

Onthou dat die Elastic Stack gebaseer is op die nie-relasionele databasis Elasticsearch, die Kibana-webkoppelvlak en dataversamelaars (die bekendste Logstash, verskeie Beats, APM en ander). Een van die lekker toevoegings tot die hele produkstapel wat gelys is, is data-analise met behulp van masjienleeralgoritmes. In die artikel verstaan ons wat hierdie algoritmes is. Asseblief onder kat.
Masjienleer is 'n betaalde kenmerk van die deelware Elastic Stack en is by die X-Pack ingesluit. Om dit te begin gebruik, is dit genoeg om 'n proeftydperk van 30 dae na installasie te aktiveer. Nadat die proeftydperk verstryk het, kan u ondersteuning versoek om dit te hernu of 'n intekening te koop. Die intekeningprys word nie op die hoeveelheid data bereken nie, maar op die aantal nodusse wat gebruik word. Nee, die hoeveelheid data beïnvloed natuurlik die aantal vereiste nodusse, maar tog is hierdie benadering tot lisensiëring meer menslik in verhouding tot die maatskappy se begroting. As daar geen behoefte aan hoë werkverrigting is nie, kan jy geld spaar.
ML in die Elastic Stack is geskryf in C++ en loop buite die JVM waarin Elasticsearch self loop. Dit wil sê, die proses (terloops, dit word outodetectie genoem) verbruik alles wat die JVM nie sluk nie. Op 'n demonstrasie-stand is dit nie so krities nie, maar in 'n produktiewe omgewing is dit belangrik om aparte nodusse vir ML-take toe te ken.
Masjienleeralgoritmes val in twee kategorieë - и . In Elastic Stack is die algoritme van die kategorie "ontoesig". Deur U kan die wiskundige apparaat van masjienleeralgoritmes sien.
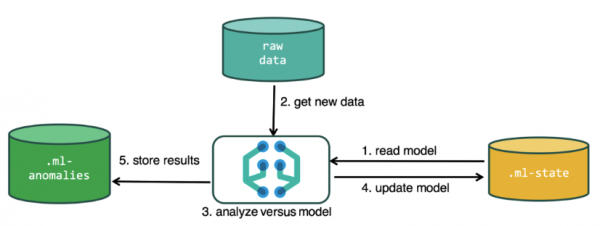
Die masjienleeralgoritme gebruik data wat in Elasticsearch-indekse gestoor is om analise uit te voer. U kan take vir ontleding skep vanaf die Kibana-koppelvlak en deur die API. As jy dit deur Kibana doen, hoef jy sekere dinge nie te weet nie. Byvoorbeeld, bykomende indekse wat die algoritme tydens werking gebruik.
Bykomende indekse wat in die ontledingsproses gebruik word.ml-staat - inligting oor statistiese modelle (analise-instellings);
.ml-anomalies-* - resultate van ML-algoritmes;
.ml-kennisgewings — kennisgewinginstellings gebaseer op ontledingsresultate.
Die datastruktuur in die Elasticsearch-databasis bestaan uit indekse en die dokumente wat daarin gestoor is. In vergelyking met 'n relasionele databasis, kan 'n indeks vergelyk word met 'n databasisskema, en 'n dokument met 'n rekord in 'n tabel. Hierdie vergelyking is voorwaardelik en word gegee om die begrip van verdere materiaal te vereenvoudig vir diegene wat net van Elasticsearch gehoor het.
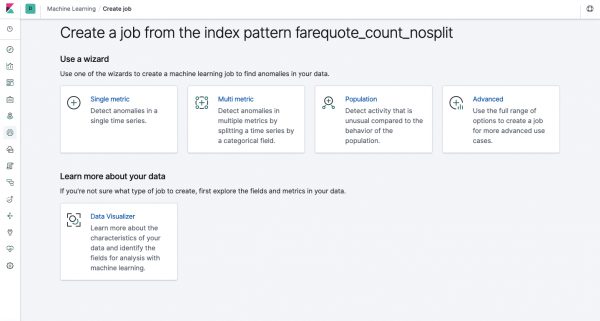
Dieselfde funksionaliteit is beskikbaar deur die API as deur die webkoppelvlak, so vir duidelikheid en begrip van die konsepte, sal ons wys hoe om deur Kibana op te stel. In die kieslys aan die linkerkant is daar 'n Masjienleer-afdeling, waarin jy 'n nuwe werk (Job) kan skep. In die Kibana-koppelvlak lyk dit soos die prentjie hieronder. Nou gaan ons elke tipe taak ontleed en die tipes analise wys wat hier gekonstrueer kan word.
Enkele metrieke - ontleding van een metrieke, Multi Metrieke - ontleding van twee of meer metrieke. In beide gevalle word elke metriek in 'n geïsoleerde omgewing ontleed, m.a.w. die algoritme neem nie die gedrag van metrieke wat parallel ontleed word in ag nie, soos dit in die geval van Multi Metric mag lyk. Om te bereken met inagneming van die korrelasie van verskeie metrieke, kan jy die Bevolkingsanalise toepas. En Advanced is 'n fyninstelling van algoritmes met bykomende opsies vir sekere take.
Enkelmetriek
Die ontleding van veranderinge in een enkele maatstaf is die maklikste ding om hier te doen. Nadat u op Create Job geklik het, sal die algoritme na anomalieë soek.
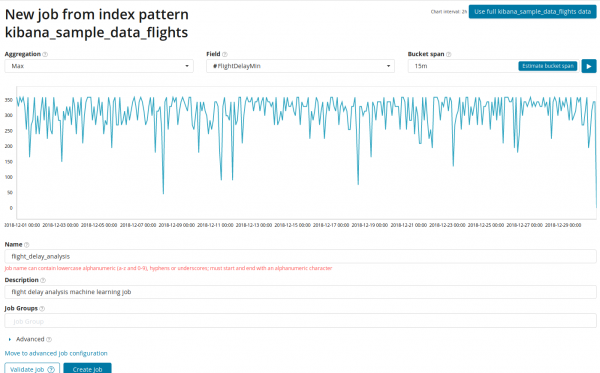
In die veld samevoeging jy kan die benadering kies om na anomalieë te soek. Byvoorbeeld, wanneer Min waardes onder die tipiese waardes sal as abnormaal beskou word. Eet Maksimum, hoog gemiddelde, laag, gemiddelde, duidelik en ander. Beskrywing van alle funksies kan gevind word .
In die veld Veld die numeriese veld in die dokument word aangedui, waarvolgens ons die ontleding sal uitvoer.
In die veld - die korreligheid van die gapings op die tydlyn, waarvolgens die ontleding uitgevoer sal word. U kan die outomatisering vertrou of handmatig kies. Die prent hieronder toon 'n voorbeeld van te lae korreligheid - jy kan die anomalie mis. Met hierdie instelling kan jy die sensitiwiteit van die algoritme vir anomalieë verander.
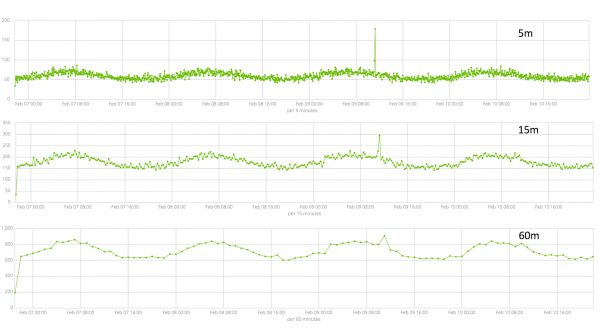
Die tydsduur van die versamelde data is 'n sleutelsaak wat die doeltreffendheid van die analise beïnvloed. Tydens die analise bepaal die algoritme herhalende gapings, bereken die vertrouensinterval (basislyne) en bespeur anomalieë - atipiese afwykings van die gewone gedrag van die metrieke. Net byvoorbeeld:
Grondlyne vir 'n klein datasegment:
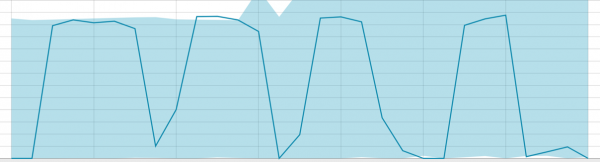
Wanneer die algoritme iets het om van te leer, lyk die basislyne soos volg:
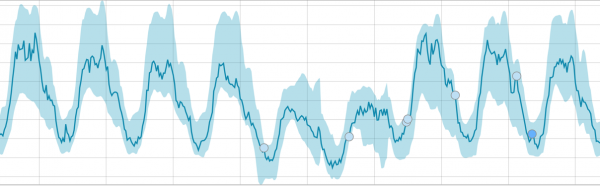
Nadat die taak begin is, bepaal die algoritme abnormale afwykings van die norm en rangskik dit volgens die waarskynlikheid van anomalie (die kleur van die ooreenstemmende etiket word tussen hakies aangedui):
Waarskuwing (blou): minder as 25
Minor (geel): 25-50
Majoor (oranje): 50-75
Kritiek (rooi): 75-100
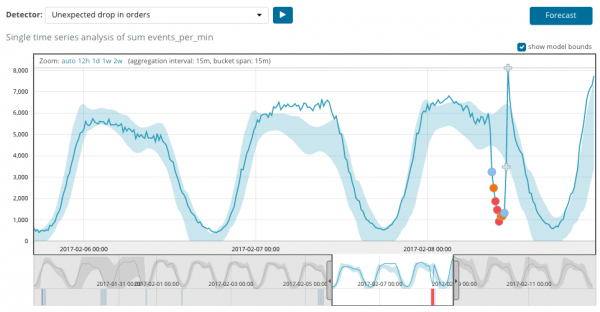
Die grafiek hieronder toon 'n voorbeeld met die gevind afwykings.
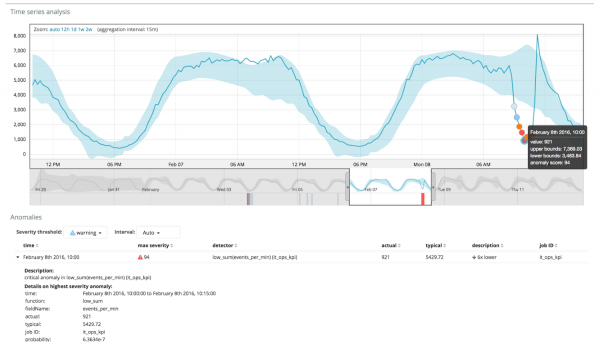
Hier kan jy die nommer 94 sien, wat die waarskynlikheid van 'n anomalie aandui. Dit is duidelik dat aangesien die waarde naby aan 100 is, ons 'n anomalie het. Die kolom onder die grafiek dui 'n pejoratief klein waarskynlikheid aan van 0.000063634% van die metrieke waarde wat daar verskyn.
Benewens om na afwykings in Kibana te soek, kan jy voorspellings uitvoer. Dit word elementêr gedoen en vanuit dieselfde voorstelling met anomalieë - die knoppie Voorspelling in die regter boonste hoek.
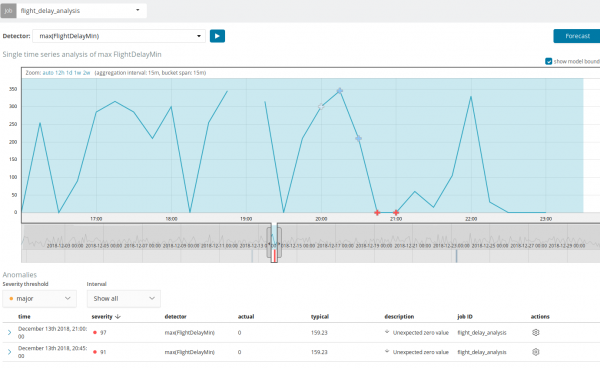
Die voorspelling word opgebou tot 8 weke vooruit. Selfs as jy regtig wil, kan jy nie meer ontwerp nie.
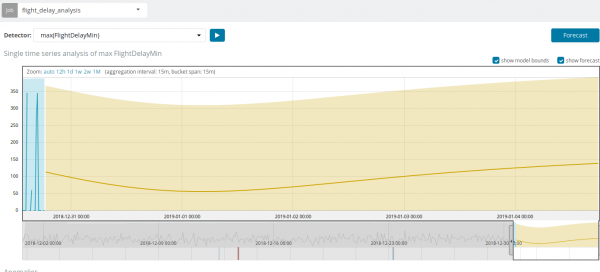
In sommige situasies sal die voorspelling baie nuttig wees, byvoorbeeld wanneer die gebruikerslading op die infrastruktuur gemonitor word.
MultiMetric
Kom ons gaan aan na die volgende ML-kenmerk in Elastic Stack - die ontleding van verskeie metrieke in een bondel. Maar dit beteken nie dat die afhanklikheid van een metriek van 'n ander ontleed sal word nie. Dit is slegs dieselfde as Enkelmetriek met veelvuldige metrieke op een skerm vir maklike vergelyking van die impak van een op 'n ander. Ons sal praat oor die ontleding van die afhanklikheid van een metriek van 'n ander in die Bevolkingsdeel.
Nadat u op die vierkant met Multi Metric geklik het, sal 'n venster met instellings verskyn. Laat ons in meer detail oor hulle stilstaan.
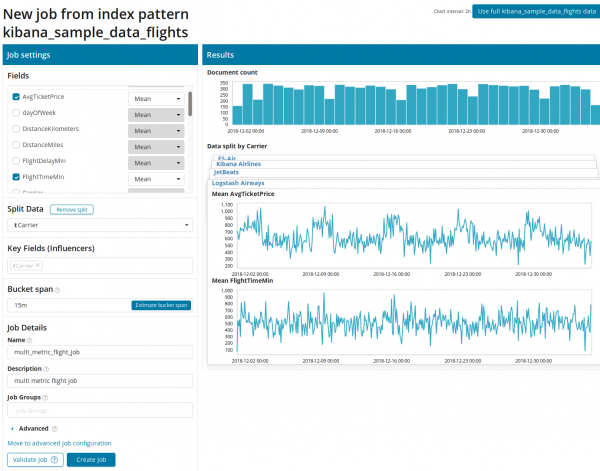
Eerstens moet jy die velde vir ontleding en die samevoeging van data daaroor kies. Die samevoegingsopsies hier is dieselfde as vir Enkelmetriek (Maksimum, hoog gemiddelde, laag, gemiddelde, duidelik en ander). Verder word die data, indien verlang, in een van die velde (veld data verdeel). In die voorbeeld het ons dit regoor die veld gedoen OriginAirportID. Let daarop dat die metrieke grafiek aan die regterkant nou as 'n stel grafieke voorgestel word.
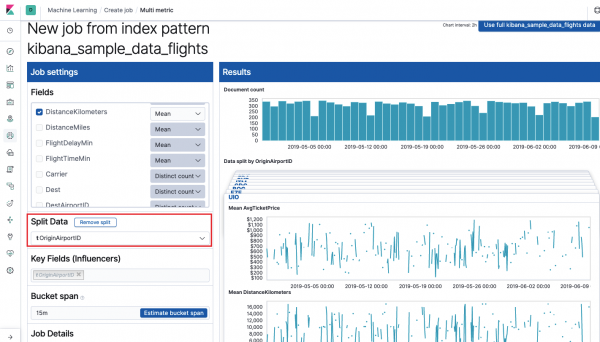
Veld Sleutelvelde (beïnvloeders) affekteer die gevind afwykings direk. By verstek sal daar altyd ten minste een waarde wees, en jy kan meer byvoeg. Die algoritme sal die invloed van hierdie velde in die analise in ag neem en die mees "invloedryke" waardes toon.
Na bekendstelling sal die volgende prentjie in die Kibana-koppelvlak verskyn.
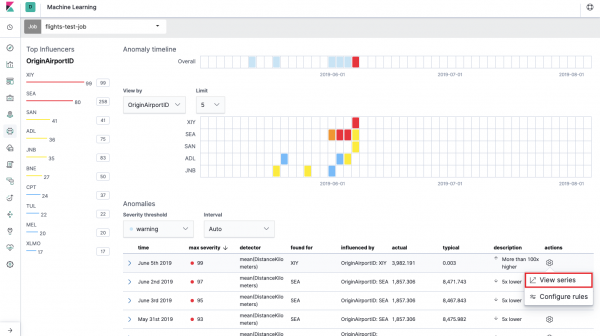
Dit is die sogenaamde. hittekaart van anomalieë vir elke veldwaarde OriginAirportIDwat ons in aangedui het data verdeel. Soos met Enkelmetriek, dui die kleur die vlak van uitskieter aan. Dit is gerieflik om 'n soortgelyke ontleding te doen, byvoorbeeld op werkstasies om dié op te spoor waar daar verdagte baie magtigings is, ens. Ons het reeds geskryf , wat ook hier versamel en ontleed kan word.
Onder die hittekaart is 'n lys van afwykings, van elkeen kan jy na die Enkelmetriese aansig gaan vir gedetailleerde ontleding.
bevolking
Om na anomalieë tussen korrelasies tussen verskillende maatstawwe te soek, het die Elastiese Stapel 'n gespesialiseerde Bevolkingsanalise. Dit is met behulp daarvan dat 'n mens kan soek na abnormale waardes in die werkverrigting van 'n bediener in vergelyking met die res wanneer, byvoorbeeld, 'n toename in die aantal versoeke na die teikenstelsel.
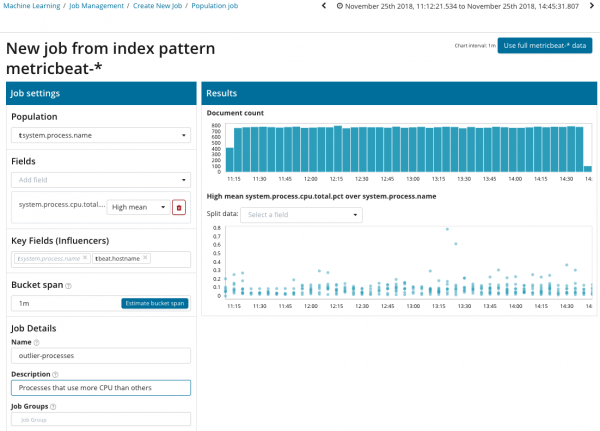
In hierdie illustrasie dui die Bevolking-veld die waarde aan waarna die geanaliseerde maatstawwe sal verwys. In hierdie geval is dit die naam van die proses. As gevolg hiervan sal ons sien hoe die verwerkerlading van elk van die prosesse mekaar beïnvloed het.
Neem asseblief kennis dat die plot van die geanaliseerde data verskil van die gevalle met Enkelmetriek en Multi Metriek. Dit word deur ontwerp in Kibana gedoen om die persepsie van die verspreiding van die waardes van die geanaliseerde data te verbeter.
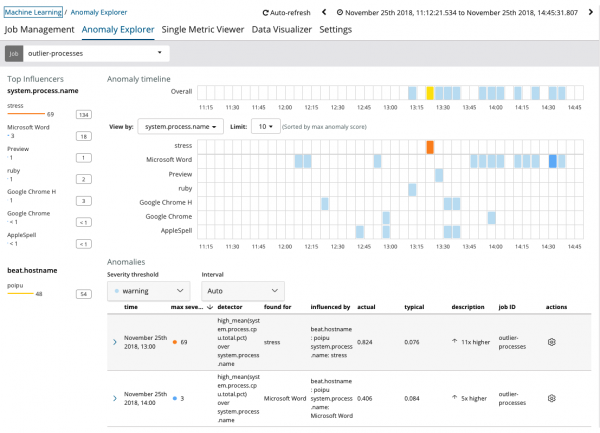
Die grafiek toon dat die proses abnormaal opgetree het stres (terloops, gegenereer deur 'n spesiale hulpprogram) op die bediener poipu, wat die voorkoms van hierdie anomalie beïnvloed het (of geblyk het 'n beïnvloeder te wees).
Gevorderde
Analytics met fyn tuning. Met Gevorderde analise in Kibana verskyn bykomende instellings. Nadat u op die Gevorderde-teël in die skepkieslys geklik het, verskyn die volgende oortjievenster. oortjie werk besonderhede doelbewus oorgeslaan, is daar basiese instellings wat nie direk verband hou met die analise-opstelling nie.
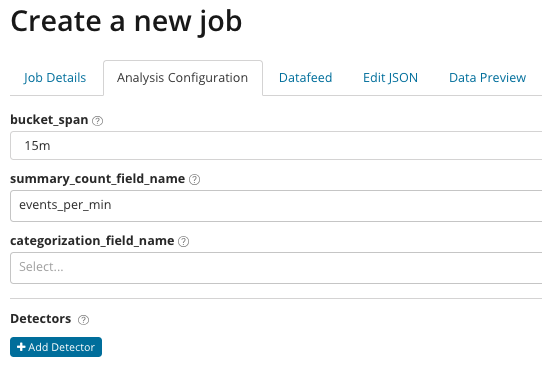
В summary_count_field_name opsioneel kan jy die naam van die veld spesifiseer uit die dokumente wat die saamgevoegde waardes bevat. In hierdie voorbeeld, die aantal gebeurtenisse per minuut. IN spesifiseer die naam van die waarde van die veld uit die dokument, wat een of ander veranderlike waarde bevat. Deur die masker op hierdie veld kan jy die geanaliseerde data in substelle verdeel. Gee aandag aan die knoppie Voeg detektor by in die vorige illustrasie. Hieronder is die resultaat van die klik op hierdie knoppie.
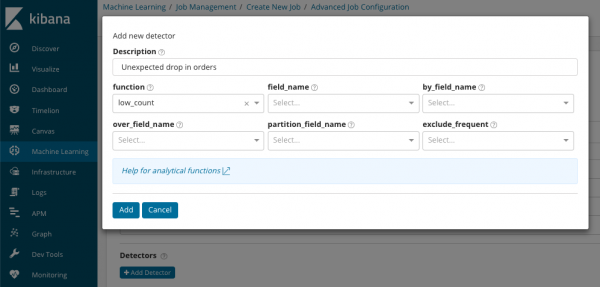
Hier is 'n bykomende blok instellings vir die opstel van die anomalie detector vir 'n spesifieke taak. Ons beplan om spesifieke gebruiksgevalle (veral sekuriteitsgevalle) in die volgende artikels te ontleed. Byvoorbeeld, een van die gevallestudies. Dit word geassosieer met die soeke na waardes wat selde voorkom en word geïmplementeer .
In die veld funksie jy kan 'n spesifieke funksie kies om na afwykings te soek. Behalwe skaars, daar is 'n paar interessante funksies - . Hulle openbaar onreëlmatighede in die gedrag van metrieke deur die dag of week, onderskeidelik. Ander analise funksies .
В veld naam die veld van die dokument waarvolgens die ontleding uitgevoer sal word, word aangedui. By_veldnaam kan gebruik word om die ontledingsresultate vir elke individuele waarde van die dokumentveld wat hier gespesifiseer word, te skei. As vul oor_veldnaam ons kry die bevolkingsanalise, wat ons hierbo oorweeg het. As jy 'n waarde spesifiseer in partisieveldnaam, dan sal aparte basislyne vir elke waarde vir hierdie veld van die dokument bereken word (byvoorbeeld, die naam van die bediener of proses op die bediener kan as 'n waarde optree). IN sluit_gereelde uit kan kies almal of niemand, wat sou beteken die uitsluiting (of insluiting van) algemeen voorkomende dokumentveldwaardes.
In die artikel het ons probeer om die mees bondige idee te gee van die moontlikhede van masjienleer in die Elastic Stack, daar is nog baie besonderhede agter die skerms. Vertel ons in die opmerkings watter gevalle jy daarin geslaag het om met behulp van Elastic Stack op te los en vir watter take jy dit gebruik. Om ons te kontak, kan jy privaat boodskappe op Habré of .
Bron: will.com
