

Daar is situasies wanneer na 'n tabel sonder 'n primêre sleutel of 'n ander unieke indeks, as gevolg van 'n toesig, word volledige klone van reeds bestaande rekords ingesluit.

Byvoorbeeld, die waardes van 'n chronologiese metrieke word in PostgreSQL geskryf met 'n COPY-stroom, en dan is daar 'n skielike mislukking, en 'n deel van die heeltemal identiese data kom weer aan.
Hoe om die databasis van onnodige klone ontslae te raak?
Wanneer PK nie 'n helper is nie
Die maklikste manier is om te verhoed dat so 'n situasie in die eerste plek voorkom. Rol byvoorbeeld PRIMÊRE SLEUTEL. Maar dit is nie altyd moontlik sonder om die volume gestoorde data te verhoog nie.
Byvoorbeeld, as die akkuraatheid van die bronstelsel hoër is as die akkuraatheid van die veld in die databasis:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
Het jy opgemerk? Die aftelling in plaas van 00:00:02 is 'n sekonde vroeër in die databasis aangeteken met ts, maar het redelik geldig gebly vanuit 'n toepassingsoogpunt (die datawaardes is immers anders!).
Natuurlik kan jy dit doen PK(metriek, ts) - maar dan sal ons invoegingskonflikte kry vir geldige data.
Kan doen PK(metriek, ts, data) - maar dit sal die volume daarvan aansienlik verhoog, wat ons nie sal gebruik nie.
Daarom is die mees korrekte opsie om 'n gereelde nie-unieke indeks te maak (metriek, ts) en probleme agterna te hanteer as dit wel opduik.
"Die kloniese oorlog het begin"
Een of ander ongeluk het gebeur, en nou moet ons die kloonrekords van die tafel af vernietig.

Kom ons modelleer die oorspronklike data:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;Hier het ons hand drie keer gebewe, Ctrl+V het vasgesit, en nou...
Eerstens, laat ons verstaan dat ons tafel baie groot kan wees, so nadat ons al die klone gevind het, is dit raadsaam dat ons letterlik "ons vinger steek" om uit te vee spesifieke rekords sonder om dit weer te deursoek.
En daar is so 'n manier - hierdie , die fisiese identifiseerder van 'n spesifieke rekord.
Dit wil sê, eerstens moet ons die ctid van rekords insamel in die konteks van die volledige inhoud van die tabelry. Die eenvoudigste opsie is om die hele reël in teks te gooi:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
Is dit moontlik om nie te gooi nie?In beginsel is dit in die meeste gevalle moontlik. Totdat jy velde in hierdie tabel begin gebruik tipes sonder gelykheidsoperateur:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
Ja, ons sien dadelik dat as daar meer as een inskrywing in die skikking is, dit almal klone is. Kom ons los hulle net:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)Vir diegene wat daarvan hou om korter te skryfJy kan dit ook so skryf:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;Aangesien die waarde van die reeksreeks self nie vir ons interessant is nie, het ons dit eenvoudig uit die teruggekeerde kolomme van die subnavraag gegooi.
Daar is net 'n bietjie oor om te doen - laat DELETE die stel gebruik wat ons ontvang het:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);Kom ons kyk na onsself:
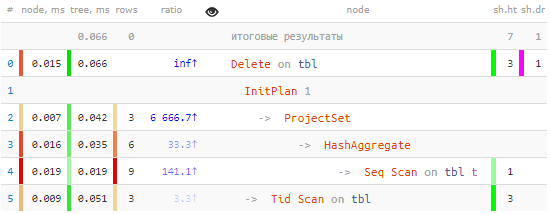
Ja, alles is korrek: ons 3 rekords is gekies vir die enigste Seq Scan van die hele tabel, en die Delete node is gebruik om data te soek enkele pas met Tid Scan:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))As jy baie rekords uitgevee het, .
Kom ons kyk vir 'n groter tabel en met 'n groter aantal duplikate:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
Die metode werk dus suksesvol, maar dit moet met omsigtigheid gebruik word. Want vir elke rekord wat uitgevee word, is daar een databladsy wat in Tid Scan gelees word, en een in Delete.
Bron: will.com
