

Paketi səliqəli R dilində ən məşhur kitabxanalardan birinin nüvəsinə daxil edilmişdir - səliqə-sahman.
Paketin əsas məqsədi verilənləri dəqiq formaya gətirməkdir.
Artıq Habré-də bu paketə həsr olunmuş, lakin 2015-ci ilə aiddir. Mən sizə bir neçə gün əvvəl onun müəllifi Hedley Wickham tərəfindən elan edilmiş ən aktual dəyişikliklər haqqında danışmaq istəyirəm.
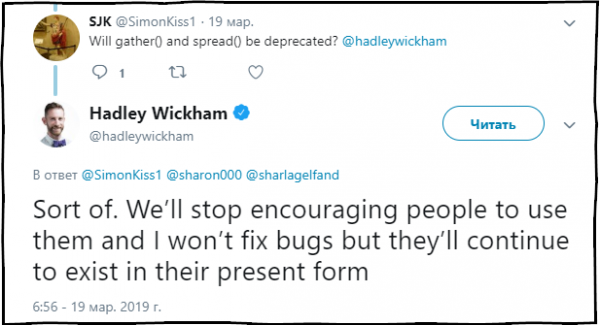
SJK: gather() və spread() köhnələcəkmi?
Hadley Wickham: Müəyyən dərəcədə. Biz artıq bu funksiyaların istifadəsini tövsiyə etməyəcəyik və onlarda olan səhvləri düzəltməyəcəyik, lakin onlar paketdə hazırkı vəziyyətdə olmağa davam edəcəklər.
Məzmun
Əgər məlumatların təhlili ilə maraqlanırsınızsa, mənimlə maraqlana bilərsiniz и kanallar. Məzmununun çoxu R dilinə həsr olunub.
TidyData konsepsiyası
Məqsəd səliqəli — məlumatları sözdə səliqəli formaya gətirməyə kömək edir. Səliqəli məlumat verilənlərdir:
- Hər bir dəyişən bir sütundadır.
- Hər bir müşahidə bir sətirdir.
- Hər bir dəyər bir hüceyrədir.
Təhlil apararkən səliqəli məlumatlarda təqdim olunan məlumatlarla işləmək daha asan və daha rahatdır.
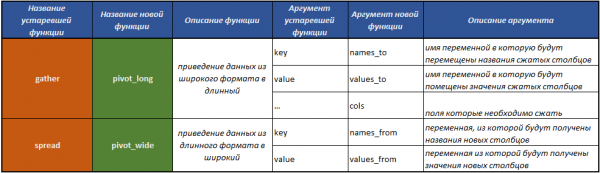
Tidyr paketinə daxil olan əsas funksiyalar
tidyr cədvəlləri çevirmək üçün hazırlanmış bir sıra funksiyaları ehtiva edir:
fill()— sütunda çatışmayan dəyərləri əvvəlki dəyərlərlə doldurmaq;separate()— separatordan istifadə edərək bir sahəni bir neçə yerə bölür;unite()— funksiyanın tərs hərəkətini, bir neçə sahəsi birləşdirmək əməliyyatını yerinə yetirirseparate();pivot_longer()— verilənləri geniş formatdan uzun formata çevirən funksiya;pivot_wider()- verilənləri uzun formatdan geniş formata çevirən funksiya. Funksiya tərəfindən yerinə yetirilən əməliyyatın tərs əməliyyatıpivot_longer().gather()köhnəlmişdir — verilənləri geniş formatdan uzun formata çevirən funksiya;spread()köhnəlmişdir - verilənləri uzun formatdan geniş formata çevirən funksiya. Funksiya tərəfindən yerinə yetirilən əməliyyatın tərs əməliyyatıgather().
Məlumatların geniş formatdan uzun formata və əksinə çevrilməsi üçün yeni konsepsiya
Əvvəllər bu cür transformasiya üçün funksiyalardan istifadə olunurdu gather() и spread(). Bu funksiyaların mövcud olduğu illər ərzində məlum oldu ki, əksər istifadəçilər, o cümlədən paketin müəllifi üçün bu funksiyaların adları və onların arqumentləri o qədər də aydın deyildi və onları tapmaqda və bu funksiyalardan hansının çevrildiyini başa düşməkdə çətinliklərə səbəb oldu. tarix çərçivəsi genişdən uzun formata və əksinə.
Bununla əlaqədar olaraq, in səliqəli Tarix çərçivələrini çevirmək üçün nəzərdə tutulmuş iki yeni, vacib funksiya əlavə edildi.
Yeni Xüsusiyyətlər pivot_longer() и pivot_wider() paketdəki bəzi xüsusiyyətlərdən ilhamlanıb cdata, John Mount və Nina Zumel tərəfindən yaradılmışdır.
tidyr 0.8.3.9000-ın ən son versiyasının quraşdırılması
Paketin yeni, ən aktual versiyasını quraşdırmaq üçün səliqəli 0.8.3.9000, yeni funksiyalar mövcud olduqda, aşağıdakı kodu istifadə edin.
devtools::install_github("tidyverse/tidyr")
Yazı zamanı bu funksiyalar yalnız GitHub-da paketin inkişaf etdirici versiyasında mövcuddur.
Yeni funksiyalara keçid
Əslində, köhnə skriptləri yeni funksiyalarla işləmək üçün köçürmək çətin deyil, daha yaxşı başa düşmək üçün köhnə funksiyaların sənədlərindən nümunə götürəcəyəm və eyni əməliyyatların yenilərindən istifadə edərək necə edildiyini göstərəcəyəm. pivot_*() funksiyaları.
Geniş formatı uzun formata çevirin.
Toplama funksiyası sənədlərindən nümunə kodu
# example
library(dplyr)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 0, 1),
Y = rnorm(10, 0, 2),
Z = rnorm(10, 0, 4)
)
# old
stocks_gather <- stocks %>% gather(key = stock,
value = price,
-time)
# new
stocks_long <- stocks %>% pivot_longer(cols = -time,
names_to = "stock",
values_to = "price")
Uzun formatın geniş formata çevrilməsi.
Yayılmış funksiya sənədlərindən nümunə kodu
# old
stocks_spread <- stocks_gather %>% spread(key = stock,
value = price)
# new
stock_wide <- stocks_long %>% pivot_wider(names_from = "stock",
values_from = "price")
Çünki ilə işləmək üçün yuxarıdakı nümunələrdə pivot_longer() и pivot_wider(), orijinal cədvəldə Səhmlərin arqumentlərdə heç bir sütun qeyd edilməyib adlar_to и dəyərlər_to onların adları dırnaq içərisində olmalıdır.
Yeni bir konsepsiya ilə işləməyə necə keçməyinizi ən asan başa düşməyə kömək edəcək bir cədvəl səliqəli.
Müəllifdən qeyd
Aşağıdakı mətnlərin hamısı adaptivdir, hətta pulsuz tərcümə deyərdim tidyverse kitabxanasının rəsmi saytından.
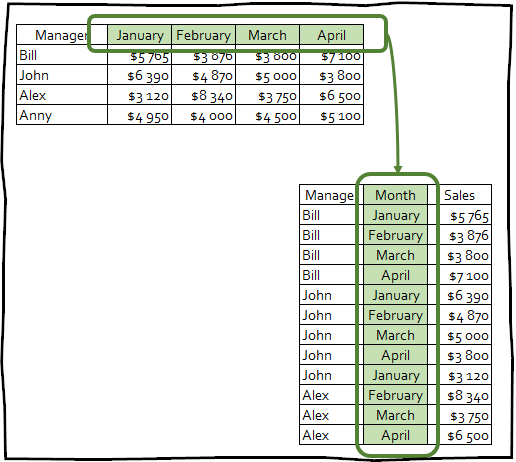
Məlumatların geniş formatdan uzun formata çevrilməsinin sadə nümunəsi
pivot_longer () — sütunların sayını azaltmaqla və sətirlərin sayını artırmaqla məlumat dəstlərini daha uzun edir.
Məqalədə təqdim olunan nümunələri işə salmaq üçün əvvəlcə lazımi paketləri birləşdirməlisiniz:
library(tidyr)
library(dplyr)
library(readr)Deyək ki, (digər şeylərlə yanaşı) insanların dinləri və illik gəlirləri barədə soruşulan sorğunun nəticələri ilə bir cədvəlimiz var:
#> # A tibble: 18 x 11
#> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Agnostic 27 34 60 81 76 137
#> 2 Atheist 12 27 37 52 35 70
#> 3 Buddhist 27 21 30 34 33 58
#> 4 Catholic 418 617 732 670 638 1116
#> 5 Don’t k… 15 14 15 11 10 35
#> 6 Evangel… 575 869 1064 982 881 1486
#> 7 Hindu 1 9 7 9 11 34
#> 8 Histori… 228 244 236 238 197 223
#> 9 Jehovah… 20 27 24 24 21 30
#> 10 Jewish 19 19 25 25 30 95
#> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>,
#> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>Bu cədvəl respondentlərin din məlumatlarını satırlarda ehtiva edir və gəlir səviyyələri sütun adları üzrə səpələnmişdir. Hər bir kateqoriyadan olan respondentlərin sayı din və gəlir səviyyəsinin kəsişməsindəki hüceyrə dəyərlərində saxlanılır. Cədvəli səliqəli, düzgün formata gətirmək üçün istifadə etmək kifayətdir pivot_longer():
pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")pew %>%
pivot_longer(cols = -religion, names_to = "income", values_to = "count")
#> # A tibble: 180 x 3
#> religion income count
#> <chr> <chr> <dbl>
#> 1 Agnostic <$10k 27
#> 2 Agnostic $10-20k 34
#> 3 Agnostic $20-30k 60
#> 4 Agnostic $30-40k 81
#> 5 Agnostic $40-50k 76
#> 6 Agnostic $50-75k 137
#> 7 Agnostic $75-100k 122
#> 8 Agnostic $100-150k 109
#> 9 Agnostic >150k 84
#> 10 Agnostic Don't know/refused 96
#> # … with 170 more rowsFunksiya Arqumentləri pivot_longer()
- Birinci arqument yaxalar, hansı sütunların birləşdirilməli olduğunu təsvir edir. Bu halda, istisna olmaqla, bütün sütunlar vaxt.
- arqument adlar_to birləşdirdiyimiz sütunların adlarından yaradılacaq dəyişənin adını verir.
- dəyərlər_to birləşdirilən sütunların xanalarının dəyərlərində saxlanılan məlumatlardan yaradılacaq dəyişənin adını verir.
Xüsusiyyətlər
Bu, paketin yeni funksionallığıdır səliqəli, köhnə funksiyalarla işləyərkən əvvəllər mövcud deyildi.
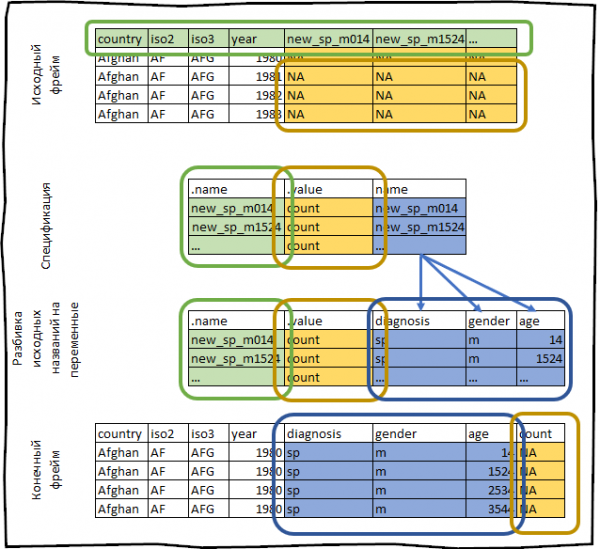
Spesifikasiya məlumat çərçivəsidir, hər sətri yeni çıxış tarixi çərçivəsindəki bir sütuna və aşağıdakılarla başlayan iki xüsusi sütuna uyğundur:
- . Adı orijinal sütun adını ehtiva edir.
- .dəyər xana dəyərlərini ehtiva edən sütunun adını ehtiva edir.
Spesifikasiyanın qalan sütunları yeni sütunun sıxılmış sütunların adını necə göstərəcəyini əks etdirir . Adı.
Spesifikasiya sütun adında saxlanılan metaməlumatları təsvir edir, hər bir sütun üçün bir sıra və hər dəyişən üçün bir sütun sütun adı ilə birləşdirilmişdir, bu tərif hazırda çaşqın görünə bilər, lakin bir neçə nümunəyə baxdıqdan sonra daha çox olacaq. daha aydın.
Spesifikasiyanın mahiyyəti ondan ibarətdir ki, siz çevrilən dataframe üçün yeni metadata əldə edə, dəyişdirə və müəyyən edə bilərsiniz.
Cədvəli geniş formatdan uzun formata çevirərkən spesifikasiyalarla işləmək üçün funksiyadan istifadə edin pivot_longer_spec().
Bu funksiyanın necə işləməsi ondan ibarətdir ki, o, istənilən tarix çərçivəsini götürür və yuxarıda təsvir edilən şəkildə metadatasını yaradır.
Nümunə olaraq paketlə təmin edilən who datasetini götürək səliqəli. Bu məlumat dəstində vərəmlə bağlı beynəlxalq səhiyyə təşkilatı tərəfindən verilən məlumatlar var.
who
#> # A tibble: 7,240 x 60
#> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534
#> <chr> <chr> <chr> <int> <int> <int> <int>
#> 1 Afghan… AF AFG 1980 NA NA NA
#> 2 Afghan… AF AFG 1981 NA NA NA
#> 3 Afghan… AF AFG 1982 NA NA NA
#> 4 Afghan… AF AFG 1983 NA NA NA
#> 5 Afghan… AF AFG 1984 NA NA NA
#> 6 Afghan… AF AFG 1985 NA NA NA
#> 7 Afghan… AF AFG 1986 NA NA NA
#> 8 Afghan… AF AFG 1987 NA NA NA
#> 9 Afghan… AF AFG 1988 NA NA NA
#> 10 Afghan… AF AFG 1989 NA NA NA
#> # … with 7,230 more rows, and 53 more variablesGəlin onun spesifikasiyasını quraq.
spec <- who %>%
pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")#> # A tibble: 56 x 3
#> .name .value name
#> <chr> <chr> <chr>
#> 1 new_sp_m014 count new_sp_m014
#> 2 new_sp_m1524 count new_sp_m1524
#> 3 new_sp_m2534 count new_sp_m2534
#> 4 new_sp_m3544 count new_sp_m3544
#> 5 new_sp_m4554 count new_sp_m4554
#> 6 new_sp_m5564 count new_sp_m5564
#> 7 new_sp_m65 count new_sp_m65
#> 8 new_sp_f014 count new_sp_f014
#> 9 new_sp_f1524 count new_sp_f1524
#> 10 new_sp_f2534 count new_sp_f2534
#> # … with 46 more rowssahələri ölkə, iso2, iso3 artıq dəyişənlərdir. Bizim vəzifəmiz sütunları çevirməkdir new_sp_m014 haqqında newrel_f65.
Bu sütunların adları aşağıdakı məlumatları saxlayır:
- Prefiks
new_sütunda yeni vərəm halları haqqında məlumatların olduğunu göstərir, cari tarix çərçivəsi yalnız yeni xəstəliklər haqqında məlumatları ehtiva edir, buna görə də cari kontekstdə bu prefiks heç bir məna daşımır. sp/rel/sp/epxəstəliyin diaqnostikası üsulunu təsvir edir.m/fxəstənin cinsi.014/1524/2535/3544/4554/65xəstənin yaş aralığı.
Funksiyadan istifadə edərək bu sütunları bölmək olar extract()müntəzəm ifadədən istifadə etməklə.
spec <- spec %>%
extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")#> # A tibble: 56 x 5
#> .name .value diagnosis gender age
#> <chr> <chr> <chr> <chr> <chr>
#> 1 new_sp_m014 count sp m 014
#> 2 new_sp_m1524 count sp m 1524
#> 3 new_sp_m2534 count sp m 2534
#> 4 new_sp_m3544 count sp m 3544
#> 5 new_sp_m4554 count sp m 4554
#> 6 new_sp_m5564 count sp m 5564
#> 7 new_sp_m65 count sp m 65
#> 8 new_sp_f014 count sp f 014
#> 9 new_sp_f1524 count sp f 1524
#> 10 new_sp_f2534 count sp f 2534
#> # … with 46 more rowsSütunu qeyd edin . Adı dəyişməz qalmalıdır, çünki bu, orijinal verilənlər toplusunun sütun adlarına daxil olan indeksimizdir.
Cins və yaş (sütunlar cins и yaş) sabit və məlum dəyərlərə malikdir, ona görə də bu sütunları amillərə çevirmək tövsiyə olunur:
spec <- spec %>%
mutate(
gender = factor(gender, levels = c("f", "m")),
age = factor(age, levels = unique(age), ordered = TRUE)
) Nəhayət, yaratdığımız spesifikasiyanı orijinal tarix çərçivəsinə tətbiq etmək üçün kim arqumentdən istifadə etməliyik spec funksiyasında pivot_longer().
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8
#> country iso2 iso3 year diagnosis gender age count
#> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int>
#> 1 Afghanistan AF AFG 1980 sp m 014 NA
#> 2 Afghanistan AF AFG 1980 sp m 1524 NA
#> 3 Afghanistan AF AFG 1980 sp m 2534 NA
#> 4 Afghanistan AF AFG 1980 sp m 3544 NA
#> 5 Afghanistan AF AFG 1980 sp m 4554 NA
#> 6 Afghanistan AF AFG 1980 sp m 5564 NA
#> 7 Afghanistan AF AFG 1980 sp m 65 NA
#> 8 Afghanistan AF AFG 1980 sp f 014 NA
#> 9 Afghanistan AF AFG 1980 sp f 1524 NA
#> 10 Afghanistan AF AFG 1980 sp f 2534 NA
#> # … with 405,430 more rowsSadəcə etdiyimiz hər şeyi sxematik şəkildə aşağıdakı kimi təsvir etmək olar:
Çox dəyərdən istifadə edən spesifikasiya (.value)
Yuxarıdakı nümunədə spesifikasiya sütunu .dəyər yalnız bir dəyərdən ibarət idi, əksər hallarda belədir.
Ancaq bəzən dəyərlərdə müxtəlif məlumat növləri olan sütunlardan məlumat toplamaq lazım olduqda vəziyyət yarana bilər. Köhnə funksiyadan istifadə spread() bunu etmək olduqca çətin olardı.
Aşağıdakı nümunə ondan götürülüb paketə məlumat cədvəli.
Gəlin təlim dataframe yaradaq.
family <- tibble::tribble(
~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2,
1L, "1998-11-26", "2000-01-29", 1L, 2L,
2L, "1996-06-22", NA, 2L, NA,
3L, "2002-07-11", "2004-04-05", 2L, 2L,
4L, "2004-10-10", "2009-08-27", 1L, 1L,
5L, "2000-12-05", "2005-02-28", 2L, 1L,
)
family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)#> # A tibble: 5 x 5
#> family dob_child1 dob_child2 gender_child1 gender_child2
#> <int> <date> <date> <int> <int>
#> 1 1 1998-11-26 2000-01-29 1 2
#> 2 2 1996-06-22 NA 2 NA
#> 3 3 2002-07-11 2004-04-05 2 2
#> 4 4 2004-10-10 2009-08-27 1 1
#> 5 5 2000-12-05 2005-02-28 2 1Yaradılmış tarix çərçivəsi hər sətirdə bir ailənin uşaqları haqqında məlumatları ehtiva edir. Ailələrin bir və ya iki uşağı ola bilər. Hər bir uşaq üçün doğum tarixi və cinsi haqqında məlumatlar verilir və hər bir uşaq üçün məlumatlar ayrı sütunlarda verilir; bizim vəzifəmiz bu məlumatları təhlil üçün düzgün formata gətirməkdir.
Nəzərə alın ki, bizdə hər bir uşaq haqqında məlumat olan iki dəyişən var: onların cinsi və doğum tarixi (prefiksli sütunlar) Vəftiz doğum tarixini, prefiksi olan sütunları ehtiva edir cins uşağın cinsini ehtiva edir). Gözlənilən nəticə onların ayrı sütunlarda görünməsidir. Bunu sütunun olduğu bir spesifikasiya yaradaraq edə bilərik .value iki fərqli məna daşıyacaq.
spec <- family %>%
pivot_longer_spec(-family) %>%
separate(col = name, into = c(".value", "child"))%>%
mutate(child = parse_number(child))
#> # A tibble: 4 x 3
#> .name .value child
#> <chr> <chr> <dbl>
#> 1 dob_child1 dob 1
#> 2 dob_child2 dob 2
#> 3 gender_child1 gender 1
#> 4 gender_child2 gender 2Beləliklə, yuxarıdakı kodun yerinə yetirdiyi hərəkətlərə addım-addım nəzər salaq.
pivot_longer_spec(-family)— ailə sütunundan başqa bütün mövcud sütunları sıxışdıran spesifikasiya yaradın.separate(col = name, into = c(".value", "child"))- sütunu bölün . Adıalt xəttdən istifadə edərək və nəticədə alınan dəyərləri sütunlara daxil edən mənbə sahələrinin adlarını ehtiva edən . .dəyər и uşaq.mutate(child = parse_number(child))— sahə dəyərlərini çevirmək uşaq mətndən rəqəmsal məlumat növünə qədər.
İndi əldə edilən spesifikasiyanı orijinal dataframe-ə tətbiq edə və cədvəli istədiyiniz formaya gətirə bilərik.
family %>%
pivot_longer(spec = spec, na.rm = T)#> # A tibble: 9 x 4
#> family child dob gender
#> <int> <dbl> <date> <int>
#> 1 1 1 1998-11-26 1
#> 2 1 2 2000-01-29 2
#> 3 2 1 1996-06-22 2
#> 4 3 1 2002-07-11 2
#> 5 3 2 2004-04-05 2
#> 6 4 1 2004-10-10 1
#> 7 4 2 2009-08-27 1
#> 8 5 1 2000-12-05 2
#> 9 5 2 2005-02-28 1Arqumentdən istifadə edirik na.rm = TRUE, çünki verilənlərin cari forması mövcud olmayan müşahidələr üçün əlavə cərgələr yaratmağa məcbur edir. Çünki 2-ci ailənin yalnız bir uşağı var, na.rm = TRUE 2-ci ailənin çıxışda bir sıra olacağına zəmanət verir.
Tarix çərçivələrinin uzun formatdan geniş formata çevrilməsi
pivot_wider() - tərs çevrilmədir və əksinə sıraların sayını azaltmaqla tarix çərçivəsinin sütunlarının sayını artırır.
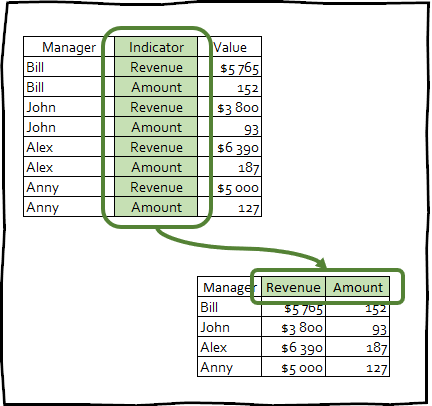
Bu cür transformasiya məlumatları dəqiq formaya gətirmək üçün çox nadir hallarda istifadə olunur, lakin bu texnika təqdimatlarda istifadə olunan pivot cədvəlləri yaratmaq və ya bəzi digər alətlərlə inteqrasiya üçün faydalı ola bilər.
Əslində funksiyalar pivot_longer() и pivot_wider() simmetrikdir və bir-birinə tərs hərəkətlər yaradır, yəni: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) и df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) orijinal df qaytaracaq.
Cədvəlin geniş formata çevrilməsinin ən sadə nümunəsi
Funksiyanın necə işlədiyini nümayiş etdirmək üçün pivot_wider() verilənlər bazasından istifadə edəcəyik balıq_görüşləri, bu, müxtəlif stansiyaların çay boyunca balıqların hərəkətini necə qeyd etdiyi barədə məlumatları saxlayır.
#> # A tibble: 114 x 3
#> fish station seen
#> <fct> <fct> <int>
#> 1 4842 Release 1
#> 2 4842 I80_1 1
#> 3 4842 Lisbon 1
#> 4 4842 Rstr 1
#> 5 4842 Base_TD 1
#> 6 4842 BCE 1
#> 7 4842 BCW 1
#> 8 4842 BCE2 1
#> 9 4842 BCW2 1
#> 10 4842 MAE 1
#> # … with 104 more rowsƏksər hallarda, hər bir stansiya üçün məlumatı ayrıca sütunda təqdim etsəniz, bu cədvəl daha informativ və istifadəsi asan olacaq.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 NA NA NA NA NA
#> 5 4847 1 1 1 NA NA NA NA NA NA NA
#> 6 4848 1 1 1 1 NA NA NA NA NA NA
#> 7 4849 1 1 NA NA NA NA NA NA NA NA
#> 8 4850 1 1 NA 1 1 1 1 NA NA NA
#> 9 4851 1 1 NA NA NA NA NA NA NA NA
#> 10 4854 1 1 NA NA NA NA NA NA NA NA
#> # … with 9 more rows, and 1 more variable: MAW <int>Bu məlumat dəsti yalnız stansiya tərəfindən balıq aşkar edildikdə məlumatları qeyd edir, yəni. hər hansı bir balıq hansısa stansiya tərəfindən qeydə alınmayıbsa, bu məlumat cədvəldə olmayacaq. Bu, çıxışın NA ilə doldurulacağı deməkdir.
Ancaq bu halda biz bilirik ki, rekordun olmaması balığın görünməməsi deməkdir, buna görə də arqumentdən istifadə edə bilərik. dəyərləri_doldur funksiyasında pivot_wider() və bu çatışmayan dəyərləri sıfırlarla doldurun:
fish_encounters %>% pivot_wider(
names_from = station,
values_from = seen,
values_fill = list(seen = 0)
)#> # A tibble: 19 x 12
#> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE
#> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 4842 1 1 1 1 1 1 1 1 1 1
#> 2 4843 1 1 1 1 1 1 1 1 1 1
#> 3 4844 1 1 1 1 1 1 1 1 1 1
#> 4 4845 1 1 1 1 1 0 0 0 0 0
#> 5 4847 1 1 1 0 0 0 0 0 0 0
#> 6 4848 1 1 1 1 0 0 0 0 0 0
#> 7 4849 1 1 0 0 0 0 0 0 0 0
#> 8 4850 1 1 0 1 1 1 1 0 0 0
#> 9 4851 1 1 0 0 0 0 0 0 0 0
#> 10 4854 1 1 0 0 0 0 0 0 0 0
#> # … with 9 more rows, and 1 more variable: MAW <int>Çox mənbə dəyişənlərindən sütun adının yaradılması
Təsəvvür edin ki, məhsul, ölkə və ilin birləşməsindən ibarət cədvəlimiz var. Test tarixi çərçivəsi yaratmaq üçün aşağıdakı kodu işlədə bilərsiniz:
df <- expand_grid(
product = c("A", "B"),
country = c("AI", "EI"),
year = 2000:2014
) %>%
filter((product == "A" & country == "AI") | product == "B") %>%
mutate(value = rnorm(nrow(.)))#> # A tibble: 45 x 4
#> product country year value
#> <chr> <chr> <int> <dbl>
#> 1 A AI 2000 -2.05
#> 2 A AI 2001 -0.676
#> 3 A AI 2002 1.60
#> 4 A AI 2003 -0.353
#> 5 A AI 2004 -0.00530
#> 6 A AI 2005 0.442
#> 7 A AI 2006 -0.610
#> 8 A AI 2007 -2.77
#> 9 A AI 2008 0.899
#> 10 A AI 2009 -0.106
#> # … with 35 more rowsBizim vəzifəmiz məlumat çərçivəsini genişləndirməkdir ki, bir sütun məhsul və ölkənin hər birləşməsi üçün məlumatları ehtiva etsin. Bunu etmək üçün sadəcə arqumentə keçin adlar_dan birləşdiriləcək sahələrin adlarını ehtiva edən vektor.
df %>% pivot_wider(names_from = c(product, country),
values_from = "value")#> # A tibble: 15 x 4
#> year A_AI B_AI B_EI
#> <int> <dbl> <dbl> <dbl>
#> 1 2000 -2.05 0.607 1.20
#> 2 2001 -0.676 1.65 -0.114
#> 3 2002 1.60 -0.0245 0.501
#> 4 2003 -0.353 1.30 -0.459
#> 5 2004 -0.00530 0.921 -0.0589
#> 6 2005 0.442 -1.55 0.594
#> 7 2006 -0.610 0.380 -1.28
#> 8 2007 -2.77 0.830 0.637
#> 9 2008 0.899 0.0175 -1.30
#> 10 2009 -0.106 -0.195 1.03
#> # … with 5 more rowsSiz həmçinin spesifikasiyaları funksiyaya tətbiq edə bilərsiniz pivot_wider(). Ancaq təqdim edildikdə pivot_wider() spesifikasiya əks çevrilmə edir pivot_longer(): Göstərilən sütunlar . Adı, dəyərlərdən istifadə edərək .dəyər və digər sütunlar.
Bu verilənlər bazası üçün, əgər siz hər bir mümkün ölkə və məhsul birləşməsinin məlumatda mövcud olanların deyil, öz sütununun olmasını istəyirsinizsə, fərdi spesifikasiya yarada bilərsiniz:
spec <- df %>%
expand(product, country, .value = "value") %>%
unite(".name", product, country, remove = FALSE)#> # A tibble: 4 x 4
#> .name product country .value
#> <chr> <chr> <chr> <chr>
#> 1 A_AI A AI value
#> 2 A_EI A EI value
#> 3 B_AI B AI value
#> 4 B_EI B EI valuedf %>% pivot_wider(spec = spec) %>% head()#> # A tibble: 6 x 5
#> year A_AI A_EI B_AI B_EI
#> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 2000 -2.05 NA 0.607 1.20
#> 2 2001 -0.676 NA 1.65 -0.114
#> 3 2002 1.60 NA -0.0245 0.501
#> 4 2003 -0.353 NA 1.30 -0.459
#> 5 2004 -0.00530 NA 0.921 -0.0589
#> 6 2005 0.442 NA -1.55 0.594Yeni tidyr konsepsiyası ilə işləməyin bir neçə qabaqcıl nümunəsi
Nümunə kimi ABŞ Census Income and Rent verilənlər bazasından istifadə edərək məlumatların təmizlənməsi.
Məlumat dəsti bizə_kirayə_gəlir 2017-ci il üçün ABŞ-ın hər bir ştatı üçün orta gəlir və icarə məlumatlarını ehtiva edir (paketdə mövcud olan məlumat dəsti səliqəli siyahıyaalma).
us_rent_income
#> # A tibble: 104 x 5
#> GEOID NAME variable estimate moe
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 01 Alabama income 24476 136
#> 2 01 Alabama rent 747 3
#> 3 02 Alaska income 32940 508
#> 4 02 Alaska rent 1200 13
#> 5 04 Arizona income 27517 148
#> 6 04 Arizona rent 972 4
#> 7 05 Arkansas income 23789 165
#> 8 05 Arkansas rent 709 5
#> 9 06 California income 29454 109
#> 10 06 California rent 1358 3
#> # … with 94 more rowsVerilənlərin verilənlər bazasında saxlandığı formada bizə_kirayə_gəlir onlarla işləmək son dərəcə əlverişsizdir, ona görə də sütunlarla məlumat dəsti yaratmaq istərdik: icarə, kirayə_moe, gəl, gəlir_moe. Bu spesifikasiyanı yaratmağın bir çox yolu var, lakin əsas məqam odur ki, biz dəyişən dəyərlərin hər bir birləşməsini yaratmalıyıq. təxmin / moevə sonra sütun adını yaradın.
spec <- us_rent_income %>%
expand(variable, .value = c("estimate", "moe")) %>%
mutate(
.name = paste0(variable, ifelse(.value == "moe", "_moe", ""))
)#> # A tibble: 4 x 3
#> variable .value .name
#> <chr> <chr> <chr>
#> 1 income estimate income
#> 2 income moe income_moe
#> 3 rent estimate rent
#> 4 rent moe rent_moeBu spesifikasiyanın təmin edilməsi pivot_wider() Bizə axtardığımız nəticəni verir:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6
#> GEOID NAME income income_moe rent rent_moe
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 01 Alabama 24476 136 747 3
#> 2 02 Alaska 32940 508 1200 13
#> 3 04 Arizona 27517 148 972 4
#> 4 05 Arkansas 23789 165 709 5
#> 5 06 California 29454 109 1358 3
#> 6 08 Colorado 32401 109 1125 5
#> 7 09 Connecticut 35326 195 1123 5
#> 8 10 Delaware 31560 247 1076 10
#> 9 11 District of Columbia 43198 681 1424 17
#> 10 12 Florida 25952 70 1077 3
#> # … with 42 more rowsDünya Bankı
Bəzən verilənlər toplusunu istədiyiniz formaya gətirmək bir neçə addım tələb edir.
Dataset world_bank_pop 2000-2018-ci illər arasında hər bir ölkənin əhalisi haqqında Dünya Bankının məlumatlarını ehtiva edir.
#> # A tibble: 1,056 x 20
#> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006`
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4
#> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2
#> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5
#> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1
#> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6
#> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0
#> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7
#> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0
#> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7
#> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0
#> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>,
#> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>,
#> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>Məqsədimiz öz sütununda hər dəyişən ilə səliqəli məlumat dəsti yaratmaqdır. Tam olaraq hansı addımların lazım olduğu bəlli deyil, lakin biz ən aşkar problemlə başlayacağıq: il bir neçə sütuna yayılmışdır.
Bunu düzəltmək üçün funksiyadan istifadə etməlisiniz pivot_longer().
pop2 <- world_bank_pop %>%
pivot_longer(`2000`:`2017`, names_to = "year")#> # A tibble: 19,008 x 4
#> country indicator year value
#> <chr> <chr> <chr> <dbl>
#> 1 ABW SP.URB.TOTL 2000 42444
#> 2 ABW SP.URB.TOTL 2001 43048
#> 3 ABW SP.URB.TOTL 2002 43670
#> 4 ABW SP.URB.TOTL 2003 44246
#> 5 ABW SP.URB.TOTL 2004 44669
#> 6 ABW SP.URB.TOTL 2005 44889
#> 7 ABW SP.URB.TOTL 2006 44881
#> 8 ABW SP.URB.TOTL 2007 44686
#> 9 ABW SP.URB.TOTL 2008 44375
#> 10 ABW SP.URB.TOTL 2009 44052
#> # … with 18,998 more rowsNövbəti addım göstərici dəyişənə baxmaqdır.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2
#> indicator n
#> <chr> <int>
#> 1 SP.POP.GROW 4752
#> 2 SP.POP.TOTL 4752
#> 3 SP.URB.GROW 4752
#> 4 SP.URB.TOTL 4752SP.POP.GROW əhalinin artımı olduğu halda, SP.POP.TOTL ümumi əhali və SP.URB. * eyni şey, ancaq şəhər yerləri üçün. Gəlin bu dəyərləri iki dəyişənə bölək: sahə - sahə (ümumi və ya şəhər) və faktiki məlumatları (əhali və ya artım) ehtiva edən dəyişən:
pop3 <- pop2 %>%
separate(indicator, c(NA, "area", "variable"))#> # A tibble: 19,008 x 5
#> country area variable year value
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 ABW URB TOTL 2000 42444
#> 2 ABW URB TOTL 2001 43048
#> 3 ABW URB TOTL 2002 43670
#> 4 ABW URB TOTL 2003 44246
#> 5 ABW URB TOTL 2004 44669
#> 6 ABW URB TOTL 2005 44889
#> 7 ABW URB TOTL 2006 44881
#> 8 ABW URB TOTL 2007 44686
#> 9 ABW URB TOTL 2008 44375
#> 10 ABW URB TOTL 2009 44052
#> # … with 18,998 more rowsİndi etməli olduğumuz tək şey dəyişəni iki sütuna bölməkdir:
pop3 %>%
pivot_wider(names_from = variable, values_from = value)#> # A tibble: 9,504 x 5
#> country area year TOTL GROW
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 ABW URB 2000 42444 1.18
#> 2 ABW URB 2001 43048 1.41
#> 3 ABW URB 2002 43670 1.43
#> 4 ABW URB 2003 44246 1.31
#> 5 ABW URB 2004 44669 0.951
#> 6 ABW URB 2005 44889 0.491
#> 7 ABW URB 2006 44881 -0.0178
#> 8 ABW URB 2007 44686 -0.435
#> 9 ABW URB 2008 44375 -0.698
#> 10 ABW URB 2009 44052 -0.731
#> # … with 9,494 more rowsƏlaqələrin siyahısı
Son bir nümunə, veb saytdan kopyalayıb yapışdırdığınız bir əlaqə siyahısının olduğunu təsəvvür edin:
contacts <- tribble(
~field, ~value,
"name", "Jiena McLellan",
"company", "Toyota",
"name", "John Smith",
"company", "google",
"email", "john@google.com",
"name", "Huxley Ratcliffe"
)Bu siyahının cədvəlini tərtib etmək olduqca çətindir, çünki hansı məlumatın hansı kontakta aid olduğunu müəyyən edən dəyişən yoxdur. Hər yeni kontaktın məlumatının "ad" ilə başladığını qeyd etməklə bunu düzəldə bilərik ki, biz unikal identifikator yarada və hər dəfə sahə sütununda "ad" dəyərini ehtiva edəndə onu bir artıra bilərik:
contacts <- contacts %>%
mutate(
person_id = cumsum(field == "name")
)
contacts#> # A tibble: 6 x 3
#> field value person_id
#> <chr> <chr> <int>
#> 1 name Jiena McLellan 1
#> 2 company Toyota 1
#> 3 name John Smith 2
#> 4 company google 2
#> 5 email john@google.com 2
#> 6 name Huxley Ratcliffe 3İndi hər bir əlaqə üçün unikal identifikatorumuz var, biz sahəni və dəyəri sütunlara çevirə bilərik:
contacts %>%
pivot_wider(names_from = field, values_from = value)#> # A tibble: 3 x 4
#> person_id name company email
#> <int> <chr> <chr> <chr>
#> 1 1 Jiena McLellan Toyota <NA>
#> 2 2 John Smith google john@google.com
#> 3 3 Huxley Ratcliffe <NA> <NA>Nəticə
Şəxsi fikrim budur ki, yeni konsepsiya səliqəli həqiqətən daha intuitivdir və funksionallıq baxımından köhnə funksiyalardan əhəmiyyətli dərəcədə üstündür spread() и gather(). Ümid edirəm bu məqalə sizə kömək etdi pivot_longer() и pivot_wider().
Mənbə: www.habr.com
