


يا هبر.
في الآونة الأخيرة، وأنا حول المعلمات التي نستخدمها كفريق في أغلب الأحيان لمنتج ومستهلك كافكا للاقتراب من التسليم المضمون. أريد في هذه المقالة أن أخبرك كيف قمنا بتنظيم إعادة معالجة حدث تم استلامه من كافكا نتيجة لعدم توفر النظام الخارجي بشكل مؤقت.
تعمل التطبيقات الحديثة في بيئة معقدة للغاية. منطق الأعمال المغلف في حزمة تقنية حديثة، يعمل في صورة Docker تتم إدارتها بواسطة منسق مثل Kubernetes أو OpenShift، ويتواصل مع التطبيقات الأخرى أو حلول المؤسسات من خلال سلسلة من أجهزة التوجيه الفعلية والافتراضية. في مثل هذه البيئة، يمكن أن يتعطل شيء ما دائمًا، لذا فإن إعادة معالجة الأحداث في حالة عدم توفر أحد الأنظمة الخارجية يعد جزءًا مهمًا من عمليات أعمالنا.
كيف كان الأمر قبل كافكا
في وقت سابق من المشروع استخدمنا IBM MQ لتسليم الرسائل غير المتزامنة. في حالة حدوث أي خطأ أثناء تشغيل الخدمة، يمكن وضع الرسالة المستلمة في قائمة انتظار الرسائل الميتة (DLQ) لمزيد من التحليل اليدوي. تم إنشاء DLQ بجوار قائمة الانتظار الواردة، وتم نقل الرسالة داخل IBM MQ.
إذا كان الخطأ مؤقتًا وتمكنا من تحديده (على سبيل المثال، ResourceAccessException عند استدعاء HTTP أو MongoTimeoutException عند طلب MongoDb)، فستسري استراتيجية إعادة المحاولة. بغض النظر عن منطق التفريع للتطبيق، تم نقل الرسالة الأصلية إما إلى قائمة انتظار النظام للإرسال المؤجل، أو إلى تطبيق منفصل تم إنشاؤه منذ فترة طويلة لإعادة إرسال الرسائل. يتضمن ذلك رقم إعادة الإرسال في رأس الرسالة، والذي يرتبط بفاصل التأخير أو نهاية إستراتيجية مستوى التطبيق. إذا وصلنا إلى نهاية الإستراتيجية ولكن النظام الخارجي لا يزال غير متاح، فسيتم وضع الرسالة في DLQ للتحليل اليدوي.
حلول البحث
، يمكنك العثور على ما يلي . باختصار، يُقترح إنشاء موضوع لكل فترة تأخير وتنفيذ تطبيقات المستهلك على الجانب، والتي ستقرأ الرسائل مع التأخير المطلوب.
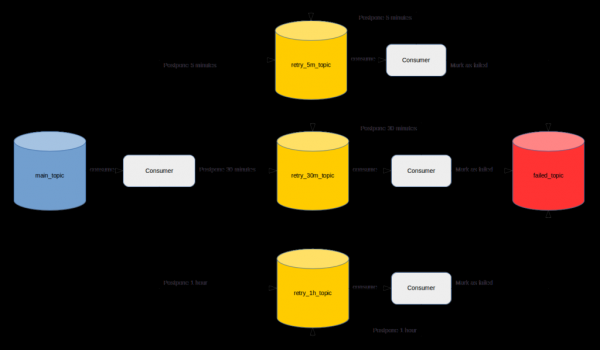
على الرغم من العدد الكبير من المراجعات الإيجابية، يبدو لي أنه لم يكن ناجحا تماما. بادئ ذي بدء، لأن المطور، بالإضافة إلى تنفيذ متطلبات العمل، سيتعين عليه قضاء الكثير من الوقت في تنفيذ الآلية الموضحة.
بالإضافة إلى ذلك، إذا تم تمكين التحكم في الوصول في مجموعة كافكا، فسيتعين عليك قضاء بعض الوقت في إنشاء المواضيع وتوفير الوصول اللازم إليها. بالإضافة إلى ذلك، ستحتاج إلى تحديد معلمة الاحتفاظ الصحيحة لكل موضوع من موضوعات إعادة المحاولة حتى يكون لدى الرسائل وقت لإعادة إرسالها ولا تختفي منها. يجب تكرار التنفيذ وطلب الوصول لكل خدمة موجودة أو جديدة.
دعونا الآن نرى ما هي الآليات التي يوفرها لنا Spring بشكل عام وSpring-kafka بشكل خاص لإعادة معالجة الرسائل. لدى Spring-kafka اعتماد متعدٍ على إعادة المحاولة الربيعية، والذي يوفر تجريدات لإدارة BackOffPolicies المختلفة. هذه أداة مرنة إلى حد ما، ولكن عيبها الكبير هو تخزين الرسائل لإعادة إرسالها في ذاكرة التطبيق. وهذا يعني أن إعادة تشغيل التطبيق بسبب تحديث أو خطأ تشغيلي سيؤدي إلى فقدان جميع الرسائل التي في انتظار إعادة المعالجة. وبما أن هذه النقطة بالغة الأهمية لنظامنا، فإننا لم نفكر فيها أكثر.
يوفر Spring-kafka نفسه العديد من تطبيقات ContainerAwareErrorHandler، على سبيل المثال ، والتي يمكنك من خلالها معالجة الرسالة لاحقًا دون تغيير الإزاحة في حالة حدوث خطأ. بدءًا من إصدار Spring-kafka 2.3، أصبح من الممكن ضبط BackOffPolicy.
يسمح هذا الأسلوب للرسائل المعاد معالجتها بالبقاء على قيد الحياة عند إعادة تشغيل التطبيق، ولكن لا توجد آلية DLQ حتى الآن. لقد اخترنا هذا الخيار في بداية عام 2019، معتقدين بشكل متفائل أنه لن تكون هناك حاجة إلى DLQ (كنا محظوظين ولم نكن بحاجة إليه بالفعل بعد عدة أشهر من تشغيل التطبيق بنظام إعادة المعالجة هذا). تسببت الأخطاء المؤقتة في تشغيل SeekToCurrentErrorHandler. تمت طباعة الأخطاء المتبقية في السجل، مما أدى إلى إزاحة، واستمرت المعالجة مع الرسالة التالية.
قرار نهائي
لقد دفعنا التنفيذ المستند إلى SeekToCurrentErrorHandler إلى تطوير آليتنا الخاصة لإعادة إرسال الرسائل.
بادئ ذي بدء، أردنا استخدام الخبرة الحالية وتوسيعها اعتمادًا على منطق التطبيق. بالنسبة لتطبيق المنطق الخطي، سيكون من الأمثل التوقف عن قراءة الرسائل الجديدة لفترة قصيرة من الوقت تحددها استراتيجية إعادة المحاولة. بالنسبة للتطبيقات الأخرى، أردت الحصول على نقطة واحدة من شأنها فرض استراتيجية إعادة المحاولة. بالإضافة إلى ذلك، يجب أن تحتوي هذه النقطة المفردة على وظيفة DLQ لكلا الطريقتين.
يجب تخزين استراتيجية إعادة المحاولة نفسها في التطبيق، وهو المسؤول عن استرداد الفاصل الزمني التالي عند حدوث خطأ مؤقت.
إيقاف المستهلك لتطبيق المنطق الخطي
عند العمل مع Spring-kafka، قد يبدو رمز إيقاف المستهلك كما يلي:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}في المثال، retryAt هو الوقت المناسب لإعادة تشغيلMessageListenerContainer إذا كان لا يزال قيد التشغيل. ستتم إعادة التشغيل في سلسلة محادثات منفصلة يتم إطلاقها في TaskScheduler، والتي سيتم تنفيذها أيضًا بحلول الربيع.
نجد قيمة retryAt بالطريقة التالية:
- يتم البحث عن قيمة عداد إعادة الاتصال.
- واستنادًا إلى قيمة العداد، يتم البحث عن الفاصل الزمني للتأخير الحالي في استراتيجية إعادة المحاولة. يتم الإعلان عن الإستراتيجية في التطبيق نفسه، وقد اخترنا تنسيق JSON لتخزينها.
- يحتوي الفاصل الزمني الموجود في مصفوفة JSON على عدد الثواني التي يجب تكرار المعالجة بعدها. تتم إضافة هذا العدد من الثواني إلى الوقت الحالي لتكوين قيمة retryAt.
- إذا لم يتم العثور على الفاصل الزمني، فستكون قيمة retryAt فارغة وسيتم إرسال الرسالة إلى DLQ للتحليل اليدوي.
مع هذا الأسلوب، كل ما تبقى هو حفظ عدد المكالمات المتكررة لكل رسالة تتم معالجتها حاليًا، على سبيل المثال في ذاكرة التطبيق. إن الاحتفاظ بعدد مرات إعادة المحاولة في الذاكرة ليس أمرًا بالغ الأهمية لهذا الأسلوب، نظرًا لأن تطبيق المنطق الخطي لا يمكنه التعامل مع المعالجة ككل. على عكس إعادة المحاولة الربيعية، لن تؤدي إعادة تشغيل التطبيق إلى فقدان جميع الرسائل لإعادة معالجتها، ولكنها ستؤدي ببساطة إلى إعادة تشغيل الإستراتيجية.
يساعد هذا الأسلوب على إزالة العبء عن النظام الخارجي، والذي قد لا يكون متاحًا بسبب الحمل الثقيل جدًا. بمعنى آخر، بالإضافة إلى إعادة المعالجة، حققنا تنفيذ النمط .
في حالتنا، يبلغ حد الخطأ 1 فقط، ولتقليل وقت توقف النظام بسبب انقطاع الشبكة المؤقت، نستخدم إستراتيجية إعادة المحاولة الدقيقة للغاية مع فترات زمن الوصول الصغيرة. قد لا يكون هذا مناسبًا لجميع تطبيقات المجموعة، لذلك يجب تحديد العلاقة بين حد الخطأ وقيمة الفاصل الزمني بناءً على خصائص النظام.
تطبيق منفصل لمعالجة الرسائل من التطبيقات ذات المنطق غير الحتمي
فيما يلي مثال للتعليمة البرمجية التي ترسل رسالة إلى هذا التطبيق (Retryer)، والتي سيتم إعادة إرسالها إلى موضوع DESTINATION عند الوصول إلى وقت RETRY_AT:
public <K, V> void retry(ConsumerRecord<K, V> record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List<Header> arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord<K, V> messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
}يوضح المثال أن الكثير من المعلومات يتم نقلها في الرؤوس. تم العثور على قيمة RETRY_AT بنفس الطريقة المستخدمة في آلية إعادة المحاولة من خلال توقف المستهلك. بالإضافة إلى DESTINATION وRETRY_AT، نمرر:
- GROUP_ID، والذي من خلاله نقوم بتجميع الرسائل للتحليل اليدوي والبحث المبسط.
- ORIGINAL_PARTITION لمحاولة الاحتفاظ بنفس المستهلك لإعادة المعالجة. يمكن أن تكون هذه المعلمة فارغة، وفي هذه الحالة سيتم الحصول على القسم الجديد باستخدام مفتاح السجل.key() للرسالة الأصلية.
- تم تحديث قيمة COUNTER لمتابعة استراتيجية إعادة المحاولة.
- SEND_TO هو ثابت يشير إلى ما إذا كانت الرسالة قد تم إرسالها لإعادة المعالجة عند الوصول إلى RETRY_AT أو تم وضعها في DLQ.
- السبب - سبب مقاطعة معالجة الرسائل.
يقوم Retryer بتخزين الرسائل لإعادة إرسالها وتحليلها يدويًا في PostgreSQL. يبدأ المؤقت مهمة تبحث عن الرسائل ذات RETRY_AT وترسلها مرة أخرى إلى قسم ORIGINAL_PARTITION لموضوع DESTINATION باستخدام المفتاح Record.key().
بمجرد إرسالها، يتم حذف الرسائل من PostgreSQL. يحدث التحليل اليدوي للرسائل في واجهة مستخدم بسيطة تتفاعل مع Retryer عبر REST API. ميزاته الرئيسية هي إعادة إرسال الرسائل أو حذفها من DLQ، وعرض معلومات الخطأ والبحث عن الرسائل، على سبيل المثال عن طريق اسم الخطأ.
نظرًا لتمكين التحكم في الوصول في مجموعاتنا، فمن الضروري أيضًا طلب الوصول إلى الموضوع الذي يستمع إليه Retryer، والسماح لـ Retryer بالكتابة إلى موضوع DESTINATION. هذا أمر غير مريح، ولكن، على عكس نهج الموضوع الفاصل، لدينا DLQ وواجهة مستخدم كاملة لإدارته.
هناك حالات تتم فيها قراءة موضوع وارد من قبل عدة مجموعات مختلفة من المستهلكين، الذين تطبق تطبيقاتهم منطقًا مختلفًا. ستؤدي إعادة معالجة الرسالة من خلال Retryer لأحد هذه التطبيقات إلى ظهور نسخة مكررة من التطبيق الآخر. وللحماية من ذلك، نقوم بإنشاء موضوع منفصل لإعادة المعالجة. يمكن لنفس المستهلك قراءة المواضيع الواردة وإعادة المحاولة دون أي قيود.
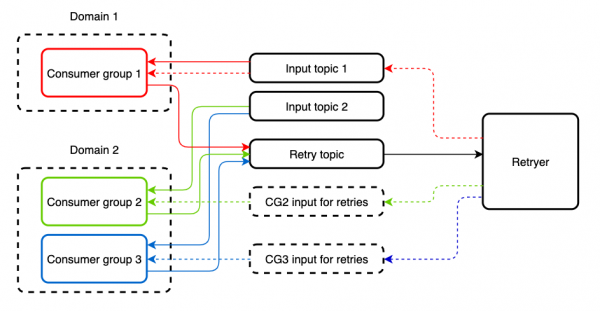
بشكل افتراضي، لا يوفر هذا الأسلوب وظيفة قاطع الدائرة، ولكن يمكن إضافتها إلى التطبيق باستخدام أو جديد ، وتغليف الأماكن التي يتم فيها استدعاء الخدمات الخارجية في التجريدات المناسبة. وبالإضافة إلى ذلك، يصبح من الممكن اختيار استراتيجية ل النمط، والذي يمكن أن يكون مفيدًا أيضًا. على سبيل المثال، في Spring-cloud-netflix، يمكن أن يكون هذا عبارة عن تجمع خيوط أو إشارة.
إنتاج
ونتيجة لذلك، أصبح لدينا تطبيق منفصل يسمح لنا بتكرار معالجة الرسائل في حالة عدم توفر أي نظام خارجي مؤقتًا.
إحدى المزايا الرئيسية للتطبيق هي أنه يمكن استخدامه من قبل الأنظمة الخارجية التي تعمل على نفس مجموعة كافكا، دون تعديلات كبيرة من جانبها! سيحتاج مثل هذا التطبيق فقط إلى الوصول إلى موضوع إعادة المحاولة، وملء بعض رؤوس كافكا وإرسال رسالة إلى مُعيد المحاولة. ليست هناك حاجة لرفع أي بنية تحتية إضافية. ومن أجل تقليل عدد الرسائل المنقولة من التطبيق إلى Retryer والعودة، قمنا بتحديد التطبيقات ذات المنطق الخطي وأعدنا معالجتها من خلال توقف المستهلك.
المصدر: www.habr.com
