

ይህ ቀልድ እንኳን አይደለም፤ ይህ ምስል የእነዚህን የውሂብ ጎታዎች ይዘት በትክክል የሚያንፀባርቅ ይመስላል፣ እና በመጨረሻም ምክንያቱ ግልፅ ይሆናል፡

በDB-Engines Ranking መሠረት፣ ሁለቱ በጣም ተወዳጅ የሆኑት የNoSQL አምድ የውሂብ ጎታዎች ካሳንድራ (ከዚህ በኋላ CS ይባላል) እና HBase (HB) ናቸው።
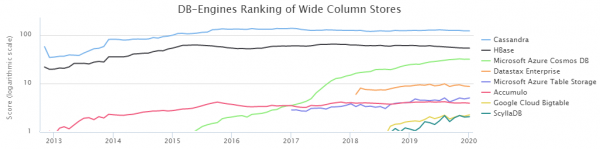
እንደ እድል ሆኖ፣ በSberbank የሚገኘው የውሂብ ጭነት አስተዳደር ቡድናችን አስቀድሞ አድርጓል እና ከኤችቢ ጋር በቅርበት ይሰራል። በዚህ ጊዜ፣ ስለ ጥንካሬዎቹና ድክመቶቹ በሚገባ ተረድተናል እንዲሁም እንዴት እንደምንጠቀምበት ተምረናል። ሆኖም፣ በሲኤስ መልክ አማራጭ መኖሩ ራሳችንን በጥርጣሬ እንድናሰቃይ ያደርገናል፡ ትክክለኛውን ምርጫ አድርገናል? በተለይም ከውጤቱ ወዲህ። የDataStax ሙከራዎች ሲኤስ በቀላሉ HBን በዝቅጠት እንደሚያሸንፍ ተናግረዋል። ሆኖም ግን፣ DataStax የራሱ የሆነ ጥቅም አለው፣ ስለዚህ ቃላቸውን መቀበል የለብዎትም። ስለ ምርመራ ሁኔታዎች ያለው በአንጻራዊ ሁኔታ ውስን መረጃም አሳሳቢ ነበር፣ ስለዚህ የBigData NoSql ንጉሥ ማን እንደሆነ በራሳችን ለማወቅ ወሰንን፣ ውጤቶቹም በጣም አስደሳች ነበሩ።
ሆኖም ግን፣ የፈተና ውጤቶቹን ከመወያየታችን በፊት፣ የአካባቢ ውቅር ቁልፍ ገጽታዎችን መግለጽ አስፈላጊ ነው። CS በውሂብ መጥፋት-ተቋቋሚ ሁነታ ጥቅም ላይ ሊውል ይችላል። ይህ ማለት ለአንድ የተወሰነ ቁልፍ መረጃ አንድ አገልጋይ (ኖድ) ብቻ ነው ተጠያቂ የሚሆነው፣ እና በማንኛውም ምክንያት ካልተሳካ፣ የዚያ ቁልፍ ዋጋ ይጠፋል። ለብዙ አፕሊኬሽኖች፣ ይህ ወሳኝ አይደለም፣ ነገር ግን ለባንክ፣ ከህጉ ይልቅ ልዩ ነው። በእኛ ሁኔታ፣ ደህንነቱ የተጠበቀ ማከማቻ ለማግኘት ብዙ የውሂብ ቅጂዎች መኖራቸው ወሳኝ ነው።
ስለዚህ፣ የሲኤስ የሶስትዮሽ ማባዛት ሁነታ ብቻ ተወስኗል፣ ማለትም የቁልፍ ቦታ መፍጠር የተከናወነው በሚከተሉት መለኪያዎች ነው፡
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; የሚፈለገውን ወጥነት ደረጃ ለማረጋገጥ ሁለት መንገዶች አሉ። አጠቃላይ ደንቡ፡
NW + NR > አርኤፍ
ይህ ማለት የኖድ የጽሑፍ ማረጋገጫዎች (NW) እና የኖድ ንባብ ማረጋገጫዎች ብዛት (NR) ከማባዛት ሁኔታ የበለጠ መሆን አለባቸው ማለት ነው። በእኛ ሁኔታ፣ RF = 3፣ ይህም ማለት የሚከተሉት አማራጮች ተስማሚ ናቸው ማለት ነው፡
2 + 2 > 3
3 + 1 > 3
መረጃን በተቻለ መጠን ደህንነቱ በተጠበቀ ሁኔታ ማከማቸት ለእኛ ወሳኝ ስለሆነ፣ የ3+1 እቅድን መርጠናል። በተጨማሪም፣ HB በተመሳሳይ መርህ ላይ ይሰራል፣ ይህ ማለት ይህ ንጽጽር የበለጠ ፍትሃዊ ይሆናል ማለት ነው።
ዳታስታክስ በጥናታቸው ተቃራኒውን እንዳደረጉ ልብ ሊባል የሚገባው ነው፡ ለሁለቱም CS እና HB RF = 1 አስቀምጠዋል (የኋለኛውን HDFS ቅንብሮችን በመቀየር)። ይህ በጣም አስፈላጊ ገጽታ ነው፣ ምክንያቱም በዚህ ጉዳይ ላይ በCS አፈጻጸም ላይ ያለው ተጽእኖ ጉልህ ነው። ለምሳሌ፣ ከታች ያለው ምስል ውሂብ ወደ CS ለመጫን የሚያስፈልገውን ጊዜ መጨመር ያሳያል፡
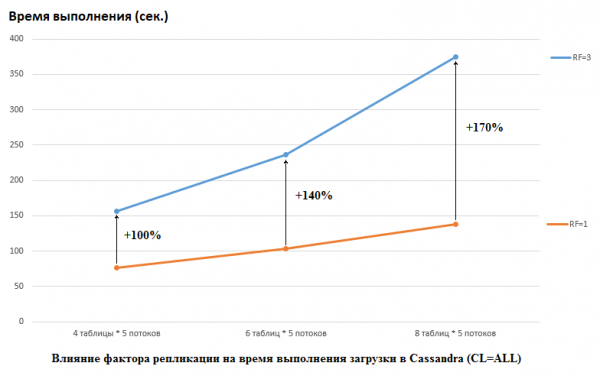
እዚህ ላይ የሚከተለውን እናያለን፡- ብዙ ተፎካካሪ ክሮች ውሂብ ሲጽፉ፣ ረዘም ያለ ጊዜ ይወስዳል። ይህ ተፈጥሯዊ ነው፣ ነገር ግን የRF=3 የአፈጻጸም መበላሸት በከፍተኛ ሁኔታ ከፍ ያለ መሆኑን ልብ ማለት አስፈላጊ ነው። በሌላ አነጋገር፣ እያንዳንዳቸው 5 ክሮች ያሏቸው 4 ሰንጠረዦች (በአጠቃላይ 20) ብንጽፍ፣ RF=3 በግምት 2 ጊዜ ይጠፋል (ለRF=3 150 ሰከንዶች ከRF=1 ጋር ሲነጻጸር 75)። ነገር ግን እያንዳንዳቸው 5 ክሮች ያሏቸው 8 ሰንጠረዦች ዳታ በመጫን ጭነቱን ከጨመርን (በአጠቃላይ 40)፣ RF=3 በ2,7 እጥፍ (በአጠቃላይ 375 ሰከንዶች ከ138 ጋር ሲነጻጸር) ያጣል።
ምናልባት ይህ በከፊል የDataStax የሲኤስን የተሳካ የጭነት ሙከራ ሚስጥር ሊሆን ይችላል፣ ምክንያቱም የማባዛት ፋክተርን ከ2 ወደ 3 መቀየር በኛ ቅንብር ውስጥ በኤችቢ ላይ ምንም ተጽእኖ ስላላሳደረ። ይህ ማለት ዲስኮች በእኛ ውቅር ውስጥ ለኤችቢ ችግር አይደሉም ማለት ነው። ሆኖም ግን፣ እዚህ ብዙ ሌሎች ወጥመዶች አሉ፣ ምክንያቱም የኤችቢ ስሪታችን በትንሹ የተስተካከለ እና የተስተካከለ መሆኑ፣ አካባቢዎቹ ሙሉ በሙሉ የተለያዩ መሆናቸው፣ ወዘተ ልብ ሊባል የሚገባው ነው። እንዲሁም CSን እንዴት በትክክል ማዘጋጀት እንዳለብኝ እርግጠኛ ባልሆንም እና ከእሱ ጋር ለመስራት የበለጠ ውጤታማ መንገዶች ሊኖሩ እንደሚችሉ ልብ ሊባል ይገባል። ይህንን በአስተያየቶቹ ውስጥ እንደምንረዳ ተስፋ አደርጋለሁ። ግን በመጀመሪያ ነገሮች።
ሁሉም ሙከራዎች የተከናወኑት እያንዳንዳቸው የሚከተሉትን ውቅር ባላቸው 4 አገልጋዮች በተዋቀረ የሃርድዌር ክላስተር ላይ ነው፡
ሲፒዩ፡ Xeon E5-2680 v4 @ 2.40GHz 64 ክሮች።
ድራይቮች፡ 12 የSATA ኤችዲዲዎች
ጃቫ ስሪት: 1.8.0_111
የሲኤስ ስሪት፡ 3.11.5
cassandra.yml መለኪያዎችየnum_tokens: 256
hint_handoff_enabled: እውነት
hint_handoff_throttle_in_kb: 1024
ከፍተኛ_ፍንጮች_የማድረሻ_ክሮች፡ 2
የቲፕስ_ዳይሬክቶሪ: /data10/cassandra/hints
hints_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
አረጋጋጭ፡ AllowAllAuthenticator
ፈቃድ ሰጪ፡ AllowAllAuthorizer
ሚና_አስተዳዳሪ፡ ካሳንድራ ሚናማኔጀር
roles_validity_in_ms: 2000
የፈቃዶች_ውጤታማነት_በ_ሚስ_ውስጥ፡ 2000
credentials_validity_in_ms: 2000
ክፍልፋይ፡ org.apache.cassandra.dht.Murmur3ክፍልፋይ
የውሂብ_ፋይል_ማውጫዎች፡
— /data1/cassandra/data # እያንዳንዱ dataN ማውጫ የተለየ ዲስክ ነው
— /data2/cassandra/data
— /data3/cassandra/data
— /data4/cassandra/data
— /data5/cassandra/data
— /data6/cassandra/data
— /data7/cassandra/data
— /data8/cassandra/data
commitlog_directory: /data9/cassandra/commitlog
cdc_enabled: ሐሰት
የዲስክ_ውድቀት_ፖሊሲ፡ አቁም
የውድቀት_መሪ_ፖሊሲ፡ አቁም
የተዘጋጁ_መግለጫዎች_መሸጎጫ_መጠን_mb፡
thrift_prepared_statements_cache_size_mb:
ቁልፍ_መሸጎጫ_መጠን_በ_mb፡
የቁልፍ_መሸጎጫ_ማስቀመጫ_ጊዜ: 14400
የrow_cache_size_in_mb: 0
የrow_cache_save_period: 0
ተቃራኒ_መሸጎጫ_መጠን_በ_mb፡
የተቃራኒ_መሸጎጫ_ማስቀመጥ_ጊዜ: 7200
የተቀመጠ_ካሼ_ማውጫ፦ /data10/cassandra/saved_caches
commitlog_Sync: ወቅታዊ
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
የዘር_አቅራቢ፡
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
መለኪያዎች
— ዘሮች፡ "*፣*"
concurrent_reads: 256 # ሞክሯል 64 - ምንም ልዩነት አልታየም
concurrent_writes: 256 # ሞክሯል 64 - ምንም ልዩነት አልታየም
concurrent_counter_writes: 256 # ሞክሯል 64 - ምንም ልዩነት አልታየም
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # 16 ጊባ ሞክሯል - ቀርፋፋ ነበር
የሜምብሌ_አሎክሽን_አይነት፡ የሂፕ_ማፍረሮች
index_summary_capacity_in_mb:
index_summary_resize_interval_in_ደቂቃዎች: 60
trickle_fsync: ሐሰት
trickle_fsync_interval_in_kb: 10240
ማከማቻ_ወደብ፡ 7000
ssl_storage_port: 7001
የማዳመጥ_አድራሻ፡ *
የስርጭት_አድራሻ፡ *
የስርጭት_አድራሻ_ላይ_ማዳመጥ፡ እውነት
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: እውነት
ተወላጅ_ትራንስፖርት_ፖርት፡ 9042
start_rpc: እውነት
የrpc_አድራሻ፡ *
rpc_port: 9160
rpc_keepalive: እውነት
rpc_server_type: ማመሳሰል
thrift_framed_transport_size_in_mb: 15
incremental_backups: ሐሰት
ከ_ኮምፓክት_በፊት_ፎቶግራፍ፡ ሐሰት
ራስ-ሰር_ቅጽበታዊ ገጽ እይታ፡ እውነት
column_index_size_in_kb: 64
column_index_cache_size_in_kb: 2
ኮንኮንትራት_ኮምፓክተሮች፡ 4
የ compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
የread_request_timeout_in_ms: 100000
የ_ሬንጅ_ጥያቄ_ጊዜ_ማውጣት_በ_ኤምኤስ: 200000
የጻፍ_ጥያቄ_ጊዜ_አውት_በ_ኤምኤስ: 40000
የመልስ_መጻፍ_ጥያቄ_ጊዜ_አውት_በ_ኤምኤስ: 100000
cas_contingion_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
የጥያቄ_ጊዜ_አውት_በ_ኤምኤስ: 200000
slow_query_log_timeout_in_ms: 500
የመስቀል_ኖድ_ጊዜ_አቁም: ሐሰት
የመጨረሻ_ነጥብ_ስኒች፡ ጎሲፒንግPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000
የdynamic_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
የአገልጋይ_ምስጠራ_አማራጮች፡
የኢንተርኖድ_ኢንክሪፕሽን፡ የለም
የደንበኛ_ምስጠራ_አማራጮች፡
ነቅቷል: ሐሰት
የውስጥ_መጭመቂያ፡ dc
inter_dc_tcp_nodelay: ሐሰት
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
የተጠቃሚ_የተገለጸ_ተግባራትን አንቃ፡ ሐሰት
enable_scripted_user_defined_functions: ሐሰት
የዊንዶውስ_ጊዜ_ጊዜ_ጊዜ_ጊዜ_ጊዜ: 1
ግልጽ_ውሂብ_ምስጠራ_አማራጮች፡
ነቅቷል: ሐሰት
የመቃብር_ድንጋይ_ማስጠንቀቂያ_መዳረሻ፡ 1000
የመቃብር_ድንጋይ_ውድቀት_መዳፍ፡ 100000
ባች_መጠን_ማስጠንቀቂያ_በ_ኪባ: 200
ባች_መጠን_ውድቅ_የመሃል_ደረጃ_በ_ኪባ: 250
ያልተቆለፈ_ባች_በአቋራጭ_ክፍፍሎች_ማስጠንቀቂያ_መዳረሻ፡ 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
የኋላ_ግፊት_ነቅቷል: ሐሰት
enable_materialized_views: true
enable_sasi_indexes: እውነት
የጂሲ ቅንብሮች፡
### የሲኤምኤስ ቅንብሮች-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:የተረጂነት መጠን=8
-XX:ከፍተኛውየመቆሚያውThreshold=1
-XX:CMSየመጀመርያየቦታ ክፍልፋይ=75
-XX:+ሲኤምኤስ ይጠቀሙየመጀመርያ ቦታ ብቻ
-XX:CMSየቆይታ ጊዜ=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
የjvm.options ማህደረ ትውስታ 16 Gb ተመድቧል (እኛም 32 Gb ሞክረናል፣ ምንም ልዩነት አልታየም)።
ሰንጠረዦቹ የተፈጠሩት በሚከተለው ትዕዛዝ ነው፡
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};የኤችቢ ስሪት፡ 1.2.0-cdh5.14.2 (በ org.apache.hadoop.hbase.regionserver.HRegion ክፍል ውስጥ፣ MetricsRegionን አስወግደናል፣ ይህም በ RegionServer ላይ ያሉት ክልሎች ብዛት ከ1000 በላይ ሲሆን ወደ GC አመራ)
ነባሪ ያልሆኑ የHBase መለኪያዎችየዞይፐር.session.timeout: 120000
hbase.rpc.timeout: 2 ደቂቃ(ዎች)
hbase.client.scanner.timeout.period: 2 ደቂቃ(ዎች)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 ደቂቃ(ዎች)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 ሰዓት(ዎች)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreፋይሎች፡ 200
hbase.hregion.majorcompaction: 1 ቀን(ዎች)
ለ hbase-site.xml የHBase አገልግሎት የላቀ የውቅር ቅንጣቢ (የደህንነት ቫልቭ)፡
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
የጃቫ ውቅር አማራጮች ለ HBase RegionServer፡
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 ደቂቃ(ዎች)
hbase.snapshot.region.timeout: 2 ደቂቃ(ዎች)
hbase.snapshot.master.timeout.millis: 2 ደቂቃ(ዎች)
HBase REST የአገልጋይ ከፍተኛ የሎግ መጠን፡ 100 MiB
የHBase REST አገልጋይ ከፍተኛው የሎግ ፋይል ምትኬዎች፡ 5
የHBase Thrift አገልጋይ ከፍተኛ የሎግ መጠን፡ 100 MiB
የHBase Thrift አገልጋይ ከፍተኛው የሎግ ፋይል ምትኬዎች፡ 5
የማስተር ማክስ ሎግ መጠን፡ 100 ሜባ
ማስተር ማክስሚክ ሎግ ፋይል ምትኬዎች፡ 5
የRegionServer ከፍተኛ የሎግ መጠን፡ 100 MiB
የ RegionServer ከፍተኛው የሎግ ፋይል ምትኬዎች፡ 5
የHBase አክቲቭ ማስተር ዲቴክሽን መስኮት፡ 4 ደቂቃ(ዎች)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 ሚሊሰከንድ(ዎች)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
ከፍተኛው የሂደት ፋይል ገላጮች፡ 180000
hbase.thrift.minWorkerክሮች፡ 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
የክልል አንቀሳቃሽ ክሮች፡ 6
የደንበኛ ጃቫ ክምር መጠን በባይትስ፡ 1 ጊቢ
የHBase REST አገልጋይ ነባሪ ቡድን፡ 3 ጊቢ
የHBase Thrift አገልጋይ ነባሪ ቡድን፡ 3 GiB
የ HBase ማስተር በባይትስ የጃቫ ክምር መጠን፡ 16 ጊቢ
የ HBase ክልል አገልጋይ በባይትስ የጃቫ ክምር መጠን፡ 32 ጊቢ
+የእንስሳት ጠባቂ
maxClientCnxns: 601
ከፍተኛ የክፍለ ጊዜ ማብቂያ፡ 120000
ሰንጠረዦችን መፍጠር፡
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
እዚህ ላይ አንድ አስፈላጊ ነጥብ አለ፡ የDataStax መግለጫው የHB ሰንጠረዦችን ለመፍጠር ምን ያህል ክልሎች ጥቅም ላይ እንደዋሉ አይገልጽም፣ ምንም እንኳን ይህ ለትላልቅ መጠኖች ወሳኝ ቢሆንም። ስለዚህ፣ እስከ 640 ጊባ የሚደርስ ማከማቻ እንዲኖር 64 ክልሎች ተመርጠዋል፣ ማለትም መካከለኛ መጠን ያለው ሰንጠረዥ።
በሙከራው ጊዜ፣ HBase 22 ጠረጴዛዎች እና 67 ክልሎች ነበሩት (ይህ ከላይ ለተጠቀሰው ፓች ባይሆን ኖሮ ለስሪት 1.2.0 አስከፊ ይሆን ነበር)።
አሁን፣ ስለ ኮዱ። ለእያንዳንዱ የውሂብ ጎታ የትኞቹ ውቅሮች የበለጠ ጠቃሚ እንደሆኑ ግልጽ ስላልነበር፣ ሙከራዎች በተለያዩ ጥምረቶች ተካሂደዋል። ያም ማለት፣ በአንዳንድ ሙከራዎች፣ ጭነት በአንድ ጊዜ በአራት ሰንጠረዦች ውስጥ ተከናውኗል (ሁሉም አራቱ ኖዶች ለግንኙነቱ ጥቅም ላይ ውለዋል)። በሌሎች ሙከራዎች፣ ስምንት የተለያዩ ሰንጠረዦች ጥቅም ላይ ውለዋል። በአንዳንድ ሁኔታዎች፣ የባች መጠኑ 100 ነበር፣ በሌሎች ደግሞ 200 ነበር (የባች መለኪያ - ከታች ያለውን ኮድ ይመልከቱ)። ለእሴት የውሂብ መጠን 10 ባይት ወይም 100 ባይት (የዳታSize) ነበር። በእያንዳንዱ ጊዜ 5 ሚሊዮን መዝገቦች ተጽፈው በእያንዳንዱ ሠንጠረዥ ውስጥ ተነበቡ። አምስት ክሮች (thNum የክር ቁጥር) በእያንዳንዱ ሠንጠረዥ ውስጥ ጽፈዋል/ተነበዋል፣ እያንዳንዳቸው የራሳቸውን የቁልፍ ክልል ይጠቀማሉ (ቁጥር = 1 ሚሊዮን)፡
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
በዚህ መሠረት ለኤችቢ ተመሳሳይ ተግባር ተሰጥቷል፡
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
በኤችቢ ውስጥ ደንበኛው ለመረጃ ወጥ የሆነ ስርጭት ኃላፊነት ስለሚወስድ፣ የቁልፍ ጨው ተግባር እንደዚህ ይመስላል፡
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
አሁን በጣም አስደሳችው ክፍል - ውጤቶቹ
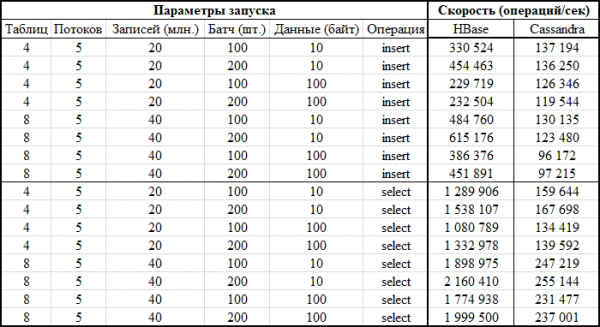
በግራፍ መልክም ተመሳሳይ ነው፡
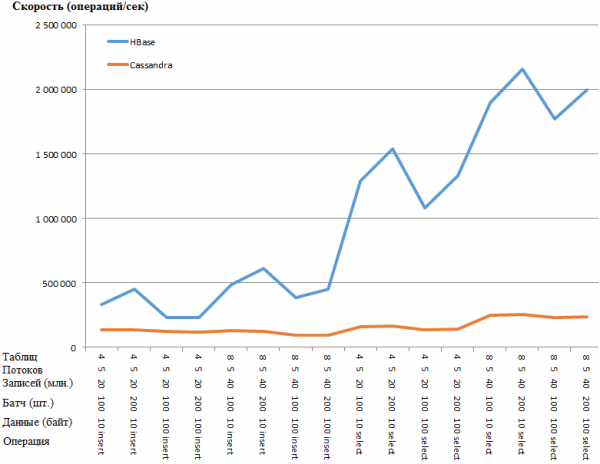
የኤችቢ (HB) ጥቅሙ በጣም አስገራሚ ስለሆነ በሲኤስ ቅንብሮች ውስጥ አንዳንድ ክፍተቶች እንዳሉ እገምታለሁ። ሆኖም ግን፣ በጣም ግልጽ የሆኑትን መለኪያዎች (እንደ concurrent_writes ወይም memtable_heap_space_in_mb ያሉ) በጉግል ላይ ማስተካከል እና ማስተካከል ምንም ፍጥነት አላመጣም። ይህ በእንዲህ እንዳለ፣ ምዝግቦቹ ንጹህ ናቸው፣ ምንም ችግር የለባቸውም።
መረጃው በኖዶቹ ላይ በእኩል መጠን ይሰራጫል፣ እና ከሁሉም ኖዶች የተገኘው ስታቲስቲክስ በግምት ተመሳሳይ ነው።
ከኖዶች አንዱ ያለው ሠንጠረዥ ስታቲስቲክስ የሚመስለው ይህ ነው።የቁልፍ ክፍተት፡ ks
የተነበበ ብዛት: 9383707
የንባብ መዘግየት፡ 0.04287025042448576 ሚሴ
የጽሑፍ ብዛት፡ 15462012
የፅሁፍ መዘግየት፡ 0.1350068438699957 ms
በመጠባበቅ ላይ ያሉ ፍሉሽዎች፡ 0
ሰንጠረዥ፡ t1
የኤስኤስቲቤል ብዛት፡ 16
ጥቅም ላይ የዋለ ቦታ (በቀጥታ): 148.59 ሚቢ
ጥቅም ላይ የዋለ ቦታ (ጠቅላላ): 148.59 ሚቢ
በቅጽበተ-ፎቶዎች የተጠቀመበት ቦታ (ጠቅላላ): 0 ባይት
ጥቅም ላይ የዋለው ከክምር ውጪ የሆነ ማህደረ ትውስታ (ጠቅላላ): 5.17 ሚቢ
የኤስኤስቲብል ኮምፕሬሽን ሬሾ፡ 0.5720989576459437
የክፍፍሎች ብዛት (ግምት): 3970323
የሜምብሌድ ሴል ብዛት፡ 0
የሜምብሌድ የውሂብ መጠን፡ 0 ባይት
ጥቅም ላይ የዋለው የሜምቴብል ከክምር ማህደረ ትውስታ ውጪ፡ 0 ባይትስ
የሜምብሌድ ማብሪያ/ማጥፊያ ብዛት፡ 5
የአካባቢው የተነበበ ብዛት፡ 2346045
የአካባቢ ንባብ መዘግየት፡ NaN ms
የአካባቢው የጽሑፍ ብዛት፡ 3865503
የአካባቢ የጽሑፍ መዘግየት፡ NaN ms
በመጠባበቅ ላይ ያሉ ብልሽቶች፡ 0
የተጠገነ መቶኛ፦ 0.0
የብሉም ማጣሪያ የውሸት ፖዘቲቭስ፡ 25
የብሉም ማጣሪያ የተሳሳተ ጥምርታ፡ 0.00000
ጥቅም ላይ የዋለው የብሉም ማጣሪያ ቦታ፡ 4.57 ሚቢ
ጥቅም ላይ የዋለው የብሉም ማጣሪያ ከክምር ማህደረ ትውስታ፦ 4.57 ሚቢ
ጥቅም ላይ የዋለው የክምር ማህደረ ትውስታ ማውጫ ማጠቃለያ፡ 590.02 ኪባ
ጥቅም ላይ የዋለው የክምር ሜታዳታ ከክምር ማህደረ ትውስታ ውጪ፦ 19.45 ኪባ
የተጨመቀ የክፍልፋይ ዝቅተኛ ባይት፡ 36
የተጨመቀ ክፍልፍል ከፍተኛው ባይት፡ 42
የተጨመቀ ክፍልፍል አማካይ ባይትስ፡ 42
በአንድ ቁራጭ አማካይ ሕያው ሴሎች (በመጨረሻው አምስት ደቂቃ): NaN
በአንድ ቁራጭ ከፍተኛው የቀጥታ ሴሎች (በመጨረሻው አምስት ደቂቃ)፡ 0
በአንድ ቁራጭ አማካይ የመቃብር ድንጋዮች (በመጨረሻው አምስት ደቂቃ): NaN
በአንድ ቁራጭ የሚፈቀደው ከፍተኛ የመቃብር ድንጋይ (በመጨረሻው አምስት ደቂቃ)፡ 0
የተጣሉ ሚውቴሽኖች፡ 0 ባይት
የባች መጠኑን ለመቀነስ መሞከር (የግለሰብ ባችዎችን መላክ እንኳን) ምንም ውጤት አላስገኘም፤ የባሰ ነገር ሆነ። ለCS የተገኙት ውጤቶች ከDataStax ጋር ተመሳሳይ ስለሆኑ ይህ ለCS ከፍተኛው አፈጻጸም ሊሆን ይችላል - በሰከንድ ወደ መቶ ሺህ የሚጠጉ ስራዎች። በተጨማሪም፣ የሀብት አጠቃቀምን ከተመለከትን፣ CS በከፍተኛ ሁኔታ የበለጠ ሲፒዩ እና የዲስክ ቦታ እንደሚጠቀም እናያለን፡
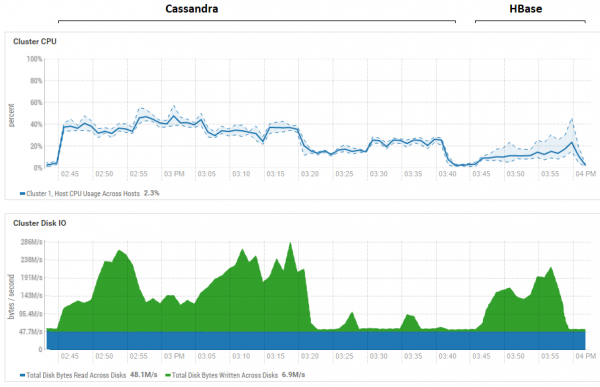
ይህ ምስል ለሁለቱም የውሂብ ጎታዎች በተከታታይ የተደረጉ የሁሉም ሙከራዎች አጠቃቀምን ያሳያል።
HB በንባብ አፈጻጸም ላይ ስላለው ጉልህ ጥቅም፣ ለሁለቱም የውሂብ ጎታዎች፣ በንባብ ወቅት የዲስክ አጠቃቀም እጅግ በጣም ዝቅተኛ መሆኑ ግልፅ ነው (የንባብ ሙከራዎች የእያንዳንዱ የውሂብ ጎታ የሙከራ ዑደት የመጨረሻ ክፍል ናቸው፤ ለምሳሌ ለCS፣ ይህ ከቀኑ 15፡20 እስከ ከሰዓት በኋላ 15፡40 ነው።) በHB ጉዳይ፣ ምክንያቱ ግልጽ ነው - አብዛኛው መረጃ በማህደረ ትውስታ ውስጥ፣ በሜምስቶር ውስጥ ነው፣ እና አንዳንዶቹ በብሎክካሽ ውስጥ ተከማችተዋል። ስለ CS፣ እንዴት እንደሚሰራ ሙሉ በሙሉ ግልጽ አይደለም፣ ነገር ግን የዲስክ አጠቃቀምም አይታይም። ምናልባት፣ መሸጎጫውን ለማንቃት ሞክሬ ነበር (row_cache_size_in_mb = 2048) እና ማዋቀር cache = {'keys': 'ALL', 'rows_per_partition': '2000000'}፣ ነገር ግን ይህ በእውነቱ ነገሮችን በትንሹ አባብሶታል።
በኤችቢ ውስጥ ስላለው የክልል ብዛት አንድ አስፈላጊ ነጥብ መድገም ተገቢ ነው። በእኛ ሁኔታ 64 ተገልጾ ነበር። ወደ 4 ዝቅ ካደረግነው፣ ለምሳሌ፣ የንባብ ፍጥነት በ2 እጥፍ ይቀንሳል። ይህ የሆነበት ምክንያት ሜምስቶር በፍጥነት ስለሚሞላ፣ ፋይሎች በተደጋጋሚ ስለሚበሩ እና ንባብ ተጨማሪ ፋይሎችን ማቀናበር ስለሚያስፈልግ ነው፣ ይህም ለኤችቢ በጣም ውስብስብ የሆነ አሠራር ነው። በእውነተኛ ዓለም ሁኔታዎች፣ ይህ ቅድመ-መሰንጠቅ እና የመጨመቅ ስትራቴጂ በማዘጋጀት ሊፈታ ይችላል። በተለይም፣ የቆሻሻ መሰብሰብን እና የኤችፋይልስ መጭመቂያን ከበስተጀርባ ያለማቋረጥ የሚያከናውን ብጁ መገልገያ እንጠቀማለን። የDataStax ሙከራዎች በአንድ ሠንጠረዥ አንድ ክልል ብቻ የተነደፉ ሊሆኑ ይችላሉ (ይህም የተሳሳተ ነው)፣ እና ይህ HB በንባብ ሙከራዎቻቸው ውስጥ ለምን ደካማ እንዳደረገ በተወሰነ ደረጃ ያብራራል።
ከዚህ የሚከተሉት የመጀመሪያ መደምደሚያዎች ሊገኙ ይችላሉ። በሙከራ ጊዜ ምንም አይነት ከባድ ስህተቶች እንዳልተደረጉ ከግምት ውስጥ በማስገባት ካሳንድራ እንደ ሸክላ እግሮች ያሉት ኮሎሰስ ነው። ይበልጥ በትክክል፣ በአንድ እግር ላይ ሚዛን ሲጠብቅ፣ በጽሑፉ መጀመሪያ ላይ ባለው ምስል ላይ እንደሚታየው፣ በአንጻራዊ ሁኔታ ጥሩ ውጤቶችን ያሳያል፣ ነገር ግን በተመሳሳይ ሁኔታዎች ሲሞከር ሙሉ በሙሉ ይጠፋል። ከዚህም በላይ፣ በሃርድዌርችን ላይ ያለው ዝቅተኛ የሲፒዩ አጠቃቀም ከግምት ውስጥ በማስገባት፣ በአንድ አስተናጋጅ ሁለት የክልል ሰርቨር HBs ማሰማራትን ተምረናል፣ በዚህም አፈፃፀሙን በእጥፍ ይጨምራል። ስለዚህ፣ የሀብት አጠቃቀምን ግምት ውስጥ በማስገባት፣ የሲኤስ ሁኔታ የበለጠ አስከፊ ይሆናል።
እርግጥ ነው፣ እነዚህ ሙከራዎች በጣም ሰው ሰራሽ ናቸው፣ እና እዚህ ጥቅም ላይ የዋለው የውሂብ መጠን በአንጻራዊነት መጠነኛ ነው። እስከ ቴራባይት ድረስ ብናሳድግ ኖሮ ሁኔታው የተለየ ይሆን ነበር፣ ነገር ግን ለ HB ቴራባይት የውሂብ መጠን ማስተናገድ ብንችልም፣ ይህ ለ CS ችግር ሆኖበታል። የምላሽ ጊዜ ማብቂያ መለኪያዎች ከነባሪው ጋር ሲነፃፀሩ በከፍተኛ ሁኔታ ቢጨምሩም በእነዚህ ጥራዞች ላይ እንኳን OperationTimedOutException በተደጋጋሚ ይጥላል።
በጋራ ጥረታችን በሲኤስ ውስጥ ያሉትን ማነቆዎች እንደምናገኝ ተስፋ አደርጋለሁ፣ እና ማፋጠን ከቻልን፣ ስለ መጨረሻው ውጤት መረጃ በእርግጠኝነት በጽሁፉ መጨረሻ ላይ እጨምራለሁ።
ዝማኔ፡- ለጓደኞቼ ምክር ምስጋና ይግባውና ንባቤን ማፋጠን ችያለሁ።
159,644 ኦፕስ (4 ሰንጠረዦች፣ 5 ክሮች፣ ባች 100)።
ተጨምሯል በ
.withLoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
እና የክር ክር ብዛትን ተጫወትኩ። ያገኘሁት ይሄ ነው፡
4 ሰንጠረዦች፣ 100 ክሮች፣ ባች = 1 (በተናጠል): 301,969 ኦፕስ
4 ሰንጠረዦች፣ 100 ክሮች፣ ባች = 10፡ 625,655 ኦፕስ
4 ሰንጠረዦች፣ 100 ክሮች፣ ባች = 100፡ 625,655 ኦፕስ
በኋላ ላይ ሌሎች የማስተካከያ ምክሮችን ተግባራዊ አደርጋለሁ፣ ሙሉ የሙከራ ዑደት አሄዳለሁ፣ እና ውጤቶቹን በልጥፉ መጨረሻ ላይ እጨምራለሁ።
ምንጭ: hab.com
