarde stoor om die voorafberekende toestand van 'n voorwerp te verkry
Die opdatering van die toestand van 'n voorwerp via die API is ook maklik om te implementeer. Basies, al wat jy hoef te doen is om 'n Kafka-vervaardiger te skep en dit te gebruik om 'n rekord te maak wat die nuwe staat bevat. Dit verseker dat alle boodskappe wat deur die API gegenereer word op dieselfde manier verwerk sal word as dié wat van ander produsente (bv. agente) ontvang word.

Figuur 6: Jy kan die toestand van 'n voorwerp stel deur die Kafka-vervaardiger te gebruik
Klein komplikasie: Kafka het baie partisies
Vervolgens wou ons die verwerkingslading versprei en beskikbaarheid verbeter deur 'n groep gedeelde staat-mikrodienste per scenario te verskaf. Opstelling was 'n briesie: sodra ons alle gevalle gekonfigureer het om onder dieselfde toepassing-ID (en dieselfde selflaai-bedieners) te loop, is byna alles anders outomaties gedoen. Ons het ook gespesifiseer dat elke brononderwerp uit verskeie partisies sal bestaan, sodat aan elke instansie 'n subset van sulke partisies toegeken kan word.
Ek sal ook noem dat dit algemene praktyk is om 'n rugsteunkopie van die staatswinkel te maak sodat, byvoorbeeld, in geval van herstel na 'n mislukking, hierdie kopie na 'n ander instansie oorgedra word. Vir elke staatswinkel in Kafka Streams word 'n gerepliseerde onderwerp geskep met 'n veranderingslogboek (wat plaaslike opdaterings naspoor). Kafka rugsteun dus voortdurend die staatswinkel. Daarom, in die geval van 'n mislukking van een of ander Kafka Streams-instansie, kan die staatswinkel vinnig op 'n ander instansie herstel word, waar die ooreenstemmende partisies sal gaan. Ons toetse het getoon dat dit binne 'n kwessie van sekondes gedoen word, selfs al is daar miljoene rekords in die winkel.
Om van 'n enkele mikrodiens met gedeelde toestand na 'n groep mikrodienste te beweeg, word dit minder triviaal om die Get State API te implementeer. In die nuwe situasie bevat die staatswinkel van elke mikrodiens slegs 'n deel van die algehele prentjie (daardie voorwerpe wie se sleutels na 'n spesifieke partisie gekarteer is). Ons moes bepaal watter instansie die toestand van die voorwerp bevat wat ons nodig gehad het, en ons het dit gedoen op grond van die draadmetadata, soos hieronder getoon:
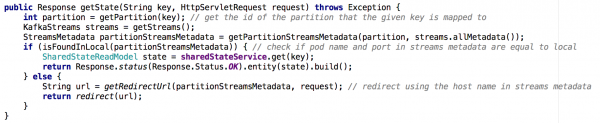
Figuur 7: Deur gebruik te maak van stroom-metadata, bepaal ons uit watter instansie om die toestand van die verlangde voorwerp te bevraagteken; 'n soortgelyke benadering is gebruik met die GET ALL API
Sleutelbevindinge
Staatswinkels in Kafka Streams kan as 'n de facto verspreide databasis dien,
- voortdurend in Kafka herhaal
- 'n CRUD API kan maklik bo-op so 'n stelsel gebou word
- Die hantering van veelvuldige partisies is 'n bietjie meer ingewikkeld
- Dit is ook moontlik om een of meer staatswinkels by die stroomtopologie te voeg om hulpdata te stoor. Hierdie opsie kan gebruik word vir:
- Langtermynberging van data wat benodig word vir berekeninge tydens stroomverwerking
- Langtermynberging van data wat nuttig kan wees die volgende keer wanneer die stroominstansie voorsien word
- baie meer...
Hierdie en ander voordele maak Kafka Streams goed geskik vir die handhawing van globale toestand in 'n verspreide stelsel soos ons s'n. Kafka Streams het bewys dat dit baie betroubaar is in produksie (ons het feitlik geen boodskapverlies gehad sedert ons dit ontplooi het nie), en ons is vol vertroue dat sy vermoëns nie daar sal stop nie!
Bron: will.com
