


تواجهك مهمة اكتشاف الأشياء مرة أخرى. الأولوية هي سرعة التشغيل مع الدقة المقبولة. تأخذ بنية YOLOv3 وتقوم بتدريبها بشكل أكبر. الدقة (mAp75) أكبر من 0.95. ولكن سرعة الجري لا تزال منخفضة. هراء.
اليوم سوف نتجاوز التكميم. دعونا نلقي نظرة تحت القطع نموذج التقليم - تقليم الأجزاء الزائدة من الشبكة لتسريع الاستدلال دون فقدان الدقة. بوضوح - أين، وبأي قدر، وكيف يمكنك القطع. دعونا نلقي نظرة على كيفية القيام بذلك يدويًا وأين يمكن أن يتم أتمتته. في النهاية يوجد مستودع keras.
مقدمة
في وظيفتي السابقة، Macroscop في بيرم، اكتسبت عادة واحدة: مراقبة وقت تنفيذ الخوارزميات دائمًا. وتأكد دائمًا من وقت تشغيل الشبكة من خلال مرشح الكفاية. عادةً لا تجتاز أحدث التقنيات في الإنتاج هذا الفلتر، وهو ما قادني إلى التقليم.
التقليم هو موضوع قديم تمت مناقشته في في عام 2017. الفكرة الرئيسية هي تقليل حجم الشبكة المدربة دون فقدان الدقة عن طريق إزالة العقد المختلفة. يبدو رائعًا، لكنني نادرًا ما أسمع عن استخدامه. ربما لا يوجد ما يكفي من التنفيذات، أو لا توجد مقالات باللغة الروسية، أو أن الجميع يعتبرون مجرد تقليم المعرفة ويلتزمون الصمت.
ولكن من الصعب معرفة ذلك
نظرة في علم الأحياء
أنا أحب ذلك عندما تأتي الأفكار من علم الأحياء إلى التعلم العميق. إنهم، مثل التطور، يمكن الوثوق بهم (وهل تعلم أن ReLU مشابه جدًا لـ ?)
تعتبر عملية التقليم النموذجي أيضًا قريبة من علم الأحياء. ويمكن مقارنة استجابة الشبكة هنا بمرونة الدماغ. هناك بعض الأمثلة المثيرة للاهتمام في الكتاب. :
- دماغ امرأة ولدت بنصف دماغ فقط أعاد برمجة نفسه للقيام بوظائف النصف المفقود.
- أطلق الرجل النار على الجزء من دماغه المسؤول عن الرؤية. وبمرور الوقت، تولت أجزاء أخرى من الدماغ هذه الوظائف. (نحن لا نحاول التكرار)
وبنفس الطريقة، يمكنك قطع بعض الطيات الضعيفة من نموذجك. في الحالات القصوى، يمكن استخدام اللفائف المتبقية لتحل محل اللفائف المقطوعة.
هل تحب التعلم الانتقالي أم تتعلم من الصفر؟
الخيار رقم واحد. أنت تستخدم Transfer Learning على Yolov3. شبكية العين، قناع-RCNN أو U-Net. لكن في أغلب الأحيان لا نحتاج إلى التعرف على 80 فئة من الكائنات كما هو الحال في COCO. في ممارستي، كل شيء يقتصر على درجة أو درجتين. يمكننا أن نفترض أن بنية 1 فئة زائدة عن الحاجة هنا. الفكرة هي أن الهندسة المعمارية تحتاج إلى التقليص. علاوة على ذلك، نود أن نفعل هذا دون أن نفقد الأوزان المدربة مسبقًا.
الخيار الثاني. ربما لديك الكثير من البيانات وموارد الحوسبة، أو تحتاج فقط إلى بنية مخصصة للغاية. لا يهم. لكنك تتعلم الشبكة من الصفر. الإجراء المعتاد هو النظر إلى بنية البيانات، واختيار بنية زائدة عن الحاجة من حيث الطاقة، ودفع عمليات التسرب من الإفراط في التجهيز. لقد رأيت 0.6 من المتسربين، كارل.
في كلتا الحالتين، يمكن تقليص الشبكة. مُحفّز. الآن دعونا نتعرف على ما هو التقليم.
خوارزمية عامة
قررنا أنه بإمكاننا إزالة الحزم. يبدو الأمر بسيطًا جدًا:
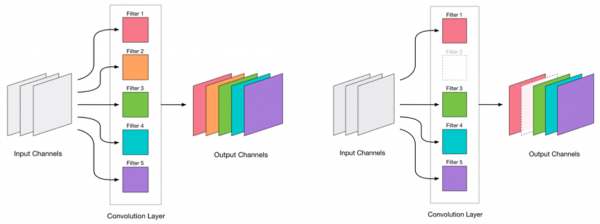
إن إزالة أي التفاف يشكل ضغطًا على الشبكة، مما يؤدي عادةً إلى زيادة في الخطأ. من ناحية أخرى، فإن هذه الزيادة في الخطأ هي مؤشر على مدى نجاحنا في إزالة الالتواءات (على سبيل المثال، تشير الزيادة الكبيرة إلى أننا نفعل شيئًا خاطئًا). ولكن الزيادة الصغيرة مقبولة تمامًا وغالبًا ما يتم التخلص منها عن طريق إعادة تدريب الضوء اللاحق باستخدام LR صغير. أضف خطوة تدريبية أخرى:
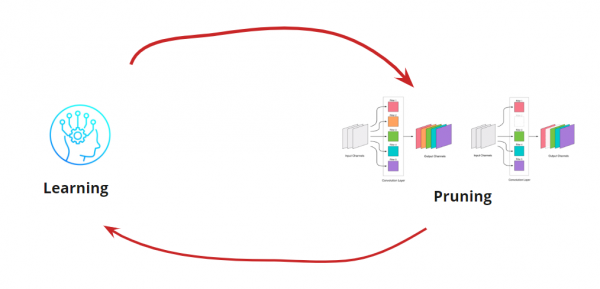
الآن نحتاج إلى معرفة متى نريد إيقاف حلقة التعلم <-> التقليم. قد تكون هناك خيارات غريبة هنا عندما نحتاج إلى تقليل الشبكة إلى حجم معين وسرعة تشغيل (على سبيل المثال، للأجهزة المحمولة). ومع ذلك، فإن الخيار الأكثر شيوعا هو الاستمرار في الدورة حتى يصبح الخطأ أعلى من المستوى المقبول. أضف شرطًا:
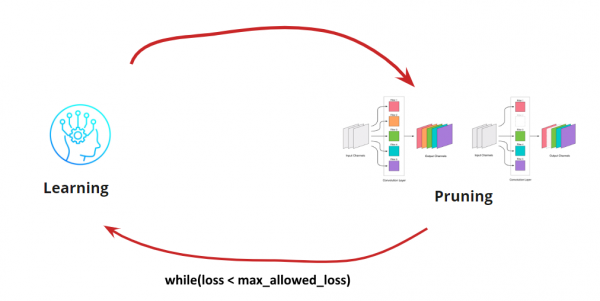
وبذلك تصبح الخوارزمية واضحة. يبقى أن نكتشف كيفية تحديد الطيات التي يجب إزالتها.
البحث عن الحزم القابلة للحذف
نحن بحاجة إلى إزالة بعض الحزم. الاندفاع مباشرة وإطلاق النار على الجميع فكرة سيئة، حتى لو كانت ستنجح. ولكن إذا كان لديك عقل، فيمكنك التفكير ومحاولة تحديد الطيات "الضعيفة" للحذف. هناك عدة خيارات:
- . فكرة أن التلافيف ذات قيم الوزن الصغيرة لا تساهم كثيرًا في القرار النهائي
- أصغر مقياس L1 مع الأخذ في الاعتبار المتوسط والانحراف المعياري. ونستكمل ذلك بتقييم طبيعة التوزيع.
- . اكتشاف أكثر دقة للتفافات غير المهمة، لكنه يستغرق وقتًا طويلاً ويستهلك الكثير من الموارد.
- آخرون
لكل خيار الحق في الوجود وميزات التنفيذ الخاصة به. سننظر هنا في المتغير الذي لديه أصغر مقياس L1
عملية يدوية لـ YOLOv3
يحتوي البناء الأصلي على كتل متبقية. ولكن على الرغم من مدى روعتها بالنسبة للشبكات العميقة، إلا أنها تشكل عائقًا لنا إلى حد ما. تكمن الصعوبة في أنه لا يمكنك حذف التوفيقات مع مؤشرات مختلفة في هذه الطبقات:
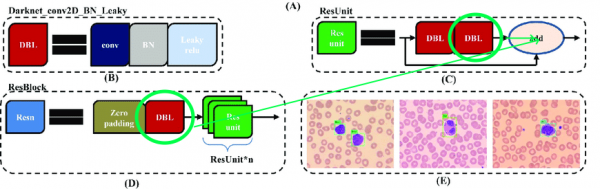
لذلك، دعونا نختار الطبقات التي يمكننا إزالة الاختبارات منها بحرية:

الآن دعونا نبني دورة عمل:
- تفريغ التنشيطات
- دعونا نكتشف مقدار ما يجب قطعه
- لقد قطعنا
- نتعلم 10 عصور مع LR=1e-4
- اختبارات
إن تفريغ الطيات مفيد لتقدير مقدار ما يمكننا إزالته في خطوة معينة. أمثلة على التفريغ:
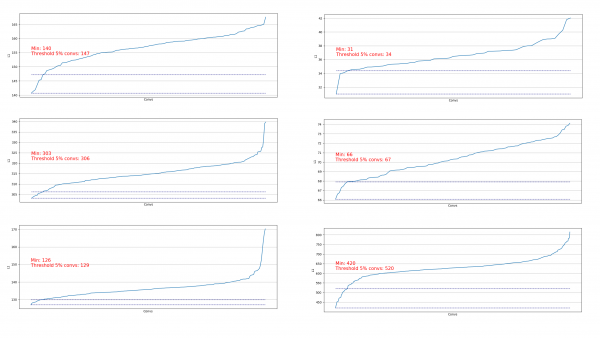
نرى أنه في كل مكان تقريبًا، 5% من التلافيف لها معيار L1 منخفض جدًا ويمكننا إزالتها. في كل خطوة، تم تكرار هذا التفريغ وتم إجراء تقييم للطبقات وكمية ما يمكن قطعه.
استغرقت العملية بأكملها 4 خطوات (هنا وفي كل مكان تكون الأرقام خاصة بـ RTX 2060 Super):
| خطوة | mAp75 | عدد المعلمات، مليون | حجم الشبكة، ميجا بايت | من الأصل، % | وقت التشغيل، مللي ثانية | حالة الختان |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | 5% من الكل |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | 5% من الكل |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15% للطبقات التي تحتوي على أكثر من 400 التفاف |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 10% للطبقات التي تحتوي على أكثر من 100 التفاف |
أضافت الخطوة الثانية تأثيرًا إيجابيًا واحدًا: حجم الدفعة 2 يتناسب مع الذاكرة، مما أدى إلى تسريع عملية التدريب الإضافي بشكل كبير.
في الخطوة 4 توقفت العملية لأن التدريب الإضافي طويل الأمد لم يرفع mAp75 إلى القيم القديمة.
ونتيجة لذلك، تمكنا من تسريع الاستدلال عن طريق 15%، تقليل الحجم بمقدار 35% ولا تفقد الدقة.
الأتمتة للهندسة المعمارية البسيطة
بالنسبة للهندسة المعمارية للشبكة الأكثر بساطة (بدون إضافة مشروطة وتسلسل وكتل متبقية)، من الممكن تمامًا التركيز على معالجة جميع طبقات الالتفاف وأتمتة عملية قطع الالتفافات.
لقد قمت بتنفيذ هذا الخيار .
إنه أمر بسيط: كل ما تحتاجه هو دالة خسارة، ومُحسِّن، ومولدات دفعات:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)إذا لزم الأمر، يمكنك تغيير معلمات التكوين:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}بالإضافة إلى ذلك، تم تنفيذ حد يعتمد على الانحراف المعياري. الهدف هو الحد من جزء العناصر التي تمت إزالتها، باستثناء التلافيف التي تحتوي بالفعل على مقاييس L1 "الكافية":
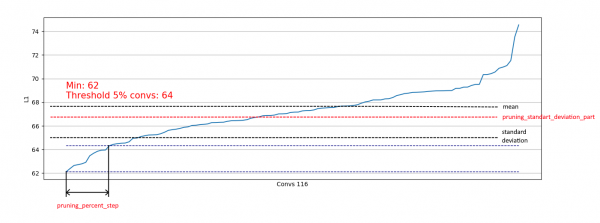
بهذه الطريقة نسمح فقط بإزالة التلافيف الضعيفة من التوزيعات المشابهة للتوزيع الأيمن وعدم التأثير على الإزالة من التوزيعات المشابهة للتوزيع الأيسر:

عندما يقترب التوزيع من الوضع الطبيعي، يمكن تحديد معامل pruning_standart_deviation_part من:
أوصي بالتسامح 2 سيجما. أو يمكنك تجاهل هذه الميزة وترك القيمة < 1.0.
يكون الإخراج عبارة عن رسم بياني لحجم الشبكة والخسارة ووقت تشغيل الشبكة للاختبار بأكمله، مع تطبيعه إلى 1.0. على سبيل المثال، تم هنا تقليص حجم الشبكة بما يقرب من مرتين دون فقدان الجودة (شبكة ملتوية صغيرة تحتوي على 2 ألف وزن):
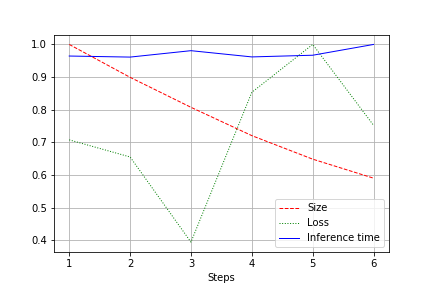
تخضع سرعة الجري لتقلبات طبيعية وتظل دون تغيير تقريبًا. هناك تفسير لذلك:
- يتغير عدد الالتفافات من الملائم (32، 64، 128) إلى غير الملائم لبطاقات الفيديو - 27، 51، وما إلى ذلك. قد أكون مخطئًا هنا، ولكن على الأرجح أن له تأثيرًا.
- الهندسة المعمارية ليست واسعة، ولكنها متسقة. بتقليل العرض، لا نلمس العمق. يؤدي هذا إلى تقليل الحمل، ولكن لا يغير السرعة.
لذلك، تم التعبير عن التحسن في انخفاض حمل CUDA أثناء التشغيل بنسبة 20-30%، ولكن ليس في انخفاض وقت التشغيل.
نتائج
دعونا نفكر. لقد نظرنا إلى خيارين للتقليم - بالنسبة لـ YOLOv2 (عندما يتعين عليك العمل يدويًا) وللشبكات ذات الهندسة المعمارية الأكثر بساطة. ومن الواضح أنه في كلتا الحالتين من الممكن تحقيق تقليل حجم الشبكة وتسريعها دون فقدان الدقة. نتائج:
- تصغير الحجم
- تشغيل التسارع
- تم تقليل حمل CUDA
- ونتيجة لذلك، فإن الصديقة للبيئة (نعمل على تحسين الاستخدام المستقبلي لموارد الحوسبة. في مكان ما يفرح المرء )
الزائدة الدودية
- بعد خطوة التقليم، يمكنك أيضًا تعديل التكميم (على سبيل المثال باستخدام TensorRT)
- يوفر Tensorflow إمكانيات لـ . أعمال.
- أريد أن أتطور وسأكون سعيدًا بالمساعدة
المصدر: www.habr.com
