


በVMware vSphere (ወይም ሌላ ማንኛውም የቴክኖሎጂ ቁልል) ላይ በመመስረት ምናባዊ መሠረተ ልማትን የምታስተዳድሩት ከሆነ፣ ምናልባት ብዙውን ጊዜ ከተጠቃሚዎች ቅሬታዎችን ትሰሙ ይሆናል፡ “ምናባዊ ማሽኑ ቀርፋፋ ነው!” በዚህ ተከታታይ መጣጥፎች ውስጥ የአፈፃፀም መለኪያዎችን እመረምራለሁ እና ምን እና ለምን እንደሚቀንስ እና እንዴት እንደማይቀንስ እነግርዎታለሁ።
የሚከተሉትን የቨርቹዋል ማሽን አፈጻጸም ገፅታዎች ግምት ውስጥ አስገባለሁ፡
- ሲፒዩ ፣
- ፈረስ ፣
- ዲስክ፣
- አውታረ መረብ.
በሲፒዩ እጀምራለሁ.
አፈፃፀሙን ለመተንተን እኛ ያስፈልገናል-
- vCenter የአፈጻጸም ቆጣሪዎች - የአፈፃፀም ቆጣሪዎች ፣ የእነሱ ግራፎች በ vSphere ደንበኛ በኩል ሊታዩ ይችላሉ። በእነዚህ ቆጣሪዎች ላይ ያለው መረጃ በማንኛውም የደንበኛው ስሪት ("ወፍራም" ደንበኛ በ C #፣ የድር ደንበኛ በFlex እና የድር ደንበኛ በ HTML5) ይገኛል። በእነዚህ መጣጥፎች ውስጥ ከ C # ደንበኛ ቅጽበታዊ ገጽ እይታዎችን እንጠቀማለን ፣ ምክንያቱም እነሱ በትንሹ የተሻሉ ስለሚመስሉ ብቻ :)
- ESXTOP - ከ ESXi ትዕዛዝ መስመር የሚሰራ መገልገያ። በእሱ እርዳታ የአፈፃፀም ቆጣሪዎችን በቅጽበት ማግኘት ወይም እነዚህን እሴቶች ለተወሰነ ጊዜ ወደ .csv ፋይል ለተጨማሪ ትንተና መስቀል ይችላሉ። በመቀጠል, ስለዚህ መሳሪያ የበለጠ እነግርዎታለሁ እና በርዕሱ ላይ ለሰነዶች እና ለጽሁፎች በርካታ ጠቃሚ አገናኞችን እሰጣለሁ.
ጥቂት ንድፈ-ሐሳቦች
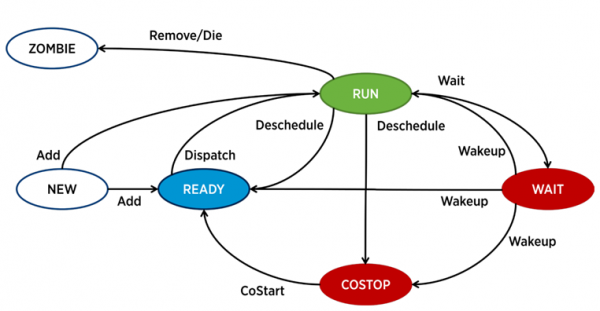
በ ESXi ውስጥ፣ የተለየ ሂደት - ዓለም በ VMware ቃላት - ለእያንዳንዱ vCPU (ምናባዊ ማሽን ኮር) አሠራር ተጠያቂ ነው። የአገልግሎት ሂደቶችም አሉ, ነገር ግን የቪኤም አፈፃፀምን ከመተንተን አንጻር ሲታይ ብዙም ትኩረት የሚስቡ አይደሉም.
በESXi ውስጥ ያለ ሂደት ከአራቱ ግዛቶች በአንዱ ሊሆን ይችላል፡-
- ሩጫ - ሂደቱ አንዳንድ ጠቃሚ ስራዎችን ያከናውናል.
- ጠብቅ - ሂደቱ ምንም ስራ እየሰራ አይደለም (ስራ ፈት) ወይም ግብዓት/ውጤት እየጠበቀ ነው።
- ወጪ - በባለብዙ-ኮር ምናባዊ ማሽኖች ውስጥ የሚከሰት ሁኔታ. የሚከሰተው የሃይፐርቪዘር ሲፒዩ መርሐግብር አዘጋጅ (ESXi CPU Scheduler) የሁሉም ንቁ የቨርቹዋል ማሽን ኮሮች በአካላዊ አገልጋይ ኮሮች ላይ በአንድ ጊዜ እንዲፈፀሙ መርሐግብር በማይሰጥበት ጊዜ ነው። በአካላዊው አለም ሁሉም ፕሮሰሰር ኮሮች በትይዩ ይሰራሉ፣ በቪኤም ውስጥ ያለው የእንግዳ ስርዓተ ክወና ተመሳሳይ ባህሪን ይጠብቃል፣ ስለዚህ ሃይፐርቫይዘር የሰዓት ዑደታቸውን በፍጥነት የመጨረስ አቅም ያላቸውን የVM ኮሮች ፍጥነት መቀነስ አለበት። በዘመናዊ የ ESXi ስሪቶች የሲፒዩ መርሐግብር አዘጋጅ ዘና ያለ አብሮ መርሐግብር የሚባል ዘዴ ይጠቀማል፡ ሃይፐርቫይዘር በ"ፈጣኑ" እና "ቀስ ብሎ" በምናባዊ ማሽን ኮር (skew) መካከል ያለውን ክፍተት ይመለከታል። ክፍተቱ ከተወሰነ ገደብ በላይ ከሆነ, ፈጣን ኮር ወደ ኮስታፕ ግዛት ውስጥ ይገባል. የቪኤም ኮሮች በዚህ ሁኔታ ብዙ ጊዜ ካሳለፉ የአፈጻጸም ችግሮችን ሊያስከትል ይችላል።
- ዝግጁ - ሂደቱ ወደዚህ ሁኔታ የሚገባው ሃይፐርቫይዘር ለተፈፃሚው ግብዓት መመደብ በማይችልበት ጊዜ ነው። ከፍተኛ ዝግጁ የሆኑ ዋጋዎች የቪኤም አፈጻጸም ችግሮችን ሊያስከትሉ ይችላሉ.
መሰረታዊ የቨርቹዋል ማሽን ሲፒዩ አፈጻጸም ቆጣሪዎች
የሲፒዩ አጠቃቀም፣% ለተወሰነ ክፍለ ጊዜ የሲፒዩ አጠቃቀም መቶኛን ያሳያል።
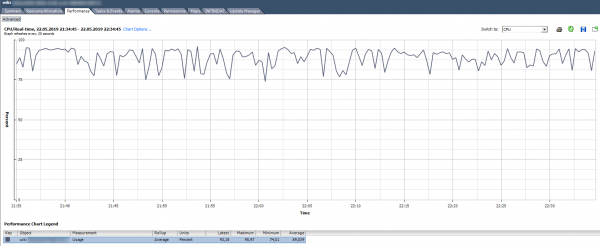
እንዴት መተንተን ይቻላል? VM በተከታታይ ሲፒዩ በ90% የሚጠቀም ከሆነ ወይም እስከ 100% የሚደርሱ ቁንጮዎች ካሉ ችግር አለብን። ችግሮች ሊገለጹ የሚችሉት በ VM ውስጥ ባለው የመተግበሪያው "ቀስ በቀስ" አሠራር ላይ ብቻ ሳይሆን በአውታረ መረቡ ላይ የቪኤም ተደራሽነት አለመቻሉም ጭምር ነው። የክትትል ስርዓቱ ቪኤም በየጊዜው እንደሚወድቅ ካሳየ በሲፒዩ አጠቃቀም ግራፍ ውስጥ ላሉት ጫፎች ትኩረት ይስጡ።
የቨርቹዋል ማሽኑን የሲፒዩ ጭነት የሚያሳይ መደበኛ ማንቂያ አለ፡-

ምን ማድረግ አለብኝ? የቪኤም ሲፒዩ አጠቃቀም በቋሚነት በጣሪያው ውስጥ የሚያልፍ ከሆነ የvCPUs ብዛት ስለማሳደግ (እንደ እድል ሆኖ ይህ ሁልጊዜ አይረዳም) ወይም ቪኤምን የበለጠ ኃይለኛ ፕሮሰሰር ወዳለው አገልጋይ ስለማንቀሳቀስ ማሰብ ይችላሉ።
የሲፒዩ አጠቃቀም በ MHz
በ% vCenter አጠቃቀም ላይ ባሉት ግራፎች ውስጥ ማየት የሚችሉት ለመላው ቨርቹዋል ማሽን ብቻ ነው፤ ለግለሰብ ኮሮች ምንም ግራፎች የሉም (በኤስክስቶፕ ውስጥ ለኮሮች % እሴቶች አሉ።) ለእያንዳንዱ ኮር በMHz ውስጥ አጠቃቀምን ማየት ይችላሉ።
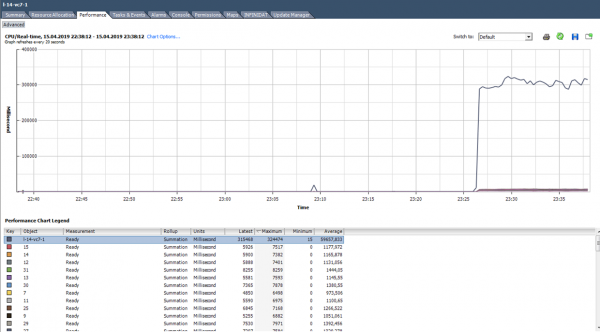
እንዴት መተንተን ይቻላል? አንድ መተግበሪያ ለባለብዙ-ኮር አርክቴክቸር አለመመቻቸቱ ይከሰታል፡ አንድ ኮር 100% ብቻ ነው የሚጠቀመው፣ የተቀረው ደግሞ ያለ ጭነት ነው። ለምሳሌ፣ በነባሪ የመጠባበቂያ ቅንጅቶች፣ MS SQL ሂደቱን በአንድ ኮር ብቻ ይጀምራል። በውጤቱም, የመጠባበቂያ ቅጂው በዲስኮች ቀርፋፋ ፍጥነት ምክንያት አይደለም (ይህ ተጠቃሚው መጀመሪያ ላይ ቅሬታ ያቀረበበት ነው), ነገር ግን ፕሮሰሰሩ መቋቋም ስለማይችል. ችግሩ የተቀረፈው ግቤቶችን በመለወጥ ነው: መጠባበቂያ በበርካታ ፋይሎች (በቅደም ተከተል, በበርካታ ሂደቶች) በትይዩ መስራት ጀመረ.
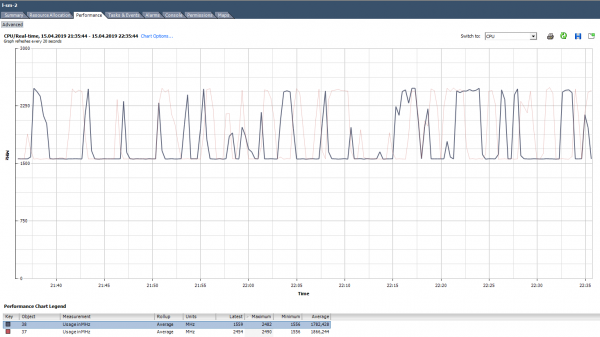
በኮሮች ላይ ያልተስተካከለ ጭነት ምሳሌ።
በተጨማሪም (ከላይ ባለው ግራፍ ላይ እንደተገለጸው) ኮርሶቹ በትክክል ሳይጫኑ ሲጫኑ እና አንዳንዶቹ 100% ከፍተኛ ደረጃ ላይ ሲደርሱ አንድ ሁኔታ አለ. ልክ እንደ አንድ ኮር ብቻ መጫን፣ የሲፒዩ አጠቃቀም ማንቂያው አይሰራም (ለጠቅላላው VM ነው) ግን የአፈጻጸም ችግሮች አሉ።
ምን ማድረግ አለብኝ? በቨርቹዋል ማሽን ውስጥ ያሉት ሶፍትዌሮች ኮርሶቹን እኩል ከጫኑ (አንድ ኮር ወይም የኮርኖቹን ክፍል ብቻ ይጠቀማል) ቁጥራቸውን መጨመር ምንም ፋይዳ የለውም። በዚህ አጋጣሚ ቪኤምን የበለጠ ኃይለኛ ፕሮሰሰር ወዳለው አገልጋይ ማንቀሳቀስ የተሻለ ነው።
እንዲሁም በአገልጋዩ ባዮስ ውስጥ የኃይል ፍጆታ ቅንብሮችን ለመፈተሽ መሞከር ይችላሉ. ብዙ አስተዳዳሪዎች ከፍተኛ አፈጻጸም ሁነታን በባዮስ ውስጥ ያንቁ እና በዚህም የC-states እና P-states ሃይል ቆጣቢ ቴክኖሎጂዎችን ያሰናክላሉ። ዘመናዊ የኢንቴል ፕሮሰሰሮች የ Turbo Boost ቴክኖሎጂን ይጠቀማሉ ፣ይህም የግለሰቦችን ፕሮሰሰር ኮሮች ብዛት በሌሎች ኮርሶች ወጪ ይጨምራል። ነገር ግን ኃይል ቆጣቢ ቴክኖሎጂዎች ሲበሩ ብቻ ነው የሚሰራው. እነሱን ካሰናከልን, ፕሮሰሰር ያልተጫኑትን የኮርሶችን የኃይል ፍጆታ መቀነስ አይችልም.
VMware በአገልጋዮች ላይ የኃይል ቆጣቢ ቴክኖሎጂዎችን ላለማሰናከል ይመክራል፣ ነገር ግን በተቻለ መጠን የኃይል አስተዳደርን ለሃይፐርቫይዘር የሚተዉ ሁነታዎችን ይመርጣል። በዚህ ሁኔታ, በሃይፐርቫይዘር የኃይል ፍጆታ ቅንጅቶች ውስጥ, ከፍተኛ አፈፃፀምን መምረጥ ያስፈልግዎታል.
በመሰረተ ልማትዎ ውስጥ የሲፒዩ ፍሪኩዌንሲ የሚጠይቁ ነጠላ ቪኤም (ወይም ቪኤም ኮሮች) ካሉዎት የኃይል ፍጆታን በትክክል ማስተካከል አፈፃፀማቸውን በእጅጉ ሊያሻሽል ይችላል።
ሲፒዩ ዝግጁ
ቪኤም ኮር (vCPU) በ Ready ሁኔታ ውስጥ ከሆነ ጠቃሚ ስራ አይሰራም። ይህ ሁኔታ የሚከሰተው ሃይፐርቫይዘሩ የቨርቹዋል ማሽኑ የvCPU ሂደት የሚመደብበት ነጻ ፊዚካል ኮር ሲያገኝ ነው።
እንዴት መተንተን ይቻላል? በተለምዶ፣ የቨርቹዋል ማሽን ኮሮች ከ10% በላይ በዝግጁ ሁኔታ ውስጥ ከሆኑ የአፈጻጸም ችግሮችን ያስተውላሉ። በቀላል አነጋገር፣ ከ10% በላይ ቪኤም አካላዊ ሀብቶች እስኪገኙ ድረስ ይጠብቃል።
በ vCenter ውስጥ ከሲፒዩ ዝግጁ ጋር የሚዛመዱ 2 ቆጣሪዎችን ማየት ይችላሉ፡
- ዝግጁነት ፣
- ዝግጁ።
የሁለቱም ቆጣሪዎች ዋጋዎች ለጠቅላላው VM እና ለግለሰብ ኮሮች ሊታዩ ይችላሉ።
ዝግጁነት እሴቱን ወዲያውኑ እንደ መቶኛ ያሳያል ፣ ግን በእውነተኛ ጊዜ (የመጨረሻው ሰዓት መረጃ ፣ የመለኪያ ክፍተት 20 ሴኮንድ)። "በተረከዙ ላይ ትኩስ" ችግሮችን ለመፈለግ ይህንን ቆጣሪ ብቻ መጠቀም የተሻለ ነው.
ዝግጁ የሆኑ የቆጣሪ እሴቶችም ከታሪካዊ እይታ አንጻር ሊታዩ ይችላሉ። ይህ ዘይቤዎችን ለመመስረት እና ለችግሩ ጥልቅ ትንተና ጠቃሚ ነው. ለምሳሌ፣ ቨርቹዋል ማሽን በተወሰነ ጊዜ የአፈጻጸም ችግር ከጀመረ፣ የ CPU Ready እሴት ክፍተቶችን ይህ ቪኤም በሚሰራበት አገልጋይ ላይ ካለው አጠቃላይ ጭነት ጋር ማወዳደር እና ጭነቱን ለመቀነስ እርምጃዎችን መውሰድ ይችላሉ (DRS ከሆነ) አልተሳካም)።
ዝግጁ፣ ከዝግጁነት በተቃራኒ፣ በመቶኛ ሳይሆን በሚሊሰከንዶች ነው የሚታየው። ይህ የማጠቃለያ አይነት ቆጣሪ ነው፣ ማለትም፣ በመለኪያ ጊዜ ውስጥ VM ኮር በዝግጁ ሁኔታ ውስጥ ምን ያህል ጊዜ እንደነበረ ያሳያል። ቀላል ቀመር በመጠቀም ይህን እሴት ወደ መቶኛ መቀየር ይችላሉ፡-
(ሲፒዩ ዝግጁ ማጠቃለያ ዋጋ / (የገበታ ነባሪ የዝማኔ ክፍተት በሰከንዶች * 1000)) * 100 = ሲፒዩ ዝግጁ %
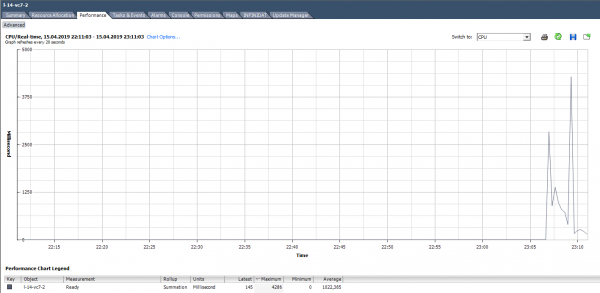
ለምሳሌ፣ ከታች ባለው ግራፍ ላይ ላለው VM፣ ለመላው ቨርቹዋል ማሽን ዝግጁ የሆነ ከፍተኛ ዋጋ እንደሚከተለው ይሆናል።

ዝግጁውን መቶኛ ሲያሰሉ ለሁለት ነጥቦች ትኩረት መስጠት አለብዎት-
- የሙሉ ቪኤም ዝግጁ እሴት በኮሮች ላይ ዝግጁ የሆነ ድምር ነው።
- የመለኪያ ክፍተት. ለእውነተኛ ጊዜ 20 ሰከንድ ነው, እና ለምሳሌ, በየቀኑ ገበታዎች ላይ 300 ሴኮንድ ነው.
በነቃ መላ ፍለጋ እነዚህ ቀላል ነጥቦች በቀላሉ ሊያመልጡ የሚችሉ እና ጠቃሚ ጊዜን ላልነበሩ ችግሮችን ለመፍታት ሊያባክኑ ይችላሉ።
ከታች ባለው ግራፍ ላይ ባለው መረጃ መሰረት ዝግጁ እናሰላ። (324474 / (20 * 1000)) * 100 = 1622% ለሙሉ ቪኤም. ኮርሶቹን ከተመለከቱ በጣም አስፈሪ አይደለም: 1622/64 = 25% በኮር. በዚህ ሁኔታ, መያዣው ለመለየት በጣም ቀላል ነው: የዝግጁ ዋጋ ከእውነታው የራቀ ነው. ነገር ግን ከ10-20% የሚሆነውን ለጠቅላላው ቪኤም ከበርካታ ኮርሞች ጋር እየተነጋገርን ከሆነ, ለእያንዳንዱ ኮር ዋጋው በተለመደው ክልል ውስጥ ሊሆን ይችላል.
ምን ማድረግ አለብኝ? ከፍተኛ ዝግጁነት ያለው እሴት የሚያመለክተው አገልጋዩ ለቨርቹዋል ማሽኖች መደበኛ ስራ በቂ ፕሮሰሰር ግብዓት እንደሌለው ነው። በእንደዚህ ዓይነት ሁኔታ ውስጥ፣ የሚቀረው በአቀነባባሪ (vCPU:pCPU) ከመጠን በላይ የደንበኝነት ምዝገባን መቀነስ ነው። በግልጽ ለማየት እንደሚቻለው፣ ይህ የነባር ቪኤምዎችን መለኪያዎች በመቀነስ ወይም የቪኤምዎቹን ክፍል ወደ ሌሎች አገልጋዮች በማዛወር ሊገኝ ይችላል።
አብሮ ማቆም
እንዴት መተንተን ይቻላል? ይህ ቆጣሪ እንዲሁ የማጠቃለያ ዓይነት ነው እና ወደ መቶኛ የሚቀየረው ልክ እንደ ዝግጁ ነው፡-
(የሲፒዩ የጋራ ማቆሚያ ማጠቃለያ እሴት / (የገበታ ነባሪ የዝማኔ ክፍተት በሰከንዶች * 1000)) * 100 = ሲፒዩ የጋራ ማቆሚያ %
እዚህ በተጨማሪ በ VM እና በመለኪያ ክፍተቱ ላይ ለቁሮች ብዛት ትኩረት መስጠት አለብዎት.
በኮስታፕ ግዛት ውስጥ ከርነል ጠቃሚ ስራ አይሰራም. በትክክለኛው የቪኤም መጠን ምርጫ እና በአገልጋዩ ላይ መደበኛ ጭነት ፣የጋራ ማቆሚያ ቆጣሪው ወደ ዜሮ ቅርብ መሆን አለበት።
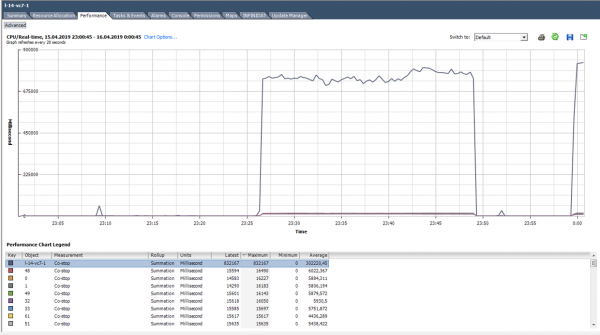
በዚህ ሁኔታ, ጭነቱ በግልጽ ያልተለመደ ነው :)
ምን ማድረግ አለብኝ? ብዙ ቁጥር ያላቸው ኮሮች ያላቸው ብዙ ቪኤምዎች በአንድ ሃይፐርቫይዘር ላይ እየሰሩ ከሆነ እና በሲፒዩ ላይ ከመጠን በላይ የደንበኝነት ምዝገባ ካለ ፣የጋራ ማቆሚያ ቆጣሪው ሊጨምር ይችላል ፣ይህም የእነዚህ ቪኤም ዎች አፈፃፀም ላይ ችግር ያስከትላል።
እንዲሁም የአንድ ቪኤም ገባሪ ኮሮች ሃይፐር-መርገጥ ከነቃ በአንድ አካላዊ አገልጋይ ኮር ላይ ክሮች ከተጠቀሙ የጋራ ማቆሚያ ይጨምራል። ይህ ሁኔታ ሊነሳ ይችላል, ለምሳሌ, ቪኤም በሚሰራበት አገልጋይ ላይ በአካል ከሚገኙት ይልቅ ብዙ ኮርሶች ካሉት ወይም "preferHT" ቅንብር ለ VM የነቃ ከሆነ. ስለዚህ ቅንብር ማንበብ ትችላለህ .
በከፍተኛ የትብብር ማቆሚያ ምክንያት ከቪኤም አፈጻጸም ጋር የተያያዙ ችግሮችን ለማስወገድ በዚህ ቪኤም ላይ የሚሰራውን የሶፍትዌር አምራቹ ባቀረቡት ምክሮች እና ቪኤም በሚሰራበት የአካላዊ አገልጋይ አቅም መሰረት የቪኤም መጠኑን ይምረጡ።
በመጠባበቂያ ውስጥ ኮሮችን አይጨምሩ ፣ ይህ ለቪኤም እራሱ ብቻ ሳይሆን በአገልጋዩ ላይ ላሉት ጎረቤቶችም የአፈፃፀም ችግርን ያስከትላል ።
ሌሎች ጠቃሚ የሲፒዩ መለኪያዎች
ሩጫ - በመለኪያ ጊዜ ውስጥ vCPU በ RUN ሁኔታ ውስጥ ምን ያህል ጊዜ (ሚሴ) ነበር ፣ ማለትም ፣ በእውነቱ ጠቃሚ ስራን እየሰራ ነበር።
ስራ ፈት - ምን ያህል ጊዜ (ሚሴ) በመለኪያ ጊዜ ውስጥ vCPU እንቅስቃሴ-አልባ በሆነ ሁኔታ ውስጥ ነበር። ከፍተኛ የስራ ፈት ዋጋዎች ችግር አይደሉም፣ vCPU ገና “ምንም የሚያደርገው” አልነበረም።
ጠብቅ - በመለኪያ ጊዜ ውስጥ vCPU ለምን ያህል ጊዜ (ሚሴ) በ Wait ሁኔታ ውስጥ እንደነበረ። IDLE በዚህ ቆጣሪ ውስጥ የተካተተ በመሆኑ ከፍተኛ የጥበቃ ዋጋዎች እንዲሁ ችግርን አያመለክቱም። ነገር ግን Wait IDLE ዝቅተኛ ከሆነ መጠበቅ ከፍተኛ ሲሆን ይህ ማለት ቪኤም የI/O ስራዎችን እስኪጠናቀቅ ድረስ እየጠበቀ ነበር ማለት ነው፣ እና ይሄ ደግሞ በሃርድ ድራይቭ ወይም በማናቸውም የVM ምናባዊ መሳሪያዎች አፈጻጸም ላይ ችግር እንዳለ ሊያመለክት ይችላል።
ከፍተኛው የተገደበ - ምን ያህል ጊዜ (ሚሴ) በመለኪያ ጊዜ ውስጥ vCPU በተቀመጠው የንብረት ገደብ ምክንያት ዝግጁ በሆነ ሁኔታ ውስጥ ነበር። አፈፃፀሙ በማይታወቅ ሁኔታ ዝቅተኛ ከሆነ ፣በቪኤም መቼቶች ውስጥ የዚህን ቆጣሪ ዋጋ እና የሲፒዩ ገደብ መፈተሽ ጠቃሚ ነው። ቪኤምዎች እርስዎ የማያውቁት ገደብ ሊኖራቸው ይችላል። ለምሳሌ፣ ይሄ የሚሆነው የሲፒዩ ገደብ ከተዘጋጀበት አብነት ቪኤም ሲቀዳ ነው።
መጠበቅን መለዋወጥ - በመለኪያ ጊዜ ውስጥ vCPU ከVMkernel Swap ጋር ለመስራት ምን ያህል ጊዜ እንደጠበቀ። የዚህ ቆጣሪ ዋጋዎች ከዜሮ በላይ ከሆኑ, VM በእርግጠኝነት የአፈጻጸም ችግሮች አሉት. ስለ RAM ቆጣሪዎች በጽሁፉ ውስጥ ስለ SWAP የበለጠ እንነጋገራለን ።
ESXTOP
በvCenter ውስጥ ያሉ የአፈጻጸም ቆጣሪዎች ታሪካዊ መረጃዎችን ለመተንተን ጥሩ ከሆኑ፣ የችግሩን የአሠራር ትንተና በESXTOP ውስጥ በተሻለ ሁኔታ ይከናወናል። እዚህ ሁሉም ዋጋዎች ዝግጁ በሆነ ቅጽ (ምንም መተርጎም አያስፈልግም) እና ዝቅተኛው የመለኪያ ጊዜ 2 ሴኮንድ ነው.
የ ESXTOP ስክሪን ለሲፒዩ የተጠራው በ"c" ቁልፍ ሲሆን ይህን ይመስላል።

ለመመቻቸት Shift-V ን በመጫን ምናባዊ ማሽን ሂደቶችን ብቻ መተው ይችላሉ።
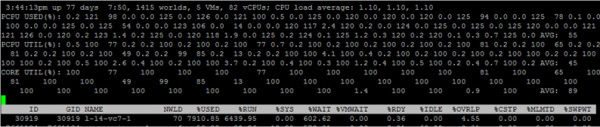
ለእያንዳንዱ የቪኤም ኮሮች መለኪያዎችን ለማየት “e”ን ተጭነው የፍላጎት ቪኤምኤው ጂአይዲ ያስገቡ (ከዚህ በታች ባለው ቅጽበታዊ ገጽ እይታ 30919)
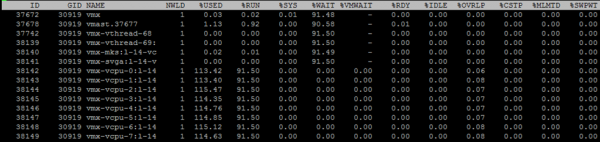
በነባሪ የቀረቡትን አምዶች ባጭሩ ላንሳ። "f" ን በመጫን ተጨማሪ ዓምዶች መጨመር ይቻላል.
NWLD (የዓለማት ብዛት) - በቡድኑ ውስጥ ያሉ ሂደቶች ብዛት. ቡድኑን ለማስፋት እና ለእያንዳንዱ ሂደት መለኪያዎችን ለማየት (ለምሳሌ፣ በባለብዙ ኮር ቪኤም ውስጥ ላለው እያንዳንዱ ኮር) “e” ን ይጫኑ። በቡድን ውስጥ ከአንድ በላይ ሂደቶች ካሉ ፣ የቡድኑ ሜትሪክ እሴቶች ለግለሰብ ሂደቶች የመለኪያ ድምር እኩል ናቸው።
% ጥቅም ላይ ውሏል - ስንት የአገልጋይ ሲፒዩ ዑደቶች በሂደት ወይም በቡድን ጥቅም ላይ ይውላሉ።
% አሂድ - በመለኪያ ጊዜ ውስጥ ሂደቱ በ RUN ሁኔታ ውስጥ ምን ያህል ጊዜ እንደነበረ, ማለትም. ጠቃሚ ሥራ ሠራ። ከ%USED የሚለየው ሃይፐር-ክር ማድረግን፣ የድግግሞሽ ልኬትን እና በስርዓት ተግባራት (% SYS) ላይ የሚጠፋውን ጊዜ ግምት ውስጥ ባለማስገባቱ ነው።
% SYS - በስርዓት ተግባራት ላይ የሚጠፋው ጊዜ ለምሳሌ: ሂደትን አቋርጥ, I / O, የኔትወርክ አሠራር, ወዘተ. ቪኤም ትልቅ I / O ካለው ዋጋው ከፍተኛ ሊሆን ይችላል.
% OVRLP - የቪኤም ሂደቱ የሚሠራበት አካላዊ ኮር በሌሎች ሂደቶች ተግባራት ላይ ምን ያህል ጊዜ ያሳልፋል።
እነዚህ መለኪያዎች እንደሚከተለው ይዛመዳሉ።
% ጥቅም ላይ የዋለው = % Run + %SYS - %OVRLP።
በተለምዶ የ%USED መለኪያ የበለጠ መረጃ ሰጭ ነው።
%ጠብቅ - በመለኪያ ጊዜ ውስጥ ሂደቱ በ Wait ሁኔታ ውስጥ ምን ያህል ጊዜ እንደነበረ። IDLEን ያነቃል።
%IDLE - በመለኪያ ጊዜ ውስጥ ሂደቱ በIDLE ሁኔታ ውስጥ ምን ያህል ጊዜ እንደነበረ።
%SWPWT - በመለኪያ ጊዜ ውስጥ vCPU ከVMkernel Swap ጋር ለመስራት ምን ያህል ጊዜ እንደጠበቀ።
%VMWAIT - በመለኪያ ጊዜ ውስጥ vCPU አንድን ክስተት በመጠባበቅ ሁኔታ ላይ ምን ያህል ጊዜ እንደነበረ (ብዙውን ጊዜ I/O)። በ vCenter ውስጥ ምንም ተመሳሳይ ቆጣሪ የለም። ከፍተኛ እሴቶች በቪኤም ላይ ከ I/O ጋር ችግሮችን ያመለክታሉ።
% መጠበቅ = %VMWAIT + %IDLE + %SWPWT።
VM VMkernel Swap የማይጠቀም ከሆነ፣ የአፈጻጸም ችግሮችን በሚተነተንበት ጊዜ %VMWAIT ን መመልከት ተገቢ ነው፣ ምክንያቱም ይህ ልኬት VM ምንም ሳያደርግ የነበረውን ጊዜ (%IDLE) ግምት ውስጥ አያስገባም።
% RDY - በመለኪያ ጊዜ ውስጥ ሂደቱ በዝግጁ ሁኔታ ውስጥ ምን ያህል ጊዜ ነበር.
%CSTP - በመለኪያ ጊዜ ውስጥ ሂደቱ በኮስታፕ ግዛት ውስጥ ምን ያህል ጊዜ ነበር.
%MLTD - በመለኪያ ጊዜ ውስጥ vCPU በተቀመጠው የንብረት ገደብ ምክንያት በዝግጁ ሁኔታ ውስጥ ምን ያህል ጊዜ እንደነበረ።
% ይጠብቁ + % RDY + % CSTP + % RUN = 100% - የቪኤም ኮር ሁል ጊዜ ከእነዚህ አራት ግዛቶች ውስጥ አንዱ ነው።
ሲፒዩ hypervisor ላይ
vCenter ለ hypervisor የሲፒዩ አፈፃፀም ቆጣሪዎች አሉት ፣ ግን ምንም አስደሳች አይደሉም - በቀላሉ በአገልጋዩ ላይ ላሉት ቪኤምኤዎች ሁሉ የቆጣሪዎች ድምር ናቸው።
በአገልጋዩ ላይ ያለውን የሲፒዩ ሁኔታ ለማየት በጣም ምቹው መንገድ በማጠቃለያ ትር ላይ ነው።

ለአገልጋዩ እና ለምናባዊው ማሽን መደበኛ ማንቂያ አለ፡-
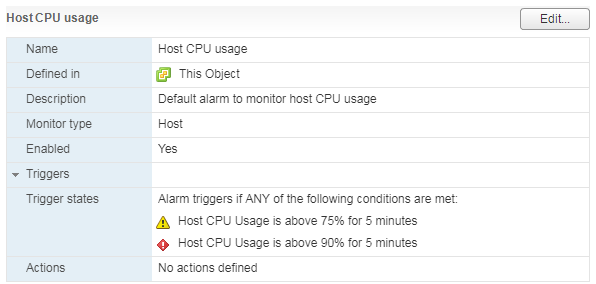
የአገልጋዩ ሲፒዩ ጭነት ከፍተኛ ሲሆን በላዩ ላይ የሚሰሩ ቪኤምዎች የአፈጻጸም ችግሮች ያጋጥሟቸዋል።
በ ESXTOP የአገልጋይ ሲፒዩ ጭነት መረጃ በማያ ገጹ ላይኛው ክፍል ላይ ቀርቧል። ለሃይፐርቫይዘሮች በጣም መረጃ ሰጭ ካልሆነው መደበኛ የሲፒዩ ጭነት በተጨማሪ ሶስት ተጨማሪ መለኪያዎች አሉ፡
CORE UTIL(%) - አካላዊ አገልጋይ ኮር በመጫን ላይ. ይህ ቆጣሪ በመለኪያ ጊዜ ውስጥ ዋናው ሥራ ምን ያህል ጊዜ እንዳከናወነ ያሳያል.
PCPU UTIL(%) - hyper-stringing ከነቃ በአንድ አካላዊ ኮር ሁለት ክሮች (PCPU) አሉ። ይህ ልኬት እያንዳንዱ ክር ሥራውን ለማጠናቀቅ ምን ያህል ጊዜ እንደወሰደ ያሳያል።
PCPU USED(%) - ከ PCPU UTIL(%) ጋር ተመሳሳይ ነው፣ ነገር ግን የድግግሞሽ ልኬትን ግምት ውስጥ ያስገባ (ወይ ለኃይል ቆጣቢ ዓላማዎች የዋና ድግግሞሽን በመቀነስ ወይም በ Turbo Boost ቴክኖሎጂ ምክንያት የኮር ድግግሞሽን ማሳደግ) እና hyper-stringing።
PCPU_USED% = PCPU_UTIL% * ውጤታማ ኮር ድግግሞሽ/ስመ ኮር ድግግሞሽ።
በዚህ ቅጽበታዊ ገጽ እይታ ላይ፣ ለአንዳንድ ኮሮች፣ በ Turbo Boost ምክንያት፣ የዋና ድግግሞሽ ከስም ከፍ ያለ ስለሆነ የUSED ዋጋ ከ100% በላይ ነው።
hyper-stringing እንዴት እንደሚወሰድ ጥቂት ቃላት። ሂደቶች በአገልጋዩ አካላዊ ኮር በሁለቱም ክሮች ላይ 100% ጊዜ የሚፈጸሙ ከሆነ፣ ዋናው ደግሞ በስመ ድግግሞሽ የሚሰራ ከሆነ፣
- CORE UTIL ለዋናው 100% ይሆናል፣
- PCPU UTIL ለሁለቱም ክሮች 100% ይሆናል፣
- PCPU ጥቅም ላይ የዋለው ለሁለቱም ክሮች 50% ይሆናል.
ሁለቱም ክሮች በመለኪያ ጊዜ ውስጥ 100% ካልሰሩ ፣ ከዚያ ክሮቹ በትይዩ በሚሠሩባቸው ጊዜያት ፣ PCPU USED ለኮርሶቹ በግማሽ ይከፈላል ።
ESXTOP የአገልጋይ ሲፒዩ የኃይል ፍጆታ መለኪያዎች ያለው ስክሪንም አለው። እዚህ አገልጋዩ ኃይል ቆጣቢ ቴክኖሎጂዎችን ይጠቀም እንደሆነ ማየት ይችላሉ-C-states እና P-states. በ"p" ቁልፍ ተጠርቷል፡-

የተለመዱ የሲፒዩ አፈጻጸም ጉዳዮች
በመጨረሻ፣ በቪኤም ሲፒዩ አፈጻጸም ላይ የችግሮች የተለመዱ መንስኤዎችን ፈትሻለሁ እና እነሱን ለመፍታት አጭር ምክሮችን እሰጣለሁ።
የኮር ሰዓት ፍጥነት በቂ አይደለም. የእርስዎን ቪኤም ወደ ኃይለኛ ኮሮች ማሻሻል የማይቻል ከሆነ ቱርቦ ቦስት በተቀላጠፈ ሁኔታ እንዲሠራ የኃይል ቅንብሮችን ለመቀየር መሞከር ይችላሉ።
ትክክል ያልሆነ የቪኤም መጠን (በጣም ብዙ/ጥቂት ኮር)። ጥቂት ኮርሞችን ከጫኑ በቪኤም ላይ ከፍተኛ የሲፒዩ ጭነት ይኖራል። ብዙ ካለ, ከፍተኛ የጋራ ማቆሚያ ይያዙ.
በአገልጋዩ ላይ ትልቅ የሲፒዩ ምዝገባ። ቪኤም ከፍተኛ ዝግጁ ከሆነ፣ የሲፒዩ ከመጠን በላይ የደንበኝነት ምዝገባን ይቀንሱ።
በትላልቅ ቪኤምዎች ላይ ትክክል ያልሆነ NUMA ቶፖሎጂ። በVM (vNUMA) የሚታየው የNUMA ቶፖሎጂ ከአገልጋዩ NUMA ቶፖሎጂ (pNUMA) ጋር መዛመድ አለበት። ለዚህ ችግር ምርመራዎች እና መፍትሄዎች ለምሳሌ በመጽሐፉ ውስጥ ተጽፈዋል . ወደ ጥልቀት መሄድ ካልፈለጉ እና በ VM ላይ በተጫነው ስርዓተ ክወና ላይ የፍቃድ ገደቦች ከሌልዎት በቪኤም ላይ ብዙ ምናባዊ ሶኬቶችን በአንድ ጊዜ አንድ ኮር ያድርጉ። ብዙ አያጡም :)
ስለ ሲፒዩ ያ ለእኔ ብቻ ነው። ጥያቄዎችን ይጠይቁ. በሚቀጥለው ክፍል ስለ RAM እናገራለሁ.
ጠቃሚ አገናኞች
ምንጭ: hab.com
