

مرحبا يا اصدقاء. قبل المغادرة للجزء الثاني من عطلة مايو ، نشارك معك المواد التي قمنا بترجمتها تحسباً لإطلاق بث جديد بالمعدل .

يقضي مطورو التطبيقات الكثير من الوقت في مقارنة عدة قواعد بيانات تشغيلية لاختيار القاعدة التي تعمل بشكل أفضل مع عبء العمل المقصود. قد تشمل الاحتياجات نمذجة البيانات المبسطة ، وضمانات المعاملات ، وأداء القراءة / الكتابة ، والقياس الأفقي ، والتسامح مع الخطأ. تقليديًا ، يبدأ الاختيار بفئة قاعدة البيانات ، SQL أو NoSQL ، نظرًا لأن كل فئة توفر مجموعة واضحة من المقايضات. يُنظر إلى الأداء العالي من حيث الكمون المنخفض والإنتاجية العالية عمومًا على أنه مطلب لا يمكن المساومة عليه وبالتالي فهو ضروري لأي قاعدة بيانات في العينة.
الغرض من هذه المقالة هو مساعدة مطوري التطبيقات على الاختيار الصحيح بين SQL و NoSQL في سياق نمذجة بيانات التطبيق. سننظر في قاعدة بيانات SQL واحدة ، وهي PostgreSQL ، وقواعد بيانات NoSQL ، وهما Cassandra و MongoDB ، لتغطية أساسيات تصميم قاعدة البيانات ، مثل إنشاء الجداول ، وتعبئتها ، وقراءة البيانات من جدول ، وحذفها. في المقالة التالية ، سننظر بالتأكيد في الفهارس والمعاملات و JOINs وتوجيهات TTL وتصميم قاعدة البيانات استنادًا إلى JSON.
ما الفرق بين SQL و NoSQL؟
تزيد قواعد بيانات SQL من مرونة التطبيق من خلال ضمانات معاملات ACID ، فضلاً عن قدرتها على الاستعلام عن البيانات باستخدام JOINs بطرق غير متوقعة بالإضافة إلى نماذج قواعد البيانات العلائقية المعيارية الحالية.
نظرًا لبنية العقدة المتجانسة / المفردة الخاصة بها واستخدام نموذج النسخ المتماثل الرئيسي والعبد للتكرار ، تفتقر قواعد بيانات SQL التقليدية إلى ميزتين مهمتين - قابلية الكتابة الخطية (أي التقسيم التلقائي عبر عقد متعددة) وفقدان البيانات التلقائي / صفر. هذا يعني أن كمية البيانات المستلمة لا يمكن أن تتجاوز الحد الأقصى لسرعة الكتابة لعقدة واحدة. بالإضافة إلى ذلك ، يجب مراعاة بعض الفقد المؤقت للبيانات من أجل التسامح مع الخطأ (في بنية غير مشتركة). هنا عليك أن تضع في اعتبارك أن الالتزامات الأخيرة لم تنعكس بعد في نسخة العبيد. من الصعب أيضًا تحقيق أي تحديثات تتعلق بوقت التعطل في قواعد بيانات SQL.
عادة ما يتم توزيع قواعد بيانات NoSQL في الطبيعة ، أي في نفوسهم ، يتم تقسيم البيانات إلى أقسام وتوزيعها على عدة عقد. تتطلب إلغاء التطبيع. هذا يعني أنه يجب أيضًا نسخ البيانات المدخلة عدة مرات من أجل الاستجابة للطلبات المحددة التي ترسلها. الهدف العام هو الحصول على أداء عالٍ عن طريق تقليل عدد الأجزاء المتاحة في وقت القراءة. هذا يعني أن NoSQL تتطلب منك نمذجة استعلاماتك ، بينما يتطلب منك SQL أن تصمم بياناتك.
تؤكد NoSQL على تحقيق أداء عالٍ في كتلة موزعة وهذا هو الأساس المنطقي للعديد من مقايضات تصميم قواعد البيانات ، والتي تشمل خسارة معاملات ACID ، و JOINs ، والمؤشرات الثانوية العالمية المتسقة.
هناك رأي مفاده أنه على الرغم من أن قواعد بيانات NoSQL توفر قابلية توسعة خطية للكتابة وتحمل عالي للأخطاء ، إلا أن فقدان ضمانات المعاملات يجعلها غير مناسبة للبيانات الهامة.
يوضح الجدول التالي كيف تختلف نمذجة البيانات في NoSQL عن SQL.
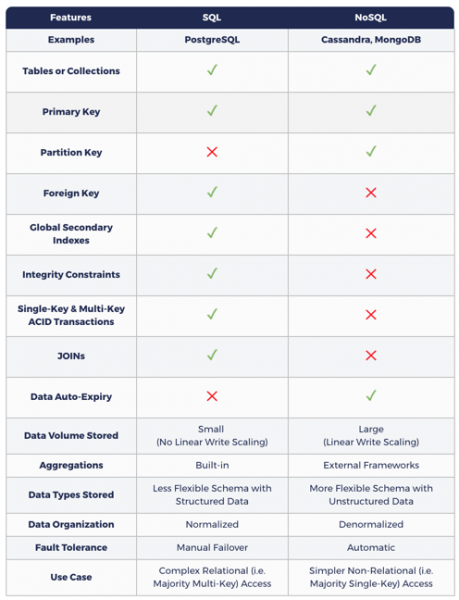
SQL و NoSQL: لماذا كلاهما مطلوب؟
تعتبر التطبيقات الواقعية التي تضم عددًا كبيرًا من المستخدمين ، مثل Amazon.com و Netflix و Uber و Airbnb ، مسؤولة عن أداء المهام المعقدة من مختلف الأنواع. على سبيل المثال ، يحتاج تطبيق التجارة الإلكترونية مثل Amazon.com إلى تخزين بيانات خفيفة الوزن وحساسة للغاية مثل المعلومات حول المستخدمين والمنتجات والطلبات والفواتير ، إلى جانب البيانات الثقيلة ولكن الأقل حساسية مثل مراجعات المنتجات ورسائل الدعم ونشاط المستخدم ومراجعات وتوصيات المستخدم. بطبيعة الحال ، تعتمد هذه التطبيقات على قاعدة بيانات SQL واحدة على الأقل إلى جانب قاعدة بيانات NoSQL واحدة على الأقل. في الأنظمة الإقليمية والعالمية ، تعمل قاعدة بيانات NoSQL كذاكرة تخزين مؤقت موزعة جغرافيًا للبيانات المخزنة في مصدر موثوق به ، قاعدة بيانات SQL ، تعمل في أي منطقة واحدة.
كيف تجمع YugaByte DB بين SQL و NoSQL؟
بنيت على محرك تخزين مختلط موجه للسجلات ، والتجزئة التلقائية ، والنسخ المتماثل الموزع والموزع للحمض (مستوحى من Google Spanner) ، فإن YugaByte DB هي أول قاعدة بيانات مفتوحة المصدر في العالم متوافقة مع NoSQL (Cassandra & Redis). ) و SQL (PostgreSQL). كما هو موضح في الجدول أدناه ، تضيف YCQL ، وهي واجهة برمجة تطبيقات YugaByte DB المتوافقة مع Cassandra ، مفاهيم معاملات ACID الفردية ومتعددة المفاتيح والفهارس الثانوية العالمية إلى NoSQL API ، وبالتالي الدخول في عصر قواعد بيانات NoSQL للمعاملات. بالإضافة إلى ذلك ، تضيف YCQL ، وهي واجهة برمجة تطبيقات YugaByte DB متوافقة مع PostgreSQL ، مفاهيم مقياس الكتابة الخطي وتجاوز الفشل التلقائي إلى واجهة برمجة تطبيقات SQL ، مما يوفر قواعد بيانات SQL الموزعة للعالم. نظرًا لأن قاعدة بيانات YugaByte DB هي معاملات بطبيعتها ، يمكن الآن استخدام واجهة NoSQL API في سياق البيانات الهامة.
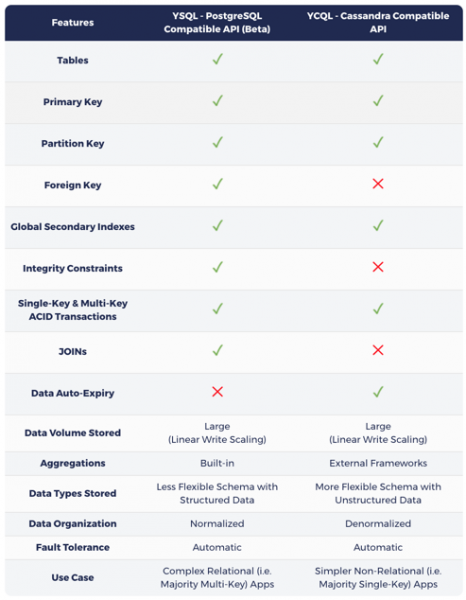
كما ذكر سابقا في المقال ، فإن الاختيار بين SQL أو NoSQL في YugaByte DB يعتمد كليًا على خصائص عبء العمل الأساسي:
- إذا كان عبء العمل الأساسي الخاص بك هو عمليات JOIN متعددة المفاتيح ، فعند اختيار YSQL ، يجب أن تدرك أن مفاتيحك قد تنتشر عبر عقد متعددة ، مما يؤدي إلى زمن انتقال أعلى و / أو إنتاجية أقل من NoSQL.
- بخلاف ذلك ، اختر أيًا من واجهتي NoSQL APIs ، مع الأخذ في الاعتبار أنك ستحصل على أداء أفضل نتيجة للاستعلامات التي يتم تقديمها من عقدة واحدة في كل مرة. يمكن أن تعمل YugaByte DB كقاعدة بيانات تشغيلية واحدة للتطبيقات المعقدة الحقيقية التي تحتاج إلى إدارة أعباء عمل متعددة في نفس الوقت.
يعتمد معمل نمذجة البيانات في القسم التالي على واجهات برمجة تطبيقات قاعدة بيانات YugaByte DB المتوافقة مع PostgreSQL و Cassandra ، بدلاً من قواعد البيانات الأصلية. يؤكد هذا النهج على سهولة التفاعل مع واجهتي API مختلفتين (على منفذين مختلفين) من نفس مجموعة قاعدة البيانات ، بدلاً من استخدام مجموعات مستقلة تمامًا من قاعدتي بيانات مختلفتين.
في الأقسام التالية ، سنلقي نظرة على معمل نمذجة البيانات لتوضيح الاختلاف وبعض القواسم المشتركة لقواعد البيانات المعنية.
معمل نمذجة البيانات
تركيب قواعد البيانات
نظرًا للتركيز على تصميم نموذج البيانات (بدلاً من معماريات النشر المعقدة) ، سنقوم بتثبيت قواعد البيانات في حاويات Docker على الجهاز المحلي ثم التفاعل معها باستخدام أغلفة سطر الأوامر الخاصة بها.
متوافق مع PostgreSQL و Cassandra ، قاعدة بيانات YugaByte DB
mkdir ~/yugabyte && cd ~/yugabyte
wget https://downloads.yugabyte.com/yb-docker-ctl && chmod +x yb-docker-ctl
docker pull yugabytedb/yugabyte
./yb-docker-ctl create --enable_postgresMongoDB
docker run --name my-mongo -d mongo:latestوصول سطر الأوامر
دعنا نتصل بقواعد البيانات باستخدام غلاف سطر الأوامر لواجهات برمجة التطبيقات المعنية.
كيو
عبارة عن غلاف سطر أوامر للتفاعل مع PostgreSQL. لسهولة الاستخدام ، يأتي YugaByte DB مع psql في مجلد سلة المهملات.
docker exec -it yb-postgres-n1 /home/yugabyte/postgres/bin/psql -p 5433 -U postgresكاساندرا
هي قذيفة سطر أوامر للتفاعل مع Cassandra وقواعد البيانات المتوافقة معها عبر CQL (لغة Cassandra Query). لسهولة الاستخدام ، يأتي YugaByte DB مع cqlsh في الكتالوج bin.
لاحظ أن لغة CQL مستوحاة من SQL ولديها مفاهيم متشابهة للجداول والصفوف والأعمدة والفهارس. ومع ذلك ، باعتبارها لغة NoSQL ، فإنها تضيف مجموعة معينة من القيود ، والتي سنغطي معظمها أيضًا في مقالات أخرى.
docker exec -it yb-tserver-n1 /home/yugabyte/bin/cqlshMongoDB
هي قذيفة سطر أوامر للتفاعل مع MongoDB. يمكن العثور عليها في دليل bin الخاص بتثبيت MongoDB.
docker exec -it my-mongo bash
cd bin
mongoإنشاء جدول
يمكننا الآن التفاعل مع قاعدة البيانات لإجراء عمليات مختلفة باستخدام سطر الأوامر. لنبدأ بإنشاء جدول يخزن معلومات حول الأغاني التي كتبها فنانين مختلفين. قد تكون هذه الأغاني جزءًا من ألبوم. السمات الاختيارية أيضًا للأغنية هي سنة الإصدار والسعر والنوع والتصنيف. نحتاج إلى مراعاة السمات الإضافية التي قد تكون مطلوبة في المستقبل من خلال حقل "العلامات". يمكنه تخزين البيانات شبه المنظمة كأزواج ذات قيمة رئيسية.
كيو
CREATE TABLE Music (
Artist VARCHAR(20) NOT NULL,
SongTitle VARCHAR(30) NOT NULL,
AlbumTitle VARCHAR(25),
Year INT,
Price FLOAT,
Genre VARCHAR(10),
CriticRating FLOAT,
Tags TEXT,
PRIMARY KEY(Artist, SongTitle)
); كاساندرا
إنشاء جدول في Cassandra يشبه إلى حد بعيد PostgreSQL. أحد الاختلافات الرئيسية هو عدم وجود قيود التكامل (مثل NOT NULL) ، ولكن هذه مسؤولية التطبيق ، وليس قاعدة بيانات NoSQL.. يتكون المفتاح الأساسي من مفتاح قسم (عمود الفنان في المثال أدناه) ومجموعة من أعمدة التجميع (عمود SongTitle في المثال أدناه). يحدد مفتاح القسم القسم / الجزء الذي سيتم وضع الصف فيه ، وتشير أعمدة التجميع إلى كيفية تنظيم البيانات داخل الجزء الحالي.
CREATE KEYSPACE myapp;
USE myapp;
CREATE TABLE Music (
Artist TEXT,
SongTitle TEXT,
AlbumTitle TEXT,
Year INT,
Price FLOAT,
Genre TEXT,
CriticRating FLOAT,
Tags TEXT,
PRIMARY KEY(Artist, SongTitle)
);MongoDB
تنظم MongoDB البيانات في قواعد بيانات (قاعدة بيانات) (على غرار Keyspace في Cassandra) ، حيث توجد مجموعات (مجموعات) (على غرار الجداول) تحتوي على مستندات (مستندات) (على غرار الصفوف في جدول). في MongoDB ، من حيث المبدأ ، لا يلزم تعريف مخطط أولي. فريق "استخدام قاعدة البيانات"، الموضح أدناه ، يقوم بإنشاء مثيل لقاعدة البيانات في المكالمة الأولى وتغيير سياق قاعدة البيانات المنشأة حديثًا. حتى المجموعات لا تحتاج إلى الإنشاء بشكل صريح ، يتم إنشاؤها تلقائيًا ، فقط عند إضافة المستند الأول إلى مجموعة جديدة. لاحظ أن MongoDB يستخدم قاعدة بيانات اختبارية بشكل افتراضي ، لذلك سيتم تنفيذ أي عملية على مستوى المجموعة بدون تحديد قاعدة بيانات معينة فيها بشكل افتراضي.
use myNewDatabase;الحصول على معلومات حول الجدول
كيو
d Music
Table "public.music"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+--------
artist | character varying(20) | | not null |
songtitle | character varying(30) | | not null |
albumtitle | character varying(25) | | |
year | integer | | |
price | double precision | | |
genre | character varying(10) | | |
criticrating | double precision | | |
tags | text | | |
Indexes:
"music_pkey" PRIMARY KEY, btree (artist, songtitle)كاساندرا
DESCRIBE TABLE MUSIC;
CREATE TABLE myapp.music (
artist text,
songtitle text,
albumtitle text,
year int,
price float,
genre text,
tags text,
PRIMARY KEY (artist, songtitle)
) WITH CLUSTERING ORDER BY (songtitle ASC)
AND default_time_to_live = 0
AND transactions = {'enabled': 'false'};MongoDB
use myNewDatabase;
show collections;إدخال البيانات في الجدول
كيو
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Year, Price, Genre, CriticRating,
Tags)
VALUES(
'No One You Know', 'Call Me Today', 'Somewhat Famous',
2015, 2.14, 'Country', 7.8,
'{"Composers": ["Smith", "Jones", "Davis"],"LengthInSeconds": 214}'
);
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Price, Genre, CriticRating)
VALUES(
'No One You Know', 'My Dog Spot', 'Hey Now',
1.98, 'Country', 8.4
);
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Price, Genre)
VALUES(
'The Acme Band', 'Look Out, World', 'The Buck Starts Here',
0.99, 'Rock'
);
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Price, Genre,
Tags)
VALUES(
'The Acme Band', 'Still In Love', 'The Buck Starts Here',
2.47, 'Rock',
'{"radioStationsPlaying": ["KHCR", "KBQX", "WTNR", "WJJH"], "tourDates": { "Seattle": "20150625", "Cleveland": "20150630"}, "rotation": Heavy}'
);كاساندرا
بشكل عام ، التعبير INSERT في Cassandra تبدو مشابهة جدًا لتلك الموجودة في PostgreSQL. ومع ذلك ، هناك اختلاف كبير في دلالات الألفاظ. في كاساندرا INSERT هي في الواقع عملية UPSERT، حيث يتم إضافة أحدث القيم إلى السلسلة ، في حالة وجود السلسلة بالفعل.
إدخال البيانات مشابه لـ PostgreSQL
INSERTفوق
.
MongoDB
على الرغم من أن MongoDB هي قاعدة بيانات NoSQL مثل Cassandra ، فإن عملية إدخال البيانات لا علاقة لها بسلوك Cassandra الدلالي. في MongoDB ليس لديه فرصة UPSERT، مما يجعله مشابهًا لـ PostgreSQL. إضافة البيانات الافتراضية بدون _idspecified سيؤدي إلى إضافة مستند جديد إلى المجموعة.
db.music.insert( {
artist: "No One You Know",
songTitle: "Call Me Today",
albumTitle: "Somewhat Famous",
year: 2015,
price: 2.14,
genre: "Country",
tags: {
Composers: ["Smith", "Jones", "Davis"],
LengthInSeconds: 214
}
}
);
db.music.insert( {
artist: "No One You Know",
songTitle: "My Dog Spot",
albumTitle: "Hey Now",
price: 1.98,
genre: "Country",
criticRating: 8.4
}
);
db.music.insert( {
artist: "The Acme Band",
songTitle: "Look Out, World",
albumTitle:"The Buck Starts Here",
price: 0.99,
genre: "Rock"
}
);
db.music.insert( {
artist: "The Acme Band",
songTitle: "Still In Love",
albumTitle:"The Buck Starts Here",
price: 2.47,
genre: "Rock",
tags: {
radioStationsPlaying:["KHCR", "KBQX", "WTNR", "WJJH"],
tourDates: {
Seattle: "20150625",
Cleveland: "20150630"
},
rotation: "Heavy"
}
}
);
استعلام جدول
ربما يكون الاختلاف الأكثر أهمية بين SQL و NoSQL من حيث الاستعلام هو استخدام FROM и WHERE. يسمح SQL بعد التعبير FROM حدد جداول متعددة ، وتعبيرًا به WHERE يمكن أن يكون بأي تعقيد (بما في ذلك العمليات JOIN بين الجداول). ومع ذلك ، تميل NoSQL إلى فرض قيود صارمة على FROM، والعمل مع جدول واحد محدد فقط ، وفي WHERE، يجب دائمًا تحديد المفتاح الأساسي. هذا بسبب الرغبة في تحسين أداء NoSQL ، والتي تحدثنا عنها سابقًا. تؤدي هذه الرغبة إلى كل تقليل محتمل لأي تفاعل عبر تبويب وتفاعل عبر المفاتيح. يمكن أن يؤدي إلى تأخير كبير في الاتصال بين العقد عند الاستجابة لطلب وبالتالي من الأفضل تجنبه من حيث المبدأ. على سبيل المثال ، تتطلب Cassandra أن تكون الطلبات مقيدة ببعض المشغلين (مسموح فقط =, IN, <, >, =>, <=) على مفاتيح الأقسام ، إلا عند الاستعلام عن فهرس ثانوي (فقط عامل التشغيل = مسموح به هنا).
كيو
فيما يلي ثلاثة أمثلة على الاستعلامات التي يمكن تنفيذها بسهولة بواسطة قاعدة بيانات SQL.
- عرض جميع أغاني الفنان.
- عرض جميع أغاني الفنان المطابقة للجزء الأول من العنوان ؛
- عرض جميع الأغاني لفنان يحتوي على كلمة معينة في عنوانه ويكون سعره أقل من 1.00.
SELECT * FROM Music
WHERE Artist='No One You Know';
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle LIKE 'Call%';
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle LIKE '%Today%'
AND Price > 1.00;كاساندرا
من بين استعلامات PostgreSQL المذكورة أعلاه ، لن يعمل إلا الاستفسار الأول دون تغيير في Cassandra ، لأن العبارة LIKE لا يمكن تطبيقه على أعمدة التجميع مثل SongTitle. في هذه الحالة ، يُسمح فقط بالعاملين = и IN.
SELECT * FROM Music
WHERE Artist='No One You Know';
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle IN ('Call Me Today', 'My Dog Spot')
AND Price > 1.00;MongoDB
كما هو موضح في الأمثلة السابقة ، فإن الطريقة الرئيسية لإنشاء استعلامات في MongoDB هي . تحتوي هذه الطريقة بشكل صريح على اسم المجموعة (music في المثال أدناه) ، لذلك لا يُسمح بالاستعلام عن مجموعات متعددة.
db.music.find( {
artist: "No One You Know"
}
);
db.music.find( {
artist: "No One You Know",
songTitle: /Call/
}
);قراءة كل صفوف الجدول
قراءة جميع الصفوف هي مجرد حالة خاصة لنمط الاستعلام الذي ناقشناه سابقًا.
كيو
SELECT *
FROM Music;كاساندرا
على غرار مثال PostgreSQL أعلاه.
MongoDB
db.music.find( {} );تحرير البيانات في جدول
كيو
تقدم PostgreSQL بيانًا UPDATE لتغيير البيانات. ليس لديها فرصة UPSERT، لذلك ستفشل هذه العبارة إذا لم يعد الصف موجودًا في قاعدة البيانات.
UPDATE Music
SET Genre = 'Disco'
WHERE Artist = 'The Acme Band' AND SongTitle = 'Still In Love';كاساندرا
كاساندرا لديها UPDATE على غرار PostgreSQL. UPDATE له نفس الدلالات UPSERT، يحب INSERT.
على غرار مثال PostgreSQL أعلاه.
MongoDB
عملية في MongoDB يمكنه تحديث مستند موجود بالكامل أو تحديث حقول معينة فقط. بشكل افتراضي ، يقوم بتحديث مستند واحد فقط مع تعطيل الدلالات UPSERT. تحديث مستندات متعددة والسلوك المماثل UPSERT يمكن تطبيقه عن طريق وضع أعلام إضافية للعملية. على سبيل المثال في المثال أدناه ، يتم تحديث نوع فنان معين من خلال أغنيته.
db.music.update(
{"artist": "The Acme Band"},
{
$set: {
"genre": "Disco"
}
},
{"multi": true, "upsert": true}
);إزالة البيانات من الجدول
كيو
DELETE FROM Music
WHERE Artist = 'The Acme Band' AND SongTitle = 'Look Out, World';كاساندرا
على غرار مثال PostgreSQL أعلاه.
MongoDB
لدى MongoDB نوعان من العمليات لحذف المستندات - и . كلا النوعين يحذف المستندات ولكن يعرضان نتائج مختلفة.
db.music.deleteMany( {
artist: "The Acme Band"
}
);
حذف الجدول
كيو
DROP TABLE Music;كاساندرا
على غرار مثال PostgreSQL أعلاه.
MongoDB
db.music.drop();اختتام
ظل الجدل حول الاختيار بين SQL و NoSQL محتدماً لأكثر من 10 سنوات. هناك جانبان رئيسيان لهذا النقاش: بنية محرك قاعدة البيانات (متجانسة ، معاملات SQL مقابل NoSQL الموزعة ، غير المعاملات) وطريقة تصميم قاعدة البيانات (نمذجة البيانات في SQL مقابل نمذجة استعلاماتك في NoSQL).
من خلال قاعدة بيانات المعاملات الموزعة مثل YugaByte DB ، يمكن تبديد النقاش حول بنية قاعدة البيانات بسهولة. نظرًا لأن أحجام البيانات تصبح أكبر مما يمكن كتابته إلى عقدة واحدة ، يصبح من الضروري وجود بنية موزعة بالكامل تدعم قابلية توسيع الكتابة الخطية مع التجزئة / إعادة الموازنة التلقائية.
بالإضافة إلى ما قيل في إحدى المقالات ، معاملات ، معمارية متسقة بشدة الآن على نطاق أوسع لتوفير مرونة تطوير أفضل من البنيات غير المعاملات ، المتسقة في نهاية المطاف.
بالعودة إلى مناقشة تصميم قاعدة البيانات ، من الإنصاف القول إن كلا من نهج التصميم (SQL و NoSQL) ضروريان لأي تطبيق معقد في العالم الحقيقي. يتيح نهج "نمذجة البيانات" في SQL للمطورين تلبية متطلبات العمل المتغيرة بسهولة أكبر ، بينما يسمح نهج "نمذجة الاستعلام" في NoSQL لهؤلاء المطورين أنفسهم بمعالجة كميات كبيرة من البيانات بزمن انتقال منخفض وإنتاجية عالية. ولهذا السبب ، توفر YugaByte DB واجهات برمجة تطبيقات SQL و NoSQL في جوهر مشترك ، ولا تدعم أيًا من الأساليب. بالإضافة إلى ذلك ، من خلال توفير التوافق مع لغات قواعد البيانات الشائعة ، بما في ذلك PostgreSQL و Cassandra ، تضمن YugaByte DB عدم اضطرار المطورين إلى تعلم لغة أخرى للعمل مع محرك قاعدة بيانات متناسق وموزع بقوة.
في هذه المقالة ، نظرنا في كيفية اختلاف أساسيات تصميم قواعد البيانات بين PostgreSQL و Cassandra و MongoDB. في المقالات التالية ، سنتعمق في مفاهيم التصميم المتقدمة مثل الفهارس والمعاملات و JOINs وتوجيهات TTL ووثائق JSON.
نتمنى لك عطلة نهاية أسبوع رائعة وندعوك إلى ذلك الذي سيعقد في 14 مايو.
المصدر: www.habr.com
