

Giriş
 "Yerində qalmaq üçün bacardığın qədər sürətlə qaçmalısan,
"Yerində qalmaq üçün bacardığın qədər sürətlə qaçmalısan,
və bir yerə çatmaq üçün ən azı iki dəfə sürətli qaçmalısan!”
(c) Alisa möcüzələr ölkəsində
Bir müddət əvvəl məndən mühazirə oxumağı xahiş etdilər analitiklər şirkətimiz məlumat modellərinin dizaynı mövzusunda, çünki layihələrdə uzun müddət (bəzən bir neçə il) oturaraq İT texnologiyaları dünyasında ətrafımızda baş verənləri görməməzlikdən gəlirik. Şirkətimizdə (belə olur) bir çox layihələr NoSQL verilənlər bazasından istifadə etmir (ən azı indiyə qədər), buna görə də öz mühazirəmdə HBase nümunəsindən istifadə edərək onlara ayrıca diqqət yetirdim və materialın təqdimatını həmin şəxslərə yönəltməyə çalışdım. hec istifade etmeyenler isleyib. Xüsusilə, mən bir neçə il əvvəl oxuduğum bir nümunədən istifadə edərək məlumat modeli dizaynının bəzi xüsusiyyətlərini təsvir etdim . Nümunələri təhlil edərkən əsas fikirləri dinləyicilərə daha yaxşı çatdırmaq üçün eyni problemin həllinin bir neçə variantını müqayisə etdim.
Bu yaxınlarda “heç bir işim olmadığından” öz-özümə sual verdim (karantində uzun may həftəsonu bunun üçün xüsusilə əlverişlidir), nəzəri hesablamalar praktikaya nə qədər uyğun olacaq? Əslində bu məqalənin ideyası belə yaranıb. Bir neçə gündür NoSQL ilə işləyən tərtibatçı ondan yeni heç nə öyrənməyə bilər (və buna görə də məqalənin yarısını dərhal atlaya bilər). Amma üçün analitiklərNoSQL ilə hələ də yaxından işləməmişlər üçün hesab edirəm ki, HBase üçün məlumat modellərinin dizayn xüsusiyyətləri haqqında əsas anlayışı əldə etmək üçün faydalı olacaq.
Nümunə təhlili
Fikrimcə, NoSQL verilənlər bazalarından istifadə etməyə başlamazdan əvvəl diqqətlə düşünmək və müsbət və mənfi cəhətləri ölçmək lazımdır. Çox vaxt problem ənənəvi əlaqəli DBMS-lərdən istifadə etməklə həll edilə bilər. Ona görə də əhəmiyyətli səbəblər olmadan NoSQL-dən istifadə etməmək daha yaxşıdır. Əgər siz yenə də NoSQL verilənlər bazasından istifadə etmək qərarına gəlmisinizsə, onda burada dizayn yanaşmalarının bir qədər fərqli olduğunu nəzərə almalısınız. Xüsusilə onlardan bəziləri əvvəllər yalnız relational DBMS ilə məşğul olanlar üçün qeyri-adi ola bilər (müşahidələrimə görə). Beləliklə, "münasibət" dünyasında biz adətən problem sahəsini modelləşdirməyə başlayırıq və yalnız bundan sonra, lazım gələrsə, modeli normallaşdırırıq. NoSQL-də biz verilənlərlə işləmək üçün gözlənilən ssenariləri dərhal nəzərə almalıdır və ilkin olaraq məlumatları normallaşdırın. Bundan əlavə, aşağıda müzakirə ediləcək bir sıra digər fərqlər də var.
Gəlin işləməyə davam edəcəyimiz aşağıdakı "sintetik" problemi nəzərdən keçirək:
Bəzi mücərrəd sosial şəbəkə istifadəçilərinin dostlarının siyahısı üçün saxlama strukturu tərtib etmək lazımdır. Sadələşdirmək üçün bütün əlaqələrimizin yönləndirildiyini güman edəcəyik (Linkedində deyil, Instagram-da olduğu kimi). Struktur sizə effektiv şəkildə imkan verməlidir:
- A istifadəçisinin B istifadəçisini oxuyub-oxumadığı sualına cavab verin (oxu nümunəsi)
- A istifadəçisinin B istifadəçisindən abunə olması/abunədən çıxması halında bağlantıların əlavə edilməsinə/çıxarılmasına icazə verin (məlumat dəyişikliyi şablonu)
Əlbəttə ki, problemin həlli üçün bir çox variant var. Müntəzəm əlaqəli verilənlər bazasında biz çox güman ki, sadəcə olaraq əlaqələr cədvəlini (məsələn, bu “dost”u ehtiva edən bir istifadəçi qrupunu saxlamalı olduğumuz halda tipikləşdirilə bilər: ailə, iş və s.) və optimallaşdırmaq üçün düzəldərdik. giriş sürəti indekslər/bölmələr əlavə edərdi. Çox güman ki, yekun cədvəl belə görünəcək:
user_id
dost_id
vasya
Petya
vasya
Оля
bundan sonra aydınlıq və daha yaxşı başa düşmək üçün şəxsiyyət vəsiqələri əvəzinə adları göstərəcəyəm
HBase vəziyyətində biz bunu bilirik:
- tam cədvəl taraması ilə nəticələnməyən səmərəli axtarış mümkündür yalnız açarla
- əslində, buna görə çoxlarına tanış olan SQL sorğularını belə verilənlər bazalarına yazmaq pis fikirdir; texniki olaraq, əlbəttə ki, eyni Impala-dan HBase-ə Qoşulmalar və digər məntiqlə SQL sorğusu göndərə bilərsiniz, lakin bu nə qədər effektiv olacaq...
Buna görə də istifadəçi ID-dən açar kimi istifadə etməyə məcbur oluruq. Və “dostların şəxsiyyət vəsiqələrini harada və necə saxlamaq olar?” mövzusunda ilk fikrim. bəlkə də onları sütunlarda saxlamaq ideyası. Bu ən bariz və “sadəlövh” seçim buna bənzəyəcək (gəlin buna zəng edək Seçim 1 (defolt)əlavə istinad üçün):
RowKey
Sütunlar
vasya
1: Petya
2: Olya
3: Dasha
Petya
1: Maşa
2: Vasya
Burada hər bir xətt bir şəbəkə istifadəçisinə uyğun gəlir. Sütunların adları var: 1, 2, ... - dostların sayına görə, dostların şəxsiyyət vəsiqələri isə sütunlarda saxlanılır. Qeyd etmək vacibdir ki, hər bir sətirdə fərqli sayda sütun olacaq. Yuxarıdakı şəkildəki nümunədə bir cərgədə üç sütun (1, 2 və 3), ikincisində isə yalnız iki (1 və 2) var - burada biz özümüz relational verilənlər bazasında olmayan iki HBase xassəsindən istifadə etdik:
- sütunların tərkibini dinamik şəkildə dəyişdirmək imkanı (dost əlavə et -> sütun əlavə et, dostu sil -> sütunu sil)
- müxtəlif sətirlərdə fərqli sütun kompozisiyaları ola bilər
Tapşırığın tələblərinə uyğunluğu üçün strukturumuzu yoxlayaq:
- Məlumatların oxunması: Vasyanın Olyaya abunə olub-olmadığını başa düşmək üçün çıxarmaq lazımdır bütün xətt RowKey = "Vasya" düyməsi ilə və biz onlarda Olya ilə "görüşənə qədər" sütun dəyərlərini sıralayın. Və ya bütün sütunların dəyərlərini təkrarlayın, Olya ilə "qarşılaşmayın" və Yanlış cavabını qaytarın;
- Məlumatların redaktəsi: dost əlavə etmək: oxşar tapşırıq üçün biz də çıxmalıyıq bütün xətt RowKey = "Vasya" düyməsini istifadə edərək dostlarının ümumi sayını hesablayın. Yeni dostun şəxsiyyət vəsiqəsini yazmalı olduğumuz sütunun sayını müəyyən etmək üçün bu ümumi dost sayına ehtiyacımız var.
- Məlumatların dəyişdirilməsi: dostun silinməsi:
- Çıxarmaq lazımdır bütün xətt RowKey = "Vasya" düyməsi ilə və silinəcək dostun qeyd olunduğu sütunu tapmaq üçün sütunları sıralayın;
- Sonra, bir dostu sildikdən sonra nömrələnməsində "boşluqlar" almamaq üçün bütün məlumatları bir sütuna "köçürməliyik".
İndi “şərti tətbiq” tərəfində həyata keçirməli olacağımız bu alqoritmlərin nə qədər məhsuldar olacağını qiymətləndirək. . Gəlin hipotetik sosial şəbəkəmizin ölçüsünü n kimi qeyd edək. O zaman bir istifadəçinin ola biləcəyi maksimum dost sayı (n-1) təşkil edir. Bundan əlavə, məqsədlərimiz üçün bunu (-1) laqeyd edə bilərik, çünki O simvollarının istifadəsi çərçivəsində bu əhəmiyyətsizdir.
- Məlumatların oxunması: bütün xətti çıxmaq və limitdə onun bütün sütunlarını təkrarlamaq lazımdır. Bu o deməkdir ki, xərclərin yuxarı təxmini təxminən O(n) olacaq
- Məlumatların redaktəsi: dost əlavə etmək: dostların sayını müəyyən etmək üçün cərgənin bütün sütunlarını təkrarlamalı və sonra yeni sütun daxil etməlisiniz => O(n)
- Məlumatların dəyişdirilməsi: dostun silinməsi:
- Əlavə etməyə bənzər - limitdəki bütün sütunları keçməlisiniz => O(n)
- Sütunları çıxardıqdan sonra onları "hərəkət etməliyik". Bu "baş-üstə" həyata keçirsəniz, limitdə sizə (n-1) qədər əməliyyat lazımdır. Ancaq burada və daha sonra praktik hissədə biz sabit sayda əməliyyatlar üçün "psevdo shift" həyata keçirəcək fərqli bir yanaşmadan istifadə edəcəyik - yəni n-dən asılı olmayaraq ona daimi vaxt sərf olunacaq. Bu sabit vaxt (dəqiq olmaq üçün O(2)) O(n) ilə müqayisədə laqeyd qala bilər. Bu yanaşma aşağıdakı şəkildə göstərilmişdir: biz sadəcə olaraq məlumatları "son" sütunundan məlumatları silmək istədiyimiz sütuna köçürür və sonra sonuncu sütunu silirik:

Ümumilikdə, bütün ssenarilərdə biz O(n)-in asimptotik hesablama mürəkkəbliyini aldıq.
Siz yəqin ki, artıq fikir vermisiniz ki, biz demək olar ki, həmişə verilənlər bazasından bütün sətiri oxumalıyıq və üç halda iki halda, sadəcə, bütün sütunları keçmək və dostların ümumi sayını hesablamaq üçün. Buna görə də, optimallaşdırma cəhdi olaraq, hər bir şəbəkə istifadəçisinin dostlarının ümumi sayını saxlayan "saymaq" sütunu əlavə edə bilərsiniz. Bu vəziyyətdə, dostların ümumi sayını hesablamaq üçün bütün sətri oxuya bilmərik, ancaq bir "sayma" sütununu oxuya bilərik. Əsas odur ki, məlumatları manipulyasiya edərkən "saymağı" yeniləməyi unutma. Bu. təkmilləşirik Seçim 2 (hesab):
RowKey
Sütunlar
vasya
1: Petya
2: Olya
3: Dasha
sayı: 3
Petya
1: Maşa
2: Vasya
sayı: 2
Birinci seçimlə müqayisədə:
- Məlumatların oxunması: "Vasya Olyanı oxuyurmu?" sualına cavab almaq üçün heç nə dəyişməyib => O(n)
- Məlumatların redaktəsi: dost əlavə etmək: Biz yeni dostun daxil edilməsini sadələşdirmişik, çünki indi bütün sətri oxumağa və onun sütunları üzərində təkrarlamağa ehtiyac yoxdur, ancaq “saymaq” sütununun dəyərini əldə edə bilərik və s. yeni dost daxil etmək üçün dərhal sütun nömrəsini təyin edin. Bu, hesablama mürəkkəbliyinin O(1)-ə qədər azalmasına gətirib çıxarır.
- Məlumatların dəyişdirilməsi: dostun silinməsi: Dostu silərkən, məlumatları bir xana sola “köçürərkən” I/O əməliyyatlarının sayını azaltmaq üçün də bu sütundan istifadə edə bilərik. Ancaq silinməli olanı tapmaq üçün sütunlar arasında təkrarlama ehtiyacı hələ də qalır, buna görə => O(n)
- Digər tərəfdən, indi məlumatları yeniləyərkən biz hər dəfə "saymaq" sütununu yeniləməliyik, lakin bu, O simvolları çərçivəsində nəzərə alınmayan daimi vaxt tələb edir.
Ümumiyyətlə, 2-ci variant bir az daha optimal görünür, lakin daha çox “inqilab əvəzinə təkamül” kimidir. “İnqilab” etmək üçün bizə lazım olacaq Seçim 3 (color).
Gəlin hər şeyi "alt-üstə çevirək": təyin edəcəyik sütun adı istifadəçi ID! Sütunda yazılacaqların özü bizim üçün artıq əhəmiyyət kəsb etmir, 1 nömrə olsun (ümumiyyətlə orada faydalı şeylər saxlanıla bilər, məsələn, “ailə/dostlar/s.” qrupu). Bu yanaşma, NoSQL verilənlər bazası ilə işləmək təcrübəsi olmayan hazırlıqsız "layman"ı təəccübləndirə bilər, lakin məhz bu yanaşma HBase potensialından bu vəzifədə daha səmərəli istifadə etməyə imkan verir:
RowKey
Sütunlar
vasya
Petya: 1
Olya: 1
Dasha: 1
Petya
Maşa: 1
Vasya: 1
Burada bir anda bir neçə üstünlük əldə edirik. Onları başa düşmək üçün yeni strukturu təhlil edək və hesablama mürəkkəbliyini qiymətləndirək:
- Məlumatların oxunması: Vasyanın Olyaya abunə olub-olmaması sualına cavab vermək üçün bir "Olya" sütununu oxumaq kifayətdir: əgər oradadırsa, cavab Doğrudur, yoxsa - Yanlış => O(1)
- Məlumatların redaktəsi: dost əlavə etmək: Dost əlavə etmək: sadəcə yeni “Dost ID” sütunu əlavə edin => O(1)
- Məlumatların dəyişdirilməsi: dostun silinməsi: sadəcə Dost ID sütununu silin => O(1)
Gördüyünüz kimi, bu saxlama modelinin əhəmiyyətli üstünlüyü ondan ibarətdir ki, bizə lazım olan bütün ssenarilərdə biz yalnız bir sütunla işləyirik, verilənlər bazasından bütün sətri oxumaqdan qaçırıq və üstəlik, bu sıranın bütün sütunlarını sadalayırıq. Orada dayana bilərdik, amma...
Siz çaşıb qala bilərsiniz və verilənlər bazasına daxil olarkən performansın optimallaşdırılması və I/O əməliyyatlarının azaldılması yolu ilə bir az da irəli gedə bilərsiniz. Tam əlaqə məlumatını birbaşa sətir açarının özündə saxlasaq necə olar? Yəni, userID.friendID kimi açarı birləşdirin? Bu halda sətrin sütunlarını oxumağa belə ehtiyacımız yoxdur (Seçim 4 (sətir)):
RowKey
Sütunlar
Vasya.Petya
Petya: 1
Vasya.Olya
Olya: 1
Vasya.Daşa
Dasha: 1
Petya.Maşa
Maşa: 1
Petya.Vasya
Vasya: 1
Aydındır ki, əvvəlki versiyada olduğu kimi, belə bir strukturda bütün məlumatların manipulyasiya ssenarilərinin qiymətləndirilməsi O(1) olacaqdır. Seçim 3 ilə fərq yalnız verilənlər bazasında I/O əməliyyatlarının səmərəliliyində olacaq.
Yaxşı, son "yay". 4-cü seçimdə cərgə açarının dəyişən uzunluğa malik olacağını görmək asandır və bu, bəlkə də performansa təsir edə bilər (burada xatırlayırıq ki, HBase məlumatları bayt dəsti kimi saxlayır və cədvəllərdəki sətirlər açara görə sıralanır). Üstəlik, bəzi ssenarilərdə işlənilməsi lazım olan bir ayırıcımız var. Bu təsiri aradan qaldırmaq üçün siz userID və friendID-dən hashlərdən istifadə edə bilərsiniz və hər iki hash sabit uzunluğa malik olduğundan, onları ayırıcı olmadan sadəcə birləşdirə bilərsiniz. Sonra cədvəldəki məlumatlar belə görünəcək (Seçim 5(hesh)):
RowKey
Sütunlar
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Petya: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
Olya: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
Dasha: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Maşa: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Vasya: 1
Aydındır ki, nəzərdən keçirdiyimiz ssenarilərdə belə strukturla işləməyin alqoritmik mürəkkəbliyi 4-cü variantla eyni olacaq - yəni O(1).
Ümumilikdə, bütün hesablama mürəkkəbliyi təxminlərimizi bir cədvəldə ümumiləşdirək:
Dost əlavə etmək
Dostunu yoxlayır
Bir dostun çıxarılması
Seçim 1 (defolt)
O (n)
O (n)
O (n)
Seçim 2 (hesab)
O (1)
O (n)
O (n)
Seçim 3 (sütun)
O (1)
O (1)
O (1)
Seçim 4 (sətir)
O (1)
O (1)
O (1)
Seçim 5 (hash)
O (1)
O (1)
O (1)
Gördüyünüz kimi, 3-5 variantları ən üstün olan kimi görünür və nəzəri cəhətdən sabit vaxtda bütün lazımi məlumatların manipulyasiya ssenarilərinin icrasını təmin edir. Tapşırığımızın şərtlərində, istifadəçinin bütün dostlarının siyahısını əldə etmək üçün heç bir açıq tələb yoxdur, lakin real layihə fəaliyyətlərində, yaxşı analitiklər kimi, belə bir vəzifənin yarana biləcəyini "gözləmək" bizim üçün yaxşı olardı və "bir saman səpin." Buna görə də mənim rəğbətim 3-cü variantın tərəfindədir. Amma çox güman ki, real layihədə bu sorğu artıq başqa vasitələrlə həll oluna bilərdi, ona görə də bütün problemə ümumi baxış olmadan bunu etməmək daha yaxşıdır. yekun nəticələr.
Təcrübənin hazırlanması
Yuxarıdakı nəzəri arqumentləri praktikada yoxlamaq istərdim - uzun həftə sonu yaranan ideyanın məqsədi bu idi. Bunu etmək üçün verilənlər bazasından istifadə üçün bütün təsvir edilmiş ssenarilərdə “şərti tətbiqetməmizin” işləmə sürətini, həmçinin sosial şəbəkənin (n) ölçüsünün artması ilə bu müddətin artımını qiymətləndirmək lazımdır. Bizi maraqlandıran və sınaq zamanı ölçəcəyimiz hədəf parametr bir “iş əməliyyatı” yerinə yetirmək üçün “şərti tətbiq”in sərf etdiyi vaxtdır. “Biznes əməliyyatı” dedikdə aşağıdakılardan birini nəzərdə tuturuq:
- Bir yeni dost əlavə olunur
- İstifadəçinin B istifadəçisinin dostu olub-olmadığını yoxlamaq
- Bir dostun çıxarılması
Beləliklə, ilkin bəyanatda göstərilən tələbləri nəzərə alaraq, yoxlama ssenarisi aşağıdakı kimi ortaya çıxır:
- Məlumat qeydi. Təsadüfi olaraq n ölçülü ilkin şəbəkə yaradın. “Real dünyaya” yaxınlaşmaq üçün hər bir istifadəçinin dostlarının sayı da təsadüfi dəyişəndir. "Şərti tətbiqimizin" bütün yaradılan məlumatları HBase-ə yazdığı vaxtı ölçün. Sonra yaranan vaxtı əlavə edilmiş dostların ümumi sayına bölün - bir "iş əməliyyatı" üçün orta vaxtı belə alırıq.
- Məlumatların oxunması. Hər bir istifadəçi üçün istifadəçinin onlara abunə olub-olmamasından asılı olmayaraq cavab almalı olduğunuz “şəxsiyyətlərin” siyahısını yaradın. Siyahının uzunluğu = istifadəçinin dostlarının təxminən sayıdır və yoxlanılan dostların yarısı üçün cavab “Bəli”, digər yarısı üçün isə “Xeyr” olmalıdır. Yoxlama elə ardıcıllıqla aparılır ki, “Bəli” və “Xeyr” cavabları bir-birini əvəz etsin (yəni hər ikinci halda 1 və 2 variantları üçün xəttin bütün sütunlarını keçməli olacağıq). Ümumi skrininq vaxtı daha sonra hər mövzu üzrə orta yoxlama vaxtını əldə etmək üçün sınaqdan keçirilmiş dostların sayına bölünür.
- Məlumatların silinməsi. İstifadəçidən bütün dostları silin. Üstəlik, silinmə ardıcıllığı təsadüfi olur (yəni biz məlumatları qeyd etmək üçün istifadə edilən orijinal siyahını "qarışdırırıq"). Ümumi yoxlama vaxtı daha sonra hər çek üçün orta vaxt əldə etmək üçün silinən dostların sayına bölünür.
Böyüdükcə zamanın necə dəyişdiyini görmək üçün 5 məlumat modeli variantının hər biri və sosial şəbəkənin müxtəlif ölçüləri üçün ssenarilər icra edilməlidir. Bir n daxilində şəbəkədəki əlaqələr və yoxlanılacaq istifadəçilərin siyahısı, əlbəttə ki, bütün 5 seçim üçün eyni olmalıdır.
Daha yaxşı başa düşmək üçün aşağıda n= 5 üçün yaradılan verilənlərin nümunəsi verilmişdir. Yazılı “generator” çıxış kimi üç ID lüğəti yaradır:
- birincisi daxil etmək üçündür
- ikincisi yoxlamaq üçündür
- üçüncü - silinmək üçün
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Gördüyünüz kimi, yoxlama üçün lüğətdə 10-dən çox olan bütün identifikatorlar, şübhəsiz ki, Yanlış cavabını verəcəkdir. “Dostların” daxil edilməsi, yoxlanılması və silinməsi tam olaraq lüğətdə göstərilən ardıcıllıqla həyata keçirilir.
Təcrübə işləyən bir noutbukda aparıldı Windows 10, burada HBase bir Docker konteynerində, Jupyter Notebook ilə Python isə digərində işləyirdi. Docker-ə 2 CPU nüvəsi və 2 GB RAM ayrıldı. "Saxta tətbiq"in simulyasiyası və test məlumatları yaratmaq və vaxt ölçmək üçün çərçivə də daxil olmaqla bütün məntiq Python dilində yazılmışdır. Kitabxana , seçim 5 üçün hashləri (MD5) hesablamaq üçün - hashlib
Müəyyən bir noutbukun hesablama gücünü nəzərə alaraq, n = 10, 30, … üçün buraxılış eksperimental olaraq seçildi. 170 – tam sınaq dövrünün ümumi iş vaxtı (bütün n variantları üçün bütün ssenarilər) daha az və ya çox ağlabatan olduqda və bir çay süfrəsi zamanı (orta hesabla 15 dəqiqə) uyğun olduqda.
Burada qeyd etmək lazımdır ki, bu təcrübədə biz ilk növbədə mütləq performans göstəricilərini qiymətləndirmirik. Hətta fərqli iki variantın nisbi müqayisəsi də tamamilə doğru olmaya bilər. İndi biz n-dən asılı olaraq vaxt dəyişikliyinin təbiəti ilə maraqlanırıq, çünki "test stendinin" yuxarıdakı konfiqurasiyasını nəzərə alaraq, təsadüfi və digər amillərin təsirindən "təmizlənmiş" vaxt təxminlərini əldə etmək çox çətindir ( və belə bir vəzifə qoyulmamışdı).
Təcrübə nəticəsi
İlk sınaq dostlar siyahısının doldurulmasına sərf olunan vaxtın necə dəyişməsidir. Nəticə aşağıdakı qrafikdədir.
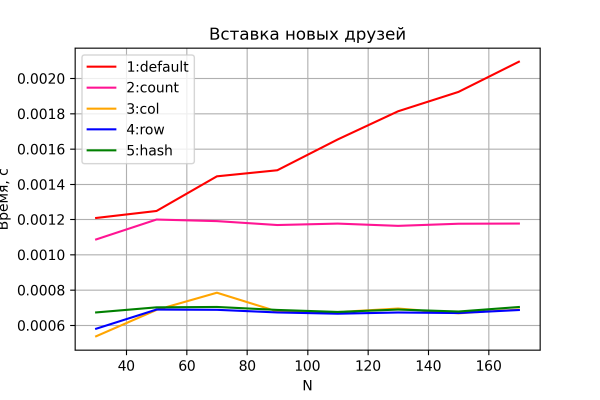
Seçimlər 3-5, gözlənildiyi kimi, şəbəkə ölçüsünün böyüməsindən və performansda fərqlənməyən fərqdən asılı olmayan, demək olar ki, sabit bir "iş əməliyyatı" vaxtını göstərir.
Variant 2 də sabit, lakin bir qədər pis performans göstərir, 2-3-ci seçimlərə nisbətən demək olar ki, tam 5 dəfə. Və bu sevinməyə bilməz, çünki bu, nəzəriyyə ilə əlaqələndirilir - bu versiyada HBase-dən / HBase-dən I/O əməliyyatlarının sayı düz 2 dəfə çoxdur. Bu, sınaq dəzgahımızın, prinsipcə, yaxşı dəqiqlik təmin etdiyinə dolayı sübut kimi xidmət edə bilər.
Seçim 1 də, gözlənildiyi kimi, ən yavaş olur və şəbəkənin ölçüsünə bir-birinin əlavə edilməsinə sərf olunan vaxtda xətti artım nümayiş etdirir.
İndi ikinci testin nəticələrinə baxaq.
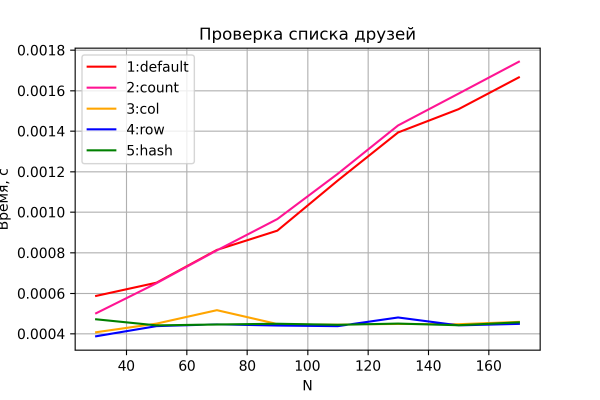
Seçimlər 3-5 yenidən gözlənildiyi kimi davranır - şəbəkənin ölçüsündən asılı olmayaraq sabit vaxt. Seçimlər 1 və 2 şəbəkə ölçüsü artdıqca və oxşar performans kimi zamanla xətti artım nümayiş etdirir. Üstəlik, 2-ci seçim bir az yavaş olur - yəqin ki, n böyüdükcə daha nəzərə çarpan əlavə "saymaq" sütununu yoxlamaq və emal etmək ehtiyacı ilə əlaqədardır. Amma bu müqayisənin dəqiqliyi nisbətən aşağı olduğu üçün hələ də heç bir nəticə çıxarmaqdan çəkinəcəyəm. Bundan əlavə, bu nisbətlər (hansı variant, 1 və ya 2 daha sürətlidir) qaçışdan qaçışa dəyişdi (asılılığın xarakterini qoruyarkən və "boyun və boyun").
Yaxşı, son qrafik silinmə testinin nəticəsidir.
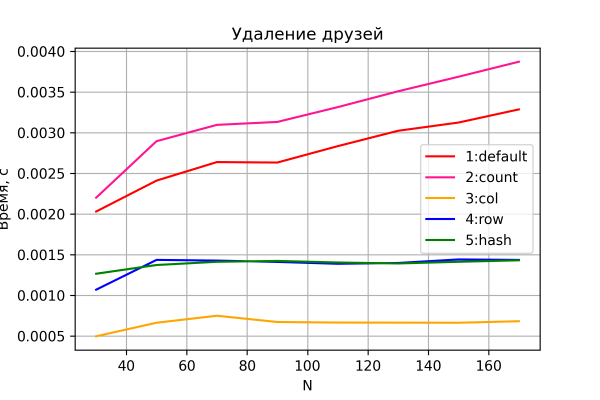
Yenə deyirəm, burada heç bir sürpriz yoxdur. Seçimlər 3-5 daimi vaxt aradan qaldırılması həyata keçirir.
Üstəlik, maraqlısı odur ki, 4 və 5-ci variantlar, əvvəlki ssenarilərdən fərqli olaraq, 3-cü variantdan nəzərəçarpacaq dərəcədə pis performans göstərir. Göründüyü kimi, sətirlərin silinməsi əməliyyatı, ümumiyyətlə, məntiqli olan sütunların silinməsi əməliyyatından daha bahalıdır.
Seçim 1 və 2, gözlənildiyi kimi, zamanın xətti artımını nümayiş etdirir. Eyni zamanda, seçim 2 ardıcıl olaraq 1-ci seçimdən daha yavaşdır - say sütununu "saxlamaq" üçün əlavə I/O əməliyyatı sayəsində.
Təcrübənin ümumi nəticələri:
- Seçimlər 3-5 HBase-dən istifadə etdikləri üçün daha yüksək səmərəlilik nümayiş etdirir; Üstəlik, onların performansı bir-birindən sabit olaraq fərqlənir və şəbəkənin ölçüsündən asılı deyil.
- Seçim 4 və 5 arasında fərq qeydə alınmadı. Amma bu o demək deyil ki, 5-ci variantdan istifadə edilməməlidir. Çox güman ki, sınaq dəzgahının performans xüsusiyyətləri nəzərə alınmaqla istifadə edilən eksperimental ssenari onun aşkarlanmasına imkan verməyib.
- Məlumatlarla "işgüzar əməliyyatlar" yerinə yetirmək üçün tələb olunan vaxtın artmasının xarakteri, ümumiyyətlə, bütün variantlar üçün əvvəllər əldə edilmiş nəzəri hesablamaları təsdiqlədi.
Epiloq
Bu təxmini təcrübələr mütləq həqiqət kimi qəbul edilməməlidir. Nəzərə alınmayan və nəticələri təhrif edən bir çox amil var (bu dalğalanmalar xüsusilə kiçik şəbəkə ölçüləri üçün qrafiklərdə görünür). Məsələn, happybase tərəfindən istifadə edilən qənaət sürəti, Pythonda yazdığım məntiqin həcmi və tətbiq metodu (kodun optimal şəkildə yazıldığını və ya bütün komponentlərdən effektiv şəkildə istifadə edildiyini iddia edə bilmərəm), ehtimal ki, HBase keşləmə xüsusiyyətləri və fon fəaliyyəti. Windows 10 Noutbukumda və s. Ümumilikdə, bütün nəzəri fərziyyələrin təcrübi olaraq doğru olduğu sübut edilmiş kimi nəticəyə gəlmək olar. Yaxud heç olmasa, onları belə bir qarşıdurma ilə təkzib etmək mümkün deyildi.
Yekun olaraq, HBase-də məlumat modellərini tərtib etməyə yeni başlayan hər kəs üçün tövsiyələr: əlaqəli verilənlər bazaları ilə işləmək təcrübəsinin xülasəsi və "əmrləri" xatırlayın:
- Dizayn edərkən, biz domen modelindən deyil, verilənlərin manipulyasiyasının tapşırığından və nümunələrindən çıxış edirik
- Effektiv giriş (tam cədvəl skan etmədən) – yalnız açarla
- Denormalizasiya
- Fərqli sıralarda fərqli sütunlar ola bilər
- Dinamiklərin dinamik tərkibi
Mənbə: www.habr.com
