

نظرًا لخط عملي، يجب أن أتعامل مع المواقف عندما يكتب أحد المطورين طلبًا ويفكر "القاعدة ذكية، يمكنها التعامل مع كل شيء بنفسها!«
في بعض الحالات (جزئيًا بسبب الجهل بقدرات قاعدة البيانات، وجزئيًا بسبب التحسينات المبكرة)، يؤدي هذا النهج إلى ظهور "الفرانكنشتاين".
أولاً، سأعطي مثالاً على هذا الطلب:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;لتقييم جودة الطلب بشكل جوهري، فلنقم بإنشاء مجموعة بيانات عشوائية:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
لقد أتضح أن استغرقت قراءة البيانات أقل من ربع الوقت تنفيذ الاستعلام:
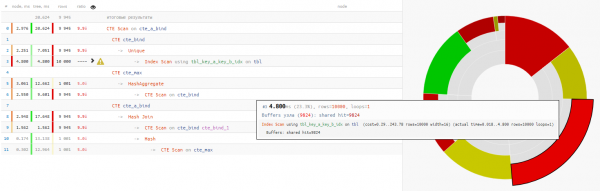
تفكيكها قطعة قطعة
دعونا نلقي نظرة فاحصة على الطلب ونكون في حيرة:
- لماذا مع العودية هنا إذا لم تكن هناك CTEs العودية؟
- لماذا يتم تجميع قيم الحد الأدنى/الحد الأقصى في CTE منفصل إذا تم ربطها بعد ذلك بالعينة الأصلية على أي حال؟
+25% الوقت - لماذا نستخدم "SELECT * FROM" غير المشروط في النهاية لتكرار CTE السابق؟
+14% الوقت
في هذه الحالة، كنا محظوظين جدًا لأنه تم اختيار Hash Join للاتصال، وليس Nested Loop، لأنه بعد ذلك كنا سنحصل على ليس فقط تمريرة مسح CTE واحدة، ولكن 10 آلاف!
قليلا عن مسح CTEوهنا يجب أن نتذكر ذلك يشبه مسح CTE مسح Seq - أي أنه لا توجد فهرسة، بل مجرد بحث كامل، وهو ما يتطلبه الأمر 10 كيلو × 0.3 مللي ثانية = 3000ms للدورات بواسطة cte_max أو 1 كيلو × 1.5 مللي ثانية = 1500ms عند التكرار بواسطة cte_bind!
في الواقع، ما الذي أردت الحصول عليه نتيجة لذلك؟ نعم، عادةً ما يظهر هذا السؤال في الدقيقة الخامسة من تحليل الاستعلامات "المكونة من ثلاثة طوابق".
أردنا إخراج كل زوج مفاتيح فريد الحد الأدنى/الحد الأقصى من المجموعة بواسطة key_a.
لذلك دعونا نستخدمها لهذا الغرض :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 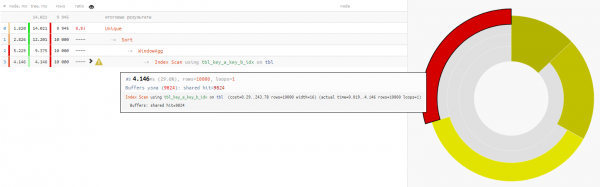
نظرًا لأن قراءة البيانات في كلا الخيارين تستغرق نفس الوقت من 4 إلى 5 مللي ثانية تقريبًا، فإننا نكسب كل وقتنا -32٪ - وهذا في أنقى صوره تمت إزالة الحمل من وحدة المعالجة المركزية الأساسية، إذا تم تنفيذ هذا الطلب في كثير من الأحيان بما فيه الكفاية.
بشكل عام، لا يجب أن تجبر القاعدة على "حمل المستديرة، ولف المربعة".
المصدر: www.habr.com
