

حتى الآن ، لا تحتوي خدمة Bitrix24 على مئات الجيجابت من حركة المرور ، ولا يوجد أسطول ضخم من الخوادم (على الرغم من وجود عدد غير قليل من الخوادم الموجودة بالطبع). ولكن بالنسبة للعديد من العملاء ، فهو الأداة الرئيسية للعمل في الشركة ، وهو تطبيق حقيقي للأعمال التجارية. لذلك ، السقوط ، حسنًا ، مستحيل. ولكن ماذا لو حدث السقوط ، لكن الخدمة "بعثت" بسرعة بحيث لم يلاحظ أحد شيئًا؟ وكيف يمكن تنفيذ تجاوز الفشل دون فقدان جودة العمل وعدد العملاء؟ تحدث ألكسندر ديميدوف ، مدير الخدمات السحابية في Bitrix24 ، في مدونتنا حول كيفية تطور نظام الحجز على مدار 7 سنوات من وجود المنتج.

"في شكل SaaS ، أطلقنا Bitrix24 منذ 7 سنوات. ربما كانت الصعوبة الرئيسية هي التالية: قبل الإطلاق العام في شكل SaaS ، كان هذا المنتج موجودًا ببساطة في شكل حل معبأ. قام العملاء بشرائه منا ، واستضافته على خوادمهم ، وبدأوا بوابة الشركة - حل مشترك لتواصل الموظفين ، وتخزين الملفات ، وإدارة المهام ، وإدارة علاقات العملاء ، هذا كل شيء. وقررنا بحلول عام 2012 أننا نرغب في إطلاقه كخدمة SaaS ، وإدارتها بأنفسنا ، وتوفير القدرة على تحمل الخطأ والموثوقية. اكتسبنا خبرة في هذه العملية ، لأنه حتى ذلك الحين لم نكن نمتلكها ببساطة - كنا مصنعي البرامج فقط ، ولسنا مقدمي الخدمات.
عند إطلاق الخدمة ، أدركنا أن أهم شيء هو ضمان التسامح مع الخطأ والموثوقية والتوافر المستمر للخدمة ، لأنه إذا كان لديك موقع ويب عادي بسيط ، ومتجر ، على سبيل المثال ، ويتعطل ويكذب لمدة ساعة ، أنت وحدك تعاني ، تخسر الطلبات ، تفقد العملاء ، لكن بالنسبة لعميلك نفسه ، هذا ليس بالغ الأهمية بالنسبة له. كان مستاءً بالطبع ، لكنه ذهب واشتري من موقع آخر. وإذا كان هذا تطبيقًا ترتبط به جميع الأعمال داخل الشركة ، والاتصالات ، والحلول ، فالشيء الأكثر أهمية هو كسب ثقة المستخدمين ، أي عدم خذلهم وعدم سقوطهم. لأن كل العمل يمكن أن ينهض إذا لم يعمل شيء بالداخل.
Bitrix.24 مثل SaaS
قمنا بتجميع أول نموذج أولي قبل عام من الإطلاق العام ، في عام 2011. قاموا بتجميعها في حوالي أسبوع ، ونظروا إليها ، ولفوها - حتى أنها كانت تعمل. أي أنه كان من الممكن الدخول في النموذج ، وإدخال اسم البوابة هناك ، وتم نشر بوابة جديدة ، وتم بدء قاعدة مستخدمين. نظرنا إليه ، وقمنا بتقييم المنتج من حيث المبدأ ، وقمنا بإيقاف تشغيله ، ثم صقلناه لمدة عام كامل. نظرًا لأن لدينا مهمة كبيرة: لم نرغب في إنشاء قاعدتين مختلفتين من الكود ، ولم نرغب في دعم منتج مُعبأ منفصل ، وحلول سحابة منفصلة ، وأردنا القيام بكل هذا داخل رمز واحد.
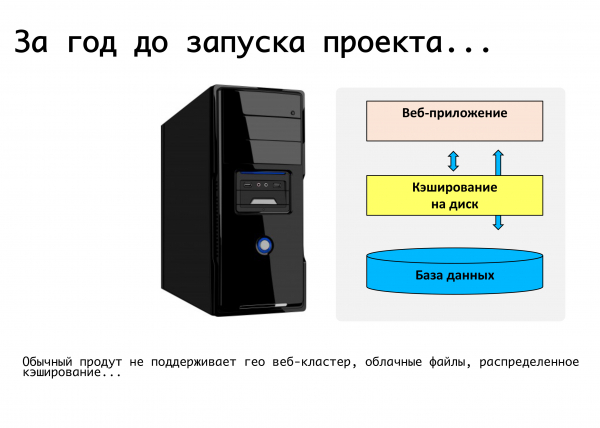
تطبيق الويب النموذجي في ذلك الوقت هو خادم واحد يعمل عليه نوع من أكواد php ، وقاعدة بيانات mysql ، ويتم تحميل الملفات ، ويتم وضع المستندات والصور في مجلد التحميل - حسنًا ، كل هذا يعمل. للأسف ، من المستحيل تشغيل خدمة ويب مستقرة للغاية على هذا. ذاكرة التخزين المؤقت الموزعة غير مدعومة هناك ، ولا يتم دعم النسخ المتماثل لقاعدة البيانات.
لقد قمنا بصياغة المتطلبات: هذه هي القدرة على التواجد في مواقع مختلفة ، ودعم النسخ المتماثل ، بشكل مثالي ، في مراكز بيانات مختلفة موزعة جغرافيًا. افصل بين منطق المنتج ، وفي الواقع ، تخزين البيانات. تكون قادرة ديناميكيًا على القياس وفقًا للحمل ، وإخراج الإحصائيات بشكل عام. من هذه الاعتبارات ، في الواقع ، تم تشكيل متطلبات المنتج ، والتي قمنا بوضع اللمسات الأخيرة عليها لمدة عام فقط. خلال هذا الوقت ، في نظام أساسي اتضح أنه موحد - للحلول المعبأة ، لخدمتنا الخاصة - قدمنا الدعم لتلك الأشياء التي نحتاجها. دعم النسخ المتماثل mysql على مستوى المنتج نفسه: أي أن المطور الذي يكتب الكود لا يفكر في كيفية توزيع طلباته ، فهو يستخدم واجهة برمجة التطبيقات الخاصة بنا ، ويمكننا توزيع طلبات الكتابة والقراءة بشكل صحيح بين الأسياد والعبيد .
لقد قدمنا الدعم على مستوى المنتج للعديد من مخازن الكائنات السحابية: تخزين google ، amazon s3 ، - بالإضافة إلى دعم Open stack swift. لذلك ، كان مناسبًا لنا كخدمة وللمطورين الذين يعملون مع حل معبأ: إذا استخدموا فقط واجهة برمجة التطبيقات الخاصة بنا للعمل ، فلن يفكروا في مكان حفظ الملف في النهاية ، محليًا على نظام الملفات أو الدخول في تخزين ملف الكائن.
نتيجة لذلك ، قررنا على الفور أننا سنقوم بعمل نسخة احتياطية على مستوى مركز البيانات بأكمله. في عام 2012 ، أطلقنا بالكامل على Amazon AWS ، لأننا لدينا بالفعل خبرة مع هذه المنصة - تمت استضافة موقعنا هناك. لقد انجذبنا إلى حقيقة أنه يوجد في كل منطقة في Amazon العديد من مناطق التوفر - في الواقع ، (في مصطلحاتهم) العديد من مراكز البيانات التي تكون مستقلة إلى حد ما عن بعضها البعض وتسمح لنا بالحجز على مستوى البيانات بأكملها المركز: إذا فشل فجأة ، يتم نسخ قواعد البيانات بواسطة السيد الرئيسي ، ويتم حجز خوادم تطبيق الويب ، ويتم نقل الثابت إلى تخزين كائن s3. كان الحمل متوازنًا - في ذلك الوقت من قِبل شركة Amazon ، ولكن بعد ذلك بقليل وصلنا إلى أدوات الموازنة الخاصة بنا ، لأننا كنا بحاجة إلى منطق أكثر تعقيدًا.
حصلوا على ما أرادوه ...
كل الأشياء الأساسية التي أردنا توفيرها - التسامح مع أخطاء الخوادم نفسها ، وتطبيقات الويب ، وقواعد البيانات - كل شيء يعمل بشكل جيد. أبسط سيناريو: إذا فشل أحد تطبيقات الويب ، فسيكون كل شيء بسيطًا - يتم إيقاف تشغيلها من الموازنة.
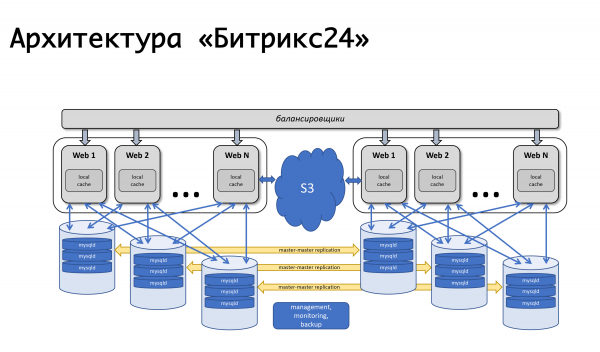
الموازن (ثم كان موقع Amazon's elb) هو الذي ميز الأجهزة الفاشلة بأنها غير صحية ، وأوقف توزيع الحمولة عليها. نجح القياس التلقائي في أمازون: عندما زاد الحمل ، تمت إضافة سيارات جديدة إلى مجموعة القياس التلقائي ، وتم توزيع الحمولة على السيارات الجديدة - كان كل شيء على ما يرام. مع الموازنات الخاصة بنا ، يكون المنطق متماثلًا تقريبًا: إذا حدث شيء ما لخادم التطبيق ، فإننا نزيل الطلبات منه ، ونطرد هذه الأجهزة ، ونبدأ أجهزة جديدة ونواصل العمل. لقد تغير المخطط قليلاً على مر السنين ، لكنه استمر في العمل: إنه بسيط ومفهوم ولا توجد صعوبات في ذلك.
نحن نعمل في جميع أنحاء العالم ، وتختلف ذروة حمولة العملاء تمامًا ، وبطريقة جيدة ، يجب أن نكون قادرين على تنفيذ بعض أعمال الخدمة على أي من مكونات نظامنا في أي وقت - بشكل غير محسوس للعملاء. لذلك ، لدينا الفرصة لإغلاق قاعدة البيانات عن طريق إعادة توزيع الحمل على مركز البيانات الثاني.
كيف يعمل هذا كله؟ - نحول حركة المرور إلى مركز بيانات عامل - إذا كان هذا حادثًا في مركز البيانات ، فعندئذٍ تمامًا ، إذا كان هذا هو عملنا المخطط له مع أي قاعدة بيانات واحدة ، فإننا نحول جزءًا من حركة المرور التي تخدم هؤلاء العملاء إلى مركز البيانات الثاني ، يتم تعليقه النسخ المتماثل. إذا كانت هناك حاجة إلى أجهزة جديدة لتطبيقات الويب ، فمع زيادة الحمل على مركز البيانات الثاني ، ستبدأ تلقائيًا. ننتهي من العمل ، ونستعيد النسخ المتماثل ونعيد التحميل بالكامل مرة أخرى. إذا احتجنا إلى عكس بعض الأعمال في DC الثاني ، على سبيل المثال ، تثبيت تحديثات النظام أو تغيير الإعدادات في قاعدة البيانات الثانية ، فإننا بشكل عام نكرر نفس الشيء ، فقط في الاتجاه الآخر. وإذا كان هذا حادثًا ، فإننا نفعل كل شيء مبتذلاً: نستخدم آلية معالجات الأحداث في نظام المراقبة. إذا نجحت عدة عمليات تحقق بالنسبة لنا وانتقلت الحالة إلى حرج ، فسيتم تشغيل هذا المعالج ، وهو معالج يمكنه تنفيذ هذا المنطق أو ذاك. بالنسبة لكل قاعدة بيانات ، قمنا بكتابة الخادم الذي يعد تجاوز الفشل ، ومكان تبديل حركة المرور إذا لم يكن متاحًا. نحن - كما حدث تاريخيًا - نستخدم ناجيوس أو أي من مفترقاته بشكل أو بآخر. من حيث المبدأ ، توجد آليات مماثلة في أي نظام مراقبة تقريبًا ، ولا نستخدم شيئًا أكثر تعقيدًا حتى الآن ، ولكن ربما في يوم من الأيام سنستخدمه. يتم تشغيل المراقبة الآن بسبب عدم التوفر ولديها القدرة على تبديل شيء ما.
هل حجزنا كل شيء؟
لدينا الكثير من العملاء من الولايات المتحدة الأمريكية والعديد من العملاء من أوروبا والكثير من العملاء الأقرب إلى الشرق - اليابان وسنغافورة وما إلى ذلك. بالطبع نسبة كبيرة من العملاء في روسيا. أي أن العمل بعيد عن منطقة واحدة. يريد المستخدمون استجابة سريعة ، وهناك متطلبات للامتثال للقوانين المحلية المختلفة ، وفي كل منطقة نحتفظ بمركزي بيانات ، بالإضافة إلى وجود بعض الخدمات الإضافية التي ، مرة أخرى ، يتم وضعها بشكل ملائم في منطقة واحدة - للعملاء الموجودين في هذه المنطقة يعملون. معالجات REST ، خوادم التفويض ، هم أقل أهمية لعمل العميل بشكل عام ، يمكنك التبديل بينها بتأخير بسيط مقبول ، لكنك لا تريد إعادة اختراع العجلة ، وكيفية مراقبتها وماذا تفعل بها. لذلك ، نحاول استخدام الحلول الحالية إلى أقصى حد ، وليس تطوير نوع من الكفاءة في منتجات إضافية. وفي مكان ما ، نستخدم التبديل على مستوى نظام أسماء النطاقات ، ويتم تحديد حيوية الخدمة من خلال نفس نظام أسماء النطاقات. تمتلك أمازون خدمة Route 53 ، ولكنها ليست فقط نظام أسماء النطاقات ، حيث يمكنك إنشاء السجلات وهذا كل شيء - إنها أكثر مرونة وملاءمة. من خلاله ، يمكنك إنشاء خدمات موزعة جغرافيًا مع تحديد المواقع الجغرافية ، عند استخدامها لتحديد من أين أتى العميل ومنحه سجلات معينة - يمكنك استخدامها لبناء هياكل تجاوز الفشل. يتم تكوين نفس الفحوصات الصحية في الطريق 53 نفسه ، حيث تقوم بتعيين نقطة النهاية التي تتم مراقبتها ، وتعيين المقاييس ، وتعيين البروتوكولات لتحديد "فعالية" الخدمة - tcp ، http ، https ؛ قم بتعيين تكرار عمليات الفحص التي تحدد ما إذا كانت الخدمة حية أم لا. وفي نظام أسماء النطاقات نفسه ، تصف ما سيكون أساسيًا ، وما سيكون ثانويًا ، ومكان التبديل إذا كان الفحص الصحي يعمل داخل الطريق 53. كل هذا يمكن القيام به باستخدام بعض الأدوات الأخرى ، ولكن الأمر الأكثر ملاءمة هو أننا قمنا بإعداده مرة ثم لا تفكر في الأمر على الإطلاق في كيفية إجراء عمليات التحقق ، وكيفية التبديل: كل شيء يعمل من تلقاء نفسه.
أول "لكن": كيف وكيف تحجز الطريق 53 نفسها؟ أنت لا تعرف أبدًا ، فجأة حدث له شيء ما؟ لحسن الحظ ، لم نتدخل أبدًا في هذا الخليع ، ولكن مرة أخرى ، سيكون أمامي قصة عن سبب اعتقادنا أننا ما زلنا بحاجة إلى التحفظ. هنا نصنع القش لأنفسنا مسبقًا. عدة مرات في اليوم ، نقوم بتفريغ كامل لجميع المناطق التي لدينا على الطريق 53. تسمح لك واجهة برمجة تطبيقات Amazon بإرسالها بسهولة إلى JSON ، ولدينا العديد من خوادم النسخ الاحتياطي حيث نقوم بتحويلها ، وتحميلها في شكل تكوينات ، وبشكل تقريبي ، لدينا تكوين نسخ احتياطي. في هذه الحالة ، يمكننا نشره يدويًا بسرعة دون فقد بيانات إعدادات نظام أسماء النطاقات.
الثانية "لكن": ما الذي لم يتم حجزه بعد في هذه الصورة؟ الموازن! توزيع عملائنا حسب المنطقة بسيط للغاية. لدينا مجالات bitrix24.ru و bitrix24.com و .de - يوجد الآن 13 نطاقًا مختلفًا تعمل في مجموعة متنوعة من المناطق. لقد توصلنا إلى ما يلي: لكل منطقة موازناتها الخاصة. لذلك يكون التوزيع حسب المنطقة أكثر ملاءمة ، اعتمادًا على مكان الحمل الأقصى على الشبكة. إذا كان هذا فشلًا على مستوى أي موازن واحد ، فسيتم ببساطة إيقاف تشغيله وإزالته من نظام أسماء النطاقات. إذا كانت هناك مشكلة مع مجموعة من الموازين ، فيتم حجزها في مواقع أخرى ، ويتم التبديل بينها باستخدام نفس المسار 53 ، لأنه بسبب فترة قصيرة من ttl ، يحدث التبديل في غضون 2 ، 3 ، 5 دقائق كحد أقصى.
الثالثة "لكن": ما الذي لم يتم حجزه بعد؟ S3 صحيح. نحن ، وضعنا الملفات التي نخزنها مع المستخدمين في s3 ، نعتقد بصدق أنها كانت خارقة للدروع ولم تكن هناك حاجة لحجز أي شيء هناك. لكن التاريخ يظهر أن الأشياء مختلفة. بشكل عام ، تصف Amazon S3 بأنها خدمة أساسية ، لأن Amazon نفسها تستخدم S3 لتخزين صور الماكينة ، والتكوينات ، وصور AMI ، واللقطات ... وإذا سقطت s3 ، كما حدث مرة واحدة في هذه السنوات السبع ، فما مقدار bitrix7 الذي كنا عليه عند التشغيل ، سيتم إخراج مجموعة من كل شيء - عدم إمكانية الوصول إلى بداية الأجهزة الافتراضية ، وفشل واجهة برمجة التطبيقات ، وما إلى ذلك.
ويمكن أن تسقط S3 - لقد حدث ذلك مرة واحدة. لذلك ، توصلنا إلى المخطط التالي: قبل بضع سنوات لم يكن هناك مستودعات عامة للأشياء الجادة في روسيا ، وفكرنا في خيار القيام بشيء خاص بنا ... لحسن الحظ ، لم نبدأ في القيام بذلك ، لأننا كان لدينا في الخبرة التي ليست لدينا ، وربما نكون قد أفسدناها. الآن لدى Mail.ru مساحة تخزين متوافقة مع s3 ، ولديها Yandex ، ولديها عدد من المزودين الآخرين. توصلنا في النهاية إلى استنتاج مفاده أننا نريد ، أولاً ، التكرار ، وثانيًا ، القدرة على العمل مع النسخ المحلية. بالنسبة لمنطقة روسية معينة ، نستخدم خدمة Mail.ru Hotbox ، وهي متوافقة مع واجهة برمجة التطبيقات (API) مع s3. لم نكن بحاجة إلى أي تحسينات جادة على الكود داخل التطبيق ، وقمنا بعمل الآلية التالية: s3 لديه مشغلات تعمل على إنشاء / حذف كائنات ، أما Amazon لديها خدمة مثل Lambda - هذا هو إطلاق كود بدون خادم سيتم تنفيذه فقط عندما يتم تشغيل بعض المشغلات.
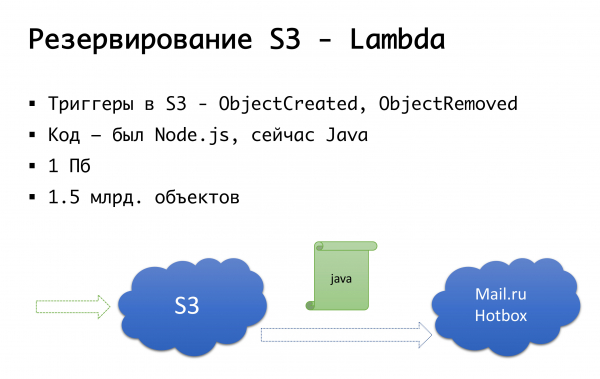
لقد جعلنا الأمر بسيطًا للغاية: إذا كان المشغل يعمل لدينا ، فإننا ننفذ الكود الذي سينسخ الكائن إلى مساحة تخزين Mail.ru. لبدء العمل بشكل كامل مع النسخ المحلية من البيانات ، نحتاج أيضًا إلى مزامنة عكسية حتى يتمكن العملاء الموجودون في الجزء الروسي من العمل باستخدام وحدة تخزين أقرب إليهم. البريد على وشك إكمال المشغلات في مستودع التخزين الخاص به - سيكون من الممكن إجراء مزامنة عكسية على مستوى البنية التحتية ، ولكن في الوقت الحالي نقوم بذلك على مستوى الكود الخاص بنا. إذا رأينا أن العميل قد وضع بعض الملفات ، فإننا نضع الحدث في قائمة الانتظار على مستوى الكود ، ونعالجها ونقوم بالنسخ العكسي. لماذا يعد أمرًا سيئًا: إذا كان لدينا نوع من العمل مع كائناتنا خارج منتجنا ، أي من خلال بعض الوسائل الخارجية ، فلن نأخذ ذلك في الاعتبار. لذلك ، ننتظر حتى النهاية ، عندما يكون هناك مشغلات على مستوى التخزين ، بحيث بغض النظر عن المكان الذي نفذنا فيه الكود ، يتم نسخ الكائن الذي وصل إلينا إلى الجانب الآخر.
على مستوى الكود ، لدينا كلا المستودعات لكل عميل: أحدهما يعتبر الرئيسي والآخر هو النسخ الاحتياطي. إذا كان كل شيء جيدًا ، فنحن نعمل مع التخزين الأقرب إلينا: أي ، عملائنا المتواجدين في Amazon ، ويعملون مع S3 ، وأولئك الذين يعملون في روسيا ، يعملون مع Hotbox. إذا تم تشغيل العلم ، فيجب أن يتم توصيل تجاوز الفشل بنا ، ونقوم بتحويل العملاء إلى وحدة تخزين أخرى. يمكننا ضبط هذه العلامة بشكل مستقل حسب المنطقة ويمكننا تبديلها ذهابًا وإيابًا. من الناحية العملية ، لم يتم استخدام هذا بعد ، ولكن تم توفير هذه الآلية ونعتقد أننا في يوم من الأيام سنحتاج إلى هذا التبديل ذاته ونكون في متناول اليد. لقد حدث بالفعل مرة واحدة.
أوه ، وهرب أمازون الخاص بك ...
يصادف شهر أبريل من هذا العام الذكرى السنوية لبدء حظر Telegram في روسيا. الموفر الأكثر تأثراً بهذا هو أمازون. ولسوء الحظ ، عانت الشركات الروسية التي عملت من أجل العالم كله أكثر.
إذا كانت الشركة عالمية وكانت روسيا شريحة صغيرة جدًا بالنسبة لها ، 3-5٪ - حسنًا ، بطريقة أو بأخرى ، يمكنك التبرع بها.
إذا كانت هذه شركة روسية بحتة - أنا متأكد من أنها بحاجة إلى استضافتها محليًا - حسنًا ، ستكون ببساطة مريحة للمستخدمين أنفسهم ، وستكون هناك مخاطر أقل.
ولكن ماذا لو كانت هذه شركة تعمل على مستوى العالم ، ولديها تقريبًا عدد متساوٍ من العملاء من روسيا ومن مكان ما حول العالم؟ يعد اتصال المقاطع أمرًا مهمًا ، ويجب أن تعمل مع بعضها بطريقة أو بأخرى.
في أواخر مارس 2018، أرسلت هيئة روسكومنادزور خطابًا إلى أكبر شركات الاتصالات تُعلمهم فيه بخططها لحجب ملايين عناوين IP التابعة لشركة أمازون بهدف حجب تطبيق المراسلة زيلو. وبفضل هؤلاء المزودين أنفسهم، تم تسريب الخطاب بنجاح إلى الجميع، وأصبح من الواضح أن الاتصال بأمازون مُهدد بالانهيار. في ذلك اليوم، يوم الجمعة، هرعنا مذعورين إلى زملائنا في servers.ru، قائلين: "أصدقاؤنا، نحتاج إلى عدة خوادم خارج روسيا، وليس في مقر أمازون، بل في مكان ما في أمستردام مثلاً"، حتى نتمكن على الأقل من إنشاء خوادمنا الخاصة هناك. VPN ولدينا خوادم وسيطة لبعض نقاط النهاية التي لا نملك السيطرة عليها، مثل نقاط نهاية S3 - لا يمكننا محاولة إعداد خدمة جديدة والحصول على عنوان IP مختلف؛ ما زلنا بحاجة إلى الوصول إليها. في غضون أيام قليلة، قمنا بتكوين هذه الخوادم وتشغيلها، وكنا مستعدين لبدء الحظر. ومن المثير للاهتمام أن هيئة روسكومنادزور، بعد أن رأت الضجة والذعر، قالت: "لا، نحن لا نحظر أي شيء الآن". (لكن هذا كان صحيحًا حتى اللحظة التي بدأوا فيها حظر تيليجرام). بعد إعداد خيارات التجاوز وإدراكنا أن الحظر لم يُفعّل، قررنا مع ذلك عدم التحقيق في الأمر برمته. تحسبًا لأي طارئ.

وفي عام 2019 ، ما زلنا نعيش في ظروف الحجب. نظرت الليلة الماضية: استمر حظر حوالي مليون عنوان IP. صحيح ، تم إلغاء حظر أمازون بالكامل تقريبًا ، فقد وصل في ذروته إلى 20 مليون عنوان ... بشكل عام ، الحقيقة هي أنه قد لا يكون هناك اتصال ، اتصال جيد. فجأة. قد لا يكون لأسباب فنية - حرائق ، حفارات ، كل ذلك. أو ، كما رأينا ، ليس تقنيًا تمامًا. لذلك ، يمكن لشخص كبير وكبير ، مع AS الخاصة به ، أن يوجهها على الأرجح بطرق أخرى - الاتصال المباشر والأشياء الأخرى موجودة بالفعل في المستوى l2. ولكن في إصدار بسيط ، مثلنا أو حتى أصغر ، فقط في حالة ، يمكنك الحصول على التكرار على مستوى الخوادم التي تم رفعها في مكان آخر ، والتي تم تكوينها مسبقًا vpn ، الوكيل ، مع القدرة على تبديل التكوين إليها بسرعة في تلك المقاطع التي هي حاسمة من حيث الاتصال. لقد كان هذا مفيدًا لنا أكثر من مرة عندما بدأت عمليات حظر Amazon ، فقد سمحنا لحركة مرور S3 بالمرور عبرها في أسوأ الحالات ، ولكن تدريجيًا انهار كل شيء.
وكيف تحجز ... مزود كامل؟
في الوقت الحالي ، ليس لدينا سيناريو لفشل منطقة الأمازون بأكملها. لدينا سيناريو مشابه لروسيا. في روسيا ، تمت استضافتنا من قبل مزود واحد ، وقد اخترنا أن يكون لدينا عدة مواقع. قبل عام ، واجهتنا مشكلة: على الرغم من وجود مركزي بيانات ، فقد تكون هناك بالفعل مشاكل على مستوى تكوين شبكة المزود والتي ستؤثر على مركزي البيانات على أي حال. ويمكننا الحصول على عدم التوفر على كلا الموقعين. بالطبع هذا ما حدث. قمنا في النهاية بمراجعة الهيكل الداخلي. لم يتغير الأمر كثيرًا ، لكن بالنسبة لروسيا لدينا الآن موقعان ، ليسا من مزود واحد ، ولكن من موقعين مختلفين. إذا فشل أحدهما ، فيمكننا التبديل إلى الآخر.
افتراضيًا ، بالنسبة إلى Amazon ، نحن ندرس إمكانية الحجز على مستوى مزود آخر ؛ ربما Google ، وربما شخصًا آخر ... ولكن حتى الآن لاحظنا عمليًا أنه إذا تعطلت Amazon على مستوى منطقة توافر واحدة ، فإن الأعطال على مستوى منطقة بأكملها نادرة جدًا. لذلك ، لدينا فكرة نظريًا أننا قد نجري حجزًا على أمازون وليس أمازون ، ولكن من الناحية العملية لا يوجد شيء من هذا القبيل حتى الآن.
بضع كلمات عن الأتمتة
هل الأتمتة مطلوبة دائمًا؟ من المناسب هنا استدعاء تأثير Dunning-Kruger. على المحور السيني توجد معرفتنا وخبرتنا التي نكتسبها ، وعلى المحور الصادي توجد الثقة في أفعالنا. في البداية لا نعرف أي شيء ولسنا متأكدين على الإطلاق. ثم نعرف القليل ونصبح واثقين للغاية - وهذا ما يسمى "ذروة الغباء" ، ويتضح ذلك جيدًا من خلال صورة "الخرف والشجاعة". ثم تعلمنا القليل بالفعل ونحن على استعداد لخوض المعركة. ثم نخطو على نوع من أشعل النار العملاقة ، نسقط في وادي اليأس ، عندما يبدو أننا نعرف شيئًا ما ، لكننا في الحقيقة لا نعرف الكثير. ثم ، عندما نكتسب الخبرة ، نصبح أكثر ثقة.
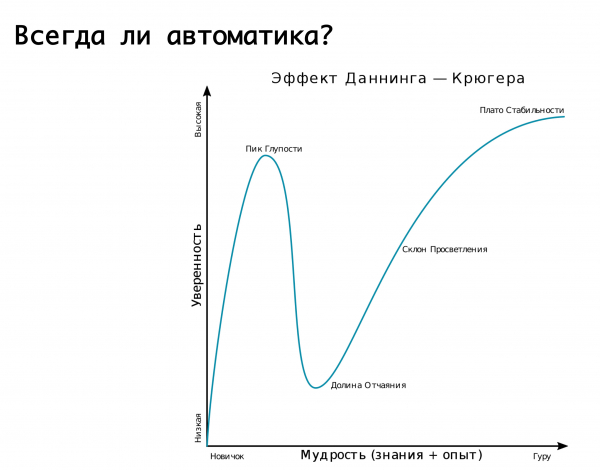
إن منطقنا حول التحول التلقائي المتنوع لحوادث معينة موصوف جيدًا في هذا الرسم البياني. بدأنا - لم نكن نعرف كيف تم إنجاز كل العمل تقريبًا يدويًا. ثم أدركنا أنه يمكنك وضع الأوتوماتيكية على كل شيء والنوم بهدوء ، مثل. وفجأة نخطو على أشعل النار: إيجابية كاذبة تعمل لصالحنا ، ونغير حركة المرور ذهابًا وإيابًا عندما ، بطريقة جيدة ، لم يكن علينا القيام بذلك. وبالتالي ، فإن التكرار ينكسر أو أي شيء آخر - هذا هو وادي اليأس ذاته. ثم توصلنا إلى أن كل شيء يجب أن يعامل بحكمة. بمعنى ، من المنطقي الاعتماد على الأتمتة ، مما يوفر إمكانية الإيجابيات الخاطئة. لكن! إذا كانت العواقب وخيمة ، فمن الأفضل تركها تحت رحمة نوبة العمل ، ومهندسي الواجب ، الذين سيتأكدون من أنه حادث بالفعل ، وسيتم تنفيذ الإجراءات اللازمة يدويًا ...
اختتام
لمدة 7 سنوات ، انتقلنا من حقيقة أنه عندما يسقط شيء ما ، كان هناك حالة من الذعر ، إلى إدراك أنه لا توجد مشاكل ، هناك مهام فقط ، يجب حلها - ويمكن - حلها. عندما تقوم ببناء خدمة ، انظر إليها من الأعلى ، وقم بتقييم جميع المخاطر التي يمكن أن تحدث. إذا رأيتهم على الفور ، فخطط مقدمًا للتكرار وإمكانية بناء بنية تحتية تتسامح مع الأخطاء ، لأن أي نقطة يمكن أن تفشل وتؤدي إلى عدم تشغيل الخدمة ستفعل ذلك بالتأكيد. وحتى لو بدا لك أن بعض عناصر البنية التحتية لن تفشل بالتأكيد - مثل نفس عنصر S3 ، فلا يزال عليك تذكر أنها تستطيع ذلك. وعلى الأقل من الناحية النظرية ، لديك فكرة عما ستفعله بهم إذا حدث شيء ما. لديك خطة لإدارة المخاطر. عندما تفكر فيما إذا كنت ستفعل كل شيء تلقائيًا أو يدويًا ، قم بتقييم المخاطر: ماذا سيحدث إذا بدأت الأتمتة في تبديل كل شيء - ألن تؤدي إلى صورة أسوأ مقارنة بالحادث؟ ربما تحتاج في مكان ما إلى استخدام حل وسط معقول بين استخدام الأتمتة ورد فعل المهندس المناوب ، الذي سيقيم الصورة الحقيقية ويفهم ما إذا كان هناك شيء يحتاج إلى التبديل أثناء التنقل أو "نعم ، ولكن ليس الآن".
حل وسط معقول بين الكمالية والقوى الحقيقية ، الوقت ، المال الذي يمكنك إنفاقه على المخطط الذي ستحصل عليه في النهاية.
هذا النص هو نسخة مكملة وموسعة من تقرير الكسندر ديميدوف في المؤتمر .
المصدر: www.habr.com
