


'n Paar jaar gelede Kubernetes op die amptelike GitHub-blog. Sedertdien het dit die standaardtegnologie geword vir die implementering van dienste. Kubernetes bestuur nou 'n aansienlike deel van interne en openbare dienste. Namate ons groepe gegroei het en prestasievereistes strenger geword het, het ons begin agterkom dat sommige dienste op Kubernetes sporadies latensie ervaar wat nie deur die las van die toepassing self verklaar kon word nie.
In wese ervaar toepassings ewekansige netwerkvertraging van tot 100ms of meer, wat lei tot uitteltyd of herproberings. Daar word verwag dat dienste baie vinniger as 100 ms op versoeke sou kon reageer. Maar dit is onmoontlik as die verbinding self soveel tyd neem. Afsonderlik het ons baie vinnige MySQL-navrae waargeneem wat millisekondes behoort te neem, en MySQL het wel in millisekondes voltooi, maar vanuit die aansoek se perspektief het die antwoord 100 ms of meer geneem.
Dit het dadelik duidelik geword dat die probleem net voorgekom het wanneer aan 'n Kubernetes-nodus gekoppel is, selfs al het die oproep van buite Kubernetes gekom. Die maklikste manier om die probleem te reproduseer, is in 'n toets , wat vanaf enige interne gasheer loop, toets die Kubernetes-diens op 'n spesifieke poort, en registreer sporadies hoë latency. In hierdie artikel sal ons kyk hoe ons die oorsaak van hierdie probleem kon opspoor.
Uitskakeling van onnodige kompleksiteit in die ketting wat tot mislukking lei
Deur dieselfde voorbeeld weer te gee, wou ons die fokus van die probleem verklein en onnodige lae kompleksiteit verwyder. Aanvanklik was daar te veel elemente in die vloei tussen Vegeta en die Kubernetes-peule. Om 'n dieper netwerkprobleem te identifiseer, moet jy sommige van hulle uitsluit.
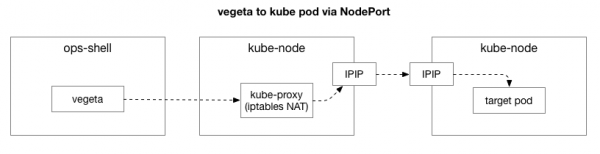
Die kliënt (Vegeta) skep 'n TCP-verbinding met enige nodus in die groep. Kubernetes werk as 'n oorlegnetwerk (bo-op die bestaande datasentrumnetwerk) wat gebruik , dit wil sê, dit omsluit die IP-pakkies van die oorlegnetwerk binne die IP-pakkies van die datasentrum. Wanneer u aan die eerste nodus koppel, word netwerkadresvertaling uitgevoer (NAT) stateful om die IP-adres en poort van die Kubernetes-nodus te vertaal na die IP-adres en poort in die oorlegnetwerk (spesifiek die pod met die toepassing). Vir inkomende pakkies word die omgekeerde volgorde van aksies uitgevoer. Dit is 'n komplekse stelsel met baie toestand en baie elemente wat voortdurend opgedateer en verander word soos dienste ontplooi en verskuif word.
Nuts tcpdump in die Vegeta-toets is daar 'n vertraging tydens die TCP-handdruk (tussen SYN en SYN-ACK). Om hierdie onnodige kompleksiteit te verwyder, kan jy gebruik hping3 vir eenvoudige "pings" met SYN-pakkies. Ons kyk of daar 'n vertraging in die antwoordpakket is, en stel dan die verbinding terug. Ons kan die data filter om net pakkies groter as 100ms in te sluit en kry 'n makliker manier om die probleem te reproduseer as Vegeta se volledige netwerk laag 7-toets. Hier is Kubernetes node "pings" met behulp van TCP SYN/SYN-ACK op die diens "node port" (30927) met 10ms intervalle, gefiltreer deur stadigste antwoorde:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 vlae=SA volgorde=1485 wen=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 vlae=SA volgorde=1486 wen=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 vlae=SA volgorde=1487 wen=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 vlae=SA volgorde=1488 wen=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 vlae=SA volgorde=5024 wen=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 vlae=SA volgorde=5231 wen=29200 rtt=109.2 ms
Kan dadelik die eerste waarneming maak. Te oordeel aan die rynommers en tydsberekeninge, is dit duidelik dat dit nie eenmalige opeenhopings is nie. Die vertraging akkumuleer dikwels en word uiteindelik verwerk.
Vervolgens wil ons uitvind watter komponente betrokke kan wees by die voorkoms van opeenhoping. Miskien is dit 'n paar van die honderde iptables-reëls in NAT? Of is daar enige probleme met IPIP tonnel op die netwerk? Een manier om dit na te gaan, is om elke stap van die stelsel te toets deur dit uit te skakel. Wat gebeur as jy NAT en firewall-logika verwyder, en net die IPIP-deel laat:
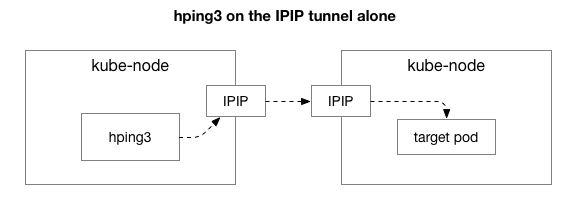
Gelukkig, Linux laat jou maklik direk toegang tot die IP-oorleglaag kry as die masjien op dieselfde netwerk is:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 vlae=RA volgorde=7346 wen=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 vlae=RA volgorde=7347 wen=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 vlae=RA volgorde=7348 wen=0 rtt=107.2 ms
Te oordeel aan die resultate bly die probleem steeds! Dit sluit iptables en NAT uit. So die probleem is TCP? Kom ons kyk hoe 'n gereelde ICMP-ping gaan:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
Die resultate toon dat die probleem nie weg is nie. Miskien is dit 'n IPIP-tonnel? Kom ons vereenvoudig die toets verder:
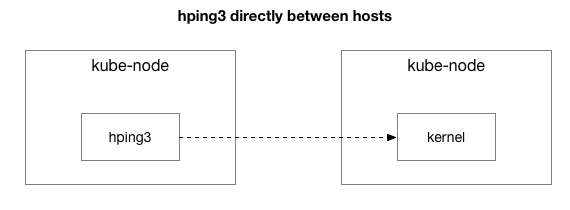
Word alle pakkies tussen hierdie twee gashere gestuur?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
Ons het die situasie vereenvoudig na twee Kubernetes-nodusse wat enige pakkie vir mekaar stuur, selfs 'n ICMP-ping. Hulle sien steeds latency as die teikengasheer "sleg" is (sommige erger as ander).
Nou die laaste vraag: hoekom vind die vertraging slegs op kube-node-bedieners plaas? En gebeur dit wanneer kube-node die sender of die ontvanger is? Gelukkig is dit ook redelik maklik om uit te vind deur 'n pakkie van 'n gasheer buite Kubernetes te stuur, maar met dieselfde "bekende slegte" ontvanger. Soos u kan sien, het die probleem nie verdwyn nie:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 vlae=RA volgorde=312 wen=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 vlae=RA volgorde=5903 wen=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 vlae=RA volgorde=6227 wen=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 vlae=RA volgorde=7929 wen=0 rtt=131.2 ms
Ons sal dan dieselfde versoeke vanaf die vorige bron-kube-node na die eksterne gasheer laat loop (wat die brongasheer uitsluit aangesien die ping beide 'n RX- en TX-komponent insluit):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Deur vertragingspakketopnames te ondersoek, het ons 'n paar bykomende inligting bekom. Spesifiek, dat die sender (onder) hierdie uitteltyd sien, maar die ontvanger (bo) nie - sien die Delta-kolom (in sekondes):
Daarbenewens, as jy kyk na die verskil in die volgorde van TCP- en ICMP-pakkies (volgens volgordenommers) aan die ontvangerkant, kom ICMP-pakkies altyd in dieselfde volgorde aan as waarin hulle gestuur is, maar met verskillende tydsberekening. Terselfdertyd interleave TCP-pakkies soms, en sommige van hulle sit vas. In die besonder, as jy die poorte van SYN-pakkies ondersoek, is hulle in orde aan die sender se kant, maar nie aan die ontvanger se kant nie.
Daar is 'n subtiele verskil in hoe moderne bedieners (soos dié in ons datasentrum) verwerk pakkies wat TCP of ICMP bevat. Wanneer 'n pakkie aankom, "hashes" die netwerkadapter dit per verbinding, dit wil sê, dit probeer om die verbindings in toue op te breek en elke tou na 'n aparte verwerkerkern te stuur. Vir TCP bevat hierdie hash beide die bron- en bestemmings-IP-adres en -poort. Met ander woorde, elke verbinding word (potensieel) anders gehas. Vir ICMP word slegs IP-adresse gehash, aangesien daar geen poorte is nie.
Nog 'n nuwe waarneming: gedurende hierdie tydperk sien ons ICMP-vertragings op alle kommunikasie tussen twee gashere, maar TCP nie. Dit sê vir ons dat die oorsaak waarskynlik verband hou met RX-tou-hashing: die opeenhoping is byna seker in die verwerking van RX-pakkies, nie in die stuur van antwoorde nie.
Dit skakel die stuur van pakkies uit die lys van moontlike oorsake uit. Ons weet nou dat die pakketverwerkingsprobleem aan die ontvangkant op sommige kube-node-bedieners is.
Verstaan pakketverwerking in die kern Linux
Om te verstaan waarom die probleem op die ontvanger op sommige kube-node-bedieners voorkom, kom ons kyk na hoe die kern Linux verwerk pakkette.
Om terug te keer na die eenvoudigste tradisionele implementering, ontvang die netwerkkaart die pakkie en stuur kern Linuxdat daar 'n pakkie is wat verwerk moet word. Die kern stop ander werk, skakel konteks oor na die onderbrekingshanterer, verwerk die pakkie en keer dan terug na die huidige taak.
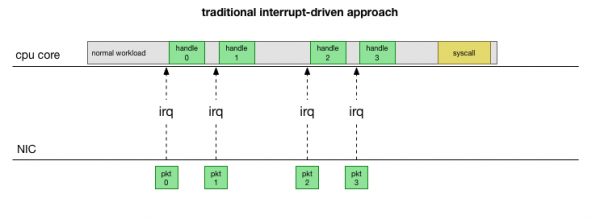
Hierdie kontekswisseling is stadig: latensie was dalk nie opmerklik op 10 Mbps netwerkkaarte in die 90's nie, maar op moderne 10G-kaarte met 'n maksimum deurset van 15 miljoen pakkies per sekonde, kan elke kern van 'n klein agtkern-bediener miljoene onderbreek word van kere per sekonde.
Om te verhoed dat ons voortdurend onderbrekings moet hanteer, baie jare gelede in Linux bygevoeg : Netwerk API wat alle moderne bestuurders gebruik om werkverrigting teen hoë spoed te verbeter. Teen lae spoed ontvang die kern steeds onderbrekings van die netwerkkaart op die ou manier. Sodra genoeg pakkies aankom wat die drempel oorskry, deaktiveer die kern onderbrekings en begin eerder om die netwerkadapter te poll en pakkies in stukke op te tel. Verwerking word uitgevoer in softirq, dit wil sê in na stelseloproepe en hardeware-onderbrekings, wanneer die kern (in teenstelling met gebruikersspasie) reeds aan die gang is.
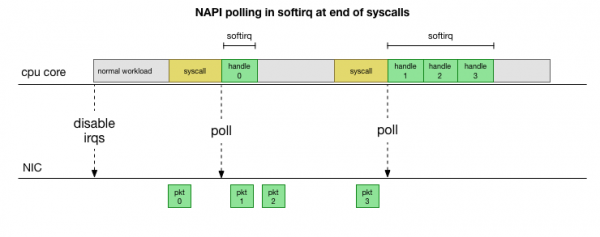
Dit is baie vinniger, maar veroorsaak 'n ander probleem. As daar te veel pakkies is, word al die tyd bestee aan die verwerking van pakkies vanaf die netwerkkaart, en gebruikersspasieprosesse het nie tyd om hierdie toue werklik leeg te maak nie (lees van TCP-verbindings, ens.). Uiteindelik word die toue vol en ons begin pakkies los. In 'n poging om 'n balans te vind, stel die kern 'n begroting op vir die maksimum aantal pakkies wat in die softirq-konteks verwerk word. Sodra hierdie begroting oorskry is, word 'n aparte draad wakker gemaak ksoftirqd (jy sal een van hulle in sien ps per kern) wat hierdie softirqs buite die normale stelsel-/onderbrekingspad hanteer. Hierdie draad is geskeduleer met behulp van die standaard proses skeduleerder, wat poog om hulpbronne regverdig toe te ken.
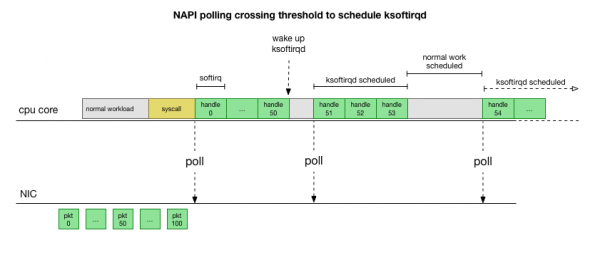
Nadat u bestudeer het hoe die kern pakkies verwerk, kan u sien dat daar 'n sekere waarskynlikheid van opeenhoping is. As softirq-oproepe minder gereeld ontvang word, sal pakkies vir 'n geruime tyd moet wag om in die RX-ry op die netwerkkaart verwerk te word. Dit kan wees as gevolg van een of ander taak wat die verwerkerkern blokkeer, of iets anders verhoed dat die kern softirq loop.
Vernou die verwerking tot die kern of metode
Softirq-vertragings is vir eers net 'n raaiskoot. Maar dit maak sin, en ons weet ons sien iets baie soortgelyks. Die volgende stap is dus om hierdie teorie te bevestig. En as dit bevestig word, vind dan die rede vir die vertragings.
Kom ons keer terug na ons stadige pakkies:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
Soos vroeër bespreek, word hierdie ICMP-pakkette in 'n enkele NIC RX-waglys gehash en deur 'n enkele SVE-kern verwerk. As ons die werking wil verstaan Linux, is dit nuttig om te weet waar (op watter SVE-kern) en hoe (softirq, ksoftirqd) hierdie pakkies verwerk word om die proses na te spoor.
Nou is dit tyd om gereedskap te gebruik wat jou toelaat om die kern se prestasie intyds te monitor. LinuxHier het ons gebruik . Hierdie stel gereedskap laat jou toe om klein C-programme te skryf wat arbitrêre funksies in die kern koppel en die gebeure buffer in 'n gebruikersruimte Python-program wat dit kan verwerk en die resultaat aan jou kan terugstuur. Om arbitrêre funksies in die kern te koppel is 'n komplekse saak, maar die hulpprogram is ontwerp vir maksimum sekuriteit en is ontwerp om presies die soort produksiekwessies op te spoor wat nie maklik in 'n toets- of ontwikkelingsomgewing gereproduseer word nie.
Die plan hier is eenvoudig: ons weet dat die kern hierdie ICMP-pings verwerk, so ons sal 'n haak aan die kernfunksie sit , wat 'n inkomende ICMP eggo versoek pakket aanvaar en inisieer die stuur van 'n ICMP eggo reaksie. Ons kan 'n pakkie identifiseer deur die icmp_seq-nommer te verhoog, wat wys hping3 hierbo.
Kode lyk ingewikkeld, maar dit is nie so skrikwekkend soos dit lyk nie. Funksie icmp_echo oordra struct sk_buff *skb: Dit is 'n pakkie met 'n "echo request". Ons kan dit opspoor, die volgorde uittrek echo.sequence (wat vergelyk met icmp_seq deur hping3 выше), en stuur dit na gebruikersspasie. Dit is ook gerieflik om die huidige proses naam/ID vas te vang. Hieronder is die resultate wat ons direk sien terwyl die kern pakkies verwerk:
TGID PID PROSES NAAM ICMP_SEQ 0 0 swapper/11 770 0 0 swapper/11 771 0 0 swapper/11 772 0 0 swapper/11 773 0 0 swapper/11 774 20041 20086 swapper 775/0 0 swapper 11 776 0 0 swapper/11 777 0 0 speke-verslag-s 11
Daar moet hier kennis geneem word dat in die konteks softirq prosesse wat stelseloproepe gemaak het, sal as "prosesse" verskyn terwyl dit in werklikheid die kern is wat pakkies veilig in die konteks van die kern verwerk.
Met hierdie instrument kan ons spesifieke prosesse assosieer met spesifieke pakkette wat 'n vertraging van toon hping3. Kom ons maak dit eenvoudig grep op hierdie vaslegging vir sekere waardes icmp_seq. Pakkies wat by die bogenoemde icmp_seq-waardes pas, is opgemerk saam met hul RTT wat ons hierbo waargeneem het (tussen hakies is die verwagte RTT-waardes vir pakkies wat ons uitgefiltreer het as gevolg van RTT-waardes minder as 50 ms):
TGID PID PROSES NAAM ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 ksoftir 11d 1954 89 ksoftir 76d ** 76d /11 1955 ** 79 ms 76 76 ksoftirqd/11 1956 ** 69 ms 76 76 ksoftirqd/11 1957 ** 59 ms 76 76 ksoftirqd/11 1958 ** (49 ms) 76 76 ksoftirqd/11 1959 ** (39 ms) 76 76 ksoftirqd (11 ms) 1960 29 ksoftirqd d / 76 76 ** (11 ms) 1961 19 ksoftirqd/76 76 ** (11 ms) -- 1962 9 cadvisor 10137 10436 2068 cadvisor 10137 10436 2069 ksoftirqd/76 ksoftirqd/76 ksoftirqd/11 ksoftirqd 2070 75 ** 76 ms 76 11 ksoftirqd/ 2071 65 ** 76 ms 76 11 ksoftirqd/2072 55 ** (76 ms) 76 11 ksoftirqd/2073 45 ** (76 ms) 76 11 ksoftirqd/2074 35 ** (76 ms) ** (76 ms) ** (11 ms) ** (2075 ms) ) 25 76 ksoftirqd/76 11 ** (2076ms)
Die resultate vertel ons verskeie dinge. Eerstens word al hierdie pakkette deur die konteks verwerk ksoftirqd/11. Dit beteken dat ICMP-pakkies vir hierdie spesifieke paar masjiene na kern 11 aan die ontvangkant verhaas is. Ons sien ook dat wanneer daar 'n jam is, daar pakkies is wat in die konteks van die stelseloproep verwerk word cadvisor... Dan ksoftirqd neem die taak oor en verwerk die opgehoopte tou: presies die aantal pakkies wat daarna opgehoop het cadvisor.
Die feit dat onmiddellik voor dit altyd werk cadvisor, impliseer sy betrokkenheid by die probleem. Ironies genoeg, die doel - "Analiseer hulpbrongebruik en prestasie-eienskappe van lopende houers" eerder as om hierdie prestasieprobleem te veroorsaak.
Soos met ander aspekte van houers, is dit almal hoogs gevorderde gereedskap en kan verwag word om prestasieprobleme te ervaar onder sommige onvoorsiene omstandighede.
Wat doen cadvisor wat die pakkettou vertraag?
Nou het ons 'n redelike goeie begrip van hoe die ineenstorting plaasvind, watter proses dit veroorsaak, en op watter SVE. Ons sien dat as gevolg van die harde sluit, die kern Linux het nie tyd om betyds te beplan nie ksoftirqd. En ons sien dat pakkies in konteks verwerk word cadvisor. Dit is logies om dit aan te neem cadvisor begin 'n stadige stelseloproep, waarna alle pakkies wat op daardie tydstip opgehoop is, verwerk word:
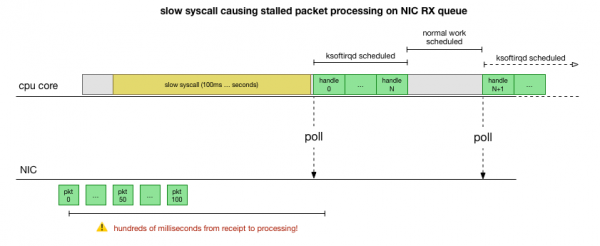
Dit is 'n teorie, maar hoe om dit te toets? Wat ons kan doen is om die SVE-kern deur hierdie proses op te spoor, die punt te vind waar die aantal pakkies oor die begroting gaan en ksoftirqd geroep word, en dan 'n bietjie verder terug te kyk om te sien wat presies op die SVE-kern geloop het net voor daardie punt . Dit is soos om die SVE elke paar millisekondes te x-straal. Dit sal so iets lyk:
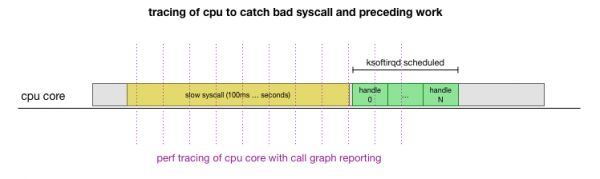
Dit alles kan gerieflik gedoen word met bestaande gereedskap. Byvoorbeeld, kontroleer 'n gegewe SVE-kern teen 'n gespesifiseerde frekwensie en kan 'n oproepgrafiek van die lopende stelsel genereer, insluitend beide gebruikersruimte en die kern LinuxJy kan hierdie rekord neem en dit verwerk met behulp van 'n klein vurk van die program. van Brendan Gregg, wat die volgorde van die stapelspoor behou. Ons kan enkellyn-stapelspore elke 1 ms stoor, en dan 'n monster uitlig en stoor 100 millisekondes voor die spoor tref ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Hier is die resultate:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Daar is baie dinge hier, maar die belangrikste ding is dat ons die "cadvisor before ksoftirqd"-patroon vind wat ons vroeër in die ICMP-spoorsnyer gesien het. Wat beteken dit?
Elke lyn is 'n SVE-spoor op 'n sekere tydstip. Elke oproep langs die stapel op 'n lyn word geskei deur 'n kommapunt. In die middel van die reëls sien ons dat die stelsel genoem word: read(): .... ;do_syscall_64;sys_read; .... So cadvisor spandeer baie tyd aan die stelsel oproep read()verband hou met funksies mem_cgroup_* (bo aan oproepstapel/einde van lyn).
Dit is ongerieflik om in 'n oproepspoor te sien wat presies gelees word, so kom ons hardloop strace en kom ons kyk wat cadvisor doen en vind stelseloproepe langer as 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Soos u kan verwag, sien ons stadige oproepe hier read(). Uit die inhoud van leesbewerkings en konteks mem_cgroup dit is duidelik dat hierdie uitdagings read() verwys na die lêer memory.stat, wat geheuegebruik en cgroup-limiete wys (Docker se hulpbron-isolasietegnologie). Die cadvisor-nutsding vra hierdie lêer om hulpbrongebruikinligting vir houers te bekom. Kom ons kyk of dit die kern of cadvisor is wat iets onverwags doen:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
werklike 0m0.153s
gebruiker 0m0.000s
stelsel 0m0.152s
theojulienne@kube-node-bad ~ $
Nou kan ons die fout reproduseer en verstaan dat die kern Linux patologie teëkom.
Hoekom is die leesbewerking so stadig?
Op hierdie stadium is dit baie makliker om boodskappe van ander gebruikers oor soortgelyke probleme te vind. Soos dit geblyk het, is hierdie fout in die cadvisor-spoorsnyer aangemeld as , dit is net dat niemand opgemerk het dat die latensie ook lukraak in die netwerkstapel weerspieël word nie. Daar is inderdaad opgemerk dat cadvisor meer SVE-tyd verbruik as wat verwag is, maar dit is nie baie belangrik geag nie, aangesien ons bedieners baie SVE-hulpbronne het, so die probleem is nie noukeurig bestudeer nie.
Die probleem is dat cgroups geheuegebruik binne die naamruimte (houer) in ag neem. Wanneer alle prosesse in hierdie cgroup afloop, stel Docker die geheue cgroup vry. “Geheue” is egter nie net prosesgeheue nie. Alhoewel die prosesgeheue self nie meer gebruik word nie, blyk dit dat die kern steeds kasinhoud toeken, soos dentries en inodes (gids- en lêermetadata), wat in die geheue-cgroup gekas is. Uit die probleembeskrywing:
zombie cgroups: cgroups wat geen prosesse het nie en wat uitgevee is, maar steeds geheue toegewys het (in my geval, vanaf die dentry-kas, maar dit kan ook vanaf die bladsy-kas of tmpfs toegewys word).
Die kern se kontrolering van al die bladsye in die kas wanneer 'n cgroup vrygestel word, kan baie stadig wees, so die lui proses word gekies: wag totdat hierdie bladsye weer aangevra word, en maak dan uiteindelik die cgroup skoon wanneer die geheue eintlik nodig is. Tot op hierdie stadium word cgroup steeds in ag geneem wanneer statistieke ingesamel word.
Vanuit 'n prestasie-oogpunt het hulle geheue opgeoffer vir prestasie: die aanvanklike opruiming bespoedig deur 'n mate van kasgeheue agter te laat. Dit is goed. Wanneer die kern die laaste van die kasgeheue gebruik, word die cgroup uiteindelik uitgevee, dus kan dit nie 'n "lek" genoem word nie. Ongelukkig is die spesifieke implementering van die soekmeganisme memory.stat in hierdie kernweergawe (4.9), gekombineer met die groot hoeveelheid geheue op ons bedieners, beteken dit dat dit baie langer neem om die nuutste kasdata te herstel en cgroup-zombies uit te vee.
Dit blyk dat sommige van ons nodusse soveel cgroup-zombies gehad het dat die lees en latensie 'n sekonde oorskry het.
Die oplossing vir die cadvisor-probleem is om dentries/inodes-kasgeheue onmiddellik regdeur die stelsel te bevry, wat onmiddellik leesvertraging sowel as netwerkvertraging op die gasheer uitskakel, aangesien die skoonmaak van die kas die gekaste zombie cgroup-bladsye aanskakel en dit ook bevry. Dit is nie 'n oplossing nie, maar dit bevestig die oorsaak van die probleem.
Dit het geblyk dat in nuwer kernweergawes (4.19+) oproepprestasie verbeter is memory.stat, so die oorskakeling na hierdie kern het die probleem opgelos. Terselfdertyd het ons gereedskap gehad om problematiese nodusse in Kubernetes-klusters op te spoor, dit grasieus te dreineer en hulle te herlaai. Ons het al die trosse gefynkam, nodusse met 'n hoë genoeg latensie gevind en hulle herlaai. Dit het ons tyd gegee om die bedryfstelsel op die oorblywende bedieners op te dateer.
Opsomming
Omdat hierdie fout RX NIC-touverwerking vir honderde millisekondes gestop het, het dit gelyktydig hoë latency op kort verbindings en mid-verbinding latency veroorsaak, soos tussen MySQL-versoeke en antwoordpakkies.
Om die werkverrigting van die mees fundamentele stelsels, soos Kubernetes, te verstaan en te handhaaf, is van kritieke belang vir die betroubaarheid en spoed van alle dienste wat daarop gebaseer is. Elke stelsel wat u bestuur, trek voordeel uit Kubernetes-prestasieverbeterings.
Bron: will.com
