


ሰላም ለሁላችሁም! ስሜ ዲሚትሪ ሳምሶኖቭ እባላለሁ፣ እና በኦድኖክላስኒኪ ውስጥ እንደ ዋና የስርዓት አስተዳዳሪ እሰራለሁ። ከ7 በላይ አካላዊ አገልጋዮች፣ በደመናችን ውስጥ 11 ኮንቴይነሮች እና 200 አፕሊኬሽኖች አሉን፣ እነዚህም በተለያዩ ውቅሮች 700 የተለያዩ ክላስተሮችን ይፈጥራሉ። አብዛኛዎቹ አገልጋዮች እየሰሩ ነው። CentOS 7.
በኦገስት 14፣ 2018፣ ስለ FragmentSmack ተጋላጭነት መረጃ ታትሟል
() እና SegmentSmack (). እነዚህ ተጋላጭነቶች ከኔትወርክ ጥቃት ቬክተር እና ከፍተኛ ነጥብ (7.5) ጋር ሲሆኑ ይህም በንብረት መሟጠጥ (ሲፒዩ) ምክንያት የአገልግሎት መከልከልን (DoS) ያሰጋል። በዚያን ጊዜ ለFragmentSmack የከርነል መጠገኛ አልቀረበም ነበር፣ በተጨማሪም፣ ስለ ተጋላጭነቱ መረጃ ከታተመ በጣም ዘግይቶ ወጣ። SegmentSmackን ለማስወገድ ከርነሉን ለማዘመን ተጠቁሟል። የዝማኔው ጥቅል ራሱ በተመሳሳይ ቀን ተለቋል ፣ የቀረው እሱን መጫን ብቻ ነበር።
አይ፣ ከርነል ማዘመንን በፍጹም አንቃወምም! ሆኖም ፣ ልዩነቶች አሉ ...
ከርነልን በምርት ላይ እንዴት እናዘምነዋለን
በአጠቃላይ ምንም የተወሳሰበ ነገር የለም፡-
- ጥቅሎችን አውርድ;
- በበርካታ አገልጋዮች ላይ (የእኛን ደመና የሚያስተናግዱ አገልጋዮችን ጨምሮ) ላይ ይጫኑዋቸው;
- ምንም ነገር እንዳልተሰበረ ያረጋግጡ;
- ሁሉም መደበኛ የከርነል ቅንጅቶች ያለ ስህተቶች መተግበራቸውን ያረጋግጡ;
- ጥቂት ቀናት ይጠብቁ;
- የአገልጋይ አፈፃፀምን ያረጋግጡ;
- የአዳዲስ አገልጋዮችን ስምሪት ወደ አዲሱ ከርነል ይቀይሩ;
- ሁሉንም አገልጋዮች በመረጃ ማዕከል አዘምን (በችግር ጊዜ በተጠቃሚዎች ላይ ያለውን ተጽእኖ ለመቀነስ አንድ የውሂብ ማዕከል በአንድ ጊዜ);
- ሁሉንም አገልጋዮች ዳግም አስነሳ.
ያለንን የከርነል ቅርንጫፎች በሙሉ ይድገሙት። በአሁኑ ጊዜ፡-
- አክሲዮን CentOS 7 3.10 - ለአብዛኛዎቹ መደበኛ አገልጋዮች፤
- ቫኒላ 4.19 - ለኛ , ምክንያቱም BFQ, BBR, ወዘተ ያስፈልገናል.
- Elrepo kernel-ml 5.2 - ለ , ምክንያቱም 4.19 ቀድሞ ያልተረጋጋ ባህሪ ነበረው, ነገር ግን ተመሳሳይ ባህሪያት ያስፈልጋሉ.
እንደገመቱት በሺዎች የሚቆጠሩ አገልጋዮችን ዳግም ማስጀመር ረጅሙን ጊዜ ይወስዳል። ሁሉም ተጋላጭነቶች ለሁሉም አገልጋዮች ወሳኝ ስላልሆኑ፣ ከኢንተርኔት በቀጥታ ማግኘት የሚችሉትን ብቻ ነው ዳግም የምንጀምረው። በደመናው ውስጥ፣ ተለዋዋጭነትን ላለመገደብ፣ ወደ ውጪ የሚደርሱ መያዣዎችን ከግል አገልጋዮች ጋር በአዲስ ከርነል አናስርም፣ ነገር ግን ሁሉንም አስተናጋጆች ያለምንም ልዩነት ዳግም አስነሳን። እንደ እድል ሆኖ, እዚያ ያለው አሰራር ከመደበኛ አገልጋዮች ይልቅ ቀላል ነው. ለምሳሌ፣ ሀገር አልባ ኮንቴይነሮች ዳግም በሚነሳበት ጊዜ በቀላሉ ወደ ሌላ አገልጋይ መሄድ ይችላሉ።
ሆኖም ግን, አሁንም ብዙ ስራ አለ, እና ብዙ ሳምንታት ሊወስድ ይችላል, እና በአዲሱ ስሪት ላይ ምንም አይነት ችግሮች ካሉ, እስከ ብዙ ወራት ድረስ. አጥቂዎች ይህንን በደንብ ስለሚረዱ እቅድ ለ ያስፈልጋቸዋል።
FragmentSmack/SegmentSmack. የማጣራት ስራ
እንደ እድል ሆኖ፣ ለአንዳንድ ተጋላጭነቶች እንደዚህ ያለ እቅድ B አለ፣ እና እሱ Workaround ይባላል። ብዙ ጊዜ፣ ይህ የከርነል/የመተግበሪያ መቼት ለውጥ ሲሆን ይህም ሊከሰት የሚችለውን ውጤት ሊቀንስ ወይም የተጋላጭነትን ብዝበዛ ሙሉ በሙሉ ያስወግዳል።
በ FragmentSmack/SegmentSmack ጉዳይ የማስተካከያ ዘዴው እንደሚከተለው ነው-
«የ 4MB እና 3MB ነባሪ እሴቶችን በnet.ipv4.ipfrag_high_thresh እና net.ipv4.ipfrag_low_thresh (እና አቻዎቻቸው ለ ipv6 net.ipv6.ipfrag_high_thresh እና net.ipv6.ipfrag_low_thresh ወይም በአክብሮት) kB256 እና 192 kB ዝቅ ያለ። ሙከራዎች በሃርድዌር፣ መቼቶች እና ሁኔታዎች ላይ በመመስረት በጥቃቱ ወቅት በሲፒዩ አጠቃቀም ላይ ከትንሽ እስከ ጉልህ ጠብታዎች ያሳያሉ። ነገር ግን፣ በipfrag_high_thresh=262144 ባይት ምክንያት የተወሰነ የአፈጻጸም ተጽእኖ ሊኖር ይችላል፣ ምክንያቱም በአንድ ጊዜ ሁለት 64K ቁርጥራጮች ብቻ ወደ መልሶ ማሰባሰብያ ወረፋ ሊገቡ ይችላሉ። ለምሳሌ, ከትላልቅ የ UDP ፓኬቶች ጋር የሚሰሩ መተግበሪያዎች ሊሰበሩ የሚችሉበት አደጋ አለ».
መለኪያዎች እራሳቸው እንደሚከተለው ተገልጿል፡-
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
በምርት አገልግሎቶች ላይ ትልቅ ዩዲፒዎች የሉንም። በ LAN ላይ ምንም የተበታተነ ትራፊክ የለም፤ በ WAN ላይ የተበታተነ ትራፊክ አለ፣ ግን ጉልህ አይደለም። ምንም ምልክቶች የሉም - Workaroundን መልቀቅ ይችላሉ!
FragmentSmack/SegmentSmack. የመጀመሪያ ደም
ያጋጠመን የመጀመሪያው ችግር የደመና ኮንቴይነሮች አንዳንድ ጊዜ አዲሶቹን መቼቶች በከፊል (ipfrag_low_thresh ብቻ) ይተገብራሉ ፣ እና አንዳንድ ጊዜ በጭራሽ አይተገበሩም - በቀላሉ በጅምር ይወድቃሉ። ችግሩን በተረጋጋ ሁኔታ እንደገና ማባዛት አልተቻለም (ሁሉም ቅንብሮች ያለ ምንም ችግር በእጅ ተተግብረዋል)። ኮንቴይነሩ መጀመሪያ ላይ ለምን እንደሚበላሽ መረዳት እንዲሁ ቀላል አይደለም፡ ምንም ስህተቶች አልተገኙም። አንድ ነገር እርግጠኛ ነበር፡ ቅንብሩን ወደ ኋላ መመለስ ችግሩን በመያዣ ብልሽቶች ይፈታል።
በአስተናጋጁ ላይ Sysctl መተግበር በቂ ያልሆነው ለምንድነው? ኮንቴይነሩ የሚኖረው በራሱ በተዘጋጀው የአውታረ መረብ ስም ቦታ ነው፣ ስለዚህ ቢያንስ በመያዣው ውስጥ ከአስተናጋጁ ሊለያይ ይችላል.
የ Sysctl ቅንጅቶች በመያዣው ውስጥ በትክክል እንዴት ይተገበራሉ? የእኛ ኮንቴይነሮች ልዩ መብት ስለሌላቸው፣ ወደ መያዣው ውስጥ በመግባት ማንኛውንም የSysctl መቼት መቀየር አይችሉም - በቀላሉ በቂ መብቶች የሎትም። መያዣዎችን ለማስኬድ፣ የእኛ ደመና በዚያን ጊዜ Dockerን (አሁን ). የአዲሱ ኮንቴይነር መለኪያዎች አስፈላጊውን የ Sysctl ቅንብሮችን ጨምሮ በኤፒአይ በኩል ወደ Docker ተላልፈዋል።
በሥሪቶቹ ውስጥ በመፈለግ ላይ፣ የዶከር ኤፒአይ ሁሉንም ስህተቶች አልመለሰም (ቢያንስ በስሪት 1.10)። መያዣውን በ"docker run" ለመጀመር ስንሞክር በመጨረሻ ቢያንስ የሆነ ነገር አየን፡-
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
የመለኪያ እሴቱ ልክ አይደለም። ግን ለምን? እና ለምን አንዳንድ ጊዜ ብቻ የማይሰራው? ዶከር የ Sysctl መለኪያዎች የሚተገበሩበትን ቅደም ተከተል ዋስትና እንደማይሰጥ (የቅርብ ጊዜ የተሞከረው ስሪት 1.13.1 ነው)፣ ስለዚህ አንዳንድ ጊዜ ipfrag_high_thresh ipfrag_low_thresh 256M ሲሆን ወደ 3 ኪ ለመቀናጀት ይሞክራል ማለትም የላይኛው ወሰን ዝቅተኛ ነበር። ወደ ስህተቱ ምክንያት የሆነው ከዝቅተኛው ገደብ ይልቅ.
በዛን ጊዜ ፣ ከመጀመሪያው በኋላ መያዣውን እንደገና ለማዋቀር የራሳችንን ዘዴ እንጠቀማለን (መያዣውን ከቀዘቀዘ በኋላ እና በመያዣው የስም ቦታ ላይ ትዕዛዞችን በመፈጸም ላይ በዚህ ክፍል ላይ የ Sysctl መለኪያዎችን መፃፍ ጨምረናል። ችግሩ ተፈትቷል.
FragmentSmack/SegmentSmack. የመጀመሪያው ደም 2
Workaround in the cloud አጠቃቀምን ለመረዳት ጊዜ ከማግኘታችን በፊት ከተጠቃሚዎች የመጀመሪያዎቹ ብርቅዬ ቅሬታዎች መምጣት ጀመሩ። በዚያን ጊዜ በመጀመሪያዎቹ አገልጋዮች ላይ Workaround መጠቀም ከጀመረ ብዙ ሳምንታት አልፈዋል። የመጀመሪያው ምርመራ በግለሰብ አገልግሎቶች ላይ ቅሬታዎች እንደተቀበሉ ያሳያል, እና ሁሉም የእነዚህ አገልግሎቶች አገልጋዮች አይደሉም. ችግሩ እንደገና በጣም እርግጠኛ ያልሆነ ሆኗል.
በመጀመሪያ ደረጃ፣ የSysctl ቅንብሮችን ወደ ኋላ ለመመለስ ሞክረን ነበር፣ ግን ያ ምንም ውጤት አላስገኘም። የተለያዩ የአገልጋይ እና የመተግበሪያ ቅንብሮች ማሻሻሎችም አልረዱም። ዳግም ማስጀመር ረድቷል። ዳግም ማስጀመር ለ Linux አብሮ ለመስራት የተለመደ ሁኔታ እንደነበረው ሁሉ ከተፈጥሮ ውጪ የሆነ Windows በድሮ ጊዜ። ሆኖም ግን ሰርቷል፣ እና አዳዲስ የSysctl ቅንብሮችን ስንተገብር "የከርነል ችግር" ብለን ገምግመነዋል። እንዴት ሞኞች ነን...
ከሶስት ሳምንታት በኋላ ችግሩ እንደገና አገረሸ. የእነዚህ አገልጋዮች ውቅር በጣም ቀላል ነበር፡ Nginx በ proxy/balancer ሁነታ። ብዙ ትራፊክ የለም። አዲስ የመግቢያ ማስታወሻ: በየቀኑ በደንበኞች ላይ የ 504 ስህተቶች ቁጥር እየጨመረ ነው (). ግራፉ ለዚህ አገልግሎት በቀን የ504 ስህተቶችን ቁጥር ያሳያል፡-
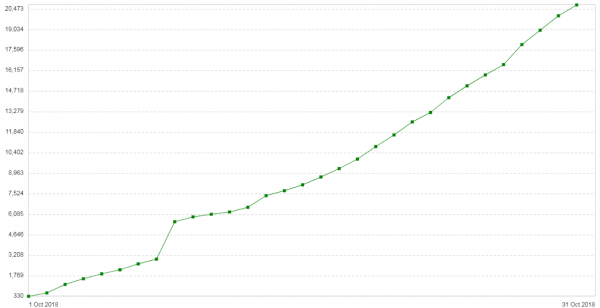
ስህተቶቹ ሁሉ ስለ አንድ አይነት የጀርባ ጀርባ - በደመና ውስጥ ስላለው ነው. በዚህ ጀርባ ላይ ያለው የጥቅል ቁርጥራጮች የማህደረ ትውስታ ፍጆታ ግራፍ ይህን ይመስላል።
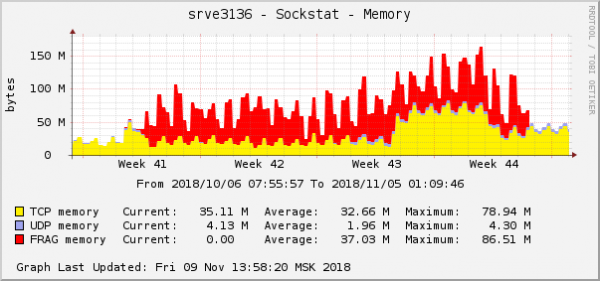
ይህ በስርዓተ ክወና ግራፎች ውስጥ በጣም ግልጽ ከሆኑ የችግሩ መገለጫዎች አንዱ ነው. በደመናው ውስጥ፣ ልክ በተመሳሳይ ጊዜ፣ በQoS (የትራፊክ ቁጥጥር) ቅንጅቶች ላይ ሌላ የአውታረ መረብ ችግር ተስተካክሏል። ለፓኬት ቁርጥራጭ የማህደረ ትውስታ ፍጆታ ግራፍ ላይ ፣ ልክ አንድ አይነት ይመስላል
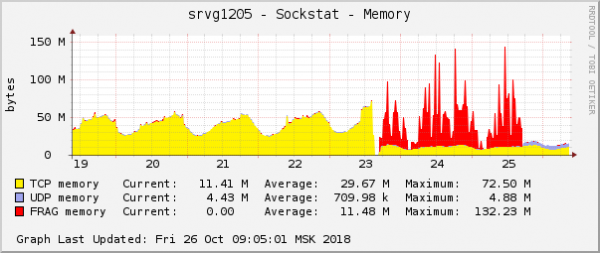
ግምቱ ቀላል ነበር-በግራፎቹ ላይ ተመሳሳይ የሚመስሉ ከሆነ, እነሱ ተመሳሳይ ምክንያት አላቸው. ከዚህም በላይ በዚህ ዓይነት የማስታወስ ችሎታ ላይ ያሉ ማናቸውም ችግሮች በጣም ጥቂት ናቸው.
የቋሚው ችግር ፍሬ ነገር የfq ፓኬት መርሐግብርን ከነባሪ ቅንጅቶች ጋር በQoS መጠቀማችን ነበር። በነባሪነት ለአንድ ግንኙነት 100 ፓኬጆችን ወደ ወረፋው ለመጨመር ይፈቅድልዎታል, እና አንዳንድ ግንኙነቶች በሰርጥ እጥረት ውስጥ, ወረፋውን ወደ አቅም መዝጋት ጀመሩ. በዚህ ሁኔታ, እሽጎች ይጣላሉ. በ tc ስታቲስቲክስ (tc -s qdisc) እንደሚከተለው ሊታይ ይችላል፡-
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545flows_plimit" ማለት የአንድ ግንኙነት የወረፋ ገደብ በማለፉ የተጣሉ እሽጎች ሲሆን "የወደቀ 464545" የሁሉም የተጣሉ የዚህ መርሐግብር እሽጎች ድምር ነው። የወረፋውን ርዝማኔ ወደ 1 ሺህ ከፍ በማድረግ እና ኮንቴይነሮችን እንደገና ካስጀመሩ በኋላ ችግሩ መከሰቱን አቆመ. ቁጭ ብለው ለስላሳ መጠጥ መጠጣት ይችላሉ.
FragmentSmack/SegmentSmack. የመጨረሻው ደም
በመጀመሪያ፣ የከርነል ተጋላጭነቶች ከተገለጹ ከጥቂት ወራት በኋላ፣ የFragmentSmack ጥገና በመጨረሻ ተለቀቀ (የነሐሴ ወር ማስታወቂያው ለSegmentSmack ማስተካከያ ብቻ አውጥቷል)፣ ይህም ብዙ ችግር ፈጥሮብን የነበረውን Workaroundን የመተው እድል ሰጥቶናል። በዚህ ጊዜ ውስጥ አንዳንድ አገልጋዮችን ወደ አዲሱ ከርነል አዛውረን ነበር፣ እና አሁን ከባዶ መጀመር ነበረብን። የFragmentSmack ጥገናን ሳንጠብቅ ከርነሉን ለምን አዘምንነው? እውነታው ግን ከእነዚህ ተጋላጭነቶች የመጠበቅ ሂደት ከWorkaround እራሱን ከማዘመን ሂደት ጋር ተገጣጠመ (እና ተዋህዷል)። CentOS (ይህም ከርነሉን ብቻ ከማዘመን የበለጠ ጊዜ ይወስዳል)። ከዚህም በተጨማሪ፣ SegmentSmack የበለጠ አደገኛ ተጋላጭነት ነው፣ እና ወዲያውኑ ለእሱ ማስተካከያ ስለተገኘ ምክንያታዊ ነበር። ሆኖም ግን፣ ከርነሉን ማዘመን ብቻ ነው CentOS በFragmentSmack ወቅት በታየው ተጋላጭነት ምክንያት አልቻልንም። CentOS 7.5 በስሪት 7.6 ብቻ ተስተካክሏል፣ ስለዚህ ዝመናውን ወደ 7.5 አቁመን ወደ 7.6 በማዘመን እንደገና መጀመር ነበረብን። ይህ ደግሞ ይከሰታል።
በሁለተኛ ደረጃ፣ ስለችግሮች እምብዛም የተጠቃሚ ቅሬታዎች ወደ እኛ ተመልሰዋል። አሁን ሁሉም ከደንበኞች ወደ አንዳንድ አገልጋዮቻችን ፋይሎችን ከመጫን ጋር የተገናኙ መሆናቸውን በእርግጠኝነት እናውቃለን። ከዚህም በላይ ከጠቅላላው ብዛት በጣም ጥቂት ቁጥር ያላቸው ሰቀላዎች በእነዚህ አገልጋዮች በኩል አልፈዋል።
ከላይ ካለው ታሪክ እንደምናስታውሰው፣ Sysctl ወደ ኋላ መመለስ አልረዳም። ዳግም ማስጀመር ረድቷል፣ ግን ለጊዜው።
በ Sysctl ላይ ያሉ ጥርጣሬዎች አልተወገዱም, ነገር ግን በዚህ ጊዜ በተቻለ መጠን ብዙ መረጃዎችን መሰብሰብ አስፈላጊ ነበር. ምን እየተከሰተ እንዳለ በትክክል ለማጥናት የሰቀላውን ችግር በደንበኛው ላይ እንደገና የማባዛት ችሎታ በጣም ትልቅ እጥረት ነበር።
የሁሉም የሚገኙ ስታቲስቲክስ እና ምዝግብ ማስታወሻዎች ትንተና ምን እየተከሰተ እንዳለ ለመረዳት እንድንችል አላደረገንም። አንድ የተወሰነ ግንኙነት "ለመሰማት" ችግሩን እንደገና የመድገም ችሎታ ከፍተኛ እጥረት ነበር. በመጨረሻም ገንቢዎቹ የመተግበሪያውን ልዩ ስሪት በመጠቀም በ Wi-Fi በኩል ሲገናኙ በሙከራ መሣሪያ ላይ የተረጋጋ የችግሮችን መራባት ችለዋል። ይህ በምርመራው ውስጥ አንድ ግኝት ነበር. ደንበኛው ከNginx ጋር ተገናኝቷል፣ እሱም ለኋለኛው ተኪ፣ እሱም የጃቫ መተግበሪያችን ነው።
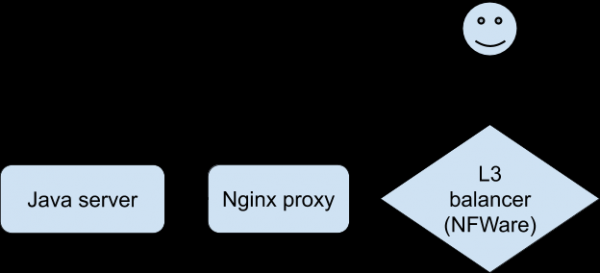
የችግሮች ምልልስ እንደዚህ ነበር (በ Nginx ፕሮክሲ ጎን ላይ ተስተካክሏል)
- ደንበኛ፡ ፋይል ስለማውረድ መረጃ እንዲቀበል ይጠይቁ።
- ጃቫ አገልጋይ: ምላሽ.
- ደንበኛ፡ POST ከፋይል ጋር።
- የጃቫ አገልጋይ: ስህተት.
በተመሳሳይ ጊዜ የጃቫ አገልጋይ 0 ባይት ውሂብ ከደንበኛው እንደተቀበለ እና የ Nginx ፕሮክሲው ጥያቄው ከ 30 ሰከንድ በላይ እንደወሰደ ይጽፋል (30 ሰከንድ የደንበኛው መተግበሪያ ጊዜው ያለፈበት ነው)። ለምን ጊዜው አልፎበታል እና ለምን 0 ባይት? ከኤችቲቲፒ እይታ አንጻር ሁሉም ነገር እንደ ሚሰራው ይሰራል ነገር ግን ከፋይሉ ጋር ያለው POST ከአውታረ መረቡ የሚጠፋ ይመስላል። ከዚህም በላይ በደንበኛው እና በ Nginx መካከል ይጠፋል. በTcpdump እራስዎን ለማስታጠቅ ጊዜው አሁን ነው! ግን በመጀመሪያ የአውታረ መረብ አወቃቀሩን መረዳት ያስፈልግዎታል. Nginx ፕሮክሲ ከL3 ሚዛን ጀርባ ነው። . መሿለኪያ እሽጎችን ከL3 ሚዛን ወደ አገልጋዩ ለማድረስ ይጠቅማል፣ ይህም የራስጌዎቹን ወደ እሽጎች ይጨምራል፡
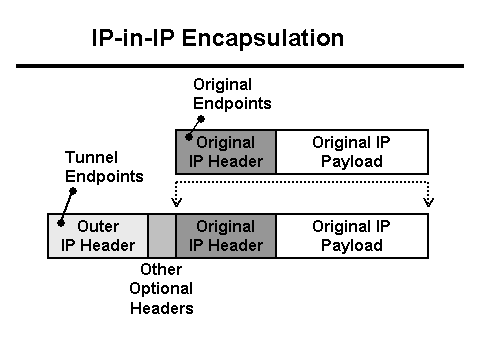
በዚህ አጋጣሚ አውታረ መረቡ ወደዚህ አገልጋይ የሚመጣው በቭላን መለያ በተሰየመ ትራፊክ መልክ ሲሆን ይህም የራሱን መስኮች ወደ እሽጎች ይጨምራል።
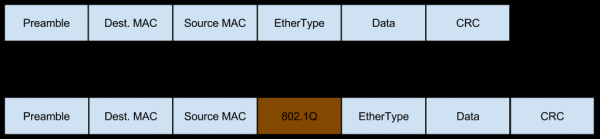
እና ይህ ትራፊክም ሊከፋፈል ይችላል (ከWorkaround የሚመጡትን ስጋቶች ስንገመግም የተነጋገርነው ያው ትንሽ መቶኛ ገቢ የተከፋፈለ ትራፊክ)፣ ይህ ደግሞ የራስጌዎቹን ይዘት ይለውጣል፡
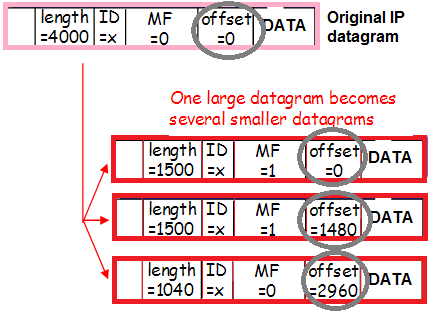
አንዴ በድጋሚ: እሽጎች በቭላን ታግ, በዋሻ ተሸፍነዋል, የተቆራረጡ ናቸው. ይህ እንዴት እንደሚከሰት በተሻለ ለመረዳት ከደንበኛው ወደ Nginx ፕሮክሲው የፓኬት መንገድን እንፈልግ።
- ፓኬቱ ወደ L3 ሚዛን ይደርሳል. በመረጃ ማእከሉ ውስጥ ለትክክለኛው መስመር፣ ፓኬቱ በዋሻው ውስጥ ተሸፍኖ ወደ አውታረመረብ ካርድ ይላካል።
- የፓኬት + መሿለኪያ ራስጌዎች ወደ MTU የማይገቡ ስለሆኑ ፓኬጁ ወደ ቁርጥራጮች ተቆርጦ ወደ አውታረ መረቡ ይላካል።
- ከ L3 ሚዛን በኋላ ያለው ማብሪያ / ማጥፊያ ፣ ፓኬት ሲቀበል ፣ በላዩ ላይ የቭላን መለያ ይጨምራል እና ይልከዋል።
- በአናፊክስ ተኪ ፊት ለፊት ያለው ማብሪያ (በባህር ማቅረቢያዎች ላይ የተመሠረተ) አገልጋዩ የ VLAN የተሰራ ፓኬት እየጠበቀ ያለ ነው, ስለሆነም የ VLAN መለያ ሳይያስወግደው እንደሌለው ነው.
- Linux የግለሰብ ፓኬጆችን ቁርጥራጮች ይቀበላል እና ወደ አንድ ትልቅ ፓኬጅ ያስቀምጣቸዋል።
- በመቀጠል, ፓኬቱ ወደ ቭላን በይነገጽ ይደርሳል, የመጀመሪያው ንብርብር ከእሱ ይወገዳል - ቭላን ማቀፊያ.
- እንግዲህ Linux ወደ ዋሻው በይነገጽ ይልከዋል፣ እዚያም ሌላ ንብርብር ከእሱ ይወገዳል - የዋሻው መክፈያ።
ችግሩ ይህንን ሁሉ እንደ መለኪያዎች ወደ tcpdump ማስተላለፍ ነው።
ከመጨረሻው እንጀምር፡ ንፁህ (አላስፈላጊ ራስጌዎች የሌሉበት) ከደንበኞች የአይ ፒ ጥቅሎች፣ ቪላን እና መሿለኪያ መሸፈኛዎች ተወግደዋል?
tcpdump host <ip клиента>
አይ፣ በአገልጋዩ ላይ እንደዚህ ያሉ ጥቅሎች አልነበሩም። ስለዚህ ችግሩ ቀደም ብሎ መሆን አለበት. የቭላን ማቀፊያ ብቻ የተወገዱ እሽጎች አሉ?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx የደንበኛው አይ ፒ አድራሻ በሄክስ ቅርጸት ነው።
32:4 - በዋሻው ፓኬት ውስጥ SCR IP የተጻፈበት የመስክ አድራሻ እና ርዝመት።
በይነመረብ ላይ ስለ 40 ፣ 44 ፣ 50 ፣ 54 ስለሚጽፉ የመስክ አድራሻው በብርቱ ኃይል መመረጥ ነበረበት ፣ ግን እዚያ ምንም የአይፒ አድራሻ አልነበረም። እንዲሁም በሄክስ ውስጥ ካሉት እሽጎች ውስጥ አንዱን (የ -xx ወይም -XX ፓራሜትር በ tcpdump) ማየት እና የሚያውቁትን የአይፒ አድራሻ ማስላት ይችላሉ።
ያለ ቭላን እና ቶንል ሽፋን ያልተወገዱ የፓኬት ቁርጥራጮች አሉ?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
ይህ አስማት የመጨረሻውን ጨምሮ ሁሉንም ቁርጥራጮች ያሳየናል. ምናልባት, ተመሳሳይ ነገር በአይፒ ሊጣራ ይችላል, ነገር ግን እኔ አልሞከርኩም, ምክንያቱም በጣም ብዙ እንደዚህ ያሉ እሽጎች ስለሌሉ, እና የሚያስፈልጓቸው በአጠቃላይ ፍሰት ውስጥ በቀላሉ ተገኝተዋል. እነሆ፡-
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 በ00:de:ff:1a:94:11 ethertype IPv4 (0x0800)፣ ርዝመት 62: (tos 0x0፣ tl 63፣ መታወቂያ 53652፣ ማካካሻ 1480, ባንዲራዎች [ምንም]፣ ፕሮቶ አይፒአይፒ (4)፣ ርዝመት 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000፡ 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010፡ 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020፡ 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .ፋኢ...ዲ-፣.!...ሲ
0x0030፡ x978 e91d x9b0 d608 0000 0000 0000 7c31 .x...........|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
እነዚህ ሁለት ቁርጥራጮች የአንድ ጥቅል (ተመሳሳይ መታወቂያ 53652) ከፎቶግራፍ ጋር (ኤግዚፍ የሚለው ቃል በመጀመሪያው ጥቅል ውስጥ ይታያል)። በዚህ ደረጃ ላይ እሽጎች በመኖራቸው, ነገር ግን በቆሻሻ ማጠራቀሚያዎች ውስጥ በተዋሃደ ቅፅ ውስጥ አይደለም, ችግሩ በስብሰባው ላይ በግልጽ ይታያል. በመጨረሻም ለዚህ የሰነድ ማስረጃ አለ!
የፓኬት ዲኮደር ግንባታውን የሚከለክል ምንም አይነት ችግር አላሳየም። እዚህ ሞክረው፡- . መጀመሪያ ላይ አንድ ነገር ለማከማቸት ሲሞክሩ ዲኮደሩ የፓኬት ቅርጸቱን አይወድም። በ Srcmac እና Ethertype መካከል (ከቁርጥራጭ መረጃ ጋር ያልተዛመደ) አንዳንድ ተጨማሪ ሁለት octets እንደነበሩ ታወቀ። እነሱን ካስወገዱ በኋላ ዲኮደር መሥራት ጀመረ. ይሁን እንጂ ምንም ችግር አላሳየም.
አንድ ሰው የሚናገረው ምንም ይሁን ምን፣ ከ Sysctl በስተቀር ሌላ ምንም ነገር አልተገኘም። የቀረው ሁሉ ልኬቱን ለመረዳት እና ተጨማሪ እርምጃዎችን ለመወሰን ችግር አገልጋዮችን የሚለይበት መንገድ መፈለግ ብቻ ነበር። የሚፈለገው ቆጣሪ በፍጥነት በበቂ ሁኔታ ተገኝቷል፡-
netstat -s | grep "packet reassembles failed”
እንዲሁም በ snmpd በ OID=1.3.6.1.2.1.4.31.1.1.16.1 (OID) ስር ይገኛል።).
"በአይፒ ዳግም ማሰባሰብ ስልተ-ቀመር (በማንኛውም ምክንያት: ጊዜው አልፎበታል, ስህተቶች, ወዘተ.) የተገኙ ውድቀቶች ብዛት."
ችግሩ ከተጠናባቸው የአገልጋዮች ቡድን መካከል፣ በሁለት ላይ ይህ ቆጣሪ በፍጥነት ጨምሯል። የዚህን ቆጣሪ ተለዋዋጭነት በጃቫ አገልጋይ ላይ ካሉት የኤችቲቲፒ ስህተቶች ተለዋዋጭነት ጋር ማነፃፀር አንድ ግኑኝነት አሳይቷል። ማለትም ቆጣሪው ቁጥጥር ሊደረግበት ይችላል.
የችግሮች አስተማማኝ አመልካች መኖሩ Sysctl ወደ ኋላ መመለስ ይረዳል እንደሆነ በትክክል ለመወሰን በጣም አስፈላጊ ነው ምክንያቱም ካለፈው ታሪክ ይህ ከመተግበሪያው ወዲያውኑ መረዳት እንደማይቻል እናውቃለን። ይህ አመልካች ተጠቃሚዎች ከማግኘታቸው በፊት በምርት ውስጥ ያሉ ሁሉንም የችግር አካባቢዎችን እንድንለይ ያስችለናል።
Sysctl ወደ ኋላ ከተገለበጠ በኋላ የክትትል ስህተቶቹ ቆመዋል፣ስለዚህ የችግሮቹ መንስኤ ተረጋግጧል፣እንዲሁም የመልሶ ማቋረጡ ይረዳል።
አዲስ ክትትል በተጀመረበት በሌሎች አገልጋዮች ላይ የመከፋፈያ ቅንጅቶችን ወደ ኋላ መለስን እና የሆነ ቦታ ቀደም ሲል ከነባሪው የበለጠ ተጨማሪ ማህደረ ትውስታን ለክፍሎች መድበናል (ይህ የ UDP ስታቲስቲክስ ነበር ፣ የእሱ ከፊል ኪሳራ በአጠቃላይ ዳራ ላይ የማይታይ ነው) .
በጣም አስፈላጊ ጥያቄዎች
ለምንድነው እሽጎች በእኛ L3 ሚዛን ላይ የተከፋፈሉት? ከተጠቃሚዎች ወደ ሚዛን ሰጪዎች የሚደርሱት አብዛኛዎቹ እሽጎች SYN እና ACK ናቸው። የእነዚህ ፓኬጆች መጠኖች ትንሽ ናቸው. ነገር ግን የእነዚህ እሽጎች ድርሻ በጣም ትልቅ ስለሆነ ከጀርባዎቻቸው አንጻር መቆራረጥ የጀመሩ ትላልቅ ፓኬቶች መኖራቸውን አላስተዋልንም.
ምክንያቱ የተሰበረ የውቅር ስክሪፕት ነበር። የቭላን በይነገጽ ባላቸው አገልጋዮች ላይ (በዚያን ጊዜ በምርት ውስጥ መለያ የተደረገባቸው ትራፊክ ያላቸው በጣም ጥቂት አገልጋዮች ነበሩ)። Advmss በአቅጣጫችን ያሉት እሽጎች መጠናቸው ያነሱ መሆን አለባቸው የሚለውን መረጃ ለደንበኛው እንድናስተላልፍ ያስችለናል ስለዚህም የመሿለኪያ ራስጌዎችን ከነሱ ጋር ካያያዝን በኋላ መቆራረጥ የለባቸውም።
ለምን Sysctl መልሶ ማሽከርከር አልረዳም፣ ግን ዳግም ማስነሳቱ ረዳ? Rolling back Sysctl ጥቅሎችን ለማዋሃድ ያለውን የማህደረ ትውስታ መጠን ቀይሯል። በተመሳሳይ ጊዜ፣ ለፍርስራሾች የማስታወስ ችሎታ መብዛቱ የግንኙነቶች መቀዛቀዝ እንዲፈጠር ምክንያት ሆኗል፣ ይህም ቁርጥራጮች በሰልፍ ውስጥ ለረጅም ጊዜ እንዲዘገዩ አድርጓል። ያም ማለት ሂደቱ በዑደት ውስጥ ነበር.
ዳግም ማስነሳቱ ማህደረ ትውስታውን አጽድቷል እና ሁሉም ነገር ወደ ትዕዛዝ ተመለሰ.
ያለ Workaround ማድረግ ይቻል ነበር? አዎ, ነገር ግን ጥቃት በሚደርስበት ጊዜ ተጠቃሚዎችን ያለ አገልግሎት የመተው ከፍተኛ አደጋ አለ. በእርግጥ የዎርክአውውን አጠቃቀም ለተጠቃሚዎች የአንዱ አገልግሎት መቀዛቀዝ ጨምሮ የተለያዩ ችግሮችን አስከትሏል፣ነገር ግን ድርጊቶቹ ትክክለኛ ናቸው ብለን እናምናለን።
አንድሬ ቲሞፊቭ (ለ) አመሰግናለሁ) ምርመራውን ለማካሄድ እርዳታ እንዲሁም አሌክሲ ክሬኔቭ () - ለታይታኒክ የማዘመን ሥራ Centos እና የሰርቨር ኮሮች። በዚህ ሁኔታ፣ ሂደቱ ብዙ ጊዜ እንደገና መጀመር ነበረበት፣ በዚህም ምክንያት ብዙ ወራትን ይወስዳል።
ምንጭ: hab.com
