

نواصل الحديث عن مشاريع هاكاثون الربيع DevDays الذي شارك فيه طلاب برنامج الماجستير .

بالمناسبة، نود أن ندعو القراء للانضمام . وسننشر فيه آخر الأخبار عن التوظيف والدراسة. كما يمكن العثور على فيديو من اليوم المفتوح في المجموعة. نذكركم: سيقام الحدث في 29 أبريل، التفاصيل .
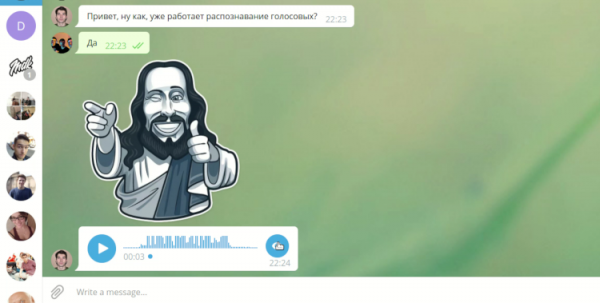
محلل الرسائل الصوتية لسطح المكتب من Telegram
مؤلف الفكرة
خوروشيف أرتيوم
هيكل القيادة
خوروشيف أرتيم – مدير المشروع/المطور/ضمان الجودة
إليسيف أنطون – محلل أعمال/أخصائي تسويق
ماريا كوكلينا – مصممة/مطورة واجهة المستخدم
بخفالوف بافيل – مصمم/مطور واجهة المستخدم/ضمان الجودة
من وجهة نظرنا، يعد Telegram برنامج مراسلة حديث ومريح، وإصدار الكمبيوتر الشخصي الخاص به شائع ومفتوح المصدر، مما يجعل من الممكن تعديله. يقدم العميل وظائف غنية جدًا. بالإضافة إلى الرسائل النصية القياسية، فهو يحتوي على مكالمات صوتية ورسائل فيديو ورسائل صوتية. وهذا الأخير هو الذي يسبب الإزعاج أحيانًا لمتلقيه. ليس من الممكن في كثير من الأحيان الاستماع إلى رسالة صوتية أثناء وجودك على جهاز كمبيوتر أو كمبيوتر محمول. قد تكون هناك ضوضاء محيطة، أو لا توجد سماعات رأس، أو لا تريد أن يسمع أي شخص محتوى الرسالة. لا تنشأ مثل هذه المشكلات أبدًا إذا كنت تستخدم Telegram على هاتف ذكي، لأنه يمكنك ببساطة إيصاله إلى أذنك، على عكس الكمبيوتر المحمول أو الكمبيوتر الشخصي. حاولنا حل هذه المشكلة.
كان الهدف من مشروعنا في DevDays هو إضافة القدرة على ترجمة الرسائل الصوتية المستلمة إلى نص إلى عميل Telegram لسطح المكتب (المشار إليه فيما يلي باسم Telegram Desktop).
جميع نظائرها في الوقت الحالي عبارة عن روبوتات يمكنك إرسال رسالة صوتية إليها وتلقي رسالة نصية ردًا عليها. نحن لسنا سعداء جدًا بهذا: إعادة توجيه الرسالة إلى الروبوت ليس أمرًا مريحًا للغاية، ونرغب في الحصول على وظيفة أصلية. بالإضافة إلى ذلك، فإن أي روبوت هو طرف ثالث يعمل كوسيط بين واجهة برمجة تطبيقات التعرف على الكلام والمستخدم، وهذا على الأقل غير آمن.
كما ذكرنا سابقًا، يتمتع Telegram-desktop بميزتين مهمتين: سهولة التشغيل وسرعته. وهذا ليس من قبيل الصدفة، لأنه مكتوب بالكامل بلغة C++. وبما أننا قررنا إضافة وظائف جديدة مباشرة إلى العميل، كان علينا تطويرها بلغة C++.
 كان هناك 4 أشخاص في فريقنا. في البداية، كان شخصان يبحثان عن مكتبة مناسبة للتعرف على الكلام، وكان أحدهما يدرس الكود المصدري لسطح مكتب Telegram، وكان الآخر ينشر مشروع البناء . وفي وقت لاحق، كان الجميع مشغولين بإصلاح واجهة المستخدم وتصحيح الأخطاء.
كان هناك 4 أشخاص في فريقنا. في البداية، كان شخصان يبحثان عن مكتبة مناسبة للتعرف على الكلام، وكان أحدهما يدرس الكود المصدري لسطح مكتب Telegram، وكان الآخر ينشر مشروع البناء . وفي وقت لاحق، كان الجميع مشغولين بإصلاح واجهة المستخدم وتصحيح الأخطاء.
يبدو أن تنفيذ الوظيفة المقصودة لن يكون صعبا، ولكن، كما يحدث دائما، نشأت الصعوبات.
يتكون حل المشكلة من مهمتين فرعيتين مستقلتين: اختيار أداة مناسبة للتعرف على الكلام وتنفيذ واجهة مستخدم للوظائف الجديدة.
عند اختيار مكتبة للتعرف على الصوت، اضطررنا على الفور إلى التخلي عن جميع واجهات برمجة التطبيقات غير المتصلة بالإنترنت، لأن نماذج اللغة تشغل مساحة كبيرة. لكننا نتحدث عن لغة واحدة فقط. أصبح من الواضح أنه سيتعين علينا استخدام واجهة برمجة التطبيقات عبر الإنترنت. اتضح لاحقًا أن خدمات التعرف على الكلام لعمالقة مثل Google وYandex وMicrosoft ليست مجانية على الإطلاق، وسيتعين علينا أن نكتفي بفترة تجريبية. ونتيجة لذلك، تم اختيار Google Speech-To-Text، لأنه يسمح لك بالحصول على رمز مميز لاستخدام الخدمة، والذي سيستمر لمدة عام كامل.
المشكلة الثانية التي واجهناها تتعلق ببعض أوجه القصور في لغة C++ - حديقة حيوانات تضم مكتبات متنوعة في غياب مستودع مركزي. يحدث أن Telegram Desktop يعتمد على العديد من المكتبات الأخرى الخاصة بالإصدار. المستودع الرسمي لديه لتجميع المشروع. وأيضا عدد كبير من القضايا المفتوحة حول مشاكل البناء، على سبيل المثال и اتضح أن جميع المشاكل مرتبطة بحقيقة أن نص البناء كُتب لـ Ubuntu 14.04، ومن أجل تجميع البرقية بنجاح بموجب Ubuntu 18.04، كان عليّ إجراء بعض التغييرات.
يستغرق تجميع Telegram Desktop وقتًا طويلاً: على جهاز كمبيوتر محمول مزود بمعالج Intel Core i5-7200U، يستغرق التجميع الكامل (العلامة -j 4) مع جميع التبعيات حوالي ثلاث ساعات. من بينها، يستغرق ربط العميل نفسه حوالي 30 دقيقة (اتضح لاحقًا أنه في تكوين التصحيح، يستغرق الارتباط حوالي 10 دقائق)، ومع ذلك يجب تكرار مرحلة الارتباط في كل مرة بعد إجراء التغييرات.
على الرغم من المشاكل، تمكنا من تنفيذ الفكرة المتصور، وكذلك التحديث إلى Ubuntu 18.04. يمكن مشاهدة عرض توضيحي للعمل على . نحن ندرج أيضًا العديد من الرسوم المتحركة. ظهر زر بجانب كافة الرسائل الصوتية، مما يسمح لك بترجمة الرسالة إلى نص. بالنقر بزر الماوس الأيمن، يمكنك بالإضافة إلى ذلك تحديد اللغة التي سيتم استخدامها للبث. بواسطة العميل متاح للتنزيل.
في رأينا، تبين أنه دليل جيد على مفهوم الوظيفة التي ستكون مناسبة للعديد من المستخدمين. نأمل أن نراها في الإصدارات المستقبلية من Telegram Desktop.
تعزيز دعم اللغة الطبيعية في IntelliJ IDEA
مؤلف الفكرة
تانكوف فلاديسلاف
هيكل القيادة
تانكوف فلاديسلاف (قائد الفريق، يعمل مع LanguageTool وIntelliJ IDEA)
نيكيتا سوكولوف (العمل مع LanguageTool وإنشاء واجهة المستخدم)
خفوروف ألكسندر (العمل باستخدام LanguageTool وتحسين الأداء)
Sadovnikov Alexander (دعم تحليل اللغات الترميزية والتعليمات البرمجية)
لقد قمنا بتطوير مكون إضافي لـ IntelliJ IDEA الذي يتحقق من النصوص المختلفة (التعليقات والوثائق، والسطور الحرفية في التعليمات البرمجية، والنص المنسق بعلامة Markdown أو علامة XML) للتأكد من الدقة النحوية والإملائية والأسلوبية (يسمى هذا في اللغة الإنجليزية التدقيق اللغوي).
كانت فكرة المشروع هي توسيع التدقيق الإملائي القياسي IntelliJ IDEA إلى مقياس Grammarly، لإنشاء نوع من القواعد النحوية داخل IDE.
يمكنك أن ترى ما حدث .
حسنا، أدناه سنتحدث بمزيد من التفاصيل حول إمكانيات البرنامج المساعد، وكذلك الصعوبات التي نشأت أثناء إنشائها.
حافز
هناك العديد من المنتجات المصممة لكتابة النصوص باللغات الطبيعية، ولكن غالبًا ما تتم كتابة التوثيق وتعليقات التعليمات البرمجية في بيئات التطوير. في الوقت نفسه، تقوم IDEs بعمل ممتاز في العثور على الأخطاء في التعليمات البرمجية، ولكنها غير مناسبة للنصوص باللغات الطبيعية. وهذا يجعل من السهل جدًا ارتكاب الأخطاء في القواعد النحوية أو علامات الترقيم أو الأسلوب دون أن تشير إليها بيئة التطوير. من الأهمية بمكان ارتكاب خطأ في كتابة واجهة المستخدم، لأن هذا سيؤثر ليس فقط على فهم التعليمات البرمجية، ولكن أيضًا على مستخدمي التطبيق المطور أنفسهم.
إحدى بيئات التطوير الأكثر شعبية وتطورًا هي IntelliJ IDEA، بالإضافة إلى IDEs المبنية على منصة IntelliJ. يحتوي IntelliJ Platform بالفعل على مدقق إملائي مدمج، لكنه لا يتخلص حتى من أبسط الأخطاء النحوية. قررنا دمج أحد أنظمة تحليل اللغة الطبيعية الشائعة في IntelliJ IDEA.
تطبيق
 لم نحدد لأنفسنا مهمة إنشاء نظام التحقق من النص الخاص بنا، لذلك استخدمنا الحل الموجود. تبين أن الخيار الأنسب هو . سمح لنا الترخيص باستخدامه بحرية لأغراضنا: فهو مجاني ومكتوب بلغة Java ومفتوح المصدر. بالإضافة إلى ذلك، فهو يدعم 25 لغة وهو قيد التطوير منذ أكثر من خمسة عشر عامًا. على الرغم من انفتاحها، تعتبر LanguageTool منافسًا جديًا لحلول التحقق من النصوص المدفوعة، وحقيقة أنها يمكن أن تعمل محليًا هي ميزتها القاتلة.
لم نحدد لأنفسنا مهمة إنشاء نظام التحقق من النص الخاص بنا، لذلك استخدمنا الحل الموجود. تبين أن الخيار الأنسب هو . سمح لنا الترخيص باستخدامه بحرية لأغراضنا: فهو مجاني ومكتوب بلغة Java ومفتوح المصدر. بالإضافة إلى ذلك، فهو يدعم 25 لغة وهو قيد التطوير منذ أكثر من خمسة عشر عامًا. على الرغم من انفتاحها، تعتبر LanguageTool منافسًا جديًا لحلول التحقق من النصوص المدفوعة، وحقيقة أنها يمكن أن تعمل محليًا هي ميزتها القاتلة.
رمز البرنامج المساعد موجود . تمت كتابة المشروع بأكمله بلغة Kotlin مع إضافة بسيطة لـ Java لواجهة المستخدم. خلال الهاكاثون، تمكنا من تقديم الدعم لـ Markdown وJavaDoc وHTML وPlain Text. بعد الهاكاثون، أضاف تحديث رئيسي دعمًا لـ XML، والسلاسل الحرفية في Java، وKotlin، وPython، والتدقيق الإملائي.
الصعوبات
لقد أدركنا بسرعة كبيرة أنه إذا قمنا بتغذية كل النص إلى LanguageTool للفحص في كل مرة، فسوف تتجمد واجهة IDEA على أي نص أكثر أو أقل خطورة، نظرًا لأن الفحص نفسه يمنع تدفق واجهة المستخدم. تم حل المشكلة من خلال فحص `ProgressManager.checkCancelled` - تطرح هذه الوظيفة استثناءً إذا اعتقدت IDEA أن الوقت قد حان لإلغاء الفحص.
أدى هذا إلى إزالة التجميد تمامًا، لكن من المستحيل استخدامه: تستغرق معالجة النص وقتًا طويلاً جدًا. علاوة على ذلك، في حالتنا، غالبًا ما يتغير جزء صغير جدًا من النص ونريد تخزين النتائج مؤقتًا بطريقة ما. هذا بالضبط ما فعلناه. لكي لا نتحقق من كل شيء في كل مرة، قمنا بتقسيم النص بشكل حتمي إلى أجزاء وتحققنا فقط من تلك التي تغيرت. نظرًا لأن النصوص يمكن أن تكون كبيرة ولم نرغب في تحميل ذاكرة التخزين المؤقت، لم نقم بتخزين النصوص نفسها، ولكن تجزئاتها. سمح هذا للمكون الإضافي بالعمل بسلاسة حتى على الملفات الكبيرة.
تدعم LanguageTool أكثر من 25 لغة، ولكن من غير المرجح أن يحتاج أي مستخدم إلى كل اللغات. أردت أن أمنح الفرصة لتنزيل المكتبات بلغة معينة عند الطلب (إذا قمت بتحديدها في واجهة المستخدم). حتى أننا قمنا بتنفيذ هذا، ولكن تبين أنه معقد للغاية وغير موثوق به. على وجه الخصوص، كان علينا تحميل LanguageTool بمجموعة جديدة من اللغات باستخدام أداة تحميل فئة منفصلة، ثم تهيئتها بعناية. وفي الوقت نفسه، كانت جميع المكتبات موجودة في مستودع المستخدم m2. وفي كل بداية كان علينا التحقق من سلامتها. في النهاية، قررنا أنه إذا واجه المستخدمون مشكلات تتعلق بحجم المكون الإضافي، فسنوفر مكونًا إضافيًا منفصلاً للعديد من اللغات الأكثر شيوعًا.
بعد الهاكاثون
انتهى الهاكاثون، ولكن استمر العمل على البرنامج الإضافي بفريق أصغر. كنت أرغب في دعم السلاسل والتعليقات وحتى بنيات اللغة مثل أسماء المتغيرات والفئات. حاليًا، هذا مدعوم فقط لـ Java وKotlin وPython، ولكننا نأمل أن تنمو هذه القائمة. لقد أصلحنا الكثير من الأخطاء الصغيرة وأصبحنا أكثر توافقًا مع المدقق الإملائي المدمج في Idea. بالإضافة إلى ذلك، ظهر دعم XML والتدقيق الإملائي. كل هذا تجدونه في النسخة الثانية التي نشرناها مؤخراً.
ما هي الخطوة التالية؟
يمكن أن يكون هذا البرنامج المساعد مفيدًا ليس فقط للمطورين، ولكن أيضًا للكتاب التقنيين (غالبًا ما يعملون، على سبيل المثال، مع XML في IDE). يتعين عليهم كل يوم العمل باللغة الطبيعية، دون الحاجة إلى مساعد في شكل نصائح للمحرر حول الأخطاء المحتملة. يوفر البرنامج المساعد الخاص بنا مثل هذه التلميحات ويقوم بذلك بدرجة عالية من الدقة.
نحن نخطط لتطوير البرنامج المساعد، سواء عن طريق إضافة لغات جديدة أو من خلال استكشاف النهج العام لتنظيم فحص النص. تتضمن خططنا الفورية تنفيذ ملفات التعريف الأسلوبية (مجموعات من القواعد التي تحدد دليل أسلوب النص، على سبيل المثال، "لا تكتب على سبيل المثال، ولكن اكتب النموذج الكامل")، وتوسيع القاموس وتحسين واجهة المستخدم (على وجه الخصوص، نريد أن نمنح المستخدم الفرصة ليس فقط لتجاهل الكلمة، بل لإضافتها إلى القاموس، مع الإشارة إلى جزء الكلام).
المصدر: www.habr.com
