

Qeyd. tərcümə.: Dünyaca məşhur Tinder xidmətinin əməkdaşları bu yaxınlarda öz infrastrukturlarını Kubernetes-ə köçürməyin bəzi texniki detallarını paylaşdılar. Proses təxminən iki il çəkdi və 8 min konteynerdə yerləşdirilən 200 xidmətdən ibarət K48-lərdə çox geniş miqyaslı platformanın işə salınması ilə nəticələndi. Tinder mühəndisləri hansı maraqlı çətinliklərlə qarşılaşdılar və hansı nəticələrə gəldilər?Bu tərcüməni oxuyun.

Niyə?
Təxminən iki il əvvəl Tinder platformasını Kubernetes-ə köçürmək qərarına gəldi. Kubernetes, Tinder komandasına dəyişməz yerləşdirmə yolu ilə minimum səylə konteynerləşdirməyə və istehsala keçməyə imkan verəcəkdir. (dəyişməz yerləşdirmə). Bu halda, proqramların yığılması, onların yerləşdirilməsi və infrastrukturun özü kodla unikal şəkildə müəyyən ediləcəkdir.
Biz həmçinin miqyaslılıq və sabitlik probleminin həllini axtarırdıq. Ölçəkləmə kritik hala gələndə biz tez-tez yeni EC2 nümunələrinin işə düşməsi üçün bir neçə dəqiqə gözləməli olurduq. Konteynerləri işə salmaq və trafikə dəqiqələr əvəzinə saniyələr ərzində xidmət etməyə başlamaq ideyası bizim üçün çox cəlbedici oldu.
Prosesin çətin olduğu ortaya çıxdı. 2019-cu ilin əvvəlində miqrasiyamız zamanı Kubernetes klasteri kritik kütləyə çatdı və biz trafikin həcmi, klaster ölçüsü və DNS ilə bağlı müxtəlif problemlərlə qarşılaşmağa başladıq. Yol boyu biz 200 xidmətin köçürülməsi və 1000 qovşaq, 15000 48000 pod və XNUMX XNUMX işləyən konteynerdən ibarət Kubernetes klasterinin saxlanması ilə bağlı bir çox maraqlı problemləri həll etdik.
Necə?
2018-ci ilin yanvar ayından biz miqrasiyanın müxtəlif mərhələlərindən keçmişik. Biz bütün xidmətlərimizi qablaşdıraraq və onları Kubernetes test bulud mühitlərində yerləşdirməklə başladıq. Oktyabr ayından başlayaraq biz bütün mövcud xidmətlərin Kubernetes-ə metodik şəkildə köçürülməsinə başladıq. Gələn ilin mart ayına qədər biz köçü tamamladıq və indi Tinder platforması yalnız Kubernetes-də işləyir.
Kubernetes üçün şəkillərin yaradılması
Kubernetes klasterində işləyən mikroservislər üçün 30-dan çox mənbə kodu anbarımız var. Bu depolardakı kod müxtəlif dillərdə (məsələn, Node.js, Java, Scala, Go) eyni dil üçün çoxlu işləmə mühiti ilə yazılmışdır.
Quraşdırma sistemi hər bir mikroservis üçün tam fərdiləşdirilə bilən "qurma kontekstini" təmin etmək üçün nəzərdə tutulmuşdur. O, adətən Dockerfile və shell əmrlərinin siyahısından ibarətdir. Onların məzmunu tamamilə fərdiləşdirilə bilər və eyni zamanda, bütün bu kontekstlər standartlaşdırılmış formata uyğun olaraq yazılmışdır. Quraşdırma kontekstlərinin standartlaşdırılması bir qurma sisteminə bütün mikroservisləri idarə etməyə imkan verir.
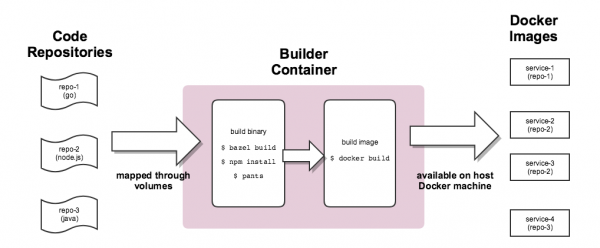
Şəkil 1-1. Builder konteyner vasitəsilə standartlaşdırılmış tikinti prosesi
İş vaxtları arasında maksimum ardıcıllığa nail olmaq üçün (iş vaxtı mühitləri) eyni qurma prosesi inkişaf və sınaq zamanı istifadə olunur. Çox maraqlı bir problemlə üzləşdik: bütün platformada tikinti mühitinin ardıcıllığını təmin etmək üçün bir yol hazırlamalı olduq. Buna nail olmaq üçün bütün montaj prosesləri xüsusi qabın içərisində aparılır. Inşaatçı.
Onun konteyner tətbiqi qabaqcıl Docker üsullarını tələb edirdi. Builder özəl Tinder repozitoriyalarına daxil olmaq üçün tələb olunan yerli istifadəçi ID və sirləri (məsələn, SSH açarı, AWS etimadnamələri və s.) miras alır. Quraşdırma artefaktlarını təbii şəkildə saxlamaq üçün mənbələrdən ibarət yerli qovluqları quraşdırır. Bu yanaşma performansı yaxşılaşdırır, çünki o, Builder konteyneri və host arasında qurma artefaktlarının surətini çıxarmaq ehtiyacını aradan qaldırır. Saxlanılan tikinti artefaktları əlavə konfiqurasiya olmadan təkrar istifadə edilə bilər.
Bəzi xidmətlər üçün kompilyasiya mühitini iş vaxtı mühitinə uyğunlaşdırmaq üçün başqa konteyner yaratmalı olduq (məsələn, Node.js bcrypt kitabxanası quraşdırma zamanı platformaya xas binar artefaktlar yaradır). Kompilyasiya prosesi zamanı tələblər xidmətlər arasında dəyişə bilər və son Dockerfile dərhal tərtib edilir.
Kubernetes klaster memarlığı və miqrasiyası
Klaster ölçüsünün idarə edilməsi
istifadə etmək qərarına gəldik kube-aws Amazon EC2 instansiyalarında avtomatlaşdırılmış klaster yerləşdirilməsi üçün. Başlanğıcda hər şey bir ümumi qovşaq hovuzunda işləyirdi. Resurslardan daha səmərəli istifadə etmək üçün iş yüklərini ölçü və nümunə növünə görə ayırmağın zəruriliyini tez başa düşdük. Məntiq ondan ibarət idi ki, bir neçə yüklənmiş çox yivli podların işə salınması onların çoxlu sayda tək yivli podlarla birgə mövcudluğundan daha çox performans baxımından daha proqnozlaşdırıla bilən oldu.
Sonda qərara gəldik:
- m5.4x böyük — monitorinq üçün (Prometey);
- c5.4x böyük - Node.js iş yükü üçün (bir yivli iş yükü);
- c5.2x böyük - Java və Go üçün (çox axınlı iş yükü);
- c5.4x böyük — idarəetmə paneli üçün (3 qovşaq).
Miqrasiya
Köhnə infrastrukturdan Kubernetesə keçmək üçün hazırlıq addımlarından biri xidmətlər arasında mövcud birbaşa əlaqəni yeni yük balanslaşdırıcılarına (Elastic Load Balancers (ELB)) yönləndirmək idi. Onlar virtual şəxsi buludun (VPC) xüsusi alt şəbəkəsində yaradılmışdır. Bu alt şəbəkə Kubernetes VPC-yə qoşulmuşdur. Bu, xidmət asılılığının xüsusi sırasını nəzərə almadan modulları tədricən köçürməyə imkan verdi.
Bu son nöqtələr hər bir yeni ELB-yə işarə edən CNAME-lərə malik olan DNS qeydlərinin çəkili dəstlərindən istifadə etməklə yaradılmışdır. Köçürmək üçün biz 0 çəkisi ilə Kubernetes xidmətinin yeni ELB-ni göstərən yeni giriş əlavə etdik. Sonra girişin Yaşamaq Vaxtını (TTL) 0 olaraq təyin etdik. Bundan sonra köhnə və yeni çəkilər yavaş-yavaş tənzimləndi və nəticədə yükün 100% yeni serverə göndərildi. Kommutasiya tamamlandıqdan sonra TTL dəyəri daha adekvat səviyyəyə qayıtdı.
Əlimizdə olan Java modulları aşağı TTL DNS ilə öhdəsindən gələ bilərdi, lakin Node proqramları bacarmadı. Mühəndislərdən biri əlaqə hovuz kodunun bir hissəsini yenidən yazdı və hər 60 saniyədən bir hovuzları yeniləyən menecerə bükdü. Seçilmiş yanaşma çox yaxşı işlədi və performansın nəzərəçarpacaq dərəcədə pisləşməsi olmadan.
Dərslər
Şəbəkə Parçasının Limitləri
8 yanvar 2019-cu il səhər tezdən Tinder platforması gözlənilmədən qəzaya uğradı. Həmin səhər platformanın gecikmə müddətinin əlaqəsiz artmasına cavab olaraq, klasterdəki podların və qovşaqların sayı artdı. Bu, ARP önbelleğinin bütün qovşaqlarımızda tükənməsinə səbəb oldu.
Üç parametr var LinuxARP keş yaddaşı ilə əlaqəli:

()
gc_thresh3 - bu sərt hədddir. Jurnalda “qonşu cədvəlinin daşması” qeydlərinin görünməsi o demək idi ki, hətta sinxron zibil yığımından (GC) sonra ARP keşində qonşu girişi saxlamaq üçün kifayət qədər yer yoxdur. Bu halda, nüvə sadəcə paketi tamamilə atdı.
İstifadə edirik Kubernetesdə şəbəkə quruluşu kimi. Paketlər VXLAN üzərindən ötürülür. VXLAN L2 şəbəkəsinin üstündə qaldırılmış L3 tunelidir. Texnologiya MAC-in-UDP (MAC Address-in-User Datagram Protocol) inkapsulyasiyasından istifadə edir və Layer 2 şəbəkə seqmentlərinin genişləndirilməsinə imkan verir. Fiziki məlumat mərkəzi şəbəkəsində nəqliyyat protokolu IP plus UDP-dir.
Şəkil 2–1. Flanel diaqramı ()
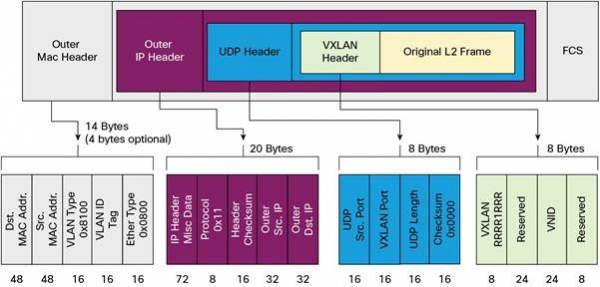
Şəkil 2-2. VXLAN paketi ()
Hər bir Kubernetes işçi qovşağı daha böyük /24 blokundan /9 maskası ilə virtual ünvan sahəsi ayırır. Hər bir node üçün bu marşrutlaşdırma cədvəlində bir giriş, ARP cədvəlində bir giriş (flanel.1 interfeysində) və keçid cədvəlində bir giriş (FDB). Onlar işçi node ilk dəfə işə salındıqda və ya hər dəfə yeni node aşkar edildikdə əlavə edilir.
Bundan əlavə, node-pod (və ya pod-pod) rabitəsi nəticədə interfeysdən keçir eth0 (yuxarıdakı Flanel diaqramında göstərildiyi kimi). Bu, hər bir müvafiq mənbə və təyinat hostu üçün ARP cədvəlində əlavə girişlə nəticələnir.
Bizim mühitdə bu cür ünsiyyət çox yaygındır. Kubernetesdəki xidmət obyektləri üçün ELB yaradılır və Kubernetes hər qovşağı ELB ilə qeyd edir. ELB podlar haqqında heç nə bilmir və seçilmiş qovşaq paketin son təyinatı olmaya bilər. Məsələ burasındadır ki, qovşaq ELB-dən paket qəbul edərkən onu qaydaları nəzərə alaraq hesab edir. iptables müəyyən bir xidmət üçün və təsadüfi olaraq başqa bir node üzrə pod seçir.
Uğursuzluq zamanı çoxluqda 605 qovşaq var idi. Yuxarıda göstərilən səbəblərə görə bu, əhəmiyyətini aradan qaldırmaq üçün kifayət idi gc_thresh3, bu standartdır. Bu baş verdikdə, nəinki paketlər atılmağa başlayır, həm də /24 maskası olan bütün Flanel virtual ünvan sahəsi ARP cədvəlindən yox olur. Node-pod rabitəsi və DNS sorğuları kəsilir (DNS klasterdə yerləşdirilir; ətraflı məlumat üçün bu məqalədə daha sonra oxuyun).
Bu problemi həll etmək üçün dəyərləri artırmaq lazımdır gc_thresh1, gc_thresh2 и gc_thresh3 və itkin şəbəkələri yenidən qeydiyyata almaq üçün Flannel-i yenidən başladın.
Gözlənilməz DNS miqyası
Miqrasiya prosesi zamanı biz trafiki idarə etmək və xidmətləri köhnə infrastrukturdan Kubernetesə tədricən köçürmək üçün DNS-dən fəal şəkildə istifadə etdik. Route53-də əlaqəli RecordSets üçün nisbətən aşağı TTL dəyərləri təyin etdik. Köhnə infrastruktur EC2 nümunələrində işləyərkən, həlledici konfiqurasiyamız Amazon DNS-ni göstərdi. Biz bunu təbii qəbul etdik və aşağı TTL-nin xidmətlərimizə və Amazon xidmətlərimizə (məsələn, DynamoDB kimi) təsiri əsasən diqqətdən kənarda qaldı.
Xidmətləri Kubernetes-ə köçürdükdə DNS-in saniyədə 250 min sorğu emal etdiyini gördük. Nəticədə tətbiqlər DNS sorğuları üçün daimi və ciddi fasilələrlə üzləşməyə başladı. Bu, DNS provayderini CoreDNS-ə (pik yüklənmədə 1000 nüvədə işləyən 120 pod-a çatan) optimallaşdırmaq və dəyişdirmək üçün inanılmaz səylərə baxmayaraq baş verdi.
Digər mümkün səbəbləri və həll yollarını araşdırarkən kəşf etdik , paket filtrləmə çərçivəsinə təsir edən yarış şərtlərini təsvir edir netfiltr в LinuxGördüyümüz zaman aşımları, artan sayğacla birlikdə, daxil_uğursuz Flanel interfeysindəki məlumatlar məqalənin nəticələrinə uyğun idi.
Problem Mənbə və Təyinat Şəbəkəsinin Ünvan Tərcüməsi (SNAT və DNAT) və sonradan cədvələ daxil olma mərhələsində baş verir. conntrack. Daxildə müzakirə edilən və icma tərəfindən təklif olunan həll yollarından biri DNS-i işçi node-nun özünə köçürmək idi. Bu halda:
- SNAT lazım deyil, çünki trafik node daxilində qalır. Onun interfeys vasitəsilə yönləndirilməsinə ehtiyac yoxdur eth0.
- DNAT tələb olunmur, çünki təyinat IP-si qovşaq üçün yerlidir və qaydalara uyğun olaraq təsadüfi seçilmiş pod deyil iptables.
Bu yanaşma ilə bağlı qalmaq qərarına gəldik. CoreDNS Kubernetes-də DaemonSet kimi yerləşdirildi və biz yerli node DNS serverini tətbiq etdik. qətnamə.conf bayraq qoyaraq hər bir pod --cluster-dns komandalar kubelet . Bu həllin DNS fasilələri üçün effektiv olduğu ortaya çıxdı.
Bununla belə, biz hələ də paket itkisi və sayğacda artım gördük daxil_uğursuz Flanel interfeysində. Bu, həll yolu həyata keçirildikdən sonra davam etdi, çünki biz yalnız DNS trafiki üçün SNAT və/və ya DNAT-ı aradan qaldıra bildik. Digər nəqliyyat növləri üçün yarış şəraiti qorunub saxlanılıb. Xoşbəxtlikdən, paketlərimizin əksəriyyəti TCP-dir və problem yaranarsa, onlar sadəcə olaraq yenidən ötürülür. Biz hələ də bütün trafik növləri üçün uyğun həll tapmağa çalışırıq.
Daha yaxşı yük balansı üçün Elçidən istifadə edin
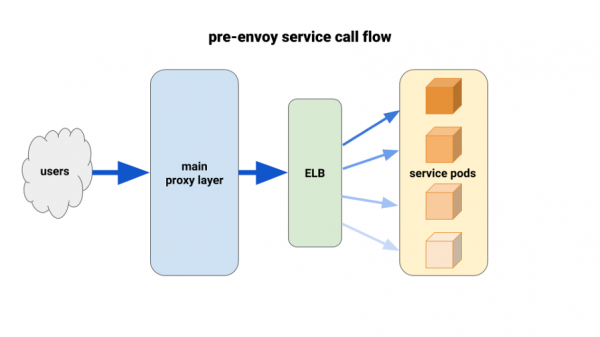
Backend xidmətlərini Kubernetes-ə köçürdükcə, podlar arasında balanssız yükdən əziyyət çəkməyə başladıq. Biz tapdıq ki, HTTP Keepalive ELB bağlantılarının hər bir yerləşdirmənin ilk hazır podlarında asılmasına səbəb oldu. Beləliklə, trafikin böyük hissəsi mövcud podların kiçik bir hissəsindən keçdi. Test etdiyimiz ilk həll, ən pis vəziyyət ssenariləri üçün MaxSurge-ni yeni yerləşdirmələrdə 100% təyin etmək idi. Təsiri daha böyük yerləşdirmələr baxımından əhəmiyyətsiz və perspektivsiz olduğu ortaya çıxdı.
İstifadə etdiyimiz başqa bir həll kritik xidmətlər üçün resurs sorğularını süni şəkildə artırmaq idi. Bu halda, yaxınlıqda yerləşdirilən podların digər ağır podlarla müqayisədə manevr etmək üçün daha çox yeri olacaq. Bu, uzunmüddətli perspektivdə də işləməyəcək, çünki bu, resurs itkisi olacaq. Bundan əlavə, Node proqramlarımız tək yivli idi və müvafiq olaraq yalnız bir nüvədən istifadə edə bilərdi. Yeganə real həll daha yaxşı yük balansından istifadə etmək idi.
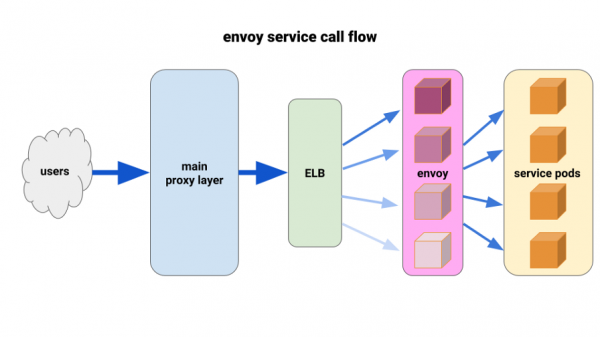
Biz çoxdan tam qiymətləndirmək istəyirik . Mövcud vəziyyət onu çox məhdud şəkildə yerləşdirməyə və dərhal nəticə əldə etməyə imkan verdi. Envoy, böyük SOA tətbiqləri üçün nəzərdə tutulmuş yüksək performanslı, açıq mənbəli, lay-XNUMX proksisidir. Avtomatik təkrar cəhdlər, elektrik açarları və qlobal sürətin məhdudlaşdırılması da daxil olmaqla qabaqcıl yük balanslaşdırma üsullarını tətbiq edə bilər. (Qeyd. tərcümə.: Bu barədə ətraflı oxuya bilərsiniz Elçiyə əsaslanan Istio haqqında.)
Biz aşağıdakı konfiqurasiya ilə gəldik: hər bir pod və bir marşrut üçün Envoy yan arabasına sahib olun və klasteri liman vasitəsilə yerli olaraq konteynerə birləşdirin. Potensial kaskadları minimuma endirmək və kiçik vuruş radiusunu saxlamaq üçün biz hər bir xidmət üçün Əlçatımlılıq Zonasına (AZ) bir olan Envoy front-proxy pods donanmasından istifadə etdik. Mühəndislərimizdən biri tərəfindən yazılmış sadə xidmət kəşfi mühərrikinə etibar etdilər və bu, sadəcə olaraq verilmiş xidmət üçün hər bir AZ-da podların siyahısını qaytardı.
Xidmət cəbhəsi elçiləri daha sonra bu xidmət kəşf mexanizmindən bir yuxarı klaster və marşrutla istifadə etdilər. Biz adekvat fasilələr təyin etdik, bütün elektrik açarı parametrlərini artırdıq və tək uğursuzluqlara kömək etmək və hamar yerləşdirmələri təmin etmək üçün minimal təkrar cəhd konfiqurasiyası əlavə etdik. Biz bu xidmət cəbhəsi elçilərinin hər birinin qarşısında bir TCP ELB yerləşdirdik. Əsas proksi təbəqəmizdən qorunma bəzi Envoy podlarında ilişib qalsa belə, onlar yenə də yükü daha yaxşı idarə edə bildilər və backenddə ən az_istək vasitəsilə balanslaşdırmaq üçün konfiqurasiya edilmişdilər.
Yerləşdirmə üçün biz həm proqram bölmələrində, həm də yan araba podlarında preStop çəngəlindən istifadə etdik. Qarmaq yan vaqon konteynerində yerləşən admin son nöqtəsinin vəziyyətinin yoxlanılması zamanı xətaya səbəb oldu və aktiv bağlantıların dayandırılmasına icazə vermək üçün bir müddət yuxuya getdi.
Bu qədər tez hərəkət etməyimizin səbəblərindən biri, tipik Prometheus quraşdırmasına asanlıqla inteqrasiya edə bildiyimiz təfərrüatlı ölçülərlə bağlıdır. Bu, konfiqurasiya parametrlərini tənzimləyərkən və trafiki yenidən bölüşdürərkən nə baş verdiyini dəqiq görməyə imkan verdi.
Nəticələr dərhal və göz qabağında idi. Biz ən balanssız xidmətlərlə başladıq və hal-hazırda klasterdə ən vacib 12 xidmətin qarşısında fəaliyyət göstərir. Bu il biz daha təkmil xidmət kəşfi, dövrə qırılması, kənar göstəricilərin aşkarlanması, sürətin məhdudlaşdırılması və izlənilməsi ilə tam xidmət şəbəkəsinə keçidi planlaşdırırıq.
Şəkil 3-1. Elçiyə keçid zamanı bir xidmətin CPU konvergensiyası
Son nəticə
Bu təcrübə və əlavə araşdırmalar vasitəsilə biz böyük Kubernetes klasterlərinin layihələndirilməsi, yerləşdirilməsi və istismarında güclü bacarıqlara malik güclü infrastruktur komandası yaratdıq. Bütün Tinder mühəndisləri indi konteynerləri qablaşdırmaq və Kubernetes-də tətbiqləri yerləşdirmək üçün bilik və təcrübəyə malikdirlər.
Köhnə infrastrukturda əlavə tutuma ehtiyac yarandıqda, yeni EC2 nümunələrinin işə salınması üçün bir neçə dəqiqə gözləməli olduq. İndi konteynerlər işə başlayır və trafiki dəqiqələr əvəzinə saniyələr ərzində emal etməyə başlayır. Tək bir EC2 nümunəsində birdən çox konteynerin planlaşdırılması da təkmilləşdirilmiş üfüqi konsentrasiyanı təmin edir. Nəticədə, 2019-cu ildə keçən illə müqayisədə EC2 xərclərinin əhəmiyyətli dərəcədə azalacağını proqnozlaşdırırıq.
Miqrasiya demək olar ki, iki il çəkdi, lakin biz onu 2019-cu ilin martında başa çatdırdıq. Hal-hazırda Tinder platforması yalnız 200 xidmət, 1000 qovşaq, 15 pod və 000 işləyən konteynerdən ibarət Kubernetes klasterində işləyir. İnfrastruktur artıq əməliyyat qruplarının yeganə sahəsi deyil. Bütün mühəndislərimiz bu məsuliyyəti bölüşür və yalnız koddan istifadə edərək tətbiqlərinin qurulması və yerləşdirilməsi prosesinə nəzarət edirlər.
Tərcüməçidən PS
Bloqumuzda bir sıra məqalələri də oxuyun:
- «.
- «.
- «.
- «.
- «.
- «.
- «.
- «.
- «.
- «.
Mənbə: www.habr.com
