


В ons het na RabbitMQ-groepering gekyk vir fouttoleransie en hoë beskikbaarheid. Kom ons delf nou diep in Apache Kafka.
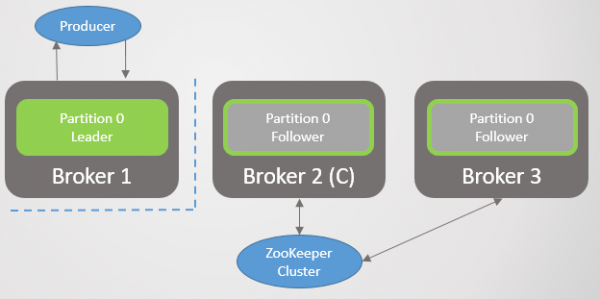
Hier is die eenheid van replikasie die partisie. Elke onderwerp het een of meer afdelings. Elke afdeling het 'n leier met of sonder volgelinge. Wanneer u 'n onderwerp skep, spesifiseer u die aantal partisies en die replikasiekoëffisiënt. Die gewone waarde is 3, wat drie replikas beteken: een leier en twee volgelinge.
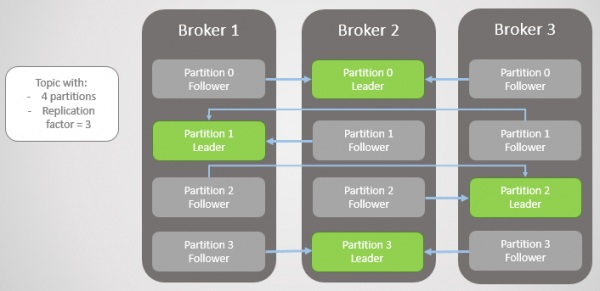
Rys. 1. Vier afdelings word onder drie makelaars versprei
Alle lees- en skryfversoeke gaan na die leier. Volgers stuur periodiek versoeke aan die leier om die jongste boodskappe te ontvang. Verbruikers wend hulle nooit tot volgelinge nie; laasgenoemde bestaan slegs vir oortolligheid en foutverdraagsaamheid.
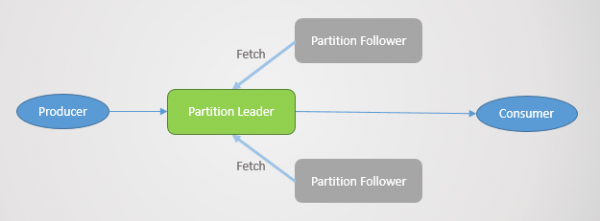
Partisie mislukking
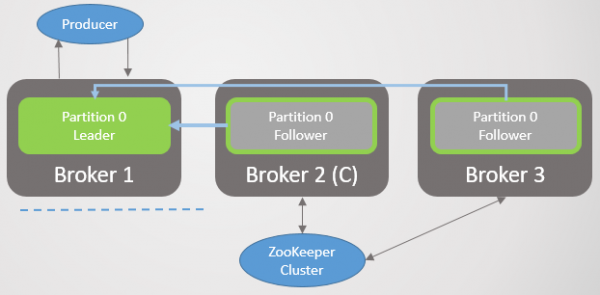
Wanneer 'n makelaar misluk, misluk die leiers van verskeie afdelings dikwels. In elkeen van hulle word 'n volgeling van 'n ander nodus die leier. Trouens, dit is nie altyd die geval nie, aangesien die sinchronisasiefaktor ook 'n invloed het: of daar gesinchroniseerde volgelinge is, en indien nie, of oorskakeling na 'n ongesinchroniseerde replika toegelaat word nie. Maar laat ons dinge nie vir eers kompliseer nie.
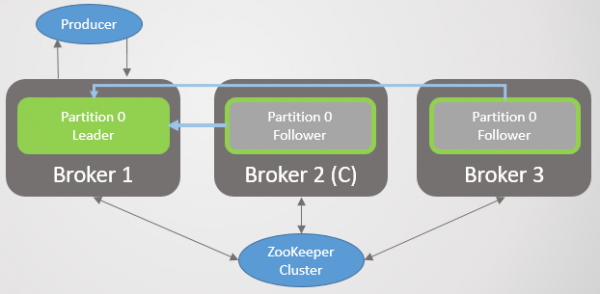
Makelaar 3 verlaat die netwerk, en 'n nuwe leier word vir afdeling 2 by makelaar 2 verkies.
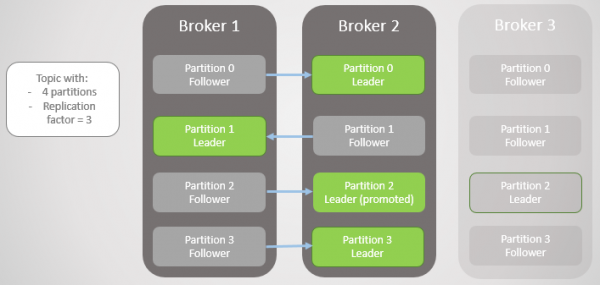
Rys. 2. Makelaar 3 sterf en sy volgeling op makelaar 2 word verkies as die nuwe leier van partisie 2
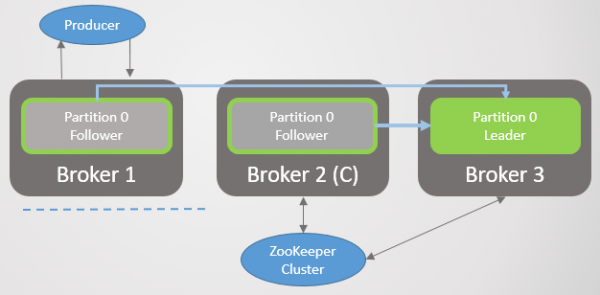
Dan vertrek makelaar 1 en afdeling 1 verloor ook sy leier wie se rol na makelaar 2 oorgaan.
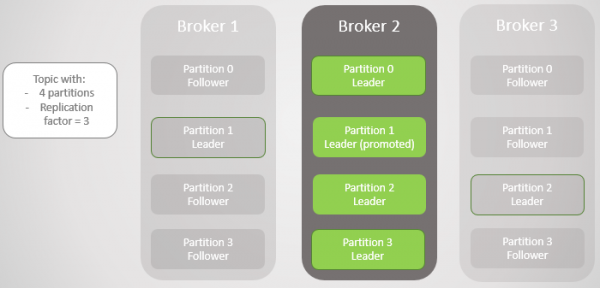
Rys. 3. Daar is een makelaar oor. Alle leiers is op een makelaar met geen oortolligheid nie
Wanneer makelaar 1 weer aanlyn kom, voeg dit vier volgelinge by, wat 'n mate van oortolligheid aan elke partisie bied. Maar al die leiers het steeds op makelaar 2 gebly.
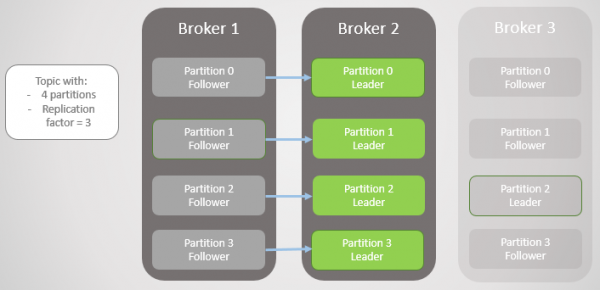
Rys. 4. Leiers bly op makelaar 2
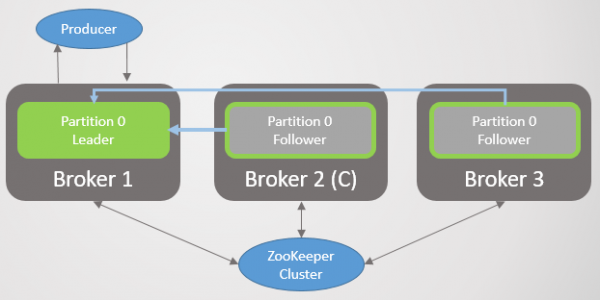
Wanneer makelaar 3 opduik, is ons terug na drie replikas per partisie. Maar al die leiers is steeds op makelaar 2.
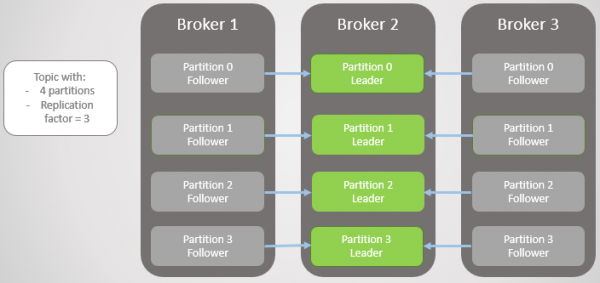
Rys. 5. Ongebalanseerde plasing van leiers na die herstel van makelaars 1 en 3
Kafka het 'n instrument vir beter leier-herbalansering as RabbitMQ. Daar moes u 'n derdeparty-inprop of -skrip gebruik wat die beleide vir die migrasie van die hoofnodus verander het deur oortolligheid tydens migrasie te verminder. Boonop moes ons vir groot toue onbeskikbaarheid tydens sinchronisasie aanvaar.
Kafka het die konsep van "voorkeur replikas" vir die leiersrol. Wanneer onderwerppartisies geskep word, poog Kafka om leiers eweredig oor nodusse te versprei en merk daardie eerste leiers as voorkeur. Met verloop van tyd, as gevolg van bedienerherlaai, mislukkings en konneksieonderbrekings, kan leiers op ander nodusse beland, soos in die uiterste geval hierbo beskryf.
Om dit reg te stel, bied Kafka twee opsies:
- opsie auto.leader.rebalance.enable=waar laat die kontroleerdernodus toe om leiers outomaties terug na voorkeur replikas toe te wys en sodoende eenvormige verspreiding te herstel.
- Die administrateur kan die skrip laat loop kafka-preferred-replica-election.sh vir handmatige hertoewysing.
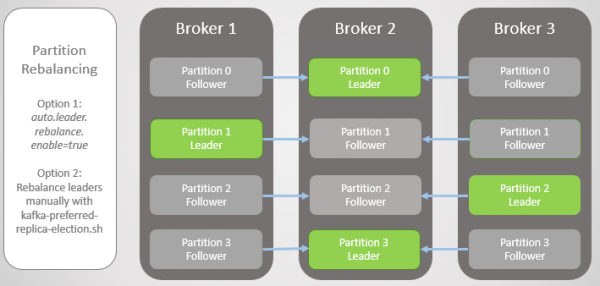
Rys. 6. Replikas na herbalansering
Dit was 'n vereenvoudigde weergawe van die mislukking, maar die werklikheid is meer kompleks, hoewel hier niks te ingewikkeld is nie. Dit kom alles neer op gesinchroniseerde replikas (In-Sync Replicas, ISR).
Gesinchroniseerde replikas (ISR)
'n ISR is 'n stel replikas van 'n partisie wat as "gesinchroniseer" (gesinkroniseer) beskou word. Daar is 'n leier, maar daar mag nie volgelinge wees nie. 'n Volger word as gesinchroniseer beskou as dit presiese afskrifte van al die leier se boodskappe gemaak het voor die interval verstryk replika.lagtyd.maks.ms.
'n Volger word uit die ISR-stel verwyder as dit:
- het nie 'n versoek gerig om vir die interval te kies nie replika.lagtyd.maks.ms (vermoedelik dood)
- kon nie daarin slaag om gedurende die interval op te dateer nie replika.lagtyd.maks.ms (beskou as stadig)
Volgers maak steekproefversoeke in die interval replica.fetch.wait.max.ms, wat verstek na 500ms.
Om die doel van ISR duidelik te verduidelik, moet ons kyk na bevestigings van die vervaardiger en sommige mislukkingscenario's. Produsente kan kies wanneer die makelaar bevestiging stuur:
- acks=0, bevestiging word nie gestuur nie
- acks=1, bevestiging word gestuur nadat die leier 'n boodskap aan sy plaaslike log geskryf het
- acks=all, bevestiging word gestuur nadat alle replikas in die ISR die boodskap na die plaaslike logs geskryf het
In Kafka-terminologie, as die ISR 'n boodskap gestoor het, is dit "toegewyd". Acks=all is die veiligste opsie, maar voeg ook bykomende vertraging by. Kom ons kyk na twee voorbeelde van mislukking en hoe die verskillende 'acks'-opsies met die ISR-konsep in wisselwerking tree.
Acks=1 en ISR
In hierdie voorbeeld sal ons sien dat as die leier nie wag vir elke boodskap van alle volgelinge om gestoor te word nie, dataverlies moontlik is as die leier misluk. Navigasie na 'n ongesinkroniseerde volger kan geaktiveer of gedeaktiveer word deur instelling onrein.leier.verkiesing.aktiveer.
In hierdie voorbeeld het die vervaardiger die waarde acks=1. Die afdeling word oor al drie makelaars versprei. Makelaar 3 is agter, dit het agt sekondes gelede met die leier gesinchroniseer en is nou 7456 boodskappe agter. Makelaar 1 was slegs een sekonde agter. Ons vervaardiger stuur 'n boodskap en ontvang vinnig 'n ack terug, sonder die oorhoofse van stadige of dooie volgelinge waarvoor die leier nie wag nie.
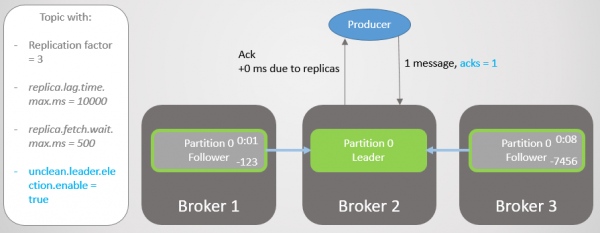
Rys. 7. ISR met drie replikas
Makelaar 2 misluk en die produsent ontvang 'n verbindingsfout. Nadat leierskap na makelaar 1 oorgedra is, verloor ons 123 boodskappe. Die volgeling op makelaar 1 was deel van die ISR, maar was nie ten volle gesinchroniseer met die leier toe dit geval het nie.
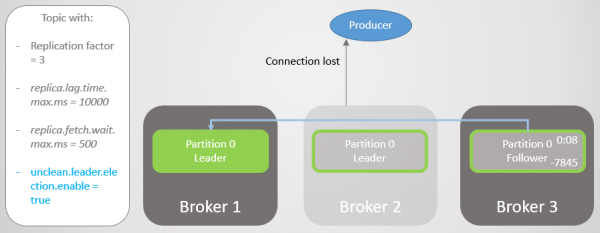
Rys. 8. Boodskappe gaan verlore wanneer dit ineenstort
In konfigurasie bootstrap.bedieners Die vervaardiger het verskeie makelaars gelys en kan 'n ander makelaar vra wie die nuwe afdelingsleier is. Dit vestig dan 'n verbinding met makelaar 1 en gaan voort om boodskappe te stuur.
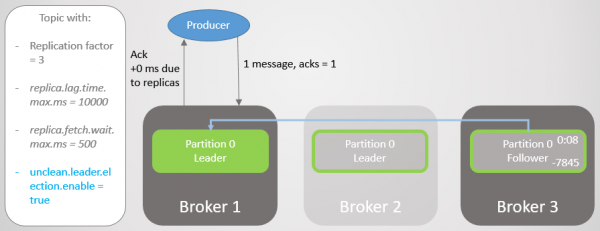
Rys. 9. Die stuur van boodskappe hervat na 'n kort pouse
Makelaar 3 is selfs verder agter. Dit maak haalversoeke, maar kan nie sinkroniseer nie. Dit kan wees as gevolg van stadige netwerkverbinding tussen makelaars, bergingskwessie, ens. Dit word van die ISR verwyder. Nou bestaan die ISR uit een replika - die leier! Die vervaardiger gaan voort om boodskappe te stuur en bevestigings te ontvang.
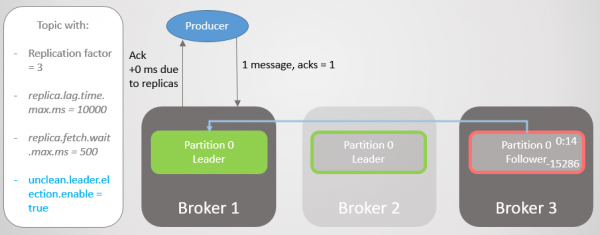
Rys. 10. Volger op makelaar 3 word van die ISR verwyder
Makelaar 1 gaan af en die leiersrol gaan na makelaar 3 met die verlies van 15286 boodskappe! Die vervaardiger ontvang 'n verbindingsfoutboodskap. Die oorgang na 'n leier buite die ISR was slegs moontlik as gevolg van die omgewing onrein.leier.election.enable=waar. As dit geïnstalleer is in valse, dan sal die oorgang nie plaasvind nie en sal alle lees- en skryfversoeke verwerp word. In hierdie geval wag ons vir makelaar 1 om terug te keer met sy ongeskonde data in die replika, wat weer leierskap sal oorneem.
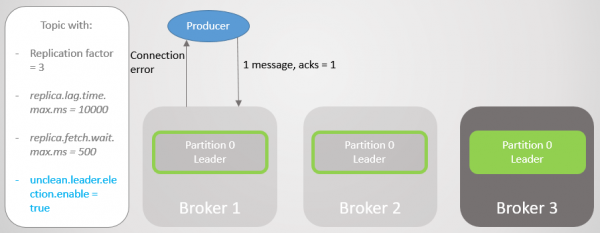
Rys. 11. Makelaar 1 val. Wanneer 'n mislukking plaasvind, gaan 'n groot aantal boodskappe verlore
Die produsent vestig 'n verbintenis met die laaste makelaar en sien dat hy nou die leier van die afdeling is. Hy begin boodskappe aan makelaar 3 stuur.
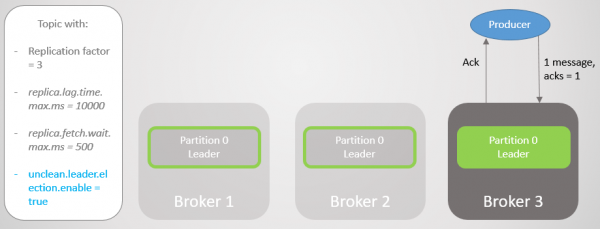
Rys. 12. Na 'n kort pouse word boodskappe weer na afdeling 0 gestuur
Ons het gesien dat, afgesien van kort onderbrekings om nuwe verbindings te vestig en na 'n nuwe leier te soek, die vervaardiger voortdurend boodskappe stuur. Hierdie konfigurasie verseker beskikbaarheid ten koste van konsekwentheid (datasekuriteit). Kafka het duisende boodskappe verloor, maar het voortgegaan om nuwe skrywes te aanvaar.
Acks=almal en ISR
Kom ons herhaal hierdie scenario weer, maar met acks = almal. Makelaar 3 het 'n gemiddelde latency van vier sekondes. Die vervaardiger stuur 'n boodskap met acks = almal, en kry nou nie 'n vinnige reaksie nie. Die leier wag dat die boodskap deur alle replikas in die ISR gestoor word.
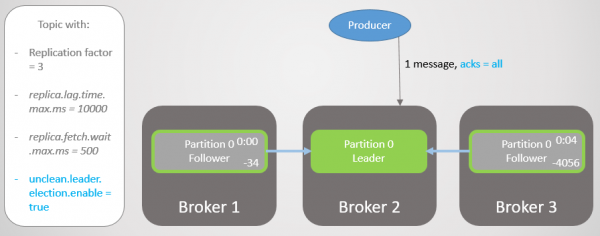
Rys. 13. ISR met drie replikas. Een is stadig, wat lei tot opname vertragings
Na vier sekondes van bykomende vertraging, stuur makelaar 2 'n ack. Alle replikas is nou volledig opgedateer.
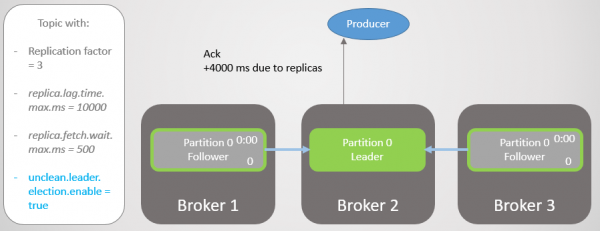
Rys. 14. Alle replikas stoor boodskappe en stuur ack
Makelaar 3 raak nou verder agter en word uit die ISR verwyder. Latency word aansienlik verminder omdat daar geen stadige replikas in die ISR oor is nie. Makelaar 2 wag nou net vir makelaar 1, en hy het 'n gemiddelde vertraging van 500 ms.
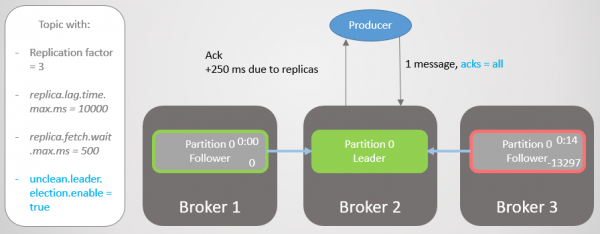
Rys. 15. Die replika op makelaar 3 word uit die ISR verwyder
Dan val makelaar 2 en leierskap gaan oor na makelaar 1 sonder verlies van boodskappe.
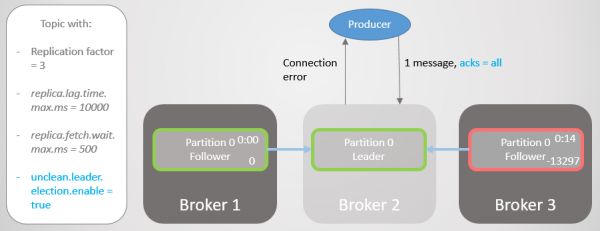
Rys. 16. Makelaar 2 val
Die vervaardiger kry 'n nuwe leier en begin boodskappe aan hom stuur. Die latensie word verder verminder omdat die ISR nou uit een replika bestaan! Daarom die opsie acks = almal voeg nie oortolligheid by nie.
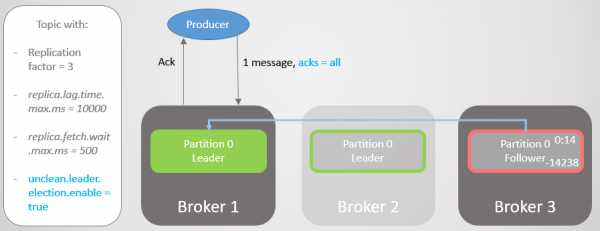
Rys. 17. Replika op makelaar 1 neem die voortou sonder om boodskappe te verloor
Dan val makelaar 1 ineen en die voorsprong gaan na makelaar 3 met 'n verlies van 14238 boodskappe!
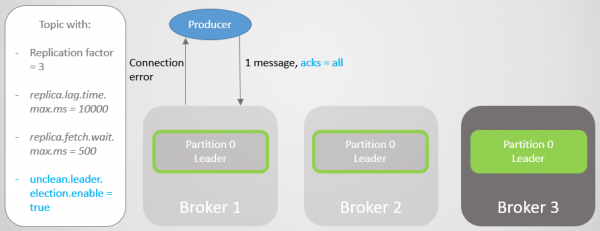
Rys. 18. Makelaar 1 sterf en leierskapoorgang met onrein omgewing lei tot uitgebreide dataverlies
Ons kon nie die opsie installeer nie onrein.leier.verkiesing.aktiveer tot betekenis waar. By verstek is dit gelyk valse. Instellings acks = almal с onrein.leier.election.enable=waar bied toeganklikheid met ekstra datasekuriteit. Maar soos jy kan sien, kan ons steeds boodskappe verloor.
Maar wat as ons datasekuriteit wil verhoog? Jy kan sit onrein.leier.election.enable = onwaar, maar dit sal ons nie noodwendig teen dataverlies beskerm nie. As die leier hard geval het en die data saamgeneem het, is boodskappe steeds verlore, plus beskikbaarheid gaan verlore totdat die administrateur die situasie herstel.
Dit is beter om te verseker dat alle boodskappe oorbodig is, en andersins die opname weg te gooi. Dan, ten minste vanuit die makelaar se oogpunt, is dataverlies slegs moontlik in die geval van twee of meer gelyktydige mislukkings.
Acks=all, min.insync.replicas en ISR
Met onderwerpkonfigurasie min.insync.replikas Ons verhoog die vlak van datasekuriteit. Kom ons gaan weer deur die laaste deel van die vorige scenario, maar hierdie keer met min.insync.replicas=2.
Makelaar 2 het dus 'n replika-leier en die volger op makelaar 3 word van die ISR verwyder.
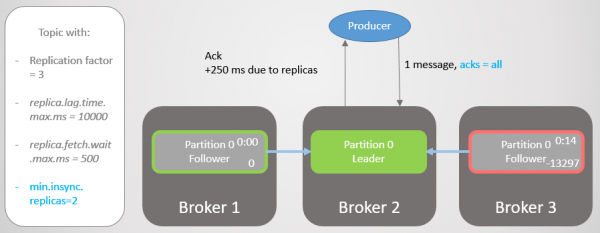
Rys. 19. ISR van twee replikas
Makelaar 2 val en leierskap gaan oor na makelaar 1 sonder verlies van boodskappe. Maar nou bestaan die ISR net uit een replika. Dit voldoen nie aan die minimum aantal om rekords te ontvang nie, en daarom reageer die makelaar op die skryfpoging met 'n fout Nie Genoeg Replikas nie.
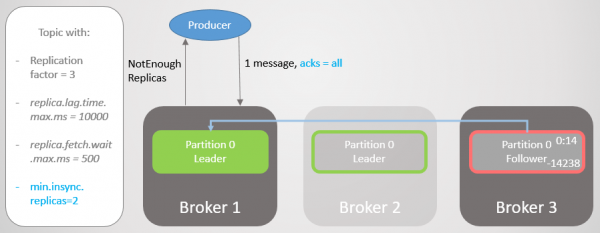
Rys. 20. Die aantal ISR'e is een laer as gespesifiseer in min.insync.replicas
Hierdie konfigurasie offer beskikbaarheid vir konsekwentheid op. Voordat ons 'n boodskap erken, maak ons seker dat dit in ten minste twee replikas geskryf is. Dit gee die vervaardiger baie meer selfvertroue. Hier is boodskapverlies slegs moontlik as twee replikas gelyktydig in 'n kort interval misluk totdat die boodskap na 'n bykomende volger gerepliseer word, wat onwaarskynlik is. Maar as jy super paranoïes is, kan jy die replikasiefaktor op 5 stel, en min.insync.replikas teen 3. Hier moet drie makelaars gelyktydig val om die rekord te verloor! Natuurlik betaal jy vir hierdie betroubaarheid in bykomende vertraging.
Wanneer toeganklikheid nodig is vir datasekuriteit
Soos in , soms is toeganklikheid nodig vir datasekuriteit. Hier is waaroor jy moet dink:
- Kan die uitgewer bloot 'n fout terugstuur en die stroomopdiens of gebruiker later weer laat probeer?
- Kan die uitgewer die boodskap plaaslik of in die databasis stoor om later weer te probeer?
As die antwoord nee is, verbeter die optimalisering van beskikbaarheid datasekuriteit. Jy sal minder data verloor as jy beskikbaarheid kies in plaas van om nie op te neem nie. Dit kom dus alles daarop neer om 'n balans te vind, en die besluit hang af van die spesifieke situasie.
Die betekenis van ISR
Die ISR-suite laat jou toe om die optimale balans tussen datasekuriteit en latensie te kies. Verseker byvoorbeeld beskikbaarheid in die geval van mislukking van die meerderheid replikas, en verminder die impak van dooie of stadige replikas in terme van latensie.
Ons kies self die betekenis replika.lagtyd.maks.ms volgens jou behoeftes. In wese beteken hierdie parameter hoeveel vertraging ons bereid is om wanneer te aanvaar acks = almal. Die verstekwaarde is tien sekondes. As dit vir jou te lank is, kan jy dit verminder. Dan sal die frekwensie van veranderinge in die ISR toeneem, aangesien volgelinge meer gereeld verwyder en bygevoeg sal word.
RabbitMQ is bloot 'n stel spieëls wat gerepliseer moet word. Stadige spieëls stel bykomende latensie in, en dooie spieëls kan wag totdat die pakkies wat die beskikbaarheid van elke nodus (netto merk) nagaan om te reageer. ISR is 'n interessante manier om hierdie vertragingskwessies te vermy. Maar ons loop die risiko om oortolligheid te verloor aangesien die ISR net tot die leier kan krimp. Om hierdie risiko te vermy, gebruik die instelling min.insync.replikas.
Kliëntverbindingwaarborg
In die instellings bootstrap.bedieners produsent en verbruiker kan verskeie makelaars spesifiseer vir die koppeling van kliënte. Die idee is dat wanneer een nodus afgaan, daar verskeie ekstras oor is waarmee die kliënt 'n verbinding kan oopmaak. Dit is nie noodwendig seksieleiers nie, maar bloot 'n springplank vir aanvanklike laai. Die kliënt kan hulle vra watter nodus die lees/skryf partisieleier huisves.
In RabbitMQ kan kliënte aan enige nodus koppel, en interne roetering stuur die versoek waarheen dit moet gaan. Dit beteken dat jy 'n lasbalanseerder voor RabbitMQ kan installeer. Kafka vereis van kliënte om te koppel aan die nodus wat die ooreenstemmende partisieleier huisves. In so 'n situasie kan jy nie 'n lasbalanseerder installeer nie. Lys bootstrap.bedieners Dit is van kritieke belang dat kliënte na 'n mislukking toegang tot die korrekte nodusse kan kry en dit kan vind.
Kafka konsensus argitektuur
Tot nou toe het ons nie oorweeg hoe die groep leer oor die val van die makelaar en hoe 'n nuwe leier verkies word nie. Om te verstaan hoe Kafka met netwerkpartisies werk, moet jy eers die konsensusargitektuur verstaan.
Elke Kafka-kluster word saam met 'n Zookeeper-kluster ontplooi, wat 'n verspreide konsensusdiens is wat die stelsel in staat stel om konsensus te bereik oor een of ander gegewe toestand, wat konsekwentheid bo beskikbaarheid prioritiseer. Die toestemming van 'n meerderheid Zookeeper nodusse word vereis om lees- en skryfbewerkings goed te keur.
Zookeeper stoor die toestand van die groep:
- Lys van onderwerpe, afdelings, konfigurasie, huidige leier replikas, voorkeur replikas.
- Groepslede. Elke makelaar ping die Zookeeper-groepering. As dit nie 'n ping binne 'n bepaalde tydperk ontvang nie, teken Zookeeper die makelaar aan as onbeskikbaar.
- Kies die hoof- en spaarknope vir die beheerder.
Die kontroleerdernodus is een van die Kafka-makelaars wat verantwoordelik is vir die verkiesing van replika-leiers. Zookeeper stuur kennisgewings aan die beheerder oor groepslidmaatskap en onderwerpveranderings, en die beheerder moet op hierdie veranderinge reageer.
Kom ons neem byvoorbeeld 'n nuwe onderwerp met tien partisies en 'n replikasiefaktor van 3. Die kontroleerder moet 'n leier vir elke partisie kies en probeer om leiers optimaal onder die makelaars te versprei.
Vir elke afdeling kontroleerder:
- dateer inligting in Zookeeper op oor ISR en leier;
- Stuur 'n LeaderAndISRCommand aan elke makelaar wat 'n replika van hierdie partisie huisves, wat die makelaars inlig oor die ISR en die leier.
Wanneer 'n makelaar met 'n leier val, stuur Zookeeper 'n kennisgewing aan die kontroleerder, en dit kies 'n nuwe leier. Weereens, die kontroleerder werk Zookeeper eers op en stuur dan 'n opdrag aan elke makelaar wat hulle in kennis stel van die leierskapverandering.
Elke leier is verantwoordelik vir die werwing van ISR's. Instellings replika.lagtyd.maks.ms bepaal wie daar sal ingaan. Wanneer die ISR verander, stuur die leier nuwe inligting aan Zookeeper.
Zookeeper word altyd ingelig oor enige veranderinge sodat in die geval van 'n mislukking die bestuur glad na 'n nuwe leier oorgaan.
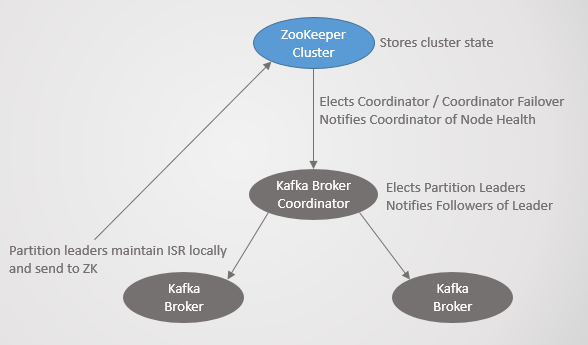
Rys. 21. Kafka Konsensus
Replikasie protokol
Om die besonderhede van replikasie te verstaan, help jou om potensiële dataverlies-scenario's beter te verstaan.
Steekproefnavrae, Log End Offset (LEO) en Highwater Mark (HW)
Ons het van mening dat volgelinge periodiek haalversoeke aan die leier stuur. Die verstek interval is 500ms. Dit verskil van RabbitMQ deurdat in RabbitMQ replikasie nie deur die tou-spieël geïnisieer word nie, maar deur die meester. Die meester druk veranderinge aan die spieëls.
Die leier en alle volgelinge stoor die Log End Offset (LEO) en die Highwater (HW) etiket. Die LEO-merk stoor die offset van die laaste boodskap in die plaaslike replika, en die HW hou die offset van die laaste commit. Onthou dat die boodskap oor alle ISR-replikas volgehou moet word vir commit-status. Dit beteken dat LEO gewoonlik effens voor HW is.
Wanneer die leier 'n boodskap ontvang, stoor hy dit plaaslik. Die volger doen 'n haalversoek deur sy LEO te versend. Die leier stuur dan 'n bondel boodskappe vanaf hierdie LEO en stuur ook die huidige HW. Wanneer die leier inligting ontvang dat alle replikas die boodskap teen die gegewe afset gestoor het, skuif dit die HW-merk. Slegs die leier kan die HW skuif, en dus sal alle volgelinge die huidige waarde in die antwoorde op hul versoek ken. Dit beteken dat volgelinge agter die leier kan bly in beide boodskap en HW kennis. Verbruikers ontvang slegs boodskappe tot die huidige HW.
Let daarop dat "aangehou" beteken geskryf na geheue, nie na skyf nie. Vir prestasie sinchroniseer Kafka met 'n spesifieke interval na skyf. RabbitMQ het ook so 'n interval, maar dit sal eers 'n erkenning aan die uitgewer stuur nadat die meester en alle spieëls die boodskap op skyf geskryf het. Die Kafka-ontwikkelaars het om prestasieredes besluit om 'n ack te stuur sodra die boodskap in die geheue geskryf is. Kafka wed dat oortolligheid die risiko verreken om erkende boodskappe net kortliks in die geheue te stoor.
Leier mislukking
Wanneer 'n leier val, stel Zookeeper die kontroleerder in kennis, en dit kies 'n nuwe leier-replika. Die nuwe leier stel 'n nuwe HW-merk volgens sy LEO. Volgers ontvang dan inligting oor die nuwe leier. Afhangende van die weergawe van Kafka, sal die volger een van twee scenario's kies:
- Dit sal die plaaslike log na 'n bekende HW afkap en 'n versoek aan die nuwe leier stuur vir boodskappe na hierdie merk.
- Sal 'n versoek aan die leier stuur om uit te vind wat die HW is toe hy as leier verkies is, en dan die log afkap tot hierdie verrekening. Dit sal dan begin om periodieke haalversoeke te maak wat by hierdie afwyking begin.
'n Volger sal dalk die log om die volgende redes moet afkap:
- Wanneer 'n leier misluk, wen die eerste volgeling in die ISR-stel wat by Zookeeper geregistreer is die verkiesing en word die leier. Alle volgelinge op ISR, alhoewel as "gesinchroniseer" beskou word, het moontlik nie afskrifte van alle boodskappe van die voormalige leier ontvang nie. Dit is heeltemal moontlik dat die uitgestalde volger nie die mees onlangse kopie het nie. Kafka verseker dat daar geen divergensie tussen replikas is nie. Dus, om verskille te vermy, moet elke volgeling sy log afkap tot die HW-waarde van die nuwe leier ten tyde van sy verkiesing. Dit is nog 'n rede waarom die instelling acks = almal so belangrik vir konsekwentheid.
- Boodskappe word periodiek na skyf geskryf. As alle cluster nodusse op dieselfde tyd misluk, sal replikas met verskillende offsets op die skywe gestoor word. Dit is moontlik dat wanneer makelaars terugkom aanlyn, die nuwe leier wat verkies word, agter sy volgelinge sal wees omdat hy voor die ander op skyf gestoor is.
Reünie met die cluster
Wanneer hulle weer by die groep aansluit, doen die replikas dieselfde as wanneer 'n leier misluk: hulle kontroleer die leier se replika en kap hul log af na sy HW (ten tyde van verkiesing). In vergelyking behandel RabbitMQ herenigde nodusse eweneens as heeltemal nuut. In beide gevalle gooi die makelaar enige bestaande staat weg. As outomatiese sinchronisasie gebruik word, moet die meester absoluut alle huidige inhoud na die nuwe spieël herhaal in 'n "laat die hele wêreld wag" metode. Die meester aanvaar geen lees- of skryfbewerkings tydens hierdie operasie nie. Hierdie benadering skep probleme in groot toue.
Kafka is 'n verspreide log en in die algemeen stoor dit meer boodskappe as 'n RabbitMQ-tou, waar data uit die tou verwyder word nadat dit gelees is. Aktiewe toue moet relatief klein bly. Maar Kafka is 'n log met sy eie retensiebeleid, wat 'n tydperk van dae of weke kan stel. Die toublokkering en volle sinchronisasiebenadering is absoluut onaanvaarbaar vir 'n verspreide logboek. In plaas daarvan, kapka-volgelinge eenvoudig hul log af na die leier se HW (ten tyde van sy verkiesing) as hul kopie voor die leier is. In die meer waarskynlike geval, wanneer die volger agter is, begin dit eenvoudig haalversoeke maak wat begin met sy huidige LEO.
Nuwe of heraangeslote volgelinge begin buite die ISR en neem nie deel aan commits nie. Hulle werk eenvoudig saam met die groep en ontvang boodskappe so vinnig as wat hulle kan totdat hulle die leier inhaal en die ISR betree. Daar is geen insluiting nie en dit is nie nodig om al jou data weg te gooi nie.
Verbindingsontwrigting
Kafka het meer komponente as RabbitMQ, so dit het 'n meer komplekse stel gedrag wanneer die groep ontkoppel word. Maar Kafka is oorspronklik vir groepe ontwerp, so die oplossings is baie goed deurdink.
Hieronder is verskeie scenario's vir verbindingsfout:
- Scenario 1: Die volgeling sien nie die leier nie, maar sien steeds die dieretuinbewaarder.
- Scenario 2: Die leier sien geen volgelinge nie, maar sien steeds Zookeeper.
- Scenario 3: Die volgeling sien die leier, maar sien nie die dieretuinwagter nie.
- Scenario 4: Die leier sien die volgelinge, maar sien nie die dieretuinwagter nie.
- Scenario 5: Die volgeling is heeltemal apart van beide ander Kafka-nodusse en Zookeeper.
- Scenario 6: Die leier is heeltemal apart van beide ander Kafka-nodusse en Zookeeper.
- Scenario 7: Die Kafka-kontroleerderknoop kan nie 'n ander Kafka-knooppunt sien nie.
- Scenario 8: Kafka-beheerder sien nie Zookeeper nie.
Elke scenario het sy eie gedrag.
Scenario 1: Volger sien nie die leier nie, maar sien steeds Zookeeper
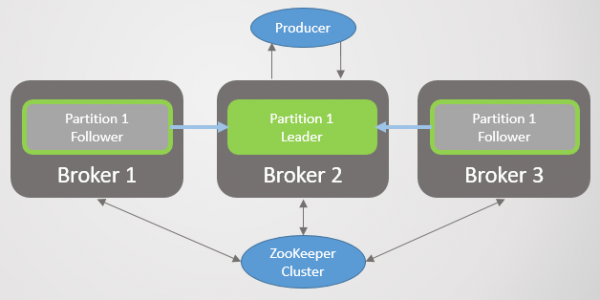
Rys. 22. Scenario 1: ISR van drie replikas
Die verbindingsfout skei makelaar 3 van makelaars 1 en 2, maar nie van Zookeeper nie. Makelaar 3 kan nie meer haalversoeke stuur nie. Nadat die tyd verby is replika.lagtyd.maks.ms dit word uit die ISR verwyder en neem nie deel aan boodskapverpligtinge nie. Sodra konnektiwiteit herstel is, sal dit haalversoeke hervat en by die ISR aansluit wanneer dit die leier inhaal. Zookeeper sal voortgaan om pings te ontvang en aanvaar dat die makelaar lewendig en gesond is.
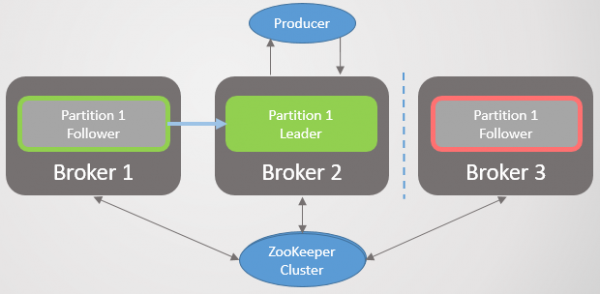
Rys. 23. Scenario 1: Die makelaar word van die ISR verwyder indien geen haalversoek van hom ontvang word binne die replica.lag.time.max.ms interval
Daar is geen gesplete brein of nodus opskorting soos in RabbitMQ nie. In plaas daarvan word oortolligheid verminder.
Scenario 2: Leier sien geen volgelinge nie, maar sien steeds Zookeeper
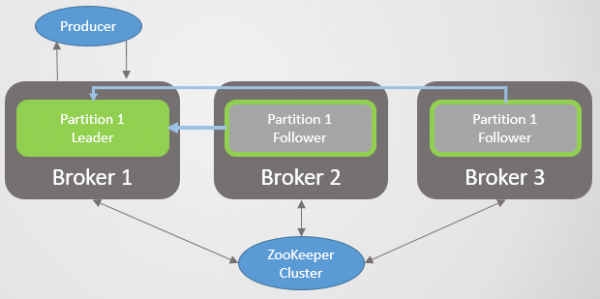
Rys. 24. Scenario 2. Leier en twee volgelinge
'n Onderbreking in netwerkverbinding skei die leier van die volgelinge, maar die makelaar kan steeds Zookeeper sien. Soos in die eerste scenario, krimp die ISR, maar hierdie keer slegs na die leier, aangesien alle volgelinge ophou om haalversoeke te stuur. Weereens, daar is geen logiese verdeling nie. In plaas daarvan is daar 'n verlies aan oortolligheid vir nuwe boodskappe totdat konneksie herstel is. Zookeeper gaan voort om pings te ontvang en glo dat die makelaar lewendig en gesond is.
Rys. 25. Scenario 2. ISR het net tot die leier gekrimp
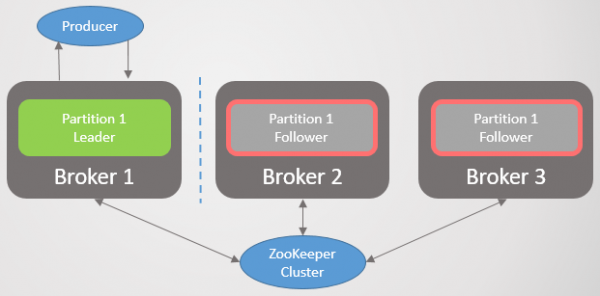
Scenario 3. Volger sien die leier, maar sien nie die dieretuinwagter nie
Die volgeling word van Zookeeper geskei, maar nie van die makelaar met die leier nie. As gevolg hiervan, gaan die volger voort om haalversoeke te maak en 'n lid van die ISR te wees. Zookeeper ontvang nie meer pings nie en registreer 'n makelaarongeluk, maar aangesien dit slegs 'n volger is, is daar geen gevolge na herstel nie.
Rys. 26. Scenario 3: Die volger gaan voort om haalversoeke aan die leier te stuur
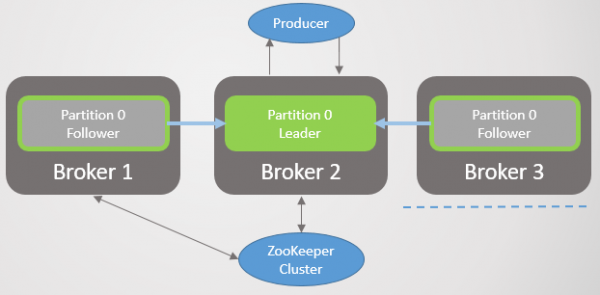
Scenario 4. Leier sien volgelinge, maar sien nie Zookeeper nie
Rys. 27. Scenario 4. Leier en twee volgelinge
Die leier word geskei van Zookeeper, maar nie van die makelaars met volgelinge nie.
Rys. 28. Scenario 4: Leier geïsoleer van Zookeeper
Na 'n geruime tyd sal Zookeeper 'n makelaarmislukking registreer en die kontroleerder daaroor in kennis stel. Hy sal 'n nuwe leier onder sy volgelinge kies. Die oorspronklike leier sal egter aanhou dink dat dit die leier is en sal voortgaan om inskrywings van te aanvaar acks=1. Volgers stuur nie meer vir hom haalversoeke nie, so hy sal hulle as dood beskou en probeer om die ISR vir homself te laat krimp. Maar aangesien dit nie 'n verbinding met Zookeeper het nie, sal dit dit nie kan doen nie, en sal op daardie stadium weier om enige verdere inskrywings te aanvaar.
Сообщения acks = almal sal nie 'n erkenning ontvang nie, want die ISR skakel eers alle replikas aan, en boodskappe bereik hulle nie. Wanneer die oorspronklike leier probeer om hulle uit die ISR te verwyder, sal dit nie in staat wees om dit te doen nie en sal ophou om enige boodskappe enigsins te aanvaar.
Kliënte merk gou die verandering in leier op en begin rekords na die nuwe bediener stuur. Sodra die netwerk herstel is, sien die oorspronklike leier dat dit nie meer 'n leier is nie en kap sy log af na die HW-waarde wat die nuwe leier gehad het ten tyde van die versuim om log divergensie te vermy. Dit sal dan haalversoeke na die nuwe leier begin stuur. Alle rekords van die oorspronklike leier wat nie na die nuwe leier gerepliseer word nie, gaan verlore. Dit wil sê, boodskappe wat nie deur die oorspronklike leier erken is in daardie paar sekondes toe twee leiers gewerk het nie, sal verlore gaan.
Rys. 29. Scenario 4. Die leier op makelaar 1 word 'n volger nadat die netwerk herstel is
Scenario 5: Die volgeling is heeltemal apart van beide ander Kafka-nodusse en Zookeeper
Die volgeling is heeltemal geïsoleer van beide ander Kafka-nodusse en Zookeeper. Hy verwyder homself eenvoudig van die ISR totdat die netwerk herstel is, en haal dan die ander in.

Rys. 30. Scenario 5: Geïsoleerde volger word van ISR verwyder
Scenario 6: Die leier is heeltemal apart van beide ander Kafka-nodusse en Zookeeper
Rys. 31. Scenario 6. Leier en twee volgelinge
Die leier is heeltemal geïsoleer van sy volgelinge, die beheerder en dieretuinwagter. Vir 'n kort tydperk sal dit voortgaan om inskrywings van te aanvaar acks=1.
Rys. 32. Scenario 6: Isoleer die leier van ander Kafka- en Zookeeper-nodes
Het nie versoeke na verstryking ontvang nie replika.lagtyd.maks.ms, sal dit probeer om die ISR vir homself te krimp, maar sal dit nie kan doen nie omdat daar geen kommunikasie met Zookeeper is nie, dan sal dit ophou om skryfwerk te aanvaar.
Intussen sal Zookeeper die geïsoleerde makelaar as dood merk en die kontroleerder sal 'n nuwe leier kies.
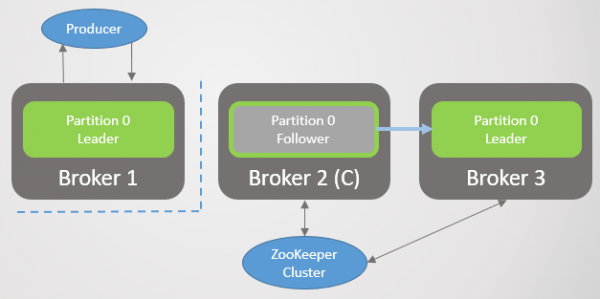
Rys. 33. Scenario 6. Twee leiers
Die oorspronklike leier kan inskrywings vir 'n paar sekondes aanvaar, maar hou dan op om enige boodskappe te aanvaar. Kliënte word elke 60 sekondes opgedateer met die nuutste metadata. Hulle sal van die leierverandering ingelig word en sal begin om inskrywings na die nuwe leier te stuur.
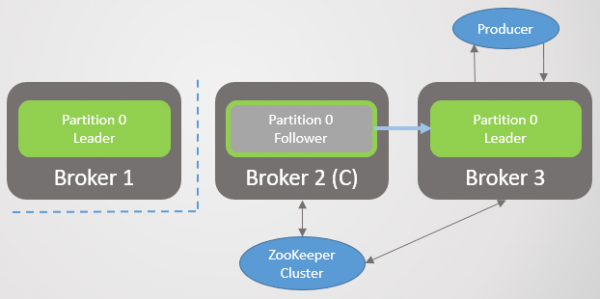
Rys. 34. Scenario 6: Vervaardigers skakel oor na 'n nuwe leier
Alle bevestigde inskrywings wat deur die oorspronklike leier gemaak is sedert die verlies van konneksie sal verlore gaan. Sodra die netwerk herstel is, sal die oorspronklike leier deur Zookeeper ontdek dat hy nie meer die leier is nie. Dan sal dit sy logboek na die HW van die nuwe leier afkap ten tyde van die verkiesing en begin om versoeke as 'n volger te stuur.
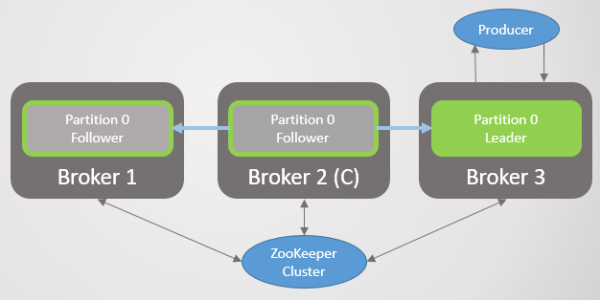
Rys. 35. Scenario 6: Die oorspronklike leier word 'n volger nadat netwerkverbinding herstel is
In hierdie situasie kan logiese skeiding vir 'n kort tydperk plaasvind, maar slegs indien acks=1 и min.insync.replikas ook 1. Logiese skeiding eindig outomaties óf nadat die netwerk herstel is, wanneer die oorspronklike leier besef dat hy nie meer die leier is nie, óf wanneer alle kliënte besef dat die leier verander het en begin skryf aan die nuwe leier - wat ook al eerste gebeur. In elk geval sal sommige boodskappe verlore gaan, maar slegs met acks=1.
Daar is nog 'n variant van hierdie scenario waar, net voor die netwerk verdeel het, die volgelinge agter geraak het en die leier die ISR net vir homself saamgepers het. Dit word dan geïsoleer as gevolg van verlies aan konnektiwiteit. 'n Nuwe leier word verkies, maar die oorspronklike leier gaan voort om selfs inskrywings te aanvaar acks = almal, want daar is niemand anders in ISR behalwe hy nie. Hierdie rekords sal verlore gaan sodra die netwerk herstel is. Die enigste manier om hierdie opsie te vermy, is min.insync.replikas = 2.
Scenario 7: Kafka-kontroleerderknoop kan nie 'n ander Kafka-knooppunt sien nie
Oor die algemeen, sodra die verbinding met 'n Kafka-nodus verloor is, sal die beheerder nie enige leierveranderingsinligting daaraan kan oordra nie. In die ergste geval sal dit lei tot 'n korttermyn logiese skeiding, soos in scenario 6. Meer dikwels as nie, sal die makelaar eenvoudig nie 'n kandidaat vir leierskap word as laasgenoemde misluk nie.
Scenario 8: Kafka-beheerder sien nie Zookeeper nie
Zookeeper sal nie 'n ping van die gevalle kontroleerder ontvang nie en sal 'n nuwe Kafka-nodus as die beheerder kies. Die oorspronklike beheerder kan voortgaan om homself as sodanig voor te stel, maar dit ontvang nie kennisgewings van Zookeeper nie, so dit sal geen take hê om uit te voer nie. Sodra die netwerk herstel is, sal hy besef dat hy nie meer 'n kontroleerder is nie, maar 'n gewone Kafka-knooppunt geword het.
Gevolgtrekkings uit die scenario's
Ons sien dat die verlies aan volgerverbinding nie tot boodskapverlies lei nie, maar bloot tydelik redundansie verminder totdat die netwerk herstel is. Dit kan natuurlik lei tot dataverlies as een of meer nodusse verlore gaan.
As die leier geskei word van Zookeeper as gevolg van 'n verlies aan konnektiwiteit, kan dit daartoe lei dat boodskappe verlore gaan van acks=1. Gebrek aan kommunikasie met Zookeeper veroorsaak 'n kort logiese skeuring met die twee leiers. Hierdie probleem word opgelos deur die parameter acks = almal.
Parameter min.insync.replikas in twee of meer replikas bied bykomende versekering dat sulke korttermyn-scenario's nie sal lei tot verlore boodskappe soos in Scenario 6 nie.
Opsomming van verlore boodskappe
Kom ons lys al die maniere waarop jy data in Kafka kan verloor:
- Enige leiermislukking as boodskappe bevestig is deur gebruik te maak acks=1
- Enige onrein oorgang van leierskap, dit wil sê na 'n volgeling buite die ISR, selfs met acks = almal
- Isoleer die leier van Zookeeper as boodskappe bevestig is deur gebruik te maak acks=1
- Volledige isolasie van die leier wat reeds die ISR-groep vir homself gekrimp het. Alle boodskappe sal selfs verlore gaan acks = almal. Dit is slegs waar as min.insync.replicas=1.
- Gelyktydige mislukkings van alle partisie nodusse. Omdat boodskappe uit die geheue erken word, is sommige dalk nog nie na skyf geskryf nie. Nadat die bedieners herlaai is, kan sommige boodskappe ontbreek.
Onsuiwer leierskapoorgange kan vermy word deur dit óf te verbied óf om ten minste twee afdankings te verseker. Die mees duursame konfigurasie is 'n kombinasie acks = almal и min.insync.replikas oor 1.
Direkte vergelyking van die betroubaarheid van RabbitMQ en Kafka
Om betroubaarheid en hoë beskikbaarheid te verseker, implementeer beide platforms 'n primêre en sekondêre replikasiestelsel. RabbitMQ het egter 'n Achilleshiel. Wanneer na 'n mislukking weer gekoppel word, gooi nodusse hul data weg en sinchronisasie word geblokkeer. Hierdie dubbele whammy bevraagteken die lang lewe van groot toue in RabbitMQ. Jy sal óf verminderde oortolligheid óf lang blokkeertye moet aanvaar. Die vermindering van oortolligheid verhoog die risiko van massiewe dataverlies. Maar as die toue klein is, kan kort periodes van onbeskikbaarheid ('n paar sekondes) ter wille van oortolligheid hanteer word deur herhaalde verbindingspogings te gebruik.
Kafka het nie hierdie probleem nie. Dit verwerp data slegs vanaf die punt van divergensie tussen die leier en die volger. Alle gedeelde data word gestoor. Boonop blokkeer replikasie nie die stelsel nie. Die leier gaan voort om poste te aanvaar terwyl die nuwe volgeling inhaal, so vir devops word om by die groep aan te sluit of weer aan te sluit 'n onbenullige taak. Natuurlik is daar steeds probleme soos netwerkbandwydte tydens replikasie. As jy verskeie volgelinge op dieselfde tyd byvoeg, kan jy 'n bandwydtelimiet teëkom.
RabbitMQ is beter as Kafka in betroubaarheid wanneer veelvuldige bedieners in 'n groep op dieselfde tyd misluk. Soos ons reeds gesê het, stuur RabbitMQ eers 'n bevestiging aan die uitgewer nadat die boodskap deur die meester en alle spieëls op skyf geskryf is. Maar dit voeg bykomende vertraging by om twee redes:
- fsync elke paar honderd millisekondes
- Die mislukking van die spieël kan eers opgemerk word nadat die leeftyd van die pakkies wat die beskikbaarheid van elke nodus kontroleer (netto merk) verstryk het. As die spieël stadiger word of val, voeg dit 'n vertraging by.
Kafka se weddenskap is dat as 'n boodskap oor verskeie nodusse gestoor word, dit boodskappe kan erken sodra hulle geheue tref. As gevolg hiervan is daar 'n risiko om boodskappe van enige aard te verloor (selfs acks = almal, min.insync.replicas=2) in geval van gelyktydige mislukking.
Oor die algemeen toon Kafka beter sagtewareprestasie en is van die grond af ontwerp vir groepe. Die aantal volgers kan tot 11 verhoog word indien nodig vir betroubaarheid. Replikasiefaktor 5 en minimum aantal replikas in sinchronisasie min.insync.replicas=3 sal boodskapverlies 'n baie seldsame gebeurtenis maak. As u infrastruktuur hierdie replikasieverhouding en vlak van oortolligheid kan ondersteun, kan u hierdie opsie kies.
RabbitMQ-groepering is goed vir klein toue. Maar selfs klein toue kan vinnig groei wanneer daar swaar verkeer is. Sodra toue groot word, sal jy moeilike keuses moet maak tussen beskikbaarheid en betroubaarheid. RabbitMQ-groepering is die beste geskik vir nie-tipiese situasies waar die voordele van RabbitMQ se buigsaamheid swaarder weeg as enige nadele van sy groepering.
Een teenmiddel teen RabbitMQ se kwesbaarheid vir groot toue is om dit in baie kleiner toue op te breek. As jy nie volledige bestelling van die hele tou benodig nie, maar slegs die relevante boodskappe (byvoorbeeld boodskappe van 'n spesifieke kliënt), of glad niks bestel nie, dan is hierdie opsie aanvaarbaar: kyk na my projek om die tou te verdeel (die projek is nog in 'n vroeë stadium).
Ten slotte, moenie vergeet van 'n aantal foute in die groepering en replikasie meganismes van beide RabbitMQ en Kafka. Met verloop van tyd het stelsels meer volwasse en stabiel geword, maar geen boodskap sal ooit 100% veilig wees teen verlies nie! Boonop vind grootskaalse ongelukke in datasentrums plaas!
As ek iets gemis het, 'n fout gemaak het, of jy verskil met enige van die punte, skryf gerus 'n opmerking of kontak my.
Ek word gereeld gevra: “Wat om te kies, Kafka of RabbitMQ?”, “Watter platform is beter?”. Die waarheid is dat dit regtig afhang van jou situasie, huidige ervaring, ens. Ek is huiwerig om my mening te gee, want dit sal te veel van 'n oorvereenvoudiging wees om een platform vir alle gebruiksgevalle en moontlike beperkings aan te beveel. Ek het hierdie reeks artikels geskryf sodat jy jou eie mening kan vorm.
Ek wil sê dat beide stelsels leiers op hierdie gebied is. Ek is dalk 'n bietjie bevooroordeeld, want uit my ervaring met projekte is ek geneig om dinge soos gewaarborgde boodskapordening en betroubaarheid te waardeer.
Ek sien ander tegnologieë wat nie hierdie betroubaarheid en gewaarborgde ordening het nie, dan kyk ek na RabbitMQ en Kafka en besef die ongelooflike waarde van beide hierdie stelsels.
Bron: will.com
