

بشكل دوري ، تنشأ مهمة البحث عن البيانات ذات الصلة بواسطة مجموعة من المفاتيح ، حتى نحصل على العدد الإجمالي المطلوب من السجلات.
يتم عرض أكثر الأمثلة "واقعية" أقدم 20 مشكلة، المدرجة على قائمة الموظفين (على سبيل المثال ، داخل نفس القسم). بالنسبة إلى "لوحات المعلومات" الإدارية المختلفة التي تحتوي على ملخصات موجزة لمجالات العمل ، فإن موضوعًا مشابهًا مطلوب في كثير من الأحيان.

في هذه المقالة ، سننظر في تطبيق نسخة "ساذجة" من حل مثل هذه المشكلة على PostgreSQL ، وهي خوارزمية "أكثر ذكاءً" ومعقدة جدًا "حلقة" في SQL مع شرط الخروج من البيانات التي تم العثور عليها، والتي يمكن أن تكون مفيدة للتطوير العام وللاستخدام في حالات أخرى مماثلة.
لنأخذ مجموعة بيانات اختبار من . حتى لا "تقفز" سجلات الإخراج من وقت لآخر عندما تتطابق القيم التي تم فرزها ، تمديد فهرس الموضوع عن طريق إضافة مفتاح أساسي. في الوقت نفسه ، هذا سيمنحها على الفور تفردًا ، ويضمن لنا تفرد ترتيب الفرز:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;كما يسمع هكذا هو مكتوب
أولاً ، دعنا نرسم أبسط نسخة من الطلب ، ونمرر معرفات فناني الأداء :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
حزين بعض الشيء - لقد طلبنا 20 سجلاً فقط ، وأعادنا فحص الفهرس خطوط 960، والتي كان لابد من ترتيبها بعد ذلك ... ودعونا نحاول قراءة أقل.
unnest + صفيف
الاعتبار الأول الذي سيساعدنا - إذا احتجنا مجموع 20 مرتبة السجلات ، يكفي أن تقرأ ما لا يزيد عن 20 مرتبة في نفس الترتيب لكل منها مفتاح. جيد، مؤشر مناسب (owner_id ، task_date ، id) لدينا.
لنستخدم نفس آلية الاستخراج و "التحويل إلى أعمدة" دخول جدول متكامل، مثل . وأيضًا تطبيق الالتفاف على مصفوفة باستخدام الوظيفة ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 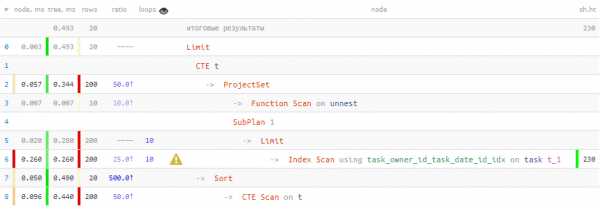
أوه ، إنه بالفعل أفضل بكثير! 40٪ بيانات أسرع و 4.5 مرات أقل اضطررت للقراءة.
تجسيد سجلات الجدول عبر CTEسوف ألاحظ ذلك في بعض الحالات يمكن أن تؤدي محاولة العمل على الفور مع حقول السجل بعد البحث عنها في استعلام فرعي ، بدون "التفاف" في CTE ، إلى "الضرب" InitPlan يتناسب مع عدد هذه الحقول نفسها:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
تم "البحث" في السجل نفسه 4 مرات ... حتى PostgreSQL 11 ، كان هذا السلوك يحدث بانتظام ، والحل هو "الالتفاف" في CTE ، وهو حد غير مشروط للمحسن في هذه الإصدارات.
تراكم عودي
في الإصدار السابق ، في المجموع ، نقرأ خطوط 200 من أجل 20 ضروريًا. ليس بالفعل 960 ، ولكن حتى أقل - هل هذا ممكن؟
دعنا نحاول استخدام المعرفة التي نحتاجها إجمالي xnumx السجلات. أي أننا سنكرر طرح البيانات فقط حتى يتم الوصول إلى المقدار الذي نحتاجه.
الخطوة 1: قائمة البداية
من الواضح أن قائمتنا "الهدف" المكونة من 20 إدخالًا يجب أن تبدأ بالإدخالات "الأولى" لأحد مفاتيح معرفات المالك. لذلك ، نجد أولًا مثل هذا "الأول" لكل مفتاح ووضعها في القائمة ، وفرزها بالترتيب الذي نريده - (تاريخ_المعرفة ، معرف).
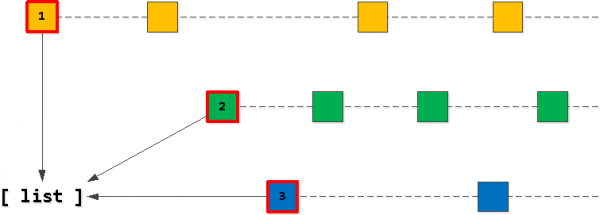
الخطوة 2: ابحث عن السجلات "التالية"
الآن إذا أخذنا الإدخال الأول من قائمتنا وبدأنا "خطوة" أسفل الفهرس مع حفظ owner_id-key ، فإن جميع السجلات التي تم العثور عليها هي فقط السجلات التالية في التحديد الناتج. طبعا فقط حتى نعبر المفتاح المطبق الإدخال الثاني في القائمة.
إذا اتضح أننا "تجاوزنا" الإدخال الثاني ، إذن يجب إضافة إدخال القراءة الأخير إلى القائمة بدلاً من الأول (مع نفس owner_id) ، وبعد ذلك يتم فرز القائمة مرة أخرى.
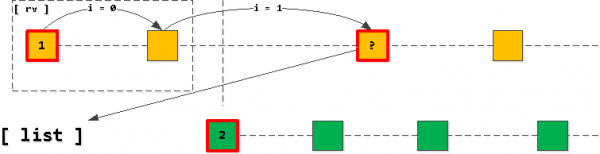
أي أننا نحصل دائمًا على أن القائمة لا تحتوي على أكثر من إدخال واحد لكل مفتاح من المفاتيح (إذا انتهت الإدخالات ولم يتم "تجاوزها" ، فسيختفي الإدخال الأول ببساطة من القائمة ولن تتم إضافة أي شيء )، و هم دائما مرتبة بترتيب تصاعدي لمفتاح التطبيق (task_date ، id).
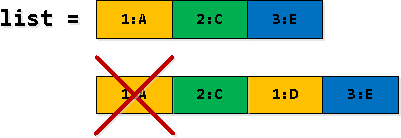
الخطوة 3: تصفية السجلات وتوسيعها
في جزء من صفوف اختيارنا العودي ، بعض السجلات rv مكررة - نجد أولاً مثل "عبور حدود الإدخال الثاني من القائمة" ، ثم نستبدلها بالأول من القائمة. وبالتالي يجب تصفية التكرار الأول.
الاستعلام النهائي الرهيب
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 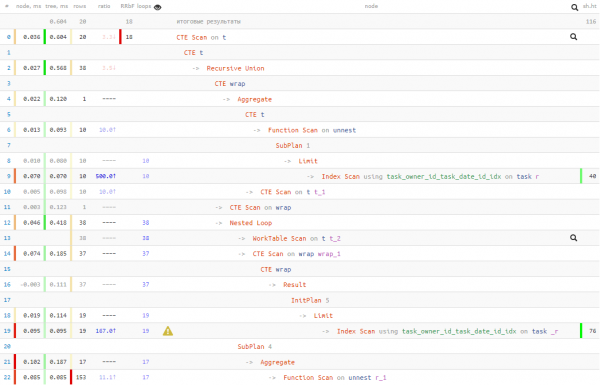
هكذا نحن تداول 50٪ من قراءات البيانات لمدة 20٪ من وقت التنفيذ. أي ، إذا كان لديك سبب للاعتقاد بأن القراءة يمكن أن تكون طويلة (على سبيل المثال ، غالبًا ما لا تكون البيانات في ذاكرة التخزين المؤقت ، وعليك أن تذهب إلى القرص من أجلها) ، فبهذه الطريقة يمكنك الاعتماد على قراءة أقل.
على أي حال ، كان وقت التنفيذ أفضل مما كان عليه في الخيار الأول "الساذج". ولكن اختيار أي من هذه الخيارات الثلاثة يعود إليك.
المصدر: www.habr.com
