

Bu qeyd R - data.table üçün cədvəl məlumat emalı kitabxanasından istifadə edənlər üçün maraqlı olacaq və müxtəlif nümunələrdə onun istifadəsinin çevikliyini görməkdən məmnun ola bilər.
Yaxşı bir nümunədən ilhamlandı , və onun məqaləsini artıq oxuduğunuza ümid edərək, kodun optimallaşdırılması və performansa əsaslanaraq daha dərindən öyrənməyi təklif edirəm. məlumat cədvəli.
Giriş: Data.table haradan gəlir?
Yaxşı olar ki, kitabxana ilə bir az uzaqdan, yəni data.table obyektinin (bundan sonra DT) əldə oluna biləcəyi verilənlər strukturları ilə tanış olun.
Maşiv
Kod
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Belə strukturlardan biri massivdir (?base::massiv). Digər dillərdə olduğu kimi burada da massivlər çoxölçülüdür. Lakin maraqlısı odur ki, məsələn, iki ölçülü massiv matris sinfindən xassələri miras almağa başlayır. (?baza::matris) və birölçülü massiv də vacibdir ki, bu da vektordan (() miras almır.?base::vektor).
Anlamaq lazımdır ki, hər hansı bir obyektdə olan məlumatların növü funksiyadan istifadə edərək yoxlanılmalıdır baza::tip, uyğun olaraq daxili tip təsvirini qaytarır R Daxili - orijinal ilə əlaqəli dilin ümumi protokolu C.
Obyektin sinfini təyin etmək üçün başqa bir əmrdir baza::class, vektorlar vəziyyətində vektor tipini qaytarır (daxili olandan adla fərqlənir, həm də məlumat növünü başa düşməyə imkan verir).
Siyahı
Matris kimi də tanınan iki ölçülü massivdən siyahıya keçə bilərsiniz (?base::list).
Kod
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Bir anda bir neçə şey baş verir:
- Matrisin ikinci ölçüsü çökür, yəni biz eyni anda həm siyahı, həm də vektor alırıq.
- Beləliklə, siyahı bu siniflərdən miras qalır. Nəzərə almaq lazımdır ki, siyahı elementi massiv matrisinin xanasından bir (skalar) qiymətə uyğun olacaq.
Siyahı da vektor olduğu üçün ona bəzi vektor funksiyaları tətbiq oluna bilər.
Dataframe
Siz siyahıdan, matrisdən və ya vektordan verilənlər çərçivəsinə keçə bilərsiniz (?base::data.frame).
Kod
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Bunun maraqlı tərəfi: dataframe siyahıdan miras qalır! Dataframe sütunları siyahı hüceyrələridir. Siyahılara tətbiq edilən funksiyalardan istifadə etdikdə bu, daha sonra vacib olacaq.
məlumat cədvəli
DT əldə edin (?data.table::data.table)-dən ola bilər dataframe, siyahı, vektor və ya matris. Məsələn, bu kimi (yerində).
Kod
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Məlumat çərçivəsi kimi, DT-nin də siyahının xüsusiyyətlərini miras alması faydalıdır.
DT və yaddaş
R bazasındakı bütün digər obyektlərdən fərqli olaraq, DT-lər istinadla ötürülür. Əgər yeni yaddaş sahəsinə surət çıxarmaq lazımdırsa, sizə funksiya lazımdır data.table::copy ya da köhnə obyektdən seçim etmək lazımdır.
Kod
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Bununla da giriş yekunlaşır. DT R-də verilənlər strukturlarının inkişafının davamıdır ki, bu da əsasən dataframe sinfinin obyektləri üzərində yerinə yetirilən əməliyyatların genişlənməsi və sürətləndirilməsi hesabına baş verir. Eyni zamanda, digər primitivlərdən miras saxlanılır.
data.table xassələrindən istifadənin bəzi nümunələri
Siyahı kimi...
Dataframe və ya DT sətirləri üzərində təkrarlamaq yaxşı fikir deyil, çünki dildə loop kodu R çox yavaş C, lakin adətən daha kiçik olan sütunlar arasında dövrə vurmaq olduqca mümkündür. Sütunlardan keçərkən unutmayın ki, hər bir sütun siyahının elementidir və adətən vektordan ibarətdir. Vektorlar üzərində əməliyyatlar dilin əsas funksiyalarında yaxşı vektorlaşdırılıb. Siz həmçinin siyahılar və vektorlar üçün ümumi seçim operatorlarından istifadə edə bilərsiniz: `[[`, `$`.
Kod
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorlaşdırma
Böyük bir DT-nin sətirlərindən keçməyə ehtiyac varsa, ən yaxşı həll vektorlaşdırma ilə bir funksiya yazmaq olardı. Ancaq bu işləmirsə, o zaman dövrü xatırlamalısınız daxilində DT hələ də dövriyyədən daha sürətlidir Rüzərində həyata keçirildiyi üçün C.
Gəlin bunu 100K sıra ilə daha böyük bir nümunədə sınayaq. Vektor sütununa daxil olan sözlərdən ilk hərfi çıxaracağıq w.
Yenilənib
Kod
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Əvvəlcə sətirlər üzərində iterasiya edin:
Vahid: millisaniyələr
ifadə min
{ dt[, `:=`(birinci_l, siyahıdan çıxarıl(strsplit(w, bölün = " ", sabit = T))[1]), ilə = 1:nrow(dt)] } 439.6217
lq orta median uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
İkinci qaçış, burada vektorlaşdırma siyahını bir matrisə çevirərək və 1 indeksli dilimdə elementləri götürməklə baş verir (sonuncu vektorlaşdırmanın özüdür). Düzəliş: funksiya səviyyəsində vektorlaşdırma strsplit, vektoru giriş kimi qəbul edə bilər. Məlum olub ki, siyahını matrisə çevirmək proseduru vektorlaşdırmanın özündən daha çətindir, lakin bu halda vektorlaşdırılmamış versiyadan daha sürətlidir.
Vahid: millisaniyələr
ifadə min lq orta median uq max neval
{ dt[, `:=`(ilk_l, .(ilk_l_f(w))))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Median ilə sürətlənmə 3 dəfə.
Üçüncü qaçış, burada matrisə çevrilmə sxemi dəyişdirildi.
Vahid: millisaniyələr
ifadə min lq orta median uq max neval
{ dt[, `:=`(ilk_l, .(ilk_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Median ilə sürətlənmə 13 dəfə.
Bu məsələ ilə təcrübə etməlisiniz, nə qədər çox olsa, bir o qədər yaxşı olar.
Vektorlaşdırma ilə başqa bir nümunə, burada mətn də var, lakin o, real şəraitə yaxındır: müxtəlif uzunluqlu sözlər, müxtəlif sayda sözlər. İlk 3 sözü almalısınız. Bunun kimi:
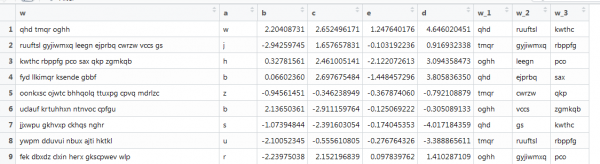
Burada əvvəlki funksiya işləmir, çünki vektorlar müxtəlif uzunluqlardadır və biz matrisin ölçüsünü təyin edirik. Gəlin, İnternetdə qazaraq bunu yenidən edək.
Kod
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Vahid: millisaniyələr
ifadə min lq orta median
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", sabit = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Skript orta hesabla 1 saniyə sürətlə işləyirdi. Pis deyil.
Bir zəncirlə bağlanır...
Zəncirləmə istifadə edərək DT obyektləri ilə işləyə bilərsiniz. Mötərizədə sintaksisi sağa, əsasən şəkərə əlavə etmək kimi görünür.
Kod
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Boruların arasından axır...
Eyni əməliyyatlar boru kəməri vasitəsilə edilə bilər, oxşar görünür, lakin funksional olaraq daha zəngindir, çünki yalnız DT deyil, hər hansı bir üsuldan istifadə edə bilərsiniz. DT-də bir sıra filtrlərlə sintetik məlumatlarımız üçün logistik reqressiya əmsallarını əldə edək.
Kod
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
DT daxilində statistika, maşın öyrənməsi və s
Lambda funksiyalarından istifadə edə bilərsiniz, lakin bəzən onları ayrı-ayrılıqda yaratmaq, bütün məlumatların təhlili boru xəttini yazmaq və davam etmək daha yaxşıdır - onlar DT daxilində işləyirlər. Nümunə yuxarıda göstərilən bütün xüsusiyyətlərlə, üstəlik, DT arsenalından bir neçə faydalı şeylə zənginləşdirilmişdir (məsələn, DT-nin özünə DT-nin daxilində keçid vasitəsilə daxil olmaq, bəzən ardıcıl olaraq deyil, belə ki, daxil edilir).
Kod
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
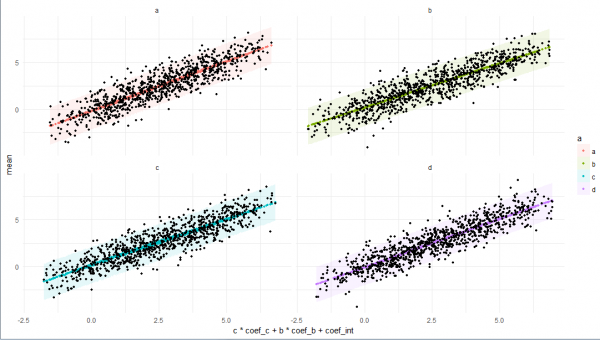
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Nəticə
Ümid edirəm ki, data.table kimi obyektin R siniflərindən miras qalması ilə bağlı xassələrindən başlayaraq səliqəli elementlərdən öz xüsusiyyətləri və mühiti ilə bitən tam, lakin təbii ki, tam olmayan şəklini yarada bildim. . Ümid edirəm ki, bu, sizə bu kitabxananı daha yaxşı öyrənməyə və iş üçün istifadə etməyə kömək edəcək əyləncə.
Təşəkkür edirik!
Tam kod
Kod
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Mənbə: www.habr.com
