


يعد Kube-scheduler جزءًا لا يتجزأ من Kubernetes، وهو المسؤول عن جدولة البودات عبر العقد وفقًا للسياسات المحددة. في كثير من الأحيان، أثناء تشغيل مجموعة Kubernetes، لا يتعين علينا التفكير في السياسات المستخدمة لجدولة القرون، نظرًا لأن مجموعة سياسات جدولة kube الافتراضية مناسبة لمعظم المهام اليومية. ومع ذلك، هناك حالات عندما يكون من المهم بالنسبة لنا ضبط عملية تخصيص البودات، وهناك طريقتان لإنجاز هذه المهمة:
- قم بإنشاء برنامج جدولة kube بمجموعة مخصصة من القواعد
- اكتب المجدول الخاص بك وقم بتعليمه كيفية العمل مع طلبات خادم API
في هذه المقالة سأصف تنفيذ النقطة الأولى لحل مشكلة الجدولة غير المتساوية للمواقد في أحد مشاريعنا.
مقدمة مختصرة عن كيفية عمل برنامج kube-scheduler
تجدر الإشارة بشكل خاص إلى حقيقة أن kube-scheduler ليس مسؤولاً عن جدولة البودات بشكل مباشر - فهو مسؤول فقط عن تحديد العقدة التي سيتم وضع البود عليها. بمعنى آخر، نتيجة عمل kube-scheduler هي اسم العقدة، التي تعيدها إلى خادم API لطلب جدولة، وهنا ينتهي عملها.
أولاً، يقوم kube-scheduler بتجميع قائمة بالعقد التي يمكن جدولة الكبسولة عليها وفقًا لسياسات المسندات. بعد ذلك، تحصل كل عقدة من هذه القائمة على عدد معين من النقاط وفقًا لسياسات الأولويات. ونتيجة لذلك، يتم تحديد العقدة مع الحد الأقصى لعدد النقاط. إذا كانت هناك عقد لها نفس الحد الأقصى من النقاط، فسيتم تحديد عقد عشوائي. يمكن العثور على قائمة ووصف لسياسات المسندات (التصفية) والأولويات (تسجيل النقاط) في .
وصف الجسم المشكلة
على الرغم من العدد الكبير من مجموعات Kubernetes المختلفة التي تتم صيانتها في Nixys، فقد واجهنا مشكلة جدولة الكبسولات لأول مرة مؤخرًا فقط، عندما احتاج أحد مشاريعنا إلى تشغيل عدد كبير من المهام الدورية (حوالي 100 كيان CronJob). لتبسيط وصف المشكلة قدر الإمكان، سنأخذ كمثال خدمة صغيرة واحدة، حيث يتم إطلاق مهمة cron مرة واحدة في الدقيقة، مما يؤدي إلى بعض التحميل على وحدة المعالجة المركزية. لتشغيل مهمة cron، تم تخصيص ثلاث عقد ذات خصائص متطابقة تمامًا (24 وحدة معالجة مركزية افتراضية لكل منها).
في الوقت نفسه، من المستحيل تحديد المدة التي سيستغرقها تنفيذ CronJob بدقة، نظرًا لأن حجم بيانات الإدخال يتغير باستمرار. في المتوسط، أثناء التشغيل العادي لبرنامج جدولة kube، تقوم كل عقدة بتشغيل 3-4 مثيلات مهمة، مما يؤدي إلى إنشاء ~20-30% من الحمل على وحدة المعالجة المركزية لكل عقدة:
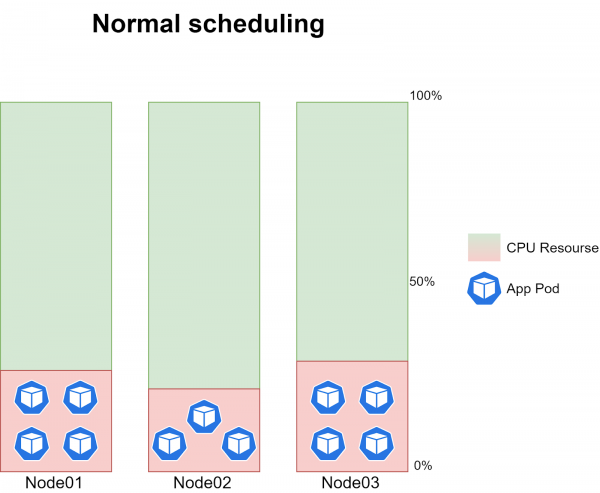
المشكلة نفسها هي أنه في بعض الأحيان تتوقف جدولة مهام cron على إحدى العقد الثلاث. أي أنه في وقت ما، لم يتم التخطيط لحجرة واحدة لإحدى العقد، بينما تم تشغيل 6-8 نسخ من المهمة في العقدتين الأخريين، مما أدى إلى إنشاء 40-60% تقريبًا من حمل وحدة المعالجة المركزية:
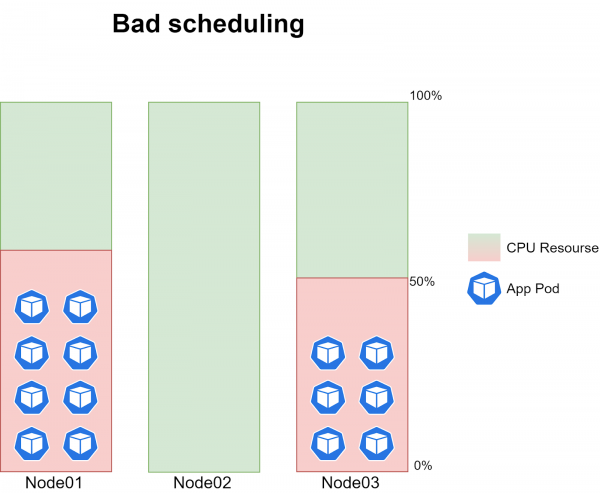
تكررت المشكلة بتكرار عشوائي تمامًا وارتبطت أحيانًا باللحظة التي تم فيها طرح نسخة جديدة من الكود.
من خلال زيادة مستوى تسجيل جدولة kube إلى المستوى 10 (-v=10)، بدأنا في تسجيل عدد النقاط التي اكتسبتها كل عقدة أثناء عملية التقييم. أثناء عملية التخطيط العادية، يمكن رؤية المعلومات التالية في السجلات:
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1387 millicores 4161694720 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1347 millicores 4444810240 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1387 millicores 4161694720 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1687 millicores 4790840320 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1347 millicores 4444810240 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1687 millicores 4790840320 memory bytes, score 9
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: NodeAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node01: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: TaintTolerationPriority, Score: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node02: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node01: SelectorSpreadPriority, Score: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node03: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node02: SelectorSpreadPriority, Score: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:781] Host Node01 => Score 100043
generic_scheduler.go:781] Host Node02 => Score 100043
generic_scheduler.go:781] Host Node03 => Score 100043أولئك. بناءً على المعلومات التي تم الحصول عليها من السجلات، سجلت كل عقدة عددًا متساويًا من النقاط النهائية وتم اختيار نقطة عشوائية للتخطيط. في وقت التخطيط الإشكالي، كانت السجلات تبدو كما يلي:
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1587 millicores 4581125120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1087 millicores 3532549120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1587 millicores 4581125120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 987 millicores 3322833920 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 987 millicores 3322833920 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1087 millicores 3532549120 memory bytes, score 9
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node03: InterPodAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node02: InterPodAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node01: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node03: SelectorSpreadPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: TaintTolerationPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:781] Host Node03 => Score 100041
generic_scheduler.go:781] Host Node02 => Score 100041
generic_scheduler.go:781] Host Node01 => Score 100038ومنه يتبين أن إحدى العقد سجلت نقاطًا نهائية أقل من العقد الأخرى، وبالتالي تم التخطيط فقط للعقدتين اللتين سجلتا الحد الأقصى من النقاط. وهكذا تأكدنا يقيناً أن المشكلة تكمن بالتحديد في جدولة البودات.
كانت الخوارزمية الإضافية لحل المشكلة واضحة بالنسبة لنا - تحليل السجلات، وفهم الأولوية التي لم تسجل العقدة نقاطًا، وإذا لزم الأمر، قم بضبط سياسات جدولة kube الافتراضية. ولكننا هنا نواجه صعوبتين مهمتين:
- عند الحد الأقصى لمستوى التسجيل (10)، تنعكس النقاط المكتسبة لبعض الأولويات فقط. في مقتطف السجلات أعلاه، يمكنك أن ترى أنه بالنسبة لجميع الأولويات المنعكسة في السجلات، تسجل العقد نفس عدد النقاط في الجدولة العادية والجدولة المشكلة، ولكن النتيجة النهائية في حالة تخطيط المشكلة مختلفة. وبالتالي، يمكننا أن نستنتج أنه بالنسبة لبعض الأولويات، يتم تسجيل النقاط "خلف الكواليس"، وليس لدينا طريقة لفهم الأولوية التي لم تحصل العقدة على نقاط بشأنها. لقد وصفنا هذه المشكلة بالتفصيل في مستودع Kubernetes على جيثب. في وقت كتابة هذا التقرير، تم تلقي رد من المطورين يفيد بأنه سيتم إضافة دعم التسجيل في تحديثات Kubernetes v1.15,1.16 و1.17 وXNUMX.
- لا توجد طريقة سهلة لفهم مجموعة السياسات المحددة التي يعمل عليها kube-scheduler حاليًا. نعم في تم إدراج هذه القائمة، ولكنها لا تحتوي على معلومات حول الأوزان المحددة المخصصة لكل سياسة من سياسات الأولويات. يمكنك رؤية الأوزان أو تحرير سياسات برنامج جدولة kube الافتراضي فقط في .
تجدر الإشارة إلى أنه بمجرد أن تمكنا من تسجيل أن العقدة لم تتلق نقاطًا وفقًا لسياسة ImageLocalityPriority، التي تمنح النقاط للعقدة إذا كانت لديها بالفعل الصورة اللازمة لتشغيل التطبيق. أي أنه في الوقت الذي تم فيه طرح إصدار جديد من التطبيق، تمكنت مهمة cron من العمل على عقدتين، وتنزيل صورة جديدة من سجل عامل الإرساء إليهما، وبالتالي حصلت العقدتان على درجة نهائية أعلى مقارنة بالعقدة الثالثة .
كما كتبت أعلاه، لا نرى في السجلات معلومات حول تقييم سياسة ImageLocalityPriority، لذا من أجل التحقق من افتراضنا، قمنا بإلقاء الصورة مع الإصدار الجديد من التطبيق على العقدة الثالثة، وبعد ذلك عملت الجدولة بشكل صحيح . كان ذلك على وجه التحديد بسبب سياسة ImageLocalityPriority التي نادرًا ما تمت ملاحظة مشكلة الجدولة فيها، وفي أغلب الأحيان كانت مرتبطة بشيء آخر. نظرًا لحقيقة أننا لم نتمكن من تصحيح الأخطاء بشكل كامل لكل السياسات الموجودة في قائمة أولويات برنامج جدولة kube الافتراضي، فقد كنا بحاجة إلى إدارة مرنة لسياسات جدولة الكبسولة.
صياغة المشكلة
أردنا أن يكون حل المشكلة محددًا قدر الإمكان، أي أن الكيانات الرئيسية لـ Kubernetes (هنا نعني جدولة kube الافتراضية) يجب أن تظل دون تغيير. لم نرغب في حل مشكلة في مكان وخلقها في مكان آخر. وهكذا توصلنا إلى خيارين لحل المشكلة تم الإعلان عنهما في مقدمة المقال - إنشاء برنامج جدولة إضافي أو كتابة برنامج جدولة خاص بك. الشرط الرئيسي لجدولة مهام cron هو توزيع الحمل بالتساوي عبر ثلاث عقد. يمكن تلبية هذا المطلب من خلال سياسات جدولة kube الحالية، لذا لحل مشكلتنا ليس هناك فائدة من كتابة برنامج جدولة خاص بك.
تم توضيح تعليمات إنشاء ونشر برنامج جدولة kube إضافي في . ومع ذلك، بدا لنا أن كيان النشر لم يكن كافيًا لضمان التسامح مع الأخطاء في تشغيل مثل هذه الخدمة المهمة مثل kube-scheduler، لذلك قررنا نشر أداة جدولة kube جديدة باعتبارها حجرة ثابتة، والتي سيتم مراقبتها مباشرة بواسطة كوبليت. وبالتالي، لدينا المتطلبات التالية لبرنامج جدولة kube الجديد:
- يجب نشر الخدمة كـ Static Pod على كافة أنظمة المجموعة الرئيسية
- يجب توفير التسامح مع الخطأ في حالة عدم توفر الكبسولة النشطة المزودة ببرنامج جدولة kube
- يجب أن تكون الأولوية الرئيسية عند التخطيط هي عدد الموارد المتاحة على العقدة (LeastRequestedPriority)
حلول التنفيذ
تجدر الإشارة على الفور إلى أننا سننفذ جميع الأعمال في الإصدار 1.14.7 من Kubernetes، لأنه هذه هي النسخة التي تم استخدامها في المشروع. لنبدأ بكتابة بيان لمجدول kube الجديد الخاص بنا. لنأخذ البيان الافتراضي (/etc/kubernetes/manifests/kube-scheduler.yaml) كأساس ونحضره إلى النموذج التالي:
kind: Pod
metadata:
labels:
component: scheduler
tier: control-plane
name: kube-scheduler-cron
namespace: kube-system
spec:
containers:
- command:
- /usr/local/bin/kube-scheduler
- --address=0.0.0.0
- --port=10151
- --secure-port=10159
- --config=/etc/kubernetes/scheduler-custom.conf
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --v=2
image: gcr.io/google-containers/kube-scheduler:v1.14.7
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10151
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
name: kube-scheduler-cron-container
resources:
requests:
cpu: '0.1'
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kube-config
readOnly: true
- mountPath: /etc/localtime
name: localtime
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom.conf
name: scheduler-config
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom-policy-config.json
name: policy-config
readOnly: true
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kube-config
- hostPath:
path: /etc/localtime
name: localtime
- hostPath:
path: /etc/kubernetes/scheduler-custom.conf
type: FileOrCreate
name: scheduler-config
- hostPath:
path: /etc/kubernetes/scheduler-custom-policy-config.json
type: FileOrCreate
name: policy-configباختصار حول التغييرات الرئيسية:
- تم تغيير اسم البود والحاوية إلى kube-scheduler-cron
- تم تحديد استخدام المنفذين 10151 و10159 كما تم تعريف الخيار
hostNetwork: trueولا يمكننا استخدام نفس المنافذ مثل برنامج جدولة kube الافتراضي (10251 و10259) - باستخدام المعلمة --config، حددنا ملف التكوين الذي يجب أن تبدأ الخدمة به
- التركيب المكوّن لملف التكوين (scheduler-custom.conf) وملف سياسة الجدولة (scheduler-custom-policy-config.json) من المضيف
لا تنس أن برنامج جدولة kube الخاص بنا سيحتاج إلى حقوق مشابهة لتلك الافتراضية. تحرير دور المجموعة الخاصة به:
kubectl edit clusterrole system:kube-scheduler...
resourceNames:
- kube-scheduler
- kube-scheduler-cron
...لنتحدث الآن عما يجب أن يتضمنه ملف التكوين وملف سياسة الجدولة:
- ملف التكوين (scheduler-custom.conf)
للحصول على التكوين الافتراضي لجدولة kube، يجب عليك استخدام المعلمة--write-config-toمن . سنضع التكوين الناتج في الملف /etc/kubernetes/scheduler-custom.conf ونختصره إلى النموذج التالي:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
schedulerName: kube-scheduler-cron
bindTimeoutSeconds: 600
clientConnection:
acceptContentTypes: ""
burst: 100
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/scheduler.conf
qps: 50
disablePreemption: false
enableContentionProfiling: false
enableProfiling: false
failureDomains: kubernetes.io/hostname,failure-domain.beta.kubernetes.io/zone,failure-domain.beta.kubernetes.io/region
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: 0.0.0.0:10151
leaderElection:
leaderElect: true
leaseDuration: 15s
lockObjectName: kube-scheduler-cron
lockObjectNamespace: kube-system
renewDeadline: 10s
resourceLock: endpoints
retryPeriod: 2s
metricsBindAddress: 0.0.0.0:10151
percentageOfNodesToScore: 0
algorithmSource:
policy:
file:
path: "/etc/kubernetes/scheduler-custom-policy-config.json"باختصار حول التغييرات الرئيسية:
- لقد قمنا بتعيين اسم الجدولة على اسم خدمة kube-scheduler-cron الخاصة بنا.
- في المعلمة
lockObjectNameتحتاج أيضًا إلى تعيين اسم خدمتنا والتأكد من أن المعلمةleaderElectتم ضبطه على "صحيح" (إذا كان لديك عقدة رئيسية واحدة، فيمكنك ضبطها على "خطأ"). - حدد المسار إلى الملف مع وصف لسياسات الجدولة في المعلمة
algorithmSource.
يجدر إلقاء نظرة فاحصة على النقطة الثانية، حيث نقوم بتحرير معلمات المفتاح leaderElection. لضمان التسامح مع الخطأ، قمنا بتمكين (leaderElect) عملية اختيار القائد (الرئيسي) بين وحدات جدولة kube الخاصة بنا باستخدام نقطة نهاية واحدة لها (resourceLock) اسمه kube-Scheduler-cron (lockObjectName) في مساحة اسم نظام kube (lockObjectNamespace). يمكن الاطلاع على كيفية ضمان Kubernetes للتوفر العالي للمكونات الرئيسية (بما في ذلك برنامج جدولة kube) في .
- ملف سياسة الجدولة (scheduler-custom-policy-config.json)
كما كتبت سابقًا، يمكننا معرفة السياسات المحددة التي يعمل معها برنامج جدولة kube الافتراضي فقط من خلال تحليل الكود الخاص به. أي أننا لا نستطيع الحصول على ملف به سياسات جدولة لبرنامج جدولة kube الافتراضي بنفس طريقة الحصول على ملف التكوين. دعنا نصف سياسات الجدولة التي نهتم بها في الملف /etc/kubernetes/scheduler-custom-policy-config.json كما يلي:
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{
"name": "GeneralPredicates"
}
],
"priorities": [
{
"name": "ServiceSpreadingPriority",
"weight": 1
},
{
"name": "EqualPriority",
"weight": 1
},
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "NodePreferAvoidPodsPriority",
"weight": 10000
},
{
"name": "NodeAffinityPriority",
"weight": 1
}
],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}وبالتالي، يقوم kube-scheduler أولاً بتجميع قائمة العقد التي يمكن جدولة الكبسولة إليها وفقًا لسياسة GeneralPredicates (والتي تتضمن مجموعة سياسات PodFitsResources، وPodFitsHostPorts، وHostName، وMatchNodeSelector). ومن ثم يتم تقييم كل عقدة وفقًا لمجموعة السياسات في مصفوفة الأولويات. ولتنفيذ شروط مهمتنا، رأينا أن مثل هذه المجموعة من السياسات ستكون الحل الأمثل. واسمحوا لي أن أذكركم أن مجموعة السياسات مع وصفها التفصيلي متوفرة في . لإنجاز مهمتك، يمكنك ببساطة تغيير مجموعة السياسات المستخدمة وتعيين الأوزان المناسبة لها.
دعنا نطلق على بيان جدولة kube الجديد، الذي أنشأناه في بداية الفصل، kube-scheduler-custom.yaml ونضعه في المسار التالي /etc/kubernetes/manifests على ثلاث عقد رئيسية. إذا تم كل شيء بشكل صحيح، فسيطلق Kubelet حجرة على كل عقدة، وفي سجلات جدولة kube الجديدة لدينا، سنرى معلومات تفيد بأنه تم تطبيق ملف السياسة الخاص بنا بنجاح:
Creating scheduler from configuration: {{ } [{GeneralPredicates <nil>}] [{ServiceSpreadingPriority 1 <nil>} {EqualPriority 1 <nil>} {LeastRequestedPriority 1 <nil>} {NodePreferAvoidPodsPriority 10000 <nil>} {NodeAffinityPriority 1 <nil>}] [] 10 false}
Registering predicate: GeneralPredicates
Predicate type GeneralPredicates already registered, reusing.
Registering priority: ServiceSpreadingPriority
Priority type ServiceSpreadingPriority already registered, reusing.
Registering priority: EqualPriority
Priority type EqualPriority already registered, reusing.
Registering priority: LeastRequestedPriority
Priority type LeastRequestedPriority already registered, reusing.
Registering priority: NodePreferAvoidPodsPriority
Priority type NodePreferAvoidPodsPriority already registered, reusing.
Registering priority: NodeAffinityPriority
Priority type NodeAffinityPriority already registered, reusing.
Creating scheduler with fit predicates 'map[GeneralPredicates:{}]' and priority functions 'map[EqualPriority:{} LeastRequestedPriority:{} NodeAffinityPriority:{} NodePreferAvoidPodsPriority:{} ServiceSpreadingPriority:{}]'الآن كل ما تبقى هو الإشارة في مواصفات CronJob إلى أن جميع طلبات جدولة البودات الخاصة بها يجب أن تتم معالجتها بواسطة برنامج جدولة kube الجديد الخاص بنا:
...
jobTemplate:
spec:
template:
spec:
schedulerName: kube-scheduler-cron
...اختتام
في النهاية، حصلنا على برنامج جدولة kube إضافي مع مجموعة فريدة من سياسات الجدولة، والتي تتم مراقبة عملها مباشرة بواسطة kubelet. بالإضافة إلى ذلك، قمنا بإعداد انتخاب قائد جديد بين حجرات برنامج جدولة kube الخاص بنا في حالة عدم توفر القائد القديم لسبب ما.
تستمر جدولة التطبيقات والخدمات العادية من خلال برنامج جدولة kube الافتراضي، وتم نقل جميع مهام cron بالكامل إلى المهمة الجديدة. يتم الآن توزيع الحمل الذي تم إنشاؤه بواسطة مهام cron بالتساوي عبر جميع العقد. وبالنظر إلى أن معظم مهام cron يتم تنفيذها على نفس العقد مثل التطبيقات الرئيسية للمشروع، فقد أدى ذلك إلى تقليل مخاطر نقل القرون بشكل كبير بسبب نقص الموارد. بعد تقديم برنامج جدولة kube الإضافي، لم تعد هناك مشاكل تتعلق بالجدولة غير المتساوية لمهام cron.
اقرأ أيضًا مقالات أخرى على مدونتنا:
المصدر: www.habr.com
