

ጥሩ የድሮ ጊዜ ያለው የመደበቅ እና የመፈለግ ጨዋታ ለአርቴፊሻል ኢንተለጀንስ (AI) ቦቶች ውሳኔዎችን እንዴት እንደሚወስኑ እና እርስ በእርስ እና በዙሪያቸው ካሉ የተለያዩ ነገሮች ጋር እንዴት እንደሚገናኙ ለማሳየት ትልቅ ፈተና ሊሆን ይችላል።
በእሱ ውስጥ , በ OpenAI በተመራማሪዎች የታተመ, ለትርፍ ያልተቋቋመ አርቴፊሻል ኢንተለጀንስ ምርምር ድርጅት ታዋቂ ሆኗል ዶታ 2 በተባለው የኮምፒውተር ጨዋታ ላይ፣ ሳይንቲስቶች በአርቴፊሻል ኢንተለጀንስ ቁጥጥር ስር ያሉ ወኪሎች እንዴት በቨርቹዋል አከባቢ ውስጥ መፈለግ እና መደበቅ የበለጠ የተራቀቁ እንዲሆኑ እንዴት እንደሰለጠኑ ይገልጻሉ። የጥናቱ ውጤት እንደሚያሳየው የሁለት ቦቶች ቡድን አጋሮች ከሌሉት ከማንኛውም ወኪል የበለጠ ውጤታማ እና በፍጥነት ይማራል።

የሳይንስ ሊቃውንት ለረጅም ጊዜ ታዋቂነትን ያተረፈውን ዘዴ ተጠቅመዋል , ሰው ሰራሽ የማሰብ ችሎታ በማይታወቅ አካባቢ ውስጥ የሚቀመጥበት ፣ ከእሱ ጋር የተወሰኑ የግንኙነት መንገዶች እና እንዲሁም ለአንድ ወይም ለሌላ የድርጊት ውጤት የሽልማት እና የቅጣት ስርዓት። ይህ ዘዴ አንድ ሰው ሊገምተው ከሚችለው በላይ በሚሊዮን በሚቆጠር ጊዜ በምናባዊ አካባቢ ውስጥ የተለያዩ ድርጊቶችን በከፍተኛ ፍጥነት ለማከናወን በ AI ችሎታ ምክንያት በጣም ውጤታማ ነው። ይህ አንድን ችግር ለመፍታት በጣም ውጤታማ የሆኑ ስልቶችን ለማግኘት ሙከራ እና ስህተት ይፈቅዳል። ግን ይህ አካሄድ አንዳንድ ገደቦችም አሉት ለምሳሌ አካባቢን መፍጠር እና በርካታ የስልጠና ዑደቶችን ማካሄድ ግዙፍ የኮምፒዩተር ግብዓቶችን ይፈልጋል እና ሂደቱ ራሱ የ AI እርምጃዎችን ከግቡ ጋር ለማነፃፀር ትክክለኛ ስርዓት ይጠይቃል። በተጨማሪም, በዚህ መንገድ በተወካዩ የተገኙ ክህሎቶች በተገለፀው ተግባር ላይ ብቻ የተገደቡ ናቸው, እና AI ችግሩን ለመቋቋም እንደተረዳ, ምንም ተጨማሪ ማሻሻያዎች አይኖሩም.
AI ድብብቆሽ እና ፍለጋን እንዲጫወት ለማሰልጠን ሳይንቲስቶች “ያልተመራ ፍለጋ” የሚባል ዘዴ ተጠቅመዋል፣ ይህም ወኪሎች ስለ ጨዋታው ዓለም ያላቸውን ግንዛቤ ለማዳበር እና የአሸናፊነት ስልቶችን ለማዘጋጀት ሙሉ ነፃነት የሚያገኙበት ነው። ይህ በ DeepMind ውስጥ ያሉ ተመራማሪዎች ብዙ ሰው ሰራሽ የማሰብ ዘዴዎችን ሲጠቀሙ ከተጠቀሙበት የባለብዙ ወኪል የመማር አካሄድ ጋር ተመሳሳይ ነው። . በዚህ ጉዳይ ላይ እንደሚታየው የ AI ወኪሎች ቀደም ሲል በጨዋታው ህግ ውስጥ የሰለጠኑ አልነበሩም, ነገር ግን ከጊዜ በኋላ መሰረታዊ ስልቶችን ተምረዋል እና ተመራማሪዎችን ቀላል ባልሆኑ መፍትሄዎች ማስደነቅ ችለዋል.
በድብቅ እና ፍለጋ ጨዋታ በርካታ ኤጀንቶች መደበቅ የነበረባቸው የፈላጊ ኤጀንቶች ቡድን ከእንቅስቃሴ ውጪ በሆነበት ወቅት ትንሽ ጭንቅላት ከጀመረ በኋላ ከተጋጣሚያቸው የእይታ መስመር መራቅ ነበረባቸው። ከዚህም በላይ በዚህ አውድ ውስጥ ያለው "የእይታ መስመር" በግለሰብ ቦት ፊት ለፊት 135 ዲግሪ ሾጣጣ ነው. ወኪሎች ከመጫወቻ ስፍራው ርቀው መሄድ ስላልቻሉ በዘፈቀደ የተፈጠሩ ክፍሎችን ለመዘዋወር የተገደዱ ሲሆን በዙሪያው ተበታትነው የሚገኙትን አንዳንድ ውጫዊ ነገሮች (ሳጥኖች ፣ ተንቀሳቃሽ ግድግዳዎች ፣ ልዩ ራምፕ) ሽፋን ለመፍጠር እና በውስጣቸው ውስጥ ሰርጎ ለመግባት ሊያገለግሉ ይችላሉ ። .
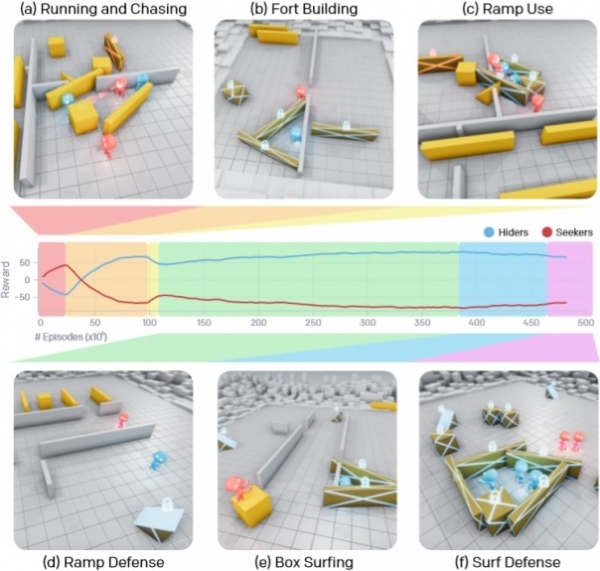
በረዥም የመማር ሂደት፣ የ AI ወኪሎች ስድስት ልዩ ስልቶችን ተምረዋል፣ እያንዳንዱም ወደ ቀጣዩ የጨዋታው ደረጃ እንዲሸጋገሩ ረድቷቸዋል። መጀመሪያ ላይ ጠያቂው እና ሸማቂው ቡድን በቀላሉ ሸሽተው እርስ በርሳቸው ተሳደዱ፣ ነገር ግን ከ25 ሚሊዮን ግጥሚያዎች በኋላ የደብዳቢው ቡድን ምንባቦችን በሳጥን በመዝጋት እና መጠለያ መስራትን ተማረ። ከ 75 ሚሊዮን ግጥሚያዎች በኋላ ቡድኑ ወደ እነዚህ መሸሸጊያ ቦታዎች ለመግባት መንገዶችን አግኝቷል። ከሌላ 10 ሚሊዮን ዙሮች በኋላ አዳሪዎች ተቃዋሚዎች እንዳይጠቀሙባቸው መወጣጫዎችን ወደ መጫወቻ ስፍራው ጫፍ መጎተት እና በቦታቸው መቆለፍን ተምረዋል።

ከ388 ሚሊዮን ግጥሚያዎች በኋላ፣ ፈላጊዎች ወደ እነርሱ በተመጡት ሳጥኖች ላይ ለመውጣት የተከለከሉ መወጣጫዎችን መጠቀምን ተምረዋል፣ ከዚያም በቀጥታ ወደ እነርሱ በመንቀሳቀስ ከተንቀሳቃሽ ግድግዳዎች የተፈጠሩ የጠላት መደበቂያዎችን ዘልቀው ይገባሉ። እና በመጨረሻ ፣ ከ 458 ሚሊዮን ግጥሚያዎች በኋላ ፣ የተደበቀው ቡድን ሁሉንም ዕቃዎች መከልከል እና መጠለያ መገንባት እንዳለበት ድምዳሜ ላይ ደርሷል ፣ ይህም ወደ መጨረሻው ድል አምርቷል ።
በጣም የሚያስደንቀው ግን ከ 22 ሚሊዮን ግጥሚያዎች በኋላ ወኪሎቹ ተግባራቸውን ማስተባበርን ተምረዋል እና የትብብራቸው ቅልጥፍና ወደፊት እየጨመረ መምጣቱ ነው ፣ ለምሳሌ ፣ እያንዳንዱ የራሱን ሳጥን ወይም ግድግዳ በማምጣት መጠለያ ለመፍጠር የራሱን ድርሻ መርጧል ። አግድ ፣ የችግር ጨዋታውን ለተቃዋሚዎች ለማወሳሰብ።

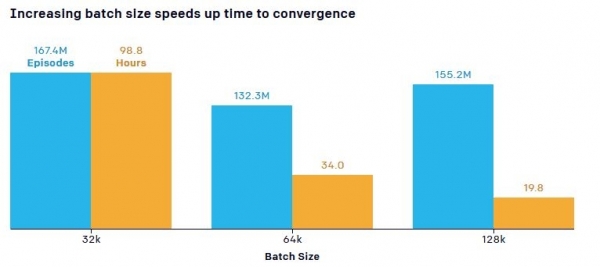
የሳይንስ ሊቃውንት የሥልጠና ዕቃዎች ብዛት (በነርቭ አውታረመረብ ውስጥ የሚያልፍ የመረጃ መጠን - “የባች መጠን”) በትምህርት ፍጥነት ላይ ካለው ተጽዕኖ ጋር የተያያዘ አንድ አስፈላጊ ነጥብ አስተውለዋል። ነባሪው ሞዴል 132,3 ሚሊዮን ግጥሚያዎች ከ34 ሰአታት በላይ ስልጠና የሚያስፈልገው ሲሆን የተደበቁ ቡድኑ ራምፖችን መከልከል የተማረበት ደረጃ ላይ ለመድረስ ሲቻል ተጨማሪ መረጃዎች ግን የስልጠና ጊዜ እንዲቀንስ አድርጓል። ለምሳሌ የመለኪያዎችን ብዛት (በአጠቃላይ የሥልጠና ሂደት የተገኘው መረጃ በከፊል) ከ 0,5 ሚሊዮን ወደ 5,8 ሚሊዮን ማሳደግ የናሙና ምርታማነትን በ2,2 ጊዜ ማሳደግ እና የግብአት መረጃ መጠን ከ64 ኪ.ባ ወደ 128 ኪ.ባ ማሳደግ የሥልጠና ቀንሷል። ጊዜ አንድ ጊዜ ተኩል ማለት ይቻላል.
በስራቸው መጨረሻ ላይ ተመራማሪዎቹ ወኪሎች ከጨዋታው ውጭ ተመሳሳይ ስራዎችን ለመቋቋም ምን ያህል የውስጠ-ጨዋታ ስልጠና እንደሚረዳቸው ለመፈተሽ ወሰኑ. በአጠቃላይ አምስት ፈተናዎች ነበሩ፡ የነገሮች ብዛት ግንዛቤ (አንድ ነገር ከእይታ ውጪ ቢሆንም ጥቅም ላይ ባይውልም ሕልውናውን እንደሚቀጥል መረዳት); "መቆለፍ እና መመለስ" - የአንድን ሰው የመጀመሪያ ቦታ የማስታወስ ችሎታ እና አንዳንድ ተጨማሪ ስራዎችን ካጠናቀቀ በኋላ ወደ እሱ መመለስ; “ተከታታይ ማገድ” - 4 ሳጥኖች በዘፈቀደ በሶስት ክፍሎች ውስጥ በሮች በሌሉበት ተቀምጠዋል ፣ ግን ወደ ውስጥ ለመግባት መወጣጫዎች ፣ ወኪሎች ሁሉንም ማግኘት እና ማገድ አለባቸው ። አስቀድሞ በተወሰኑ ቦታዎች ላይ የሳጥኖች አቀማመጥ; በሲሊንደር መልክ በአንድ ነገር ዙሪያ መጠለያ መፍጠር.
በዚህም ከአምስት ተግባራት ውስጥ በሶስቱ በጨዋታው ላይ የመጀመሪያ ደረጃ ስልጠና የወሰዱ ቦቶች በፍጥነት የተማሩ እና ችግሮችን ከባዶ ለመፍታት ከሰለጠኑት AI የተሻለ ውጤት አሳይተዋል። ስራውን በማጠናቀቅ እና ወደ መጀመሪያው ቦታ በመመለስ ፣የተዘጉ ክፍሎች ውስጥ ሳጥኖችን በቅደም ተከተል በመዝጋት እና በተሰጡ ቦታዎች ላይ ሳጥኖችን በማስቀመጥ በመጠኑ የተሻለ አፈፃፀም አሳይተዋል ፣ነገር ግን የነገሮችን ብዛት በመለየት እና በሌላ ነገር ዙሪያ ሽፋን በመፍጠር ትንሽ ደካማ አፈፃፀም አሳይተዋል።
ተመራማሪዎች የተቀላቀሉ ውጤቶችን AI አንዳንድ ችሎታዎችን እንዴት እንደሚማር እና እንደሚያስታውስ ይገልጻሉ። "የጨዋታው ውስጥ ቅድመ-ስልጠና በተሻለ ሁኔታ የተከናወነባቸው ተግባራት ቀደም ሲል የተማሩትን ችሎታዎች በተለመደው መንገድ እንደገና መጠቀምን የሚያካትት ነው ብለን እናስባለን ፣ የቀሩትን ተግባራት ከባዶ ከሰለጠነው AI በተሻለ ሁኔታ ማከናወን ግን በተለየ መንገድ መጠቀምን ይጠይቃል ብለን እናስባለን ። የበለጠ ከባድ” በማለት የሥራውን ተባባሪዎች ጻፉ። "ይህ ውጤት በስልጠና የተገኙ ክህሎቶችን ከአንድ አካባቢ ወደ ሌላ ሲያስተላልፉ ውጤታማ በሆነ መንገድ እንደገና ጥቅም ላይ ለማዋል የሚረዱ ዘዴዎችን ማዘጋጀት አስፈላጊ መሆኑን ያሳያል."
በዚህ የማስተማር ዘዴ የመጠቀም ዕድሉ ከማንኛውም ጨዋታዎች ገደብ በላይ ስለሆነ የተከናወነው ሥራ በጣም አስደናቂ ነው። ተመራማሪዎቹ ሥራቸው በሽታዎችን ለመመርመር፣ የተወሳሰቡ የፕሮቲን ሞለኪውሎችን አወቃቀሮችን ለመተንበይ እና የሲቲ ስካንን በመተንተን “ፊዚክስን መሰረት ያደረጉ” እና “ሰው መሰል” ባህሪን ለመፍጠር ትልቅ እርምጃ ነው ብለዋል።
ከዚህ በታች ባለው ቪዲዮ ውስጥ አጠቃላይ የመማር ሂደቱ እንዴት እንደተከናወነ ፣ AI እንዴት የቡድን ስራን እንደተማረ እና ስልቶቹ የበለጠ እና የበለጠ ተንኮለኛ እና ውስብስብ እንደሆኑ በግልፅ ማየት ይችላሉ ።

ምንጭ: 3dnews.ru
