

ሰላም! ስሜ ዳኒል ሊፖቮይ እባላለሁ፣ እና በSbertech የሚገኘው ቡድናችን HBaseን እንደ ኦፕሬቲንግ ዳታ መጋዘን መጠቀም ጀምሯል። ስናስስ፣ በስርዓት ለማስቀመጥ እና ለመግለጽ የፈለግነውን ጠቃሚ ተሞክሮ አከማችተናል (ይህ ለብዙዎች ጠቃሚ እንደሚሆን ተስፋ እናደርጋለን)። ከዚህ በታች ያሉት ሁሉም ሙከራዎች የተከናወኑት ከHBase ስሪቶች 1.2.0-cdh5.14.2 እና 2.0.0-cdh6.0.0-beta1 ጋር ነው።
- አጠቃላይ አርክቴክቸር
- ውሂብ ወደ HBASE በመጻፍ ላይ
- ከ HBASE የተገኘውን ውሂብ በማንበብ ላይ
- የውሂብ መሸጎጫ
- ባለብዙ ጌት/ባለብዙ ፑት ባች የውሂብ ሂደት
- ሰንጠረዦችን ወደ ክልሎች መከፋፈል (የመፍሰስ) ስትራቴጂ
- የስህተት መቻቻል፣ የታመቀነት እና የውሂብ አካባቢ
- ቅንብሮች እና አፈጻጸም
- የጭንቀት ሙከራ
- ግኝቶች
1. አጠቃላይ አርክቴክቸር
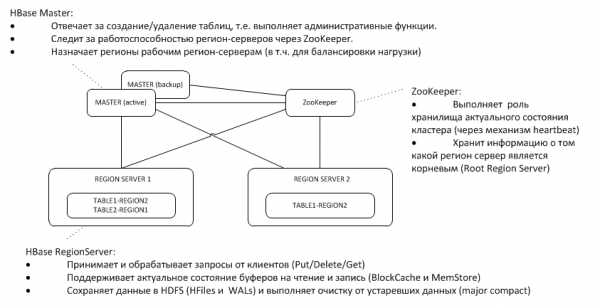
የመጠባበቂያ ማስተር በኖድ ላይ ያለውን ንቁ የዞኪፐር የልብ ምት ያዳምጣል እና ቢጠፋ የማስተርስን ተግባራት ይቆጣጠራል።
2. ውሂብ ወደ HBASE መጻፍ
በመጀመሪያ ቀላሉን ጉዳይ እንመልከት፡- የቁልፍ እሴት ነገርን በput(rowkey) በመጠቀም ወደ ሠንጠረዥ መጻፍ። ደንበኛው መጀመሪያ የhbase:meta ሰንጠረዥን የሚያከማችውን የroot Region Server (RRS) ቦታ መወሰን አለበት። ይህንን መረጃ ከZooKeeper ያገኛል። ከዚያም RRSን ይደርስና የhbase:meta ሰንጠረዥን ያነባል፣ ከዚያ የ RegionServer (RS) በፍላጎት ሰንጠረዥ ውስጥ ለተሰጠ የrowkey ውሂብ ለማከማቸት ኃላፊነት ያለበት የትኛው RegionServer (RS) እንደሆነ መረጃ ያገኛል። ለወደፊት ጥቅም፣ metatable በደንበኛው ይሸጎጣል፣ ስለዚህ ቀጣይ መዳረሻዎች ፈጣን እና በቀጥታ ወደ RS ይሄዳሉ።
ጥያቄ ሲደርሰው፣ RS መጀመሪያ ወደ WriteAheadLog (WAL) ይጽፈዋል፣ ይህም አደጋ ሲከሰት መልሶ ለማግኘት አስፈላጊ ነው። ከዚያም መረጃውን በMemStore ውስጥ ያከማቻል፣ ይህም ለተወሰነ ክልል የተደረደሩ የቁልፍ ስብስቦችን የያዘ በማስታወሻ ውስጥ ያለ ቋት ነው። አንድ ሰንጠረዥ ወደ ክልሎች (ክፍሎች) ሊከፈል ይችላል፣ እያንዳንዳቸው የተከፋፈሉ የቁልፍ ስብስቦችን ይይዛሉ። ይህ ክልሎችን በተለያዩ አገልጋዮች ላይ በማስቀመጥ ከፍተኛ አፈጻጸም እንዲኖር ያስችላል። ሆኖም፣ ይህ ግልጽ መግለጫ ቢኖርም፣ ይህ በሁሉም ሁኔታዎች እንደማይሰራ በኋላ ላይ እናያለን።
አንድ መዝገብ በMemStore ውስጥ ከተቀመጠ በኋላ፣ ደንበኛው መዝገቡ በተሳካ ሁኔታ እንደተቀመጠ የሚጠቁም ምላሽ ያገኛል። ሆኖም፣ መዝገቡ በእውነቱ በቋፍ ውስጥ ብቻ የሚከማች ሲሆን የተወሰነ ጊዜ ካለፈ በኋላ ወይም ቋቱ በአዲስ መረጃ ሲሞላ ብቻ ወደ ዲስክ ይፃፋል።
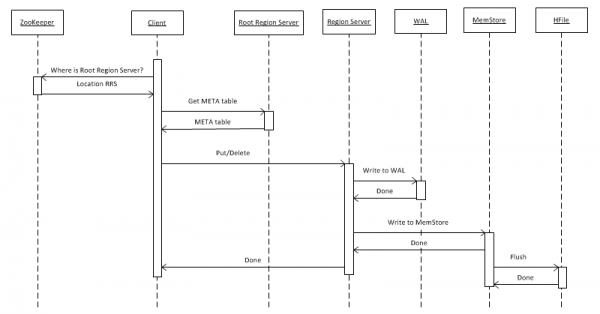
"ሰርዝ" የሚለው ተግባር ሲከናወን፣ መረጃው በአካል አይሰረዝም። በቀላሉ እንደተሰረዘ ምልክት ይደረግበታል፣ እና ጥፋቱ ራሱ የሚከሰተው ዋናው የታመቀ ተግባር ሲጠራ ነው፣ ይህም በክፍል 7 ውስጥ በዝርዝር ተገልጿል።
በኤችፋይል ቅርጸት ያሉ ፋይሎች በኤችዲኤፍኤስ ይከማቻሉ፣ እና ከጊዜ ወደ ጊዜ፣ ትንሽ የታመቀ ሂደት ይካሄዳል፣ ይህም ምንም ነገር ሳይሰርዝ ትናንሽ ፋይሎችን ወደ ትላልቅ ፋይሎች ያዋህዳል። ከጊዜ በኋላ፣ ይህ ውሂብ ሲያነቡ ብቻ የሚታይ ችግር ይሆናል (በኋላ ላይ ወደዚህ እንመለሳለን)።
ከላይ ከተገለጸው የመጫኛ ሂደት በተጨማሪ፣ የበለጠ ቀልጣፋ የሆነ አሰራር አለ፣ ይህም ምናልባት የዚህ የውሂብ ጎታ ጠንካራ ባህሪ ነው፡ BulkLoad። HFiles ን በእጅ መፍጠር እና ወደ ዲስክ መጫንን ያካትታል፣ ይህም እጅግ በጣም ጥሩ የማስፋፊያ አቅም እንዲኖር እና በጣም የተከበረ ፍጥነትን እንዲያገኙ ያስችላል። በመሠረቱ፣ እዚህ ያለው ገደብ HBase ሳይሆን የሃርድዌር ችሎታዎች ነው። ከዚህ በታች 16 RegionServers እና 16 YARN NodeManagers (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 ክሮች)፣ HBase ስሪት 1.2.0-cdh5.14.2 ባካተተ ክላስተር ላይ የመጫኛ ውጤቶች ናቸው።
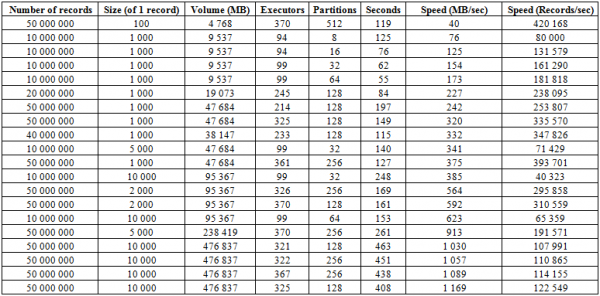
እዚህ ላይ በሠንጠረዡ ውስጥ ያሉትን የክፍፍሎች (ክልሎች) ብዛት እንዲሁም የስፓርክ አስፈፃሚዎችን መጨመር የመጫኛ ፍጥነትን እንደሚጨምር እናያለን። ፍጥነት በጽሑፍ መጠን ላይም ይወሰናል። ትላልቅ ብሎኮች በMB/ሰከንድ ጭማሪ ይሰጣሉ፣ ትናንሽ ብሎኮች ደግሞ በጊዜ አሃድ ውስጥ የተካተቱትን መዝገቦች ብዛት ይጨምራሉ፣ ሌሎች ነገሮችም እኩል ናቸው።
እንዲሁም ፍጥነቱን በእጥፍ ለማሳደግ ሁለት ጠረጴዛዎችን በአንድ ጊዜ መጫን ይችላሉ። ከዚህ በታች፣ 10 ኪባ ብሎኮችን ወደ ሁለት ጠረጴዛዎች በአንድ ጊዜ መጻፍ በእያንዳንዱ በግምት 600 ሜባ/ሰከንድ (በአጠቃላይ 1275 ሜባ/ሰከንድ) እንደሚሄድ ማየት ይችላሉ፣ ይህም በአንድ ጠረጴዛ ላይ በ623 ሜባ/ሰከንድ ከመጻፍ ጋር ተመሳሳይ ነው (ከላይ #11ን ይመልከቱ)።

ሁለተኛው የ50 ኪባ መዝገቦች ያሉት ሂደት የመጫኛ ፍጥነቱ በትንሹ ብቻ እንደሚጨምር ያሳያል፣ ይህም ከፍተኛው እሴት እየቀረበ መሆኑን ያሳያል። እዚህ ላይ HBASE ራሱ ምንም አይነት ጭነት እንደሌለው ማስታወስ አስፈላጊ ነው። መጀመሪያ የሚያስፈልገው መረጃውን ከ hbase:meta ማግኘት ነው፣ ከዚያም HFiles ን ምትኬ ካስቀመጡ በኋላ፣ የBlockCache ውሂብን ማፍሰስ እና ባዶ ካልሆነ የMemStore ቋቱን ወደ ዲስክ ማስቀመጥ ነው።
3. ከ HBASE የተገኘውን መረጃ ማንበብ
ከ hbase:meta የሚገኘው መረጃ ሁሉ ለደንበኛው አስቀድሞ የሚገኝ መሆኑን ከግምት ውስጥ በማስገባት (ነጥብ 2ን ይመልከቱ)፣ ጥያቄው በቀጥታ ወደ RS ይሄዳል፣ እዚያም የሚፈለገው ቁልፍ ይከማቻል። ፍለጋው መጀመሪያ የሚከናወነው በMemCache ነው። መረጃው እዚያ ቢኖርም ይሁን አይሁን፣ ፍለጋው በBlockCache ቋት ውስጥ እና አስፈላጊ ከሆነም በHFiles ውስጥ ይከናወናል። መረጃው በፋይል ውስጥ ከተገኘ፣ በBlockCache ውስጥ ይቀመጣል እና በሚቀጥለው ጥያቄ ላይ በበለጠ ፍጥነት ይመለሳል። በHFile ውስጥ መፈለግ በBloom ማጣሪያ በመጠቀም በአንጻራዊነት ፈጣን ነው፤ አነስተኛ መጠን ያለው ውሂብ ካነበበ በኋላ፣ ፋይሉ የሚያስፈልገውን ቁልፍ የያዘ መሆኑን ወዲያውኑ ይወስናል፣ ካልሆነም ወደሚቀጥለው ፋይል ይሄዳል።
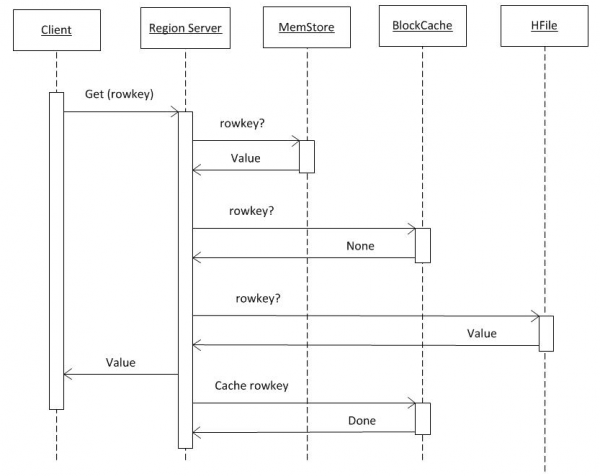
ከእነዚህ ሶስት ምንጮች መረጃ ከተቀበለ በኋላ፣ አርኤስ ምላሽ ይፈጥራል። በተለይም፣ ደንበኛው ስሪት እንዲዘጋጅ ከጠየቀ በአንድ ጊዜ በርካታ የተገኙ የአንድ ነገር ስሪቶችን ማስተላለፍ ይችላል።
4. የውሂብ መሸጎጫ
የMemStore እና የBlockCache ቋቶች በRS ውስጥ ከተመደበው የክምር ማህደረ ትውስታ እስከ 80% ይይዛሉ (የተቀረው ለRS የአገልግሎት ተግባራት የተያዘ ነው)። የተለመደው የአጠቃቀም ሁኔታ ተመሳሳይ መረጃዎችን የመጻፍ እና ወዲያውኑ የማንበብ ሂደቶችን የሚይዝ ከሆነ፣ BlockCacheን መቀነስ እና MemStoreን መጨመር ምክንያታዊ ነው፣ ምክንያቱም ውሂብ በሚጽፉበት ጊዜ የንባብ መሸጎጫ አይመታም እና BlockCache በተደጋጋሚ ጥቅም ላይ አይውልም። የBlockCache ቋት ሁለት ክፍሎችን ያቀፈ ነው፡ LruBlockCache (ሁልጊዜ በክምር ላይ) እና BucketCache (ብዙውን ጊዜ ከክምር ውጪ ወይም በSSD ላይ)። BucketCache ብዙ የንባብ ጥያቄዎች ሲኖሩ እና በLruBlockCache ውስጥ የማይገቡ ሲሆኑ ጥቅም ላይ መዋል አለበት፣ ይህም ወደ ንቁ የቆሻሻ መሰብሰብ እንቅስቃሴ ይመራል። ሆኖም፣ የንባብ መሸጎጫውን ከመጠቀም አስደናቂ የአፈጻጸም ጭማሪ መጠበቅ የለብዎትም፣ ነገር ግን በደረጃ 8 ወደዚህ እንመለሳለን።
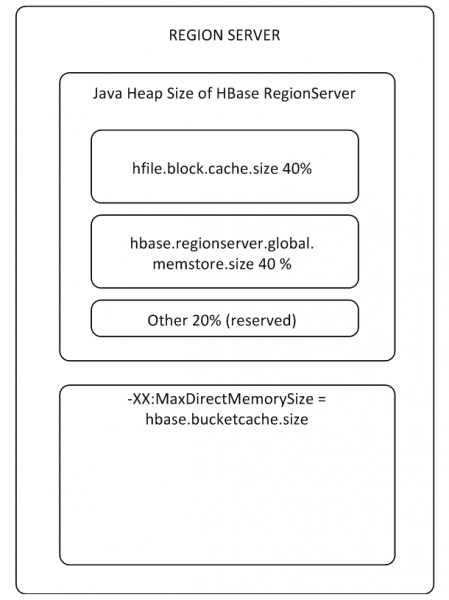
ለጠቅላላው RS አንድ BlockCache አለ፣ እና እያንዳንዱ ሠንጠረዥ የራሱ የሆነ MemStore አለው (ለእያንዳንዱ የአምድ ቤተሰብ አንድ)።
እንዴት በንድፈ ሀሳብ፣ ወደ መሸጎጫ የተፃፈ መረጃ አይጻፍም፣ እና በእርግጥም፣ የCACHE_DATA_ON_WRITE ሰንጠረዥ መለኪያ እና "በWrite ላይ ያለው የመሸጎጫ ዳታ" RS መለኪያ ወደ ሐሰት ተዋቅረዋል። ሆኖም ግን፣ በተግባር፣ ወደ MemStore ውሂብ ከጻፉ፣ ከዚያም ወደ ዲስክ (በዚህም በማጽዳት) ካጸዱት፣ እና ከዚያ የተገኘውን ፋይል ከሰረዙ፣ የGET ጥያቄን በመፈጸም ውሂቡን በተሳካ ሁኔታ ያገኛሉ። ከዚህም በላይ፣ BlockCache ን ሙሉ በሙሉ ካሰናከሉ እና ጠረጴዛውን በአዲስ መረጃ ቢሞሉም፣ ከዚያም MemStoreን ወደ ዲስክ ቢያስወግዱት፣ ቢሰርዙት እና ከሌላ ክፍለ ጊዜ ቢጠይቁትም፣ መረጃው አሁንም ከየትኛውም ቦታ ይሰረዛል። ስለዚህ፣ HBase ውሂብን ብቻ ሳይሆን ሚስጥራዊ ምስጢሮችንም ያከማቻል።
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
"በንባብ ላይ ያለ የመሸጎጫ ውሂብ" መለኪያ ወደ ሐሰት ተዋቅሯል። ማንኛውም ሀሳብ ካለዎት እባክዎ በአስተያየቶቹ ውስጥ ይወያዩባቸው።
5. የባች ዳታ ማቀናበር MultiGet/MultiPut
ነጠላ ጥያቄዎችን (Get/Put/Delete) ማስኬድ በጣም ውድ ነው፣ ስለዚህ በተቻለ መጠን ወደ ዝርዝር ወይም ዝርዝር ማዋሃድ አፈጻጸምን በእጅጉ ሊያሻሽል ይችላል። ይህ በተለይ ለጽሑፍ ስራዎች እውነት ነው፣ ነገር ግን ማንበብ ወጥመድ ይፈጥራል። ከታች ያለው ግራፍ ከMemStore 50,000 መዝገቦችን ለማንበብ የሚፈጀውን ጊዜ ያሳያል። ንባቡ የተከናወነው በአንድ ክር ሲሆን አግድም ዘንግ በጥያቄው ውስጥ ያሉትን የቁልፍ ብዛት ያሳያል። በአንድ ጥያቄ ውስጥ ያሉት የቁልፍ ብዛት ወደ አንድ ሺህ ሲጨምር የማስፈጸሚያ ጊዜ እንደሚቀንስ ግልፅ ነው፣ ይህም ማለት አፈጻጸም ይጨምራል ማለት ነው። ሆኖም፣ በነባሪነት የ MSLAB ሁነታ ሲነቃ፣ አፈጻጸም ከዚህ ገደብ በላይ በከፍተኛ ሁኔታ ማሽቆልቆል ይጀምራል፣ በመዝገቡ ውስጥ ያለው የውሂብ መጠን ሲጨምር የማስፈጸሚያ ጊዜ ይረዝማል።
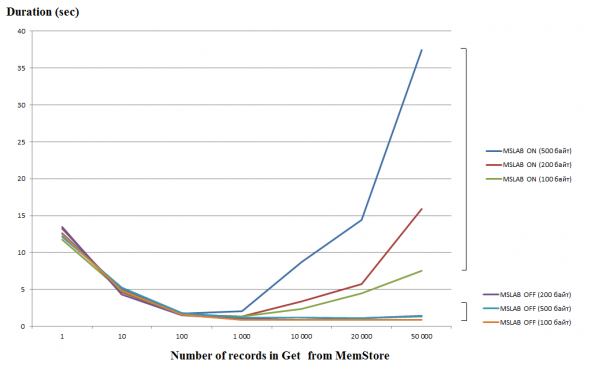
ምርመራዎቹ የተከናወኑት በምናባዊ ማሽን፣ በ8 ኮሮች፣ በHBase ስሪት 2.0.0-cdh6.0.0-beta1 ላይ ነው።
የMSLAB ሁነታ ከአዳዲስ እና ከአሮጌ ትውልዶች ውሂብን በማደባለቅ የሚፈጠረውን የክምር መከፋፈል ለመቀነስ የተነደፈ ነው። ይህንን ችግር ለመፍታት፣ MSLAB ሲነቃ፣ ውሂብ በአንጻራዊ ሁኔታ በትንሽ ቁርጥራጮች ውስጥ ይቀመጣል እና በክፍሎች ይዘጋጃል። በዚህም ምክንያት፣ የተጠየቀው የውሂብ ፓኬት መጠን ከተመደበው መጠን ሲበልጥ አፈፃፀሙ በከፍተኛ ሁኔታ ይቀንሳል። ሆኖም ግን፣ ይህንን ሁነታ ማሰናከል የማይፈለግ ነው፣ ምክንያቱም በከፍተኛ የውሂብ መዳረሻ ጊዜዎች ውስጥ የ GC ማቆሚያዎችን ያስከትላል። ጥሩ መፍትሔ ንቁ ጽሑፎችን በተመለከተ የክንድ መጠኑን ከንባቦች ጋር በተመሳሳይ ጊዜ በማስቀመጥ መጨመር ነው። ይህ ችግር ከጽሑፍ በኋላ የፍሉሽ ትዕዛዝ ከተተገበረ፣ MemStoreን ወደ ዲስክ የሚያፈስስ ከሆነ ወይም በ BulkLoad ጭነት ከተከናወነ እንደማይከሰት ልብ ሊባል ይገባል። ከዚህ በታች ያለው ሰንጠረዥ ከMemStore ለትልቅ (እና ተመሳሳይ) ውሂብ የሚጠየቁ ጥያቄዎች ፍጥነት መቀነስን እንደሚያስከትሉ ያሳያል። ሆኖም፣ የክንድ መጠን መጨመር የሂደቱን ጊዜ ወደ መደበኛው ይመልሳል።
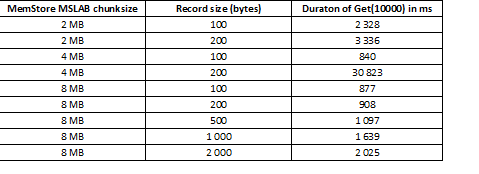
የስብስብ መጠንን ከመጨመር በተጨማሪ፣ ውሂብን በክልል መከፋፈል፣ ማለትም የሠንጠረዥ ክፍፍል፣ ይረዳል። ይህ ማለት ለእያንዳንዱ ክልል የሚላኩ ጥያቄዎች ቁጥር አነስተኛ ነው ማለት ነው፣ እና በአንድ ሕዋስ ውስጥ የሚስማሙ ከሆነ፣ ምላሹ ጥሩ ሆኖ ይቆያል።
6. ሰንጠረዦችን ወደ ክልሎች የመከፋፈል ስትራቴጂ (መፍሰስ)
HBase ቁልፍ እሴት ያለው ማከማቻ ስለሆነ እና ክፍፍል የሚከናወነው በኪይ ስለሆነ፣ ውሂብን በሁሉም ክልሎች በእኩል መጠን መከፋፈል ወሳኝ ነው። ለምሳሌ፣ እንዲህ ዓይነቱን ሰንጠረዥ በሦስት ክፍሎች መከፋፈል መረጃው በሦስት ክልሎች እንዲከፈል ያደርጋል፡
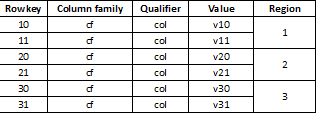
በኋላ ላይ የሚጫነው መረጃ ለምሳሌ በአብዛኛው በተመሳሳይ ቁጥር የሚጀምሩ ረጅም እሴቶች ከሆኑ ይህ አንዳንድ ጊዜ ወደ ከፍተኛ ፍጥነት መቀነስ ሊያመራ ይችላል ለምሳሌ፡
1000001
1000002
...
1100003
ቁልፎቹ እንደ ባይት አደራደር ስለሚቀመጡ፣ ሁሉም በተመሳሳይ መንገድ ይጀምራሉ እና ይህንን የቁልፍ ክልል የሚያከማችው ተመሳሳይ ክልል #1 ይሆናሉ። በርካታ የመከፋፈል ስልቶች አሉ፡
HexStringSplit – አንድን ቁልፍ ወደ "00000000" => "FFFFFFFF" እና በግራ በኩል ዜሮዎች ያሉት ፓዲንግ ባለው ክልል ውስጥ ወደ ሄክሳዴሲማል ኢንኮዲንግ ወዳለው ሕብረቁምፊ ይለውጠዋል።
ዩኒፎርም ስፕሊት - አንድን ቁልፍ በ"00" => "FF" ክልል ውስጥ ሄክሳዴሲማል ኢንኮዲንግ እና በቀኝ በኩል ዜሮዎችን የያዘ ፓዲንግ ወደ ባይት አደራደር ይለውጠዋል።
በተጨማሪም፣ ለመከፋፈል እና ራስ-ሰር ስፕሊቲንግ ለማዋቀር ማንኛውንም ክልል ወይም የቁልፍ ስብስቦችን መግለጽ ይችላሉ። ሆኖም፣ በጣም ቀላሉ እና በጣም ውጤታማ ከሆኑ አቀራረቦች አንዱ UniformSplit እና የሃሽ ኮንካቴኔሽን አጠቃቀም ነው፣ ለምሳሌ ቁልፉን በCRC32(rowkey) ተግባር እና በrowkey ራሱ በኩል ከማስኬድ በጣም ጠቃሚ የሆኑ የባይት ጥንድ፡
ሃሽ + ረድፍ ቁልፍ
ከዚያም ሁሉም መረጃዎች በክልሎች እኩል ይሰራጫሉ። ሲያነቡ የመጀመሪያዎቹ ሁለት ባይቶች በቀላሉ ይጣላሉ፣ የመጀመሪያውን ቁልፍ ይተዋሉ። RS በአንድ ክልል ውስጥ ያለውን የውሂብ እና የቁልፍ መጠን ይከታተላል እና ገደቦቹ ከተሻሉ በራስ-ሰር ወደ ክፍሎች ይከፍለዋል።
7. የስህተት መቻቻል እና የውሂብ አካባቢ
ለእያንዳንዱ የቁልፍ ስብስብ አንድ ክልል ብቻ ተጠያቂ ስለሆነ፣ ከ RS ብልሽቶች ወይም ከስራ ማቆም ጋር ለተያያዙ ችግሮች መፍትሄው ሁሉንም አስፈላጊ መረጃዎች በ HDFS ውስጥ ማከማቸት ነው። RS ሲበላሽ፣ ማስተር ይህንን የሚለየው በ ZooKeeper ኖድ ላይ የልብ ምት ባለመኖሩ ነው። ከዚያም የሚያገለግለውን ክልል ለሌላ RS ይመድባል። HFiles በተከፋፈለ የፋይል ስርዓት ውስጥ ስለሚከማቹ፣ አዲሱ ማስተር ያነባል እና ውሂቡን ማገልገሉን ይቀጥላል። ሆኖም፣ አንዳንድ መረጃዎች በMemStore ውስጥ ሊሆኑ እና እስካሁን ወደ HFiles ስላልተላለፉ፣ WAL፣ እሱም በ HDFS ውስጥ የተከማቸ፣ የአሠራር ታሪክን ወደነበረበት ለመመለስ ይጠቅማል። ለውጦቹ ከተተገበሩ በኋላ፣ RS ለጥያቄዎች ምላሽ መስጠት ይችላል፣ ነገር ግን እንቅስቃሴው አንዳንድ መረጃዎችን እና እሱን የሚያገለግሉ ሂደቶችን በተለያዩ ኖዶች ላይ እንዲገኙ ያደርጋል፣ ይህም አካባቢን ይቀንሳል።
መፍትሄው ዋና መጭመቂያ ነው። ይህ ሂደት ፋይሎችን ለእነሱ ኃላፊነት ወደሆኑት ኖዶች (ክልሎቻቸው በሚገኙባቸው ቦታዎች) ያዛውራል፣ ይህም በዚህ ሂደት ውስጥ የኔትወርክ እና የዲስክ ጭነት በከፍተኛ ሁኔታ እንዲጨምር ያደርጋል። ሆኖም ግን፣ የውሂብ መዳረሻ በኋላ ላይ በከፍተኛ ሁኔታ ፈጣን ነው። በተጨማሪም፣ major_compaction ሁሉንም HFiles በአንድ ክልል ውስጥ ወደ አንድ ፋይል ያዋህዳል እና በሠንጠረዥ ቅንብሮች ላይ በመመስረት ውሂብን ያጸዳል። ለምሳሌ፣ ለማቆየት የሚያስፈልጉትን የነገር ስሪቶች ብዛት ወይም ዕቃው በአካል የሚሰረዝበትን የህይወት ዘመን መግለጽ ይችላሉ።
ይህ አሰራር በHBase አፈጻጸም ላይ በጣም አዎንታዊ ተጽእኖ ሊኖረው ይችላል። ከታች ያለው ምስል በከባድ የውሂብ ፅሁፎች ምክንያት አፈጻጸሙ እንዴት እንደተበላሸ ያሳያል። በአንድ ጠረጴዛ ላይ የሚጽፉ 40 ክሮች እና በተመሳሳይ ጊዜ 40 ክሮች ውሂብን የሚያነቡ ክሮች ያሳያል። የመጻፊያ ክሮች ብዙ እና ብዙ ኤችፋይሎችን ያመነጫሉ፣ ከዚያም በሌሎች ክሮች ይነበባሉ። በዚህም ምክንያት፣ ብዙ እና ብዙ መረጃዎች ከማህደረ ትውስታ መወገድ አለባቸው፣ እና በመጨረሻም፣ GC ይጀምራል፣ ሁሉንም ስራዎች በተግባር ያሽመደምዳል። ዋና መጭመቂያ ማስኬድ የተገኘውን ውድቀት አጽድቶ አፈጻጸሙን ወደነበረበት መልሷል።
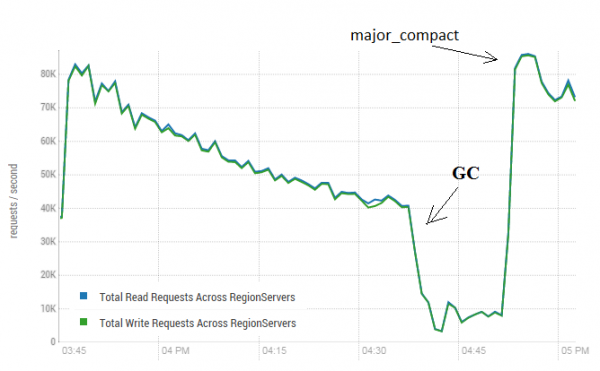
ሙከራው የተካሄደው በ3 DataNodes እና በ4 RSs (Xeon E5-2680 v4 CPU @ 2.40GHz * 64 ክሮች) ላይ ነው። HBase ስሪት 1.2.0-cdh5.14.2
ዋናው መጭመቂያ በቀጥታ ጠረጴዛ ላይ መካሄዱን ልብ ሊባል የሚገባው ሲሆን መረጃን በንቃት እየጻፈ እና እያነበበ ነው። ይህ መረጃ ሲያነቡ የተሳሳቱ ምላሾችን ሊያስከትል እንደሚችል የሚገልጹ ክሶች በመስመር ላይ ነበሩ። ይህንን ለማረጋገጥ አዲስ መረጃ የሚፈጥር እና ወደ ጠረጴዛው የጻፈው ሂደት ተጀምሯል። ከዚያም ወዲያውኑ አነበበው እና የተገኘው እሴት ከተጻፈው እሴት ጋር እንደሚዛመድ አረጋግጧል። በዚህ ሂደት ውስጥ ዋና መጭመቂያ በግምት 200 ጊዜ ተከናውኗል፣ እና አንድም ውድቀት አልተመዘገበም። ችግሩ አልፎ አልፎ የሚከሰት እና በከፍተኛ ጭነት ጊዜ ብቻ ሊሆን ይችላል፣ ስለዚህ እንደዚህ ያሉ የጂሲ ውድቀትን ለመከላከል መፃፍ እና ማንበብን አዘውትሮ ማቆም እና ማጽዳትን ማከናወን የበለጠ አስተማማኝ ነው።
እንዲሁም፣ ዋና መጭመቂያ የMemStoreን ሁኔታ አይጎዳውም፤ ወደ ዲስክ ለማፍሰስ እና ለማጣመር፣ flush (connection.getAdmin().flush(TableName.valueOf(tblName))) መጠቀም ያስፈልግዎታል።
8. ቅንብሮች እና አፈጻጸም
ቀደም ሲል እንደተጠቀሰው፣ HBase ምንም ማድረግ በማይፈልግበት ጊዜ በጣም ስኬታማ ነው - BulkLoad ን ሲያከናውን። ይህ ግን ለአብዛኛዎቹ ስርዓቶች እና ሰዎች ይሠራል። ሆኖም፣ ይህ መሳሪያ በትላልቅ ብሎኮች ውስጥ ለጅምላ ዳታ ለመጫን የበለጠ ተስማሚ ነው፣ ሂደቱ ግን በርካታ የተጓዳኝ የማንበብ እና የመጻፍ ጥያቄዎችን የሚፈልግ ከሆነ፣ ከላይ የተገለጹትን የGet and Put ትዕዛዞችን እንጠቀማለን። በጣም ጥሩውን መለኪያዎች ለመወሰን፣ የተለያዩ የሰንጠረዥ መለኪያዎችን እና ቅንብሮችን በማጣመር ሙከራዎችን አካሂደናል፡
- 10 ክሮች በተከታታይ 3 ጊዜ በአንድ ጊዜ ተጀምረዋል (ይህንን የክር ብሎክ እንበል)።
- በአንድ ብሎክ ውስጥ ያሉ የሁሉም ክሮች የሩጫ ጊዜ በአማካይ የተሰላ ሲሆን የብሎኩ ስራ የመጨረሻ ውጤት ነበር።
- ሁሉም ክሮች በተመሳሳይ ሰንጠረዥ ሠርተዋል።
- ከእያንዳንዱ የክር ብሎክ ሂደት በፊት፣ ዋና መጭመቂያ ተከናውኗል።
- እያንዳንዱ ብሎክ ከሚከተሉት ተግባራት ውስጥ አንዱን ብቻ አከናውኗል፡
— ፑት
- አግኝ
— ጌት+ፕት
- እያንዳንዱ ብሎክ 50,000 የአሠራር ድግግሞሾችን አከናውኗል።
- በአንድ ብሎክ ውስጥ ያለው የመዝገብ መጠን 100 ባይት፣ 1000 ባይት ወይም 10000 ባይት (በዘፈቀደ) ነው።
- ብሎኮቹ የተጀመሩት በተለያዩ የተጠየቁ ቁልፎች (አንድ ቁልፍ ወይም 10) በመጠቀም ነው።
- ብሎኮቹ በተለያዩ የሠንጠረዥ ቅንብሮች ተካሂደዋል። የሚከተሉት መለኪያዎች ተቀይረዋል፡
— BlockCache = ነቅቷል ወይም ተሰናክሏል
— የብሎክሳይዝ መጠን = 65 ኪባ ወይም 16 ኪባ
— ክፍልፋዮች = 1፣ 5 ወይም 30
— MSLAB = አብራ ወይም አጥፋ
ስለዚህ ብሎኩ እንደዚህ ይመስላል:
ሀ. የMSLAB ሁነታ በርቷል/ጠፍቷል።
ለ. የሚከተሉት መለኪያዎች የተቀመጡበት ሰንጠረዥ ተፈጠረ፡ BlockCache = true/none፣ BlockSize = 65/16 Kb፣ Partitions = 1/5/30።
ሐ. የጂዜድ መጭመቂያ ተዘጋጅቷል።
መ. 10 ክሮች በአንድ ጊዜ ተጀምረዋል፤ በዚህ ሠንጠረዥ ውስጥ 100/1000/10000 ባይት መዝገቦችን የያዘ 1/10 የput/get/get+put ስራዎችን በማከናወን፣ 50,000 ጥያቄዎችን በተከታታይ (በዘፈቀደ ቁልፎች) ፈጽመዋል።
ሠ. ነጥብ መ ሦስት ጊዜ ተደግሟል።
ረ. የሁሉም ክሮች የሩጫ ጊዜ በአማካይ ተመድቧል።
ሁሉም ሊሆኑ የሚችሉ ጥምረቶች ተፈትነዋል። የመዝገብ መጠኑን መጨመር አፈጻጸምን እንደሚቀንስ ወይም መሸጎጫ ማሰናከል ወደ ፍጥነት እንደሚቀንስ የሚገመት ነበር። ሆኖም፣ ግቡ የእያንዳንዱን መለኪያ ተጽእኖ ደረጃ እና ጠቀሜታ መረዳት ነበር፣ ስለዚህ የተሰበሰበው መረጃ ወደ መስመራዊ ሪግሬሽን ተግባር እንዲገባ ተደርጓል፣ ይህም የቲ-ስታቲስቲክስን በመጠቀም አስተማማኝነትን ለመገምገም ያስችላል። የፑት ስራዎችን የሚፈጽሙት ብሎኮች ውጤቶች ከዚህ በታች ይታያሉ። የጥምረቶች ሙሉ ስብስብ 2 * 2 * 3 * 2 * 3 = 144 ልዩነቶች + 72 ነው ምክንያቱም አንዳንዶቹ ሁለት ጊዜ ስለተከናወኑ። ስለዚህ፣ በድምሩ 216 ሩጫዎች፡
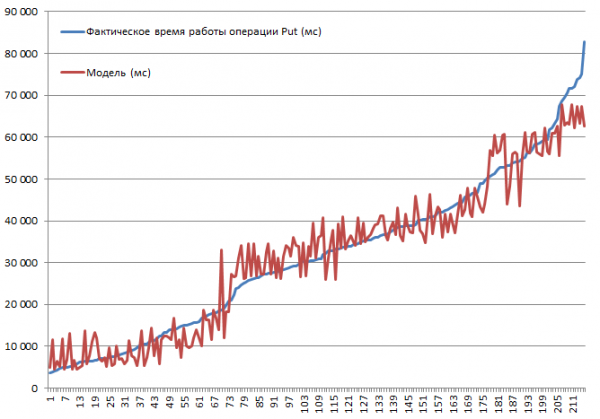
ሙከራው የተካሄደው ሶስት DataNodes እና አራት RSs (Xeon E5-2680 v4 CPUs @ 2.40 GHz * 64 ክሮች) ባካተተ አነስተኛ ክላስተር ላይ ነው። HBase ስሪት 1.2.0-cdh5.14.2።
ከፍተኛው የ3.7 ሰከንድ የማስገባት ፍጥነት የተገኘው MSLAB ሁነታ ሲሰናከል፣ አንድ ክፋይ ባለው ጠረጴዛ ላይ፣ BlockCache ሲነቃ፣ BlockSize = 16፣ እና በ10 ባች ውስጥ 100-ባይት መዝገቦች ያሉት።
ዝቅተኛው የ82.8 ሰከንድ የማስገባት ፍጥነት የተገኘው MSLAB ሁነታን በማብራት ሲሆን፣ አንድ ክፋይ ባለው ጠረጴዛ ላይ፣ BlockCache በርቶ፣ BlockSize = 16፣ 10000-ባይት መዝገቦች ያሉት፣ እያንዳንዳቸው 1 ነው።
አሁን ሞዴሉን እንመልከት። በ R2 ረገድ ጥሩ የሞዴል ጥራት እናያለን፣ ነገር ግን እዚህ ላይ ኤክስትራፖሌሽን የተከለከለ መሆኑ ግልፅ ነው። ትክክለኛው የስርዓት ባህሪ መለኪያዎች ሲቀየሩ መስመራዊ አይሆንም፤ ይህ ሞዴል ለትንበያዎች ሳይሆን በተሰጡት መለኪያዎች ውስጥ ምን እንደተፈጠረ ለመረዳት የሚያስፈልገው ነው። ለምሳሌ፣ እዚህ ከተማሪው ቲ-ሙከራ የBlockSize እና BlockCache መለኪያዎች ለPut ኦፕሬሽን ምንም ፋይዳ እንደሌላቸው እናያለን (ይህም በአጠቃላይ በጣም ሊገመት የሚችል ነው)፡

የክፍፍሎችን ቁጥር መጨመር የአፈጻጸም መቀነስን ያስከትላል የሚለው እውነታ በተወሰነ ደረጃ ያልተጠበቀ ነው (በBulkLoad የክፍፍሎችን ቁጥር መጨመር አወንታዊ ተጽእኖውን ቀደም ብለን አይተናል)፣ ምንም እንኳን ለመረዳት የሚቻል ቢሆንም። በመጀመሪያ፣ ሂደት ከአንድ ይልቅ ወደ 30 ክልሎች ጥያቄዎችን መፍጠርን ይጠይቃል፣ እና የውሂብ መጠን የአፈጻጸም ትርፍ ለማግኘት በቂ አይደለም። በሁለተኛ ደረጃ፣ አጠቃላይ የማስፈጸሚያ ጊዜ የሚወሰነው በጣም በዝግተኛው RS ነው፣ እና የDataNodes ብዛት ከRSs ብዛት ያነሰ ስለሆነ፣ አንዳንድ ክልሎች ዜሮ አካባቢ አላቸው። ከፍተኛዎቹን አምስት እንመልከት፡

አሁን የGet ብሎኮችን የማስፈጸም ውጤቶችን እንገምግም፦

የክፍፍሎች ብዛት ብዙም ጉልህ አልሆነም፣ ምናልባትም መረጃው በደንብ የተሸጎጠ እና የንባብ መሸጎጫ በጣም ጉልህ (በስታቲስቲክስ) መለኪያ ስለሆነ ሊሆን ይችላል። በተፈጥሮ፣ በአንድ ጥያቄ የመልእክቶችን ብዛት መጨመር ለአፈጻጸም በጣም ጠቃሚ ነው። ምርጥ ውጤቶች፡

በመጨረሻም፣ በመጀመሪያ የተከናወነውን የብሎክ ሞዴል እንመልከት get እና ከዚያም አስቀምጧል፡

እዚህ ላይ ሁሉም መለኪያዎች ጉልህ ናቸው። የመሪዎቹም ውጤቶች፡

9. የጭነት ሙከራ
በመጨረሻም፣ በቂ ወይም ያነሰ ጥሩ የሥራ ጫና እናድርግ፣ ነገር ግን ከእሱ ጋር የሚያወዳድሩት ነገር ሲኖርዎት ሁልጊዜ የበለጠ አስደሳች ነው። የካሳንድራ ቁልፍ ገንቢ የሆነው የDataStax ድህረ ገጽ የ HBase ስሪት 0.98.6-1ን ጨምሮ ለብዙ የ NoSQL ማከማቻ ስርዓቶች NT። ጭነት የተከናወነው በ 40 ክሮች፣ 100 ባይት የውሂብ መጠን ያለው፣ በ SSD ድራይቮች በመጠቀም ነው። የ Read-Modify-Write ሙከራ ውጤቶች የሚከተሉትን አሳይተዋል።
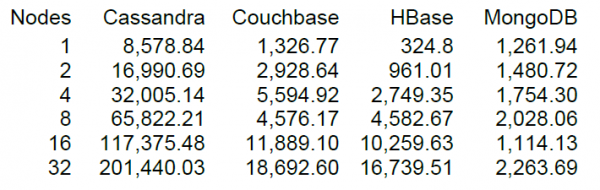
እኔ እስከገባኝ ድረስ፣ ንባብ የተካሄደው በ100 መዝገቦች ብሎኮች ሲሆን፣ ለ16 የHBase ኖዶች ደግሞ የDataStax ሙከራ በሰከንድ 10 ክዋኔዎችን አሳይቷል።
የእኛ ክላስተር 16 ኖዶች መኖራቸው እድለኛ ነው፣ ነገር ግን እያንዳንዳቸው 64 ኮሮች (ክር) ስላሏቸው ብዙም እድለኛ አይደሉም፣ የDataStax ሙከራ 4 ብቻ አለው። በሌላ በኩል፣ የSSD ድራይቮች አሏቸው፣ እኛ ደግሞ HDDዎች እና አዲስ የHBase ስሪት ስላለን፣ በጭነት ስር ያለው የሲፒዩ አጠቃቀም እምብዛም ጨምሯል (በ5-10 በመቶ በግልጽ ይታያል)። ያም ሆኖ፣ ይህንን ውቅር ለማስኬድ እንሞክራለን። የሠንጠረዥ ቅንብሮች ነባሪ ናቸው፡ ንባቦች ከ0 እስከ 50 ሚሊዮን ቁልፎች በዘፈቀደ ይከናወናሉ (ማለትም፣ በመሠረቱ በእያንዳንዱ ጊዜ አዲስ)። ሠንጠረዡ በ64 ክፍሎች የተከፈለ 50 ሚሊዮን መዝገቦችን ይዟል። ቁልፎቹ crc32 በመጠቀም ሃሽ ተደርገዋል። የሰንጠረዡ ቅንብሮች ነባሪ ናቸው፣ እና MSLAB ነቅቷል። 40 ክሮችን እናስጀምራለን፣ እያንዳንዱ ክር 100 የዘፈቀደ ቁልፎችን ያነባል እና ወዲያውኑ ለእነዚህ ቁልፎች 100 የተፈጠሩ ባይቶችን እንጽፋለን።
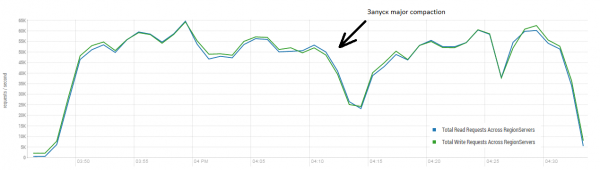
ማቆሚያ፡ 16 ዳታኖድ እና 16 አርኤስ (ሲፒዩ Xeon E5-2680 v4 @ 2.40GHz * 64 ክሮች)። የHBase ስሪት 1.2.0-cdh5.14.2።
አማካይ ውጤቱ በሰከንድ ወደ 40,000 ክዋኔዎች የሚጠጋ ሲሆን ይህም ከDataStax ሙከራ በእጅጉ የተሻለ ነው። ሆኖም ግን፣ ለሙከራ ዓላማዎች፣ ሁኔታዎቹ በትንሹ ሊሻሻሉ ይችላሉ። ሁሉም ስራዎች በአንድ ሠንጠረዥ ብቻ እና በልዩ ቁልፎች ብቻ የሚከናወኑ መሆናቸው በጣም አጠራጣሪ ነው። የጭነቱን ዋና ክፍል የሚያመነጭ "ትኩስ" የቁልፍ ስብስቦች እንዳሉ እናስብ። ስለዚህ፣ ጭነቱን በትላልቅ መዝገቦች (10 ኪባ)፣ እንዲሁም በ100 ቡድኖች፣ ወደ አራት የተለያዩ ሰንጠረዦች ለማመንጨት እንሞክራለን፣ ይህም የተጠየቁትን ቁልፎች ክልል ወደ 50,000 ይገድባል። ከታች ያለው ግራፍ 40 ክሮች እየሰሩ ነው፣ እያንዳንዱ ክር የ100 ቁልፎችን ስብስብ እያነበበ እና ወዲያውኑ የዘፈቀደ 10 ኪባ ወደ እነዚያ ቁልፎች ይጽፋል።
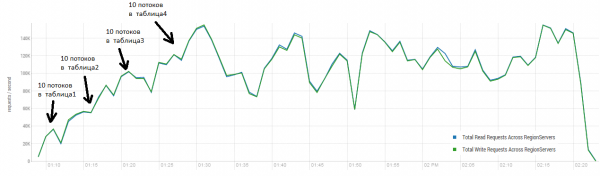
ማቆሚያ፡ 16 ዳታኖድ እና 16 አርኤስ (ሲፒዩ Xeon E5-2680 v4 @ 2.40GHz * 64 ክሮች)። የHBase ስሪት 1.2.0-cdh5.14.2።
በጭነቱ ወቅት፣ ዋና መጭመቂያ ብዙ ጊዜ ተከናውኗል። ከላይ እንደሚታየው፣ ይህ አሰራር ከሌለ አፈፃፀሙ ቀስ በቀስ ይዳከማል። ሆኖም፣ ተጨማሪ ጭነት በአፈፃፀም ወቅትም ተከስቷል። የመውደቅ ክስተቶች በተለያዩ ምክንያቶች ይከሰታሉ። አንዳንድ ጊዜ ክሮች ይቋረጣሉ፣ እንደገና ሲጀምሩ ለአፍታ ይቆማሉ፣ እና አንዳንድ ጊዜ የሶስተኛ ወገን መተግበሪያዎች በክላስተር ላይ ጭነት ፈጥረዋል።
የንባብ እና የመጻፍ ክዋኔዎች ለHBase በጣም ከሚያስፈልጉት የሥራ ጫናዎች አንዱ ናቸው። ትናንሽ የተቀመጠ መጠይቆችን ብቻ መጠቀም፣ ለምሳሌ እያንዳንዳቸው 100 ባይት፣ በ10-50 ቁርጥራጮች የተከፋፈሉ፣ በሰከንድ በመቶ ሺዎች የሚቆጠሩ ክዋኔዎችን ማግኘት ይችላል። ለንባብ ብቻ መጠይቆችም ተመሳሳይ ነው። ውጤቶቹ ከDataStax ጋር ከተገኙት በእጅጉ የተሻሉ መሆናቸውን ልብ ሊባል ይገባል፣ በተለይም በ50-ባይት የመጠይቅ መጠን ምክንያት።
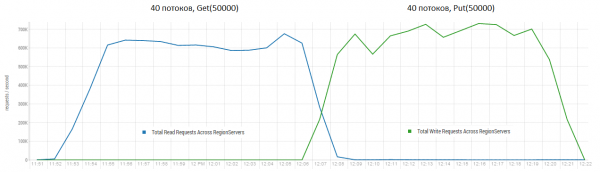
ማቆሚያ፡ 16 ዳታኖድ እና 16 አርኤስ (ሲፒዩ Xeon E5-2680 v4 @ 2.40GHz * 64 ክሮች)። የHBase ስሪት 1.2.0-cdh5.14.2።
10. መደምደሚያ
ይህ ስርዓት በማዋቀር ረገድ በጣም ተለዋዋጭ ነው፣ ነገር ግን የብዙ መለኪያዎች ተጽእኖ አይታወቅም። አንዳንዶቹ ተፈትነዋል ነገር ግን በመጨረሻው የሙከራ ስብስብ ውስጥ አልተካተቱም። ለምሳሌ፣ የመጀመሪያ ሙከራዎች መረጃውን ከጎረቤት ሴሎች እሴቶችን በመጠቀም የሚቀርጸው የDATA_BLOCK_ENCODING መለኪያ ብዙም ጠቀሜታ አላሳዩም፣ ይህም በዘፈቀደ ለሚመነጩ መረጃዎች ለመረዳት የሚቻል ነው። ብዙ ቁጥር ያላቸውን ተደጋጋሚ ነገሮች ሲጠቀሙ፣ ጥቅሞቹ ከፍተኛ ሊሆኑ ይችላሉ። በአጠቃላይ፣ HBase በተለይ ትላልቅ የውሂብ ብሎኮችን ሲይዝ በጣም ውጤታማ ሊሆን የሚችል በጣም ጠንካራ እና በሚገባ የተነደፈ የውሂብ ጎታ ይመስላል።
በበቂ ሁኔታ ያልሸፈንኩት ነገር እንዳለ ከተሰማዎት፣ በዝርዝር ለማብራራት ደስተኛ ነኝ። ተሞክሮዎን እንዲያካፍሉ ወይም ማንኛውንም አለመግባባት እንዲወያዩ እንጋብዝዎታለን።
ምንጭ: hab.com
