

Mənim adım Pavel Parkhomenko, mən ML tərtibatçısiyəm. Bu yazıda Yandex.Zen xidmətinin strukturu haqqında danışmaq və tətbiqi tövsiyələrin keyfiyyətini artırmağa imkan verən texniki təkmilləşdirmələri bölüşmək istərdim. Bu yazıdan siz bir neçə millisaniyə ərzində milyonlarla sənəd arasında istifadəçi üçün ən uyğun olanı necə tapmağı öyrənəcəksiniz; böyük matrisin (milyonlarla sütundan və on milyonlarla cərgədən ibarət) davamlı parçalanması necə aparılmalıdır ki, yeni sənədlər on dəqiqə ərzində öz vektorunu alsın; video üçün yaxşı bir vektor təsviri əldə etmək üçün istifadəçi məqaləsi matrisinin parçalanmasından necə istifadə etmək olar.
Tövsiyə bazamız müxtəlif formatlı milyonlarla sənədi ehtiva edir: platformamızda yaradılmış və xarici saytlardan, videolardan, povestlərdən və qısa yazılardan götürülmüş mətn məqalələri. Belə bir xidmətin inkişafı çoxlu sayda texniki çətinliklərlə əlaqələndirilir. Onlardan bəzilərini təqdim edirik:
- Hesablama tapşırıqlarını bölün: bütün ağır əməliyyatları oflayn yerinə yetirin və 100-200 ms-ə cavabdeh olmaq üçün real vaxtda yalnız modellərin sürətli tətbiqini həyata keçirin.
- İstifadəçi hərəkətlərini tez nəzərə alın. Bunun üçün bütün hadisələrin dərhal tövsiyəçiyə çatdırılması və modellərin nəticələrinə təsir etməsi lazımdır.
- Lenti elə edin ki, yeni istifadəçilər üçün onların davranışlarına tez uyğunlaşsın. Sistemə yeni qoşulmuş insanlar öz rəylərinin tövsiyələrə təsir etdiyini hiss etməlidirlər.
- Yeni məqaləni kimə tövsiyə edəcəyinizi tez anlayın.
- Daimi yeni məzmunun yaranmasına tez reaksiya verin. Hər gün on minlərlə məqalə dərc olunur və onların çoxunun ömrü məhduddur (məsələn, xəbərlər). Onları filmlərdən, musiqilərdən və digər uzunömürlü və bahalı məzmunlardan fərqləndirən budur.
- Biliyi bir domen sahəsindən digərinə köçürün. Tövsiyə sistemində mətn məqalələri üçün öyrədilmiş modellər varsa və biz ona video əlavə ediriksə, yeni məzmun növünün daha yaxşı yer tutması üçün mövcud modellərdən təkrar istifadə edə bilərik.
Bu problemləri necə həll etdiyimizi sizə deyəcəyəm.
Namizədlərin seçilməsi
Reytinq keyfiyyətində faktiki olaraq heç bir pisləşmə olmadan nəzərdən keçirilən sənədlərin sayını bir neçə millisaniyə ərzində minlərlə dəfə necə azaltmaq olar?
Tutaq ki, biz çoxlu ML modellərini öyrətmişik, onlar əsasında funksiyalar yaratmışıq və istifadəçi üçün sənədləri sıralayan başqa bir modeli öyrətmişik. Hər şey yaxşı olardı, ancaq real vaxt rejimində bütün sənədlər üçün bütün işarələri götürüb hesablaya bilməzsiniz, əgər bu sənədlərin sayı milyonlarladırsa və tövsiyələr 100-200 ms-də hazırlanmalıdır. Tapşırıq, istifadəçi üçün sıralanacaq milyonlarla müəyyən bir alt çoxluğu seçməkdir. Bu mərhələ adətən namizəd seçimi adlanır. Bunun üçün bir sıra tələblər var. Birincisi, seçim çox tez baş verməlidir ki, reytinqin özünə mümkün qədər çox vaxt qalsın. İkincisi, sıralama üçün sənədlərin sayını xeyli azaldaraq, istifadəçiyə aid olan sənədləri mümkün qədər tam saxlamalıyıq.
Namizədlərin seçilməsi prinsipimiz inkişaf etdi və hazırda biz çoxmərhələli sxemə gəldik:
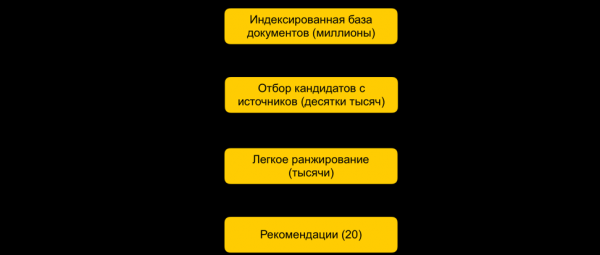
Birincisi, bütün sənədlər qruplara bölünür və hər qrupdan ən populyar sənədlər götürülür. Qruplar saytlar, mövzular, klasterlər ola bilər. Hər bir istifadəçi üçün öz tarixçəsinə əsasən ona ən yaxın qruplar seçilir və onlardan ən yaxşı sənədlər götürülür. Biz həmçinin real vaxt rejimində istifadəçiyə ən yaxın olan sənədləri seçmək üçün kNN indeksindən istifadə edirik. KNN indeksinin qurulması üçün bir neçə üsul var, bizimkilər ən yaxşı nəticə verdi (İyerarxik Naviqasiya olunan Kiçik Dünya qrafikləri). Bu, bir neçə millisaniyə ərzində milyonlarla verilənlər bazasından istifadəçi üçün ən yaxın N vektoru tapmağa imkan verən iyerarxik modeldir. Əvvəlcə bütün sənəd bazamızı oflayn olaraq indeksləyirik. İndeksdə axtarış olduqca tez işlədiyindən, bir neçə güclü daxiletmə varsa, siz bir neçə indeks yarada bilərsiniz (hər bir daxiletmə üçün bir indeks) və onların hər birinə real vaxt rejimində daxil ola bilərsiniz.
Hər bir istifadəçi üçün hələ də on minlərlə sənədimiz var. Bütün xüsusiyyətləri saymaq üçün hələ çox şey var, buna görə də bu mərhələdə biz yüngül sıralamadan istifadə edirik - daha az xüsusiyyətlərə malik yüngül, ağır reytinq modeli. Vəzifə, ağır bir modelin yuxarıda hansı sənədlərə sahib olacağını proqnozlaşdırmaqdır. Ən yüksək proqnozlaşdırıcıya malik sənədlər ağır modeldə, yəni reytinqin sonuncu mərhələsində istifadə olunacaq. Bu yanaşma istifadəçi üçün nəzərdə tutulan sənədlərin məlumat bazasını on millisaniyələrdə milyonlardan minlərə endirməyə imkan verir.
ALS iş vaxtında addım
Klikdən dərhal sonra istifadəçi rəyini necə nəzərə almaq olar?
Tövsiyələrdə mühüm amil istifadəçi rəyinə cavab müddətidir. Bu, xüsusilə yeni istifadəçilər üçün vacibdir: bir şəxs tövsiyə sistemindən istifadə etməyə başlayanda, o, müxtəlif mövzularda sənədlərin fərdiləşdirilməmiş lentini alır. İlk kliklədiyi anda bunu dərhal nəzərə almalı və onun maraqlarına uyğunlaşmalısınız. Bütün amilləri oflayn hesablasanız, gecikmə səbəbindən sistemin sürətli cavabı qeyri-mümkün olacaq. Beləliklə, real vaxt rejimində istifadəçi hərəkətlərini emal etmək lazımdır. Bu məqsədlər üçün istifadəçinin vektor təsvirini qurmaq üçün icra zamanı ALS addımından istifadə edirik.
Tutaq ki, bütün sənədlər üçün vektor təsvirimiz var. Məsələn, biz ELMo, BERT və ya digər maşın öyrənmə modellərindən istifadə edərək məqalənin mətni əsasında oflayn daxiletmələr qura bilərik. Eyni məkanda istifadəçilərin sistemdəki qarşılıqlı əlaqəsi əsasında onların vektor təsvirini necə əldə edə bilərik?
İstifadəçi-sənəd matrisinin formalaşması və parçalanmasının ümumi prinsipim istifadəçi və n sənədimiz olsun. Bəzi istifadəçilər üçün onların müəyyən sənədlərlə əlaqəsi məlumdur. Sonra bu məlumat m x n matrisi kimi təqdim edilə bilər: sətirlər istifadəçilərə, sütunlar isə sənədlərə uyğun gəlir. Şəxs sənədlərin əksəriyyətini görmədiyi üçün matris hüceyrələrinin əksəriyyəti boş qalacaq, digərləri isə doldurulacaq. Hər bir hadisə üçün (bəyənmə, bəyənməmə, klik) matrisdə müəyyən dəyər verilir - lakin gəlin bəyənmənin 1-ə, bəyənməmənin isə -1-ə uyğun gəldiyi sadələşdirilmiş modeli nəzərdən keçirək.
Matrisi iki yerə parçalayaq: P (m x d) və Q (d x n), burada d vektor təsvirinin ölçüsüdür (adətən kiçik ədəddir). Sonra hər bir obyekt d ölçülü vektoruna uyğun olacaq (istifadəçi üçün - P matrisində bir sıra, sənəd üçün - Q matrisində bir sütun). Bu vektorlar müvafiq obyektlərin yerləşdirilməsi olacaqdır. İstifadəçinin sənədi bəyənib-bəyənməyəcəyini təxmin etmək üçün sadəcə onların daxiletmələrini çoxalda bilərsiniz.

Bir matrisin parçalanmasının mümkün yollarından biri ALS-dir (Alternating Least Squares). Aşağıdakı itki funksiyasını optimallaşdıracağıq:

Burada rui u istifadəçisinin i sənədi ilə qarşılıqlı əlaqəsidir, qi i sənədinin vektoru, pu istifadəçi u istifadəçisinin vektorudur.
Sonra orta kvadrat xəta nöqteyi-nəzərindən optimal istifadəçi vektoru (sabit sənəd vektorları üçün) müvafiq xətti reqressiyanın həlli ilə analitik şəkildə tapılır.
Buna "ALS addımı" deyilir. Və ALS alqoritminin özü ondan ibarətdir ki, biz alternativ olaraq matrislərdən birini (istifadəçilər və məqalələr) düzəldirik və digərini yeniləyirik, optimal həlli tapırıq.
Xoşbəxtlikdən, istifadəçinin vektor təsvirini tapmaq kifayət qədər sürətli əməliyyatdır və vektor təlimatlarından istifadə etməklə icra zamanı edilə bilər. Bu hiylə sizə reytinqdə dərhal istifadəçi rəyini nəzərə almağa imkan verir. Namizəd seçimini təkmilləşdirmək üçün kNN indeksində eyni yerləşdirmədən istifadə etmək olar.
Paylanmış Birgə Filtrləmə
Artan paylanmış matris faktorizasiyasını necə etmək və yeni məqalələrin vektor təsvirlərini tez tapmaq olar?
Məzmun tövsiyə siqnallarının yeganə mənbəyi deyil. Digər mühüm mənbə birgə məlumatdır. Yaxşı sıralama xüsusiyyətləri ənənəvi olaraq istifadəçi-sənəd matrisinin parçalanmasından əldə edilə bilər. Ancaq belə bir parçalanma etməyə çalışarkən problemlərlə qarşılaşdıq:
1. Milyonlarla sənədimiz və on milyonlarla istifadəçimiz var. Matris tamamilə bir maşına uyğun gəlmir və parçalanma çox uzun vaxt aparacaq.
2. Sistemdəki məzmunun əksəriyyətinin ömrü qısadır: sənədlər yalnız bir neçə saat aktuallığını saxlayır. Buna görə də onların vektor təsvirini mümkün qədər tez qurmaq lazımdır.
3. Sənəd dərc edildikdən dərhal sonra parçalanma qurarsanız, kifayət qədər sayda istifadəçinin onu qiymətləndirməyə vaxtı olmayacaq. Buna görə də onun vektor təsviri çox güman ki, çox yaxşı olmayacaq.
4. Əgər istifadəçi bəyənirsə və ya bəyənmirsə, biz bunu parçalanmada dərhal nəzərə ala bilməyəcəyik.
Bu problemləri həll etmək üçün biz tez-tez artan yeniləmələrlə istifadəçi-sənəd matrisinin paylanmış parçalanmasını həyata keçirdik. Tam olaraq necə işləyir?
Tutaq ki, bizdə N maşın çoxluğu var (N yüzlərlədir) və biz onların üzərində bir maşına sığmayan matrisin paylanmış parçalanmasını etmək istəyirik. Sual yaranır ki, bu parçalanmanı necə yerinə yetirmək lazımdır ki, bir tərəfdən hər bir maşında kifayət qədər məlumat olsun, digər tərəfdən isə hesablamalar müstəqil olsun?
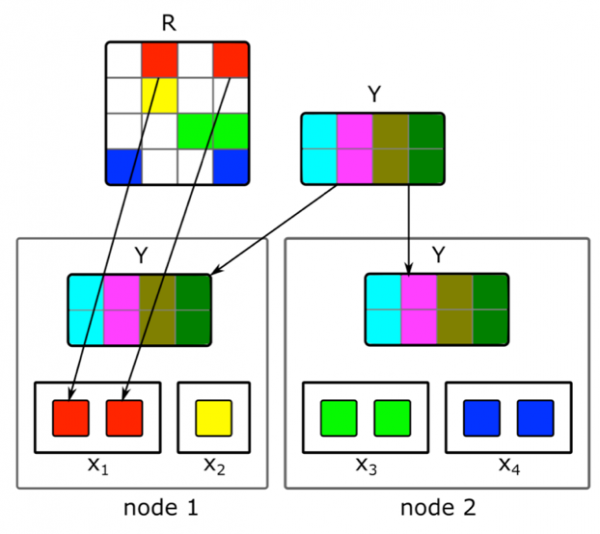
Yuxarıda təsvir edilən ALS parçalanma alqoritmindən istifadə edəcəyik. Bir ALS addımının paylanmış şəkildə necə yerinə yetirilməsinə baxaq - qalan addımlar oxşar olacaq. Tutaq ki, bizdə sabit sənədlər matrisi var və biz istifadəçilərin matrisini qurmaq istəyirik. Bunun üçün onu sətirlərlə N hissəyə böləcəyik, hər hissədə təxminən eyni sayda sətir olacaq. Biz hər bir maşına müvafiq cərgələrin boş olmayan xanalarını, həmçinin sənəd daxiletmə matrisini (bütünlüklə) göndərəcəyik. Ölçüsü çox böyük olmadığından və istifadəçi-sənəd matrisi adətən çox seyrək olduğundan, bu məlumatlar adi bir maşına uyğun olacaq.
Bu hiylə, sabit matrisi bir-bir dəyişdirərək model birləşənə qədər bir neçə dövr ərzində təkrarlana bilər. Ancaq belə olduqda, matrisin parçalanması bir neçə saat çəkə bilər. Və bu, problemi həll etmir ki, siz tez bir zamanda yeni sənədlərin daxil edilməsini qəbul etməlisiniz və modeli qurarkən haqqında az məlumat olanların daxiletmələrini yeniləməlisiniz.
Sürətli artımlı model yeniləmələrinin tətbiqi bizə kömək etdi. Deyək ki, hazırda təlim keçmiş bir modelimiz var. Onun təlimindən sonra istifadəçilərimizin qarşılıqlı əlaqədə olduğu yeni məqalələr, eləcə də təlim zamanı az qarşılıqlı əlaqədə olan məqalələr var. Bu cür məqalələrin daxil edilməsini tez əldə etmək üçün biz modelin ilk böyük təlimi zamanı əldə edilmiş istifadəçi daxiletmələrindən istifadə edirik və sabit istifadəçi matrisi verilmiş sənəd matrisini hesablamaq üçün bir ALS addımı edirik. Bu, daxiletmələri kifayət qədər tez qəbul etməyə imkan verir - sənəd dərc edildikdən bir neçə dəqiqə sonra - və tez-tez son sənədlərin daxiletmələrini yeniləyir.
Tövsiyələrin dərhal insan hərəkətlərini nəzərə alması üçün iş müddətində oflayn əldə edilmiş istifadəçi daxiletmələrindən istifadə etmirik. Bunun əvəzinə biz ALS addımı atırıq və faktiki istifadəçi vektorunu əldə edirik.
Başqa bir domen sahəsinə köçürün
Videonun vektor təsvirini yaratmaq üçün mətn məqalələrində istifadəçi rəyindən necə istifadə etmək olar?
Əvvəlcə biz yalnız mətn məqalələrini tövsiyə etdik, ona görə də alqoritmlərimizin çoxu bu tip məzmuna uyğunlaşdırılıb. Ancaq digər məzmun növlərini əlavə edərkən, modelləri uyğunlaşdırmaq ehtiyacı ilə qarşılaşdıq. Video nümunəsindən istifadə edərək bu problemi necə həll etdik? Seçimlərdən biri bütün modelləri sıfırdan yenidən hazırlamaqdır. Lakin bu, uzun müddət tələb edir və bəzi alqoritmlər xidmətdə həyatının ilk anlarında yeni məzmun növü üçün lazımi miqdarda hələ mövcud olmayan təlim nümunəsinin ölçüsünü tələb edir.
Biz başqa yolla getdik və video üçün mətn modellərindən yenidən istifadə etdik. Eyni ALS hiyləsi bizə videoların vektor təsvirlərini yaratmağa kömək etdi. Mətn məqalələri əsasında istifadəçilərin vektor təsvirini götürdük və video görüntü məlumatından istifadə edərək ALS addımı atdıq. Beləliklə, videonun vektor təsvirini asanlıqla əldə etdik. Və icra zamanı biz sadəcə olaraq mətn məqalələrindən əldə edilən istifadəçi vektoru ilə video vektoru arasındakı yaxınlığı hesablayırıq.
Nəticə
Real vaxt rejimində tövsiyə sisteminin əsasını inkişaf etdirmək bir çox problemi əhatə edir. Bu məlumatlardan səmərəli istifadə etmək üçün məlumatları tez emal etməli və ML metodlarını tətbiq etməlisiniz; minimum vaxt ərzində istifadəçi siqnallarını və yeni məzmun vahidlərini emal edə bilən mürəkkəb paylanmış sistemlər qurmaq; və bir çox başqa vəzifələr.
Dizaynını təsvir etdiyim hazırkı sistemdə istifadəçi üçün tövsiyələrin keyfiyyəti onun fəaliyyəti və xidmətdə qalma müddəti ilə birlikdə artır. Ancaq təbii ki, burada əsas çətinlik var: məzmunla az əlaqədə olan bir insanın maraqlarını sistemin dərhal başa düşməsi çətindir. Yeni istifadəçilər üçün tövsiyələrin təkmilləşdirilməsi bizim əsas məqsədimizdir. Alqoritmləri optimallaşdırmağa davam edəcəyik ki, insana aid olan məzmun onun lentinə daha tez daxil olsun və aidiyyəti olmayan məzmun göstərilməsin.
Mənbə: www.habr.com
