


SQL, daha sadə nə ola bilər? Hər birimiz sadə bir sorğu yaza bilərik - yazırıq seçmək, tələb olunan sütunları sıralayın, sonra etibarən, cədvəlin adı, bəzi şərtlər hara və hamısı budur - faydalı məlumatlar cibimizdədir və (demək olar ki) o anda hansı DBMS-nin başlıq altında olmasından asılı olmayaraq (və ya bəlkə də ). Nəticədə, demək olar ki, hər hansı bir məlumat mənbəyi ilə işləmək (əlaqəli və belə deyil) adi kod nöqteyi-nəzərindən nəzərdən keçirilə bilər (bütün bunları nəzərdə tutur - versiyaya nəzarət, kodun nəzərdən keçirilməsi, statik təhlil, avtotestlər və hamısı). Və bu, yalnız məlumatların özünə, sxemlərə və miqrasiyaya deyil, ümumiyyətlə yaddaşın bütün ömrünə aiddir. Bu yazıda gündəlik işlərdən və müxtəlif verilənlər bazaları ilə işləmək problemlərindən “kod kimi verilənlər bazası” obyektivindən danışacağıq.
Və elə buradan başlayaq . "SQL vs ORM" tipli ilk döyüşlər geridə qaldı .
Obyekt-əlaqəli xəritəçəkmə
ORM tərəfdarları ənənəvi olaraq sürət və inkişaf asanlığını, DBMS-dən müstəqilliyi və təmiz kodu qiymətləndirirlər. Bir çoxumuz üçün verilənlər bazası ilə işləmək kodu (və çox vaxt verilənlər bazasının özü)
adətən belə görünür...
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...Model ağıllı annotasiyalarla asılır və haradasa pərdə arxasında cəsur ORM tonlarla SQL kodu yaradır və icra edir. Yeri gəlmişkən, tərtibatçılar özlərini kilometrlərlə abstraksiyalarla verilənlər bazasından təcrid etməyə çalışırlar ki, bu da bəzi .
Barrikadaların digər tərəfində, təmiz "əl işi" SQL tərəfdarları əlavə təbəqələr və abstraksiyalar olmadan DBMS-dən bütün suyu sıxmaq qabiliyyətini qeyd edirlər. Nəticədə verilənlər bazasına xüsusi təlim keçmiş insanların cəlb olunduğu (onlar həm də “əsasçılardır”, onlar həm də “bazaçılardır”, onlar həm də “bazdenschiki” və s.) “məlumat mərkəzli” layihələr meydana çıxır və tərtibatçılar təfərrüatlara varmadan yalnız hazır görünüşləri və saxlanılan prosedurları “çəkmək” lazımdır.
Hər iki dünyanın ən yaxşısına sahib olsaydıq nə olardı? Bu, həyatı təsdiqləyən bir adla gözəl bir alətdə necə edilir . Sərbəst tərcüməmdə ümumi anlayışdan bir neçə sətir verəcəyəm, onunla daha ətraflı tanış ola bilərsiniz. .
Clojure DSL yaratmaq üçün əla dildir, lakin SQL özü əla DSL-dir və başqa dilə ehtiyacımız yoxdur. S-ifadələri əladır, lakin burada yeni heç nə əlavə etmirlər. Nəticədə, mötərizələr üçün mötərizələr alırıq. Razı deyilsiniz? Sonra verilənlər bazası üzərindəki abstraksiyanın sızmağa başladığı anı gözləyin və siz funksiya ilə mübarizə aparmağa başlayın (raw-sql)
Bəs mən nə etməliyəm? Gəlin SQL-i adi SQL kimi buraxaq - hər sorğu üçün bir fayl:
-- name: users-by-country
select *
from users
where country_code = :country_code... və sonra bu faylı adi Clojure funksiyasına çevirərək oxuyun:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)"SQL özü, Clojure özü" prinsipinə riayət etməklə siz:
- Sintaktik sürprizlər yoxdur. Verilənlər bazanız (hər hansı digər kimi) SQL standartına 100% uyğun deyil - lakin bunun Yesql üçün əhəmiyyəti yoxdur. SQL ekvivalent sintaksisi ilə funksiyaları axtarmağa heç vaxt vaxt itirməyəcəksiniz. Heç vaxt bir funksiyaya qayıtmalı olmayacaqsınız (raw-sql "bəzi('funky'::SYNTAX)")).
- Ən yaxşı redaktor dəstəyi. Redaktorunuz artıq əla SQL dəstəyinə malikdir. SQL-i SQL kimi saxlamaqla siz sadəcə ondan istifadə edə bilərsiniz.
- Komanda uyğunluğu. DBA-larınız Clojure layihənizdə istifadə etdiyiniz SQL-i oxuya və yaza bilər.
- Performansın daha asan tənzimlənməsi. Problemli sorğu üçün plan qurmaq lazımdırmı? Sorğunuz adi SQL olduqda bu problem deyil.
- Sorğuların təkrar istifadəsi. Eyni SQL fayllarını başqa layihələrə sürükləyin və buraxın, çünki bu, köhnə SQL-dir - sadəcə paylaşın.
Fikrimcə, ideya çox gözəl və eyni zamanda çox sadədir, bunun sayəsində layihə çox şey qazanıb müxtəlif dillərdə. Bundan sonra biz SQL kodunu ORM-dən kənarda qalan hər şeydən ayırmaq üçün oxşar fəlsəfə tətbiq etməyə çalışacağıq.
IDE və DB menecerləri
Sadə bir gündəlik işdən başlayaq. Çox vaxt verilənlər bazasında bəzi obyektləri axtarmalı oluruq, məsələn, sxemdə cədvəl tapmalı və onun strukturunu öyrənməliyik (hansı sütunlar, açarlar, indekslər, məhdudiyyətlər və s. istifadə olunur). Və hər hansı bir qrafik IDE və ya kiçik bir DB-menecerdən, ilk növbədə, biz məhz bu qabiliyyətləri gözləyirik. Sürətli olması və lazımi məlumatları olan bir pəncərə (xüsusilə uzaq verilənlər bazasına yavaş qoşulma ilə) çəkilənə qədər yarım saat gözləmək məcburiyyətində qalmamağınız və eyni zamanda alınan məlumatın təzə və aktual olması üçün, və keşlənmiş zibil deyil. Üstəlik, verilənlər bazası nə qədər mürəkkəb və böyükdürsə və onların sayı nə qədər çox olarsa, bunu etmək bir o qədər çətindir.
Amma adətən siçanı atıb sadəcə kod yazıram. Tutaq ki, siz “HR” sxemində hansı cədvəllərin (və hansı xüsusiyyətlərlə) olduğunu öyrənməlisiniz. Əksər DBMS-lərdə istənilən nəticəni information_schema-dan bu sadə sorğu ilə əldə etmək olar:
select table_name
, ...
from information_schema.tables
where schema = 'HR'Verilənlər bazasından verilənlər bazasına belə istinad cədvəllərinin məzmunu hər bir DBMS-nin imkanlarından asılı olaraq dəyişir. Və, məsələn, MySQL üçün, eyni istinad kitabından bu DBMS-ə xas olan cədvəl parametrlərini əldə edə bilərsiniz:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle information_schema bilmir, amma var , və heç bir böyük problem yaranmır:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ClickHouse istisna deyil:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'Bənzər bir şey Cassandra-da edilə bilər (burada cədvəllər əvəzinə sütun ailələri və sxemlər əvəzinə açar boşluqları var):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'Əksər digər verilənlər bazaları üçün siz də oxşar sorğularla çıxış edə bilərsiniz (hətta Mongo da var , sistemdəki bütün kolleksiyalar haqqında məlumatı ehtiva edir).
Təbii ki, bu yolla təkcə cədvəllər haqqında deyil, ümumiyyətlə istənilən obyekt haqqında məlumat əldə etmək olar. Zaman zaman mehriban insanlar müxtəlif verilənlər bazaları üçün belə kodu paylaşırlar, məsələn, habra məqalələr silsiləsində "PostgreSQL verilənlər bazalarının sənədləşdirilməsi funksiyaları" (, , ). Əlbəttə ki, bütün bu sorğular dağını beynimdə saxlamaq və onları daim yazmaq çox xoşdur, ona görə də mənim sevimli IDE/redaktorumda tez-tez istifadə olunan sorğular üçün əvvəlcədən hazırlanmış fraqmentlər dəsti var və qalan sadəcə obyekt adlarını şablona daxil edin.
Nəticədə, bu naviqasiya və obyektlərin axtarışı üsulu daha çevikdir, çox vaxta qənaət edir və məlumatı indi lazım olan formada (məsələn, yazıda təsvir edildiyi kimi) əldə etməyə imkan verir. ).
Obyektlərlə əməliyyatlar
Lazımi obyektləri tapıb öyrəndikdən sonra onlarla faydalı bir iş görməyin vaxtı gəldi. Təbii ki, barmaqlarınızı klaviaturadan çəkmədən də.
Heç kimə sirr deyil ki, sadəcə cədvəlin silinməsi demək olar ki, bütün verilənlər bazalarında eyni görünəcək:
drop table hr.personsAncaq masanın yaradılması ilə daha maraqlı olur. Demək olar ki, hər hansı bir DBMS (bir çox NoSQL daxil olmaqla) bu və ya digər formada "cədvəl yarada" bilər və onun əsas hissəsi hətta bir qədər fərqli olacaq (adı, sütunların siyahısı, məlumat növləri), lakin digər detallar kəskin şəkildə fərqlənə bilər və onlardan asılı ola bilər. daxili cihaz və xüsusi DBMS imkanları. Ən sevdiyim nümunə Oracle sənədlərində "cədvəl yarat" sintaksisi üçün yalnız "çılpaq" BNF-lərin olmasıdır. . Digər DBMS-lər daha təvazökar imkanlara malikdir, lakin onların hər biri də cədvəllər yaratmaq üçün bir çox maraqlı və unikal xüsusiyyətlərə malikdir (, , , ). Çətin ki, başqa bir IDE-dən (xüsusilə universal olan) hər hansı bir qrafik “sehrbaz” bütün bu qabiliyyətləri tam əhatə edə bilsin və bacarsa belə, zəiflər üçün tamaşa olmayacaq. Eyni zamanda düzgün və vaxtında yazılmış bəyanat cədvəl yaradın sizə onların hamısını asanlıqla istifadə etməyə, saxlama və məlumatlarınıza girişi etibarlı, optimal və mümkün qədər rahat etməyə imkan verəcək.
Həmçinin, bir çox DBMS-lərin digər DBMS-lərdə olmayan özünəməxsus obyekt növləri var. Üstəlik, biz təkcə verilənlər bazası obyektlərində deyil, həm də DBMS-nin özündə də əməliyyatlar həyata keçirə bilərik, məsələn, prosesi “öldürmək”, bəzi yaddaş sahəsini boşaltmaq, izləməni aktivləşdirmək, “yalnız oxumaq” rejiminə keçmək və s.
İndi bir az çəkək
Ən çox görülən işlərdən biri verilənlər bazası obyektləri ilə diaqram qurmaq və obyektləri və onlar arasındakı əlaqələri gözəl şəkildə görməkdir. Demək olar ki, hər hansı bir qrafik IDE, ayrıca "komanda xətti" utilitləri, xüsusi qrafik alətlər və modelləşdiricilər bunu edə bilər. Onlar sizin üçün "bacardıqları qədər" bir şey çəkəcəklər və siz bu prosesə yalnız konfiqurasiya faylındakı bir neçə parametr və ya interfeysdəki onay qutularının köməyi ilə bir az təsir edə bilərsiniz.
Ancaq bu problemi çox daha sadə, daha çevik və zərif və əlbəttə ki, kodun köməyi ilə həll etmək olar. İstənilən mürəkkəblik diaqramlarını yaratmaq üçün bizim bir neçə xüsusi işarələmə dilimiz (DOT, GraphML və s.) və onlar üçün bu cür təlimatları oxuya və müxtəlif formatlarda vizuallaşdıra bilən proqramların tam səpələnməsi (GraphViz, PlantUML, Mermaid) var. . Yaxşı, biz artıq obyektlər və onlar arasındakı əlaqələr haqqında məlumat əldə etməyi bilirik.
PlantUML və istifadə edərək, bunun necə görünə biləcəyinə dair kiçik bir nümunə (solda PlantUML üçün tələb olunan təlimatı yaradacaq bir SQL sorğusu, sağda isə nəticədir):
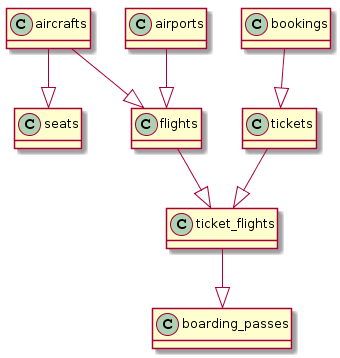
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'Və bir az cəhd etsəniz, o zaman əsaslanır real ER diaqramına çox oxşar bir şey əldə edə bilərsiniz:
SQL sorğusu bir az daha mürəkkəbdir
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
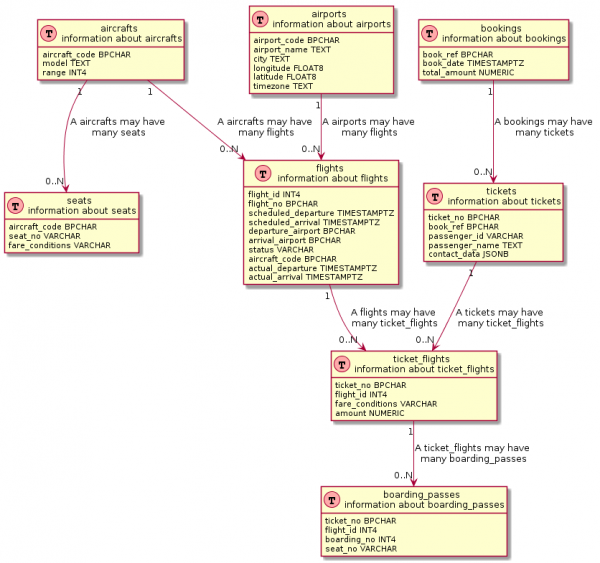
Diqqətlə baxsanız, başlıq altında bir çox vizuallaşdırma alətləri də oxşar sorğulardan istifadə edir. Düzdür, bu istəklər adətən dərindən olur , onların hər hansı bir modifikasiyasını qeyd etmək olmaz.
Metriklər və monitorinq
Gəlin ənənəvi olaraq mürəkkəb mövzuya - verilənlər bazası performansının monitorinqinə keçək. “Dostlarımdan birinin” mənə söylədiyi kiçik bir gerçək hekayəni xatırlayıram. Başqa bir layihədə müəyyən bir güclü DBA yaşayırdı və bir neçə tərtibatçı onu şəxsən tanıyırdı və ya onu şəxsən görüb (şayiələrə görə, o, növbəti binada bir yerdə işlədiyinə baxmayaraq) . “X” saatında iri pərakəndə satıcının poduction sistemi yenidən “pis hiss etməyə” başlayanda o, səssizcə Oracle Enterprise Manager-dən qrafiklərin skrinşotlarını göndərdi və orada kritik yerləri “anlaşılırlıq” üçün qırmızı markerlə diqqətlə vurğuladı ( bu, yumşaq desək, çox kömək etmədi). Və bu "fotokart" əsasında müalicə etməli oldum. Eyni zamanda, heç kimin qiymətli (sözün hər iki mənasında) Müəssisə Menecerinə çıxışı yox idi, çünki sistem mürəkkəb və bahalıdır, birdən "inkişafçılar bir şeyə büdrəyərək hər şeyi pozurlar". Buna görə də, tərtibatçılar "empirik" əyləclərin yerini və səbəbini tapdılar və yamaq buraxdılar. Əgər DBA-dan gələn hədələyici məktub yaxın vaxtlarda bir daha gəlməsəydi, o zaman hamı rahat nəfəs alıb indiki işlərinə qayıdacaqdı (yeni Məktuba qədər).
Lakin monitorinq prosesi hər kəs üçün daha əyləncəli və səmimi, ən əsası isə əlçatan və şəffaf görünə bilər. Ən azı onun əsas hissəsi, əsas monitorinq sistemlərinə əlavə olaraq (bu, əlbəttə ki, faydalıdır və bir çox hallarda əvəzolunmazdır). İstənilən DBMS öz cari vəziyyəti və performansı haqqında məlumatı paylaşmaq üçün sərbəst və tamamilə pulsuzdur. Eyni "qanlı" Oracle DB-də, proseslər və seanslardan tutmuş bufer keşinin vəziyyətinə qədər sistem görünüşlərindən performans haqqında demək olar ki, hər hansı bir məlumat əldə edilə bilər (məsələn, , bölmə "Monitorinq"). Postgresql də bir çox sistem görünüşünə malikdir , xüsusən də hər hansı bir DBA-nın gündəlik həyatında əvəzolunmaz olanlar, məsələn , , . MySQL-in hətta bunun üçün ayrıca bir sxemi var. . A In Mongo daxili performans məlumatlarını sistem kolleksiyasına toplayır .
Beləliklə, xüsusi sql sorğularını yerinə yetirə bilən bir növ ölçü kollektoru (Telegraf, Metricbeat, Collectd), bu ölçülərin saxlanması (InfluxDB, Elasticsearch, Timescaledb) və vizualizator (Grafana, Kibana) ilə silahlanmış, kifayət qədər asan əldə edə bilərsiniz. və digər sistem miqyaslı ölçülərlə sıx inteqrasiya olunacaq çevik monitorinq sistemi (məsələn, proqram serverindən, ƏS-dən və s. əldə edilir). Məsələn, bu, InfluxDB + Grafana kombinasiyasından və sistem görünüşləri üçün sorğular toplusundan istifadə edən pgwatch2-də edilir, bunlara da daxil olmaq olar. .
Ümumi
Və bu, adi SQL kodundan istifadə edərək verilənlər bazamızla nələrin edilə biləcəyinin yalnız təxmini siyahısıdır. Əminəm ki, daha çox istifadə tapa bilərsiniz, şərhlərdə yazın. Bütün bunları necə (və ən əsası niyə) avtomatlaşdırıb növbəti dəfə CI/CD boru kəmərinizə daxil etmək barədə danışacağıq.
Mənbə: www.habr.com
