

في هذه المقالة، سأصف موقفًا حدث مؤخرًا مع أحد خوادمنا السحابية الافتراضية الخاصة (VPS)، والذي حيّرني لعدة ساعات. لدي خبرة في تهيئة الخوادم واستكشاف أخطائها وإصلاحها تمتد لحوالي 15 عامًا. Linuxلكن هذه الحالة لا تتناسب مع ممارستي على الإطلاق - لقد وضعت عدة افتراضات خاطئة وكنت يائساً بعض الشيء قبل أن أتمكن من تحديد سبب المشكلة وحلها بشكل صحيح.
مقدمة
نحن ندير سحابة متوسطة الحجم، ونبنيها على خوادم قياسية بالتكوين التالي - 32 مركزًا، وذاكرة الوصول العشوائي (RAM) سعة 256 جيجابايت، ومحرك أقراص PCI-E Intel P4500 NVMe سعة 4 تيرابايت. نحن نحب هذا التكوين حقًا لأنه يلغي الحاجة إلى القلق بشأن حمل الإدخال/الإخراج من خلال توفير التقييد الصحيح على مستوى نوع مثيل VM. لأن NVMe إنتل يتمتع بأداء مثير للإعجاب، يمكننا في نفس الوقت توفير كل من توفير IOPS الكامل للأجهزة وتخزين النسخ الاحتياطي لخادم النسخ الاحتياطي بدون IOWAIT.
نحن أحد هؤلاء المؤمنين القدامى الذين لا يستخدمون شبكات SDN المتقاربة بشكل مفرط وغيرها من الأشياء الشبابية الأنيقة والعصرية لتخزين وحدات تخزين الأجهزة الافتراضية، معتقدين أنه كلما كان النظام أبسط، كان من الأسهل استكشاف الأخطاء وإصلاحها في ظروف "لقد ذهب المعلم الرئيسي" الى الجبال." ونتيجة لذلك، نقوم بتخزين وحدات تخزين VM بتنسيق QCOW2 في XFS أو EXT4، والتي يتم نشرها أعلى LVM2.
نحن مضطرون أيضًا إلى استخدام QCOW2 بواسطة المنتج الذي نستخدمه للتنسيق - Apache CloudStack.
لإجراء نسخة احتياطية، نلتقط صورة كاملة لوحدة التخزين باعتبارها لقطة LVM2 (نعم، نعلم أن لقطات LVM2 بطيئة، لكن Intel P4500 يساعدنا هنا أيضًا). نحن نفعل lvmcreate -s .. وبمساعدة dd نرسل النسخة الاحتياطية إلى خادم بعيد مزود بتخزين ZFS. نحن هنا لا نزال تقدميين قليلاً - بعد كل شيء، يمكن لـ ZFS تخزين البيانات في شكل مضغوط، ويمكننا استعادتها بسرعة باستخدام DD أو احصل على وحدات تخزين VM فردية باستخدام mount -o loop ....
لا يمكنك بالطبع إزالة الصورة الكاملة لمجلد LVM2، ولكن يمكنك تحميل نظام الملفات في ملف
ROونسخ صور QCOW2 بأنفسهم، ومع ذلك، فقد واجهنا حقيقة أن XFS أصبح سيئًا بسبب هذا، وليس على الفور، ولكن بطريقة لا يمكن التنبؤ بها. نحن لا نحب حقًا أن "يستمر" مضيفو برنامج Hypervisor فجأة في عطلات نهاية الأسبوع أو في الليل أو في العطلات بسبب أخطاء غير واضحة متى ستحدث. لذلك، بالنسبة لـ XFS، لا نستخدم تركيب اللقطةROلاستخراج المجلدات، نقوم ببساطة بنسخ مجلد LVM2 بالكامل.
يتم تحديد سرعة النسخ الاحتياطي إلى خادم النسخ الاحتياطي في حالتنا من خلال أداء خادم النسخ الاحتياطي، والذي يبلغ حوالي 600-800 ميجابايت/ثانية للبيانات غير القابلة للضغط؛ وهناك محدد آخر هو قناة 10 جيجابت/ثانية التي يتصل بها خادم النسخ الاحتياطي إلى الكتلة.
في الوقت نفسه، يتم تحميل 8 نسخ احتياطية إلى خادم نسخ احتياطي واحد في نفس الوقت. الخوادم برامج إدارة الأجهزة الافتراضية. وبالتالي، فإن أنظمة القرص والشبكة الفرعية لخادم النسخ الاحتياطي، على الرغم من كونها أبطأ، تمنع أنظمة القرص الفرعية لمضيفي برنامج إدارة الأجهزة الافتراضية من التحميل الزائد، لأنها ببساطة غير قادرة على التعامل مع، على سبيل المثال، 8 جيجابايت/ثانية، وهو ما يمكن لمضيفي برنامج إدارة الأجهزة الافتراضية التعامل معه بسهولة.
تعد عملية النسخ المذكورة أعلاه مهمة جدًا لمزيد من القصة، بما في ذلك التفاصيل - باستخدام محرك أقراص Intel P4500 سريع، باستخدام NFS، وربما باستخدام ZFS.
قصة احتياطية
في كل عقدة برنامج Hypervisor لدينا قسم SWAP صغير بحجم 8 جيجابايت، ونقوم "بطرح" عقدة برنامج Hypervisor نفسها باستخدام DD من الصورة المرجعية. بالنسبة لحجم النظام على الخوادم، نستخدم 2xSATA SSD RAID1 أو 2xSAS HDD RAID1 على وحدة تحكم الأجهزة LSI أو HP. بشكل عام، نحن لا نهتم على الإطلاق بما هو موجود بالداخل، نظرًا لأن حجم نظامنا يعمل في وضع "القراءة فقط تقريبًا"، باستثناء SWAP. وبما أن لدينا الكثير من ذاكرة الوصول العشوائي (RAM) على الخادم وهي مجانية بنسبة 30-40%، فإننا لا نفكر في SWAP.
عملية النسخ الاحتياطي. تبدو هذه المهمة كما يلي:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapلاحظ ionice -c3، في الواقع، هذا الشيء عديم الفائدة تمامًا لأجهزة NVMe، حيث تم تعيين جدولة الإدخال والإخراج الخاصة بها على النحو التالي:
cat /sys/block/nvme0n1/queue/scheduler
[none] ومع ذلك، لدينا عدد من العقد القديمة المزودة بوحدات SSD RAID التقليدية، وهذا أمر مهم بالنسبة لها، لذا فهي تتحرك AS IS. بشكل عام، هذا مجرد جزء مثير للاهتمام من التعليمات البرمجية يشرح عدم الجدوى ionice في حالة وجود مثل هذا التكوين.
انتبه إلى العلم iflag=direct إلى DD. نستخدم الإدخال المباشر لتجاوز ذاكرة التخزين المؤقت لتجنب الاستبدال غير الضروري لمخازن الإدخال والإخراج المؤقتة عند القراءة. لكن، oflag=direct لا نفعل ذلك لأننا واجهنا مشكلات في أداء ZFS عند استخدامه.
لقد تم استخدام هذا المخطط بنجاح لعدة سنوات دون مشاكل.
وبعد ذلك بدأت... اكتشفنا أن إحدى العقد لم تعد مدعومة، وأن العقدة السابقة كانت تعمل بـ IOWAIT هائل بنسبة 50%. وعند محاولة فهم سبب عدم حدوث النسخ، واجهنا الظاهرة التالية:
Volume group "images" not foundبدأنا نفكر في "لقد حانت نهاية Intel P4500"، ومع ذلك، قبل إيقاف تشغيل الخادم لاستبدال محرك الأقراص، كان لا يزال من الضروري إجراء نسخة احتياطية. قمنا بإصلاح LVM2 من خلال استعادة البيانات الوصفية من نسخة احتياطية لـ LVM2:
vgcfgrestore imagesأطلقنا نسخة احتياطية وشاهدنا هذه اللوحة الزيتية:
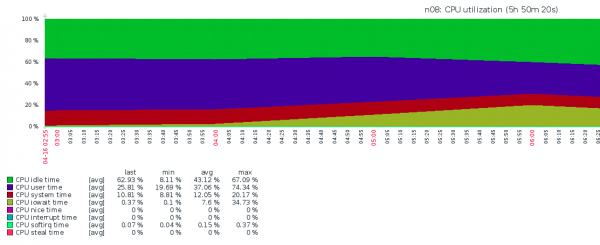
مرة أخرى، كنا حزينين للغاية - كان من الواضح أننا لا نستطيع العيش بهذه الطريقة، لأن جميع VPS ستعاني، مما يعني أننا سنعاني أيضًا. ما حدث غير واضح تماما - iostat أظهر IOPS يرثى لها وأعلى IOWAIT. لم تكن هناك أفكار أخرى غير "دعونا نستبدل NVMe"، ولكن حدثت فكرة في الوقت المناسب.
تحليل الوضع خطوة بخطوة
مجلة تاريخية. قبل بضعة أيام، كان من الضروري على هذا الخادم إنشاء VPS كبير بذاكرة وصول عشوائي (RAM) تبلغ 128 جيجابايت. يبدو أن هناك ذاكرة كافية، ولكن لكي نكون في الجانب الآمن، قمنا بتخصيص 32 جيجابايت أخرى لقسم المبادلة. تم إنشاء VPS، وأكمل مهمته بنجاح وتم نسيان الحادث، ولكن بقي قسم SWAP.
ميزات التكوين. لجميع الخوادم السحابية المعلمة vm.swappiness تم ضبطه على الوضع الافتراضي 60. وتم إنشاء SWAP على SAS HDD RAID1.
ماذا حدث (بحسب المحررين). عند النسخ الاحتياطي DD أنتجت الكثير من بيانات الكتابة، والتي تم وضعها في مخازن ذاكرة الوصول العشوائي (RAM) قبل الكتابة إلى NFS. جوهر النظام، مسترشدًا بالسياسة swappiness، كان ينقل العديد من صفحات ذاكرة VPS إلى منطقة المبادلة، والتي كانت موجودة على وحدة تخزين HDD RAID1 البطيئة. أدى هذا إلى نمو IOWAIT بقوة كبيرة، ولكن ليس بسبب IO NVMe، ولكن بسبب IO HDD RAID1.
كيف تم حل المشكلة. تم تعطيل قسم المبادلة بسعة 32 جيجابايت. استغرق هذا 16 ساعة، ويمكنك أن تقرأ بشكل منفصل عن كيفية وسبب إيقاف تشغيل SWAP ببطء شديد. تم تغيير الإعدادات swappiness إلى قيمة تساوي 5 في جميع أنحاء السحابة.
كيف لا يحدث هذا؟. أولاً، إذا كان SWAP على جهاز SSD RAID أو NVMe، وثانيًا، إذا لم يكن هناك جهاز NVMe، ولكن جهاز أبطأ لا ينتج مثل هذا الحجم من البيانات - ومن المفارقات أن المشكلة حدثت لأن NVMe سريع جدًا.
بعد ذلك، بدأ كل شيء يعمل كما كان من قبل - مع صفر IOWAIT.
المصدر: www.habr.com
