

مرحبا خابروفيتس. تقليديًا ، نواصل مشاركة المواد الممتعة عشية بدء الدورات الجديدة. اليوم ، خاصة بالنسبة لك ، قمنا بترجمة مقال حول Google Cloud Spanner ، تم توقيته ليتزامن مع إطلاق الدورة .

نُشرت في الأصل في .
بصفتها شركة تقدم مجموعة متنوعة من حلول نقاط البيع المستندة إلى مجموعة النظراء لتجار التجزئة والمطاعم والتجار عبر الإنترنت في جميع أنحاء العالم ، تستخدم Lightspeed عدة أنواع مختلفة من منصات قواعد البيانات لمجموعة متنوعة من المعاملات والتحليلات وحالات استخدام البحث. تتمتع كل من منصات قواعد البيانات هذه بنقاط القوة والضعف الخاصة بها. لذلك ، عندما قدمت Google Cloud Spanner إلى السوق - ميزات واعدة لم نشهدها في عالم قواعد البيانات العلائقية ، مثل قابلية التوسع الأفقي غير المحدودة تقريبًا واتفاقية مستوى الخدمة (SLA) بنسبة 99,999٪ ، لم نتمكن من تفويت الفرصة لجعلها بين أيدينا!
لإعطاء نظرة عامة شاملة عن تجربتنا مع Cloud Spanner ، بالإضافة إلى معايير التقييم التي استخدمناها ، سنغطي الموضوعات التالية:
- معايير التقييم لدينا
- سحابة Spanner في باختصار
- تقييمنا
- النتائج التي توصلنا إليها

1. معايير التقييم لدينا
قبل التعمق في تفاصيل Cloud Spanner وأوجه التشابه والاختلاف بينها وبين الحلول الأخرى في السوق ، دعنا نتحدث أولاً عن حالات الاستخدام الرئيسية التي وضعناها في الاعتبار عند التفكير في مكان نشر Cloud Spanner في بنيتنا التحتية:
- كبديل لحل قاعدة بيانات SQL التقليدية (السائدة)
- كحل OLTP يدعم OLAP
ملاحظة: لسهولة المقارنة ، تقارن هذه المقالة Cloud Spanner بمتغيرات MySQL لمجموعات حلول GCP Cloud SQL و Amazon AWS RDS.
استخدام Cloud Spanner كبديل لحل قاعدة بيانات SQL التقليدية
في البيئة تقليدي قواعد البيانات ، عندما يقترب وقت الاستجابة لاستعلام قاعدة البيانات أو حتى يتجاوز حدود التطبيق المحددة مسبقًا (ويرجع ذلك أساسًا إلى زيادة عدد المستخدمين و / أو الطلبات) ، فهناك عدة طرق لتقليل وقت الاستجابة إلى المستويات المقبولة. ومع ذلك ، فإن معظم هذه الحلول تنطوي على تدخل يدوي.
على سبيل المثال ، الخطوة الأولى التي يجب اتخاذها هي إلقاء نظرة على إعدادات قاعدة البيانات المختلفة المتعلقة بالأداء وضبطها لتتناسب بشكل أفضل مع أنماط سيناريو استخدام التطبيق. إذا لم يكن ذلك كافيًا ، يمكنك اختيار مقياس قاعدة البيانات رأسيًا أو أفقيًا.
يستلزم توسيع نطاق التطبيق تحديث مثيل الخادم ، عادةً عن طريق إضافة المزيد من المعالجات / المراكز ، والمزيد من ذاكرة الوصول العشوائي ، وتخزين أسرع ، وما إلى ذلك. تؤدي إضافة المزيد من موارد الأجهزة إلى زيادة أداء قاعدة البيانات ، والتي تُقاس أساسًا بالمعاملات في الثانية ، وزمن انتقال المعاملات لأنظمة OLTP. أنظمة قواعد البيانات العلائقية (التي تستخدم نهجًا متعدد الخيوط) مثل مقياس MySQL عموديًا جيدًا.
هناك العديد من العيوب في هذا النهج ، ولكن الأكثر وضوحًا هو الحجم الأقصى للخادم في السوق. بمجرد الوصول إلى أكبر حد لمثيل الخادم ، لا يتبقى سوى مسار واحد: تغيير الحجم.
التدرج هو نهج يضيف المزيد من الخوادم إلى نظام المجموعة لزيادة الأداء بشكل مثالي خطيًا مع إضافة المزيد من الخوادم. غالبية تقليدي أنظمة قواعد البيانات لا تتسع بشكل جيد أو لا تتسع على الإطلاق. على سبيل المثال ، يمكن لـ MySQL توسيع نطاق عمليات القراءة عن طريق إضافة أجهزة قراءة تابعة ، ولكن لا يمكن توسيع نطاقها لعمليات الكتابة.
من ناحية أخرى ، نظرًا لطبيعتها ، يمكن لـ Cloud Spanner التوسع أفقيًا بسهولة بأقل قدر من التدخل.
كامل المواصفات نظم إدارة قواعد البيانات كخدمة يجب تقييمها من وجهات نظر مختلفة. كأساس ، أخذنا DBMS الأكثر شيوعًا في السحابة - لـ Google و GCP Cloud SQL و Amazon و AWS RDS. ركزنا في تقييمنا على الفئات التالية:
- تعيين الميزات: مدى SQL ، DDL ، DML ؛ مكتبات الاتصال / الموصلات ، ودعم المعاملات ، وما إلى ذلك.
- دعم التطوير: سهولة التطوير والاختبار.
- الدعم الإداري: إدارة المثيلات مثل توسيع نطاق / تقليلها وترقية المثيلات ؛ اتفاقية مستوى الخدمة والنسخ الاحتياطي والاسترداد ؛ الأمن / التحكم في الوصول.
استخدام Cloud Spanner كحل OLTP ممكّن لـ OLAP
على الرغم من أن Google لا تنص صراحة على أن Cloud Spanner مخصصة للتحليلات ، إلا أنها تشارك بعض السمات مع محركات أخرى مثل Apache Impala & Kudu و YugaByte المصممة لأحمال عمل OLAP.
حتى إذا كانت هناك فرصة ضئيلة فقط أن تتضمن Cloud Spanner محرك HTAP (معاملات هجينة / معالجة تحليلية) متسقة النطاق مع مجموعة ميزات OLAP قابلة للاستخدام (أكثر أو أقل) ، نعتقد أنها تستحق اهتمامنا.
مع وضع ذلك في الاعتبار ، نظرنا إلى الفئات التالية:
- تحميل البيانات والفهارس ودعم التقسيم
- أداء الاستعلام و DML
2. سحابة البراغي في باختصار
Google Spanner هو نظام إدارة قواعد بيانات ارتباطية مجمعة (RDBMS) تستخدمه Google للعديد من خدماتها الخاصة. أتاحتها Google بشكل عام لمستخدمي Google Cloud Platform في أوائل عام 2017.
فيما يلي بعض سمات Cloud Spanner:
- مجموعة RDBMS متسقة للغاية وقابلة للتطوير: تستخدم مزامنة وقت الأجهزة لضمان اتساق البيانات.
- دعم المعاملات عبر الجداول: يمكن أن تمتد المعاملات إلى جداول متعددة - لا تقتصر بالضرورة على جدول واحد (على عكس Apache HBase أو Apache Kudu).
- الجداول القائمة على المفتاح الأساسي: يجب أن تحتوي جميع الجداول على مفتاح أساسي مُعلن (كمبيوتر شخصي) ، والذي يمكن أن يتكون من أعمدة جدول متعددة. يتم تخزين البيانات المجدولة بترتيب جهاز الكمبيوتر ، مما يجعلها فعالة للغاية وسريعة لعمليات البحث على أجهزة الكمبيوتر. كما هو الحال مع الأنظمة الأخرى المستندة إلى الكمبيوتر الشخصي ، يجب أن يكون التنفيذ على غرار حالات الاستخدام المسبق من أجل تحقيقه .
- الجداول المخططة: يمكن أن تحتوي الجداول على تبعيات مادية على بعضها البعض. يمكن مطابقة صفوف الجدول الفرعي مع صفوف الجدول الأصل. يعمل هذا النهج على تسريع البحث عن العلاقات التي يمكن تحديدها في مرحلة نمذجة البيانات ، على سبيل المثال ، عند وضع العملاء وفواتيرهم معًا.
- الفهارس: يدعم Cloud Spanner الفهارس الثانوية. يتكون الفهرس من أعمدة مفهرسة وجميع أعمدة الكمبيوتر. اختياريًا ، يمكن للفهرس أن يحتوي أيضًا على أعمدة أخرى غير مفهرسة. يمكن أن يكون الفهرس معشقًا مع الجدول الأصلي لتسريع الاستعلامات. يتم تطبيق العديد من القيود على الفهارس ، مثل الحد الأقصى لعدد الأعمدة الإضافية التي يمكن تخزينها في فهرس. أيضًا ، قد لا تكون الاستعلامات من خلال الفهارس مباشرة كما هو الحال في RDBMS الأخرى.
"يحدد Cloud Spanner فهرسًا تلقائيًا في حالات نادرة فقط. على وجه الخصوص ، لا تحدد Cloud Spanner تلقائيًا فهرسًا ثانويًا إذا طلب الاستعلام أي أعمدة غير مخزنة فيها ".
- اتفاقية مستوى الخدمة (SLA): نشر منطقة واحدة مع 99,99٪ SLA ؛ عمليات نشر متعددة المناطق بنسبة 99,999٪ طبقًا لاتفاقية مستوى الخدمة. في حين أن اتفاقية مستوى الخدمة نفسها هي مجرد اتفاقية وليست ضمانًا من أي نوع ، أعتقد أن الأشخاص في Google لديهم بعض البيانات الصعبة لتقديم مثل هذا الادعاء القوي. (كمرجع ، تعني نسبة 99,999٪ 26,3 ثانية من وقت تعطل الخدمة شهريًا.)
- أكثر من ذلك:
ملاحظة: يضيف مشروع Apache Tephra دعمًا متقدمًا للمعاملات إلى Apache HBase (تم تطبيقه الآن أيضًا في Apache Phoenix كإصدار تجريبي).
3. تقييمنا
لذلك ، قرأنا جميعًا بيانات Google حول فوائد Cloud Spanner - التدرج الأفقي غير المحدود تقريبًا مع الحفاظ على الاتساق العالي واتفاقية مستوى الخدمة العالية جدًا. على الرغم من صعوبة تحقيق هذه الادعاءات ، على أي حال ، إلا أن هدفنا لم يكن دحضها. بدلاً من ذلك ، دعنا نركز على الأشياء الأخرى التي يهتم بها معظم مستخدمي قاعدة البيانات: التكافؤ وسهولة الاستخدام.
قمنا بتقييم Cloud Spanner كبديل لـ Sharded MySQL
تحتوي كل من Google Cloud SQL و Amazon AWS RDS ، وهما من أكثر قواعد بيانات OLTP شيوعًا في السوق السحابية ، على مجموعة ميزات كبيرة جدًا. ومع ذلك ، من أجل توسيع نطاق قواعد البيانات هذه بما يتجاوز حجم عقدة واحدة ، تحتاج إلى إجراء تقسيم التطبيق. يخلق هذا النهج تعقيدًا إضافيًا لكل من التطبيقات والإدارة. نظرنا في كيفية تناسب Spanner مع سيناريو الجمع بين عدة شظايا في حالة واحدة وما هي الميزات (إن وجدت) التي يجب التضحية بها.
دعم لـ SQL و DML و DDL ، بالإضافة إلى الموصل والمكتبات؟
أولاً ، عند البدء بأي قاعدة بيانات ، تحتاج إلى إنشاء نموذج بيانات. إذا كنت تعتقد أنه يمكنك توصيل JDBC Spanner بأداة SQL المفضلة لديك ، فستجد أنه يمكنك الاستعلام عن بياناتك بها ، ولكن لا يمكنك استخدامها لإنشاء جدول أو تحديث (DDL) أو أي إدراج / تحديث / حذف عمليات (DML). لا تدعم JDBC الرسمية من Google أيضًا.
"لا تدعم برامج التشغيل حاليًا عبارات DML أو DDL."
توثيق المفك
الوضع ليس أفضل مع وحدة تحكم GCP - يمكنك فقط إرسال استعلامات SELECT. لحسن الحظ ، يوجد برنامج تشغيل JDBC مع دعم DML و DDL من المجتمع بما في ذلك المعاملات . في حين أن برنامج التشغيل هذا مفيد للغاية ، إلا أن غياب برنامج تشغيل JDBC الخاص بـ Google أمر مثير للدهشة. لحسن الحظ ، تقدم Google دعمًا واسعًا لمكتبة العملاء (استنادًا إلى gRPC): C # و Go و Java و node.js و PHP و Python و Ruby.
يؤدي الاستخدام شبه الإلزامي لواجهات برمجة التطبيقات المخصصة لـ Cloud Spanner (نظرًا لعدم وجود DDL و DML في JDBC) إلى بعض القيود على المجالات ذات الصلة من التعليمات البرمجية مثل تجميع الاتصالات أو أطر ربط قاعدة البيانات (مثل Spring MVC). بشكل عام ، عند استخدام JDBC ، يمكنك اختيار مجموعة الاتصال المفضلة لديك (مثل HikariCP و DBCP و C3PO وما إلى ذلك) التي تم اختبارها وتعمل بشكل جيد. في حالة واجهات برمجة تطبيقات Spanner المخصصة ، يتعين علينا الاعتماد على مجموعات الأطر / الربط / الجلسات التي أنشأناها بأنفسنا.
يتيح التصميم الموجه للمفتاح الأساسي (الكمبيوتر) لـ Cloud Spanner أن يكون سريعًا جدًا عند الوصول إلى البيانات عبر الكمبيوتر ، ولكنه يقدم أيضًا بعض مشكلات الاستعلام.
- لا يمكنك تحديث قيمة المفتاح الأساسي ؛ يجب عليك أولاً حذف إدخال الكمبيوتر الأصلي وإعادة إدخاله بالقيمة الجديدة. (هذا مشابه لمحركات قواعد البيانات / التخزين الأخرى الموجهة للكمبيوتر الشخصي.)
- يجب أن تحدد أي عبارات UPDATE و DELETE جهاز الكمبيوتر الشخصي في WHERE ، وبالتالي لا يمكن أن يكون هناك فارغة DELETE all statement - يجب أن يكون هناك دائمًا استعلام فرعي ، على سبيل المثال: UPDATE xxx WHERE id IN (SELECT ID FROM table1)
- عدم وجود خيار زيادة تلقائية أو شيء مشابه يحدد التسلسل لحقل الكمبيوتر الشخصي. لكي يعمل هذا ، يجب إنشاء القيمة المقابلة على جانب التطبيق.
المؤشرات الثانوية؟
يحتوي Google Cloud Spanner على دعم مدمج للفهارس الثانوية. هذه ميزة لطيفة للغاية لا توجد دائمًا في التقنيات الأخرى. لا يدعم Apache Kudu حاليًا الفهارس الثانوية على الإطلاق ، ولا يدعم Apache HBase الفهارس مباشرةً ، ولكن يمكنه إضافتها عبر Apache Phoenix.
يمكن نمذجة الفهارس في Kudu و HBase كجدول منفصل بتكوين مختلف للمفاتيح الأساسية ، ولكن يجب إجراء ذرية العمليات التي يتم إجراؤها على الجدول الأصلي وجداول الفهرس ذات الصلة على مستوى التطبيق وليست تافهة للتنفيذ بشكل صحيح.
كما هو مذكور في مراجعة Cloud Spanner ، قد تختلف فهارسها عن فهارس MySQL. وبالتالي ، يجب توخي الحذر بشكل خاص في بناء الاستعلام والتنميط لضمان استخدام الفهرس الصحيح عند الحاجة.
التمثيل؟
من العناصر الشائعة جدًا والمفيدة في قاعدة البيانات طرق العرض. يمكن أن تكون مفيدة لعدد كبير من حالات الاستخدام ؛ المفضلان لدي هما طبقة التجريد المنطقي وطبقة الأمان. للأسف لا يدعم Cloud Spanner طرق العرض. ومع ذلك ، فإن هذا يحدنا جزئيًا فقط ، حيث لا يوجد دقة على مستوى العمود لأذونات الوصول حيث يمكن أن تكون طرق العرض حلاً مقبولاً.
راجع وثائق Cloud Spanner للحصول على قسم يوضح بالتفصيل الحصص والحدود () ، هناك واحد على وجه الخصوص يمكن أن يكون مشكلة لبعض التطبيقات: يحتوي Cloud Spanner خارج الصندوق على 100 قاعدة بيانات كحد أقصى لكل مثيل. من الواضح أن هذا يمكن أن يكون عقبة رئيسية لقاعدة بيانات مصممة لتتسع لأكثر من 100 قاعدة بيانات. لحسن الحظ ، بعد التحدث مع ممثل Google الفني لدينا ، اكتشفنا أنه يمكن زيادة هذا الحد إلى أي قيمة تقريبًا من خلال دعم Google.
دعم التنمية؟
تقدم Cloud Spanner دعمًا جيدًا للغة البرمجة للعمل مع واجهة برمجة التطبيقات الخاصة بها. المكتبات المدعومة رسميًا موجودة في منطقة C # و Go و Java و node.js و PHP و Python و Ruby. الوثائق مفصلة إلى حد ما ، ولكن كما هو الحال مع التقنيات المتطورة الأخرى ، فإن المجتمع صغير جدًا مقارنةً بتقنيات قواعد البيانات الأكثر شيوعًا ، مما قد يؤدي إلى قضاء المزيد من الوقت في حالات أو مشاكل الاستخدام الأقل شيوعًا.
إذن ماذا عن دعم التنمية المحلية؟
لم نعثر على طريقة لإنشاء مثيل Cloud Spanner محليًا. أقرب صورة لدينا هي صورة Docker وهو مشابه من حيث المبدأ ، ولكنه مختلف جدًا في الممارسة. على سبيل المثال ، يمكن لـ CockroachDB استخدام PostgreSQL JDBC. نظرًا لأن بيئة التطوير يجب أن تكون قريبة قدر الإمكان من بيئة الإنتاج ، فإن Cloud Spanner ليس مثاليًا لأنك تحتاج إلى الاعتماد على مثيل Spanner كامل. لتوفير التكاليف ، يمكنك تحديد مثيل منطقة واحدة.
دعم الإدارة؟
يعد إنشاء مثيل Cloud Spanner أمرًا بسيطًا للغاية. تحتاج فقط إلى الاختيار بين إنشاء مثيل متعدد المناطق أو مثيل لمنطقة واحدة ، وتحديد المنطقة (المناطق) وعدد العقد. في أقل من دقيقة ، سيتم تشغيل المثيل.
تتوفر العديد من المقاييس الأولية مباشرةً على صفحة Spanner في وحدة تحكم Google. تتوفر عروض أكثر تفصيلاً عبر Stackdriver ، حيث يمكنك أيضًا تعيين عتبات المقاييس وسياسات التنبيه.
الوصول إلى الموارد؟
تقدم MySQL إعدادات أذونات / دور واسعة ودقيقة للغاية للمستخدم. يمكنك بسهولة تخصيص الوصول إلى جدول معين ، أو حتى مجموعة فرعية من أعمدته. يستخدم Cloud Spanner أداة Google Identity & Access Management (IAM) ، والتي تتيح لك فقط تعيين السياسات والأذونات على مستوى عالٍ جدًا. الخيار الأكثر دقة هو الإذن على مستوى قاعدة البيانات ، والذي لا يناسب معظم حالات الإنتاج. يفرض عليك هذا التقييد إضافة إجراءات أمان إضافية إلى التعليمات البرمجية أو البنية التحتية أو كليهما لمنع الاستخدام غير المصرح به لموارد Spanner.
النسخ الاحتياطية؟
ببساطة ، لا توجد نسخ احتياطية في Cloud Spanner. على الرغم من أن متطلبات اتفاقية مستوى الخدمة العالية من Google يمكن أن تضمن عدم فقد أي بيانات بسبب فشل الأجهزة أو قاعدة البيانات ، أو الخطأ البشري ، أو عيوب التطبيقات ، وما إلى ذلك ، فنحن نعلم جميعًا القاعدة: التوافر العالي ليس بديلاً عن استراتيجية النسخ الاحتياطي الذكية. حاليًا ، الطريقة الوحيدة لنسخ البيانات احتياطيًا هي دفقها برمجيًا من قاعدة البيانات إلى بيئة تخزين منفصلة.
أداء الاستعلام؟
استخدمنا Yahoo! لتحميل البيانات واختبار الطلبات. معيار الخدمة السحابية. يوضح الجدول أدناه عبء عمل B YCSB بنسبة كتابة 95٪ إلى 5٪.
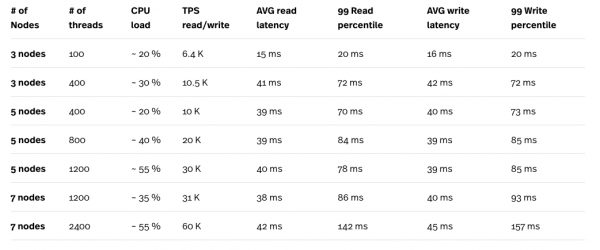
* تم تشغيل اختبار الحمل على n1-standard-32 Compute Engine (CE) (32 وحدة معالجة مركزية ، وذاكرة 120 جيجابايت) ولم يكن مثيل الاختبار أبدًا عنق الزجاجة في الاختبارات.
** الحد الأقصى لعدد سلاسل الرسائل في مثيل YCSB واحد هو 400. في المجموع ، كان لابد من تشغيل ست مثيلات متوازية من اختبارات YCSB للحصول على إجمالي 2400 مؤشر ترابط.
بالنظر إلى النتائج المعيارية ، لا سيما الجمع بين حمل وحدة المعالجة المركزية و TPS ، يمكننا أن نرى بوضوح أن Cloud Spanner يتوسع جيدًا. يتم تعويض الحمل الكبير الناتج عن عدد كبير من السلاسل بواسطة عدد كبير من العقد في مجموعة Cloud Spanner. على الرغم من أن وقت الاستجابة يبدو مرتفعًا جدًا ، خاصة عند التشغيل عند 2400 مؤشر ترابط ، فقد يكون من الضروري إعادة الاختبار باستخدام 6 حالات أصغر لمحرك الحوسبة للحصول على أرقام أكثر دقة. سيجري كل مثيل اختبار YCSB واحدًا بدلاً من مثيل CE كبير مع 6 اختبارات متوازية. سيسهل هذا التمييز بين تأخيرات طلب Cloud Spanner والتأخيرات المضافة بواسطة اتصال الشبكة بين Cloud Spanner ومثيل CE الذي يجري الاختبار.
كيف يعمل Cloud Spanner باعتباره OLAP؟
التقسيم؟
يعد تقسيم البيانات إلى مقاطع مستقلة ماديًا و / أو منطقيًا ، تسمى الأقسام ، مفهومًا شائعًا للغاية موجود في معظم محركات OLAP. يمكن للأقسام تحسين أداء الاستعلام وقابلية صيانة قاعدة البيانات بشكل كبير. مزيد من الخوض في التقسيم سيكون مقالة (مقالات) منفصلة ، لذلك دعنا نذكر فقط أهمية وجود نظام تجزئة وتقسيم فرعي. تعد القدرة على تقسيم البيانات إلى أقسام وحتى إلى أقسام فرعية هي المفتاح لأداء الاستعلامات التحليلية.
لا يدعم Cloud Spanner الأقسام في حد ذاتها. يفصل البيانات داخليًا إلى ما يسمى انقسم-s استنادًا إلى نطاقات المفاتيح الأساسية. يتم إجراء التقسيم تلقائيًا لموازنة الحمل على مجموعة Cloud Spanner. من الميزات المفيدة جدًا في Cloud Spanner تقسيم الحمل الأساسي لجدول أصلي (جدول غير مشقوق مع جدول آخر). يكتشف Spanner تلقائيًا ما إذا كان يحتوي على ملفات انقسم البيانات التي يتم قراءتها بشكل متكرر أكثر من البيانات الأخرى انقسم-آه ، وقد يقرر فصلًا آخر. وبالتالي ، يمكن إشراك المزيد من العقد في الطلب ، مما يؤدي أيضًا إلى زيادة الإنتاجية بشكل فعال.
تحميل البيانات؟
طريقة Cloud Spanner للبيانات المجمعة هي نفسها المستخدمة في التحميل المنتظم. للحصول على أقصى أداء ، عليك اتباع بعض الإرشادات ، بما في ذلك:
- فرز البيانات الخاصة بك عن طريق المفتاح الأساسي.
- قسّمهم على 10 *عدد العقد أقسام فردية.
- قم بإنشاء مجموعة من مهام العاملين التي تقوم بتحميل البيانات بشكل متوازٍ.
يستخدم تحميل البيانات هذا جميع عُقد Cloud Spanner.
استخدمنا أحمال عمل YCSB لإنشاء مجموعة بيانات 10 مليون صف.
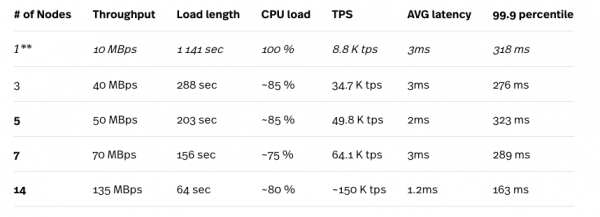
* تم تشغيل اختبار الحمل على محرك الحوسبة n1-standard-32 (32 وحدة معالجة مركزية ، وذاكرة 120 جيجابايت) ولم يكن مثيل الاختبار هو عنق الزجاجة في الاختبارات.
** لا يُنصح بإعداد عقدة واحدة لأي عبء عمل إنتاجي.
كما ذكرنا أعلاه ، تعالج Cloud Spanner التقسيمات تلقائيًا بناءً على حملها ، وبالتالي تتحسن النتائج بعد عدة تكرارات متتالية للاختبار. النتائج المعروضة هنا هي أفضل النتائج التي تلقيناها. بالنظر إلى الأرقام أعلاه ، يمكننا أن نرى كيف يتوسع Cloud Spanner (جيدًا) مع زيادة عدد العقد في الكتلة. الأرقام البارزة هي متوسط زمن انتقال منخفض للغاية ، والذي يتناقض مع نتائج أحمال العمل المختلطة (95٪ قراءة و 5٪ كتابة) كما هو موضح في القسم أعلاه.
تحجيم؟
تعد زيادة عدد عُقد Cloud Spanner وخفضه مهمة بنقرة واحدة. إذا كنت ترغب في تحميل البيانات بسرعة ، فقد ترغب في التفكير في زيادة المثيل إلى الحد الأقصى (في حالتنا كان 25 عقدة في منطقة الشرق الأوسط) ثم تقليل عدد العقد المناسبة للتحميل العادي بعد كل البيانات في قاعدة البيانات ، مع الأخذ في الاعتبار حد 2 تيرابايت / عقدة.
تم تذكيرنا بهذا الحد حتى مع وجود قاعدة بيانات أصغر بكثير. بعد عدة عمليات اختبار تحميل ، كان حجم قاعدة البيانات الخاصة بنا حوالي 155 غيغابايت ، وعند تقليص حجمها إلى مثيل عقدة واحدة ، حصلنا على الخطأ التالي:
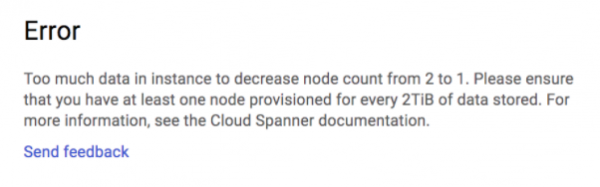
تمكنا من تقليص عدد الحالات من 25 إلى 2 ، لكننا عالقون في عقدتين.
يمكن أتمتة زيادة عدد العقد في مجموعة Cloud Spanner وتقليله باستخدام واجهة برمجة تطبيقات REST. يمكن أن يكون هذا مفيدًا بشكل خاص لتقليل الحمل الزائد على النظام أثناء ساعات الذروة.
أداء استعلام OLAP؟
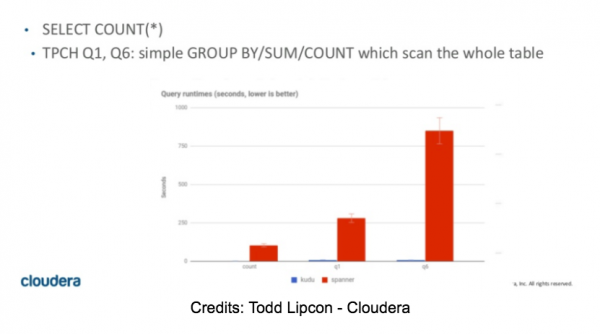
لقد خططنا في الأصل لتخصيص وقت كبير لتقييمنا لـ Spanner في هذا الجزء. بعد عدد قليل من SELECT COUNTs ، أدركنا على الفور أن الاختبار سيكون قصيرًا وأن Spanner لن يكون محركًا مناسبًا لـ OLAP. بغض النظر عن عدد العقد في المجموعة ، فإن اختيار عدد الصفوف في جدول 10M ببساطة يستغرق من 55 إلى 60 ثانية. أيضًا ، فشل أي استعلام يتطلب المزيد من الذاكرة لتخزين النتائج الوسيطة مع وجود خطأ OOM.
SELECT COUNT(DISTINCT(field0)) FROM usertable; — (10M distinct values)-> SpoolingHashAggregateIterator ran out of memory during new row.
يمكن العثور على بعض أرقام استعلامات TPC-H في مقالة Todd Lipcon ، الشريحتان 42 و 43. هذه الأرقام متوافقة مع نتائجنا (لسوء الحظ).
4. النتائج التي توصلنا إليها
نظرًا للحالة الحالية لميزات Cloud Spanner ، من الصعب رؤيتها كبديل بسيط لحل OLTP الحالي ، خاصةً عندما تتعدى احتياجاتك. سيستغرق بناء حل حول أوجه القصور في Cloud Spanner وقتًا طويلاً.
عندما بدأنا في تقييم Cloud Spanner ، توقعنا أن تكون ميزات الإدارة الخاصة به على قدم المساواة مع حلول Google SQL الأخرى أو على الأقل ليست بعيدة عنها. لكننا فوجئنا بالنقص الكامل في النسخ الاحتياطية والتحكم المحدود للغاية في الوصول إلى الموارد. ناهيك عن عدم وجود طرق عرض ، ولا توجد بيئة تطوير محلية ، وتسلسلات غير مدعومة ، و JDBC بدون دعم DML و DDL ، وما إلى ذلك.
إذن ، إلى أين نذهب لشخص يحتاج إلى توسيع نطاق قاعدة بيانات المعاملات؟ لا يبدو أن هناك حلًا واحدًا في السوق حتى الآن يناسب جميع حالات الاستخدام. هناك العديد من الحلول المغلقة والمفتوحة المصدر (بعضها مذكور في هذه المقالة) ، ولكل منها نقاط قوتها وضعفها ، ولكن لا يقدم أي منها SaaS مع 99,999٪ SLA ودرجة عالية من الاتساق. إذا كانت اتفاقية مستوى الخدمة العالية هي هدفك الأساسي ولا تميل إلى بناء الحل الخاص بك لسحب متعددة ، فقد يكون Cloud Spanner هو الحل الذي تبحث عنه. لكن يجب أن تكون على دراية بكل قيودها.
لكي نكون منصفين ، تم إصدار Cloud Spanner للجمهور فقط في ربيع عام 2017 ، لذلك من المعقول أن نتوقع أن بعض عيوبها الحالية قد تختفي في النهاية (نأمل) ، وعندما يحدث ذلك ، يمكن أن تغير قواعد اللعبة. بعد كل شيء ، Cloud Spanner ليس مجرد مشروع جانبي لـ Google. تستخدمه Google كأساس لمنتجات Google الأخرى. وعندما استبدلت Google مؤخرًا Megastore في Google Cloud Storage بـ Cloud Spanner ، سمحت لـ Google Cloud Storage بأن تصبح متسقة للغاية لقوائم الكائنات على نطاق عالمي (وهو ما لا يزال غير صحيح بالنسبة لـ ).
لذلك ، لا يزال هناك أمل ... نأمل.
هذا كل شئ. مثل كاتب المقال ، ما زلنا نأمل أيضًا ، لكن ما رأيك في هذا؟ اكتب في التعليقات
ندعو الجميع لزيارة الذي سنخبرك فيه بالتفصيل عن الدورة من أوتوس.
المصدر: www.habr.com
