


Yenidən obyekt aşkarlama vəzifəsi ilə qarşılaşırsınız. Prioritet məqbul dəqiqliklə sürətdir. Siz YOLOv3 arxitekturasını götürüb yenidən öyrədirsiniz. Dəqiqlik (mAp75) 0.95-dən çoxdur. Ancaq işləmə müddəti hələ də azdır. Lənət olsun.
Bu gün biz kvantlaşdırmanı atlayacağıq. Ancaq aşağıda baxacağıq Model Budama — dəqiqliyi itirmədən nəticə çıxarmağı sürətləndirmək üçün şəbəkənin lazımsız hissələrinin kəsilməsi. Bu, harada, nə qədər və necə kəsiləcəyini açıq şəkildə göstərir. Bunu əl ilə necə edəcəyini və harada avtomatlaşdırıla biləcəyini nəzərdən keçirəcəyik. Sonda Keras deposu mövcuddur.
Giriş
Əvvəlki işimdə, Permdəki Macroscop-da mən bir vərdiş inkişaf etdirdim: həmişə alqoritmin icra müddətinə nəzarət edirəm. Şəbəkə iş vaxtları həmişə kifayətlik filtrindən yoxlanılır. İstehsalda ən müasir məlumatlar adətən bu filtrdən keçmir, bu da məni budama aparmağa vadar etdi.
Budama müzakirə edilən köhnə bir mövzudur 2017-ci ildə. Əsas ideya müxtəlif qovşaqların çıxarılması ilə dəqiqliyi itirmədən öyrədilmiş şəbəkənin ölçüsünü azaltmaqdır. Gözəl səslənir, amma onun istifadəsi haqqında nadir hallarda eşidirəm. Ola bilsin ki, kifayət qədər tətbiq yoxdur, rus dilində məqalələr yoxdur, ya da hamı sadəcə olaraq nou-hau budamağı düşünür və susur.
Amma bunu anlamaq çətindir.
Biologiyaya baxış
Biologiyadan ideyaların Dərin Öyrənməyə daxil olması xoşuma gəlir. Onlar, təkamül kimi, etibar edilə bilər (ReLU-ya çox bənzədiyini bilirdinizmi ?)
Modelin budama prosesi də biologiyaya yaxındır. Şəbəkənin buradakı reaksiyasını beyin plastikliyi ilə müqayisə etmək olar. Kitabda bir neçə maraqlı nümunə var. :
- Yalnız bir yarım ilə doğulan qadının beyni yarımçıq qalan yarının funksiyalarını yerinə yetirmək üçün özünü yenidən proqramlaşdırıb.
- Oğlan beyninin görmə üçün məsul olan hissəsini vurdu. Zamanla beynin digər hissələri bu funksiyaları öz üzərinə götürdü. (Bunu təkrarlamağa çalışmayacağıq.)
Eynilə, modelinizdən bəzi zəif paketləri kəsə bilərsiniz. Bir çimdikdə, qalan paketlər kəsilmişləri əvəz etmək üçün istifadə edilə bilər.
Transfer Öyrənməyi sevirsiniz, yoxsa sıfırdan öyrənirsiniz?
Seçim nömrə bir. Siz Yolov3, Retina, Mask-RCNN və ya U-Net-də Transfer Öyrənməsindən istifadə edirsiniz. Lakin çox vaxt COCO-da olduğu kimi 80 obyekt sinifini tanımağa ehtiyacımız yoxdur. Təcrübəmə görə, 1-2 dərslə məhdudlaşır. 80 sinif üçün bir arxitekturanın həddindən artıq olduğunu düşünmək cazibədar ola bilər. Bu, arxitekturanın azaldılmasına ehtiyac olduğunu göstərir. Üstəlik, biz əvvəlcədən hazırlanmış çəkiləri itirmədən bunu etmək istərdik.
İkinci seçim. Ola bilsin ki, sizin çoxlu məlumat və hesablama resurslarınız var və ya sadəcə super xüsusi arxitekturaya ehtiyacınız var. Fərqi yoxdur. Amma siz şəbəkəni sıfırdan öyrədirsiniz. Adi prosedur məlumat strukturuna baxmaq, YÜKSƏN güclü arxitektura seçmək və həddən artıq uyğunlaşmanın qarşısını almaq üçün buraxılışları itələməkdir. Mən 0.6 məzuniyyət görmüşəm, Karl.
Hər iki halda şəbəkə azaldıla bilər. Məni motivasiya etdin. İndi budamanın nə olduğunu anlayaq.
Ümumi alqoritm
Qıvrımları çıxara biləcəyimizə qərar verdik. Bu olduqca sadə görünür:
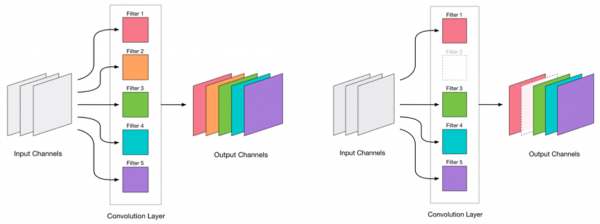
Hər hansı bir konvolyasiyanın aradan qaldırılması şəbəkəni vurğulayır, bu da adətən bəzi xətaların artmasına səbəb olur. Bir tərəfdən, bu səhv artımı, bükülmələri nə qədər yaxşı aradan qaldırdığımızın göstəricisidir (məsələn, böyük artım səhv bir şey etdiyimizi göstərir). Bununla belə, kiçik bir səhv artımı tamamilə məqbuldur və tez-tez kiçik bir LR ilə sonrakı yüngül yenidən təlim ilə düzəldilə bilər. Yenidən hazırlıq mərhələsini əlavə edək:
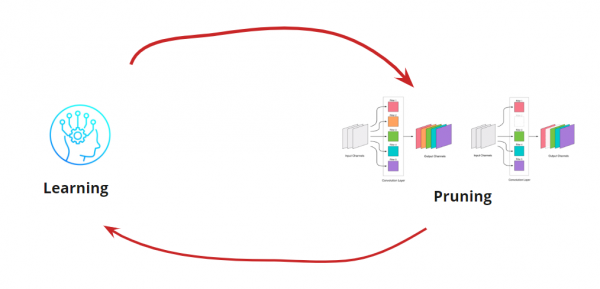
İndi öyrənməliyik<->Budama döngəmizi nə vaxt dayandırmaq istədiyimizi anlamalıyıq. Burada bəzi qeyri-adi ssenarilər ola bilər, məsələn, şəbəkəni müəyyən bir ölçüyə və işləmə sürətinə (məsələn, mobil cihazlar üçün) azaltmaq lazım olduqda. Bununla belə, ən çox yayılmış ssenari, səhv məqbul dəyərdən yüksək olana qədər dövrəni davam etdirməkdir. Şərti əlavə edək:
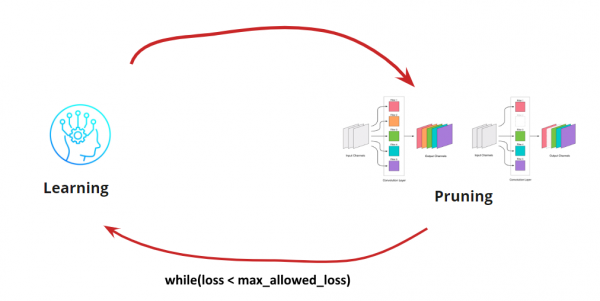
Beləliklə, alqoritm aydındır. İndi hansı qıvrımların aradan qaldırılmasını necə müəyyənləşdirəcəyimizi anlayaq.
Silinən qatları axtarın
Bəzi paketləri silməliyik. Tələsmək və hər birini "atmaq" pis fikirdir, baxmayaraq ki, işləyəcək. Ancaq bir qədər beyin qabiliyyətiniz varsa, bu barədə düşünə və silinmək üçün "zəif" paketləri müəyyən etməyə çalışa bilərsiniz. Bir neçə variant var:
- Kiçik çəki dəyərləri olan qıvrımların son qərara az töhfə verməsi fikri
- Orta və standart sapma nəzərə alınmaqla ən kiçik L1-balı. Bölüşdürmə xarakterinin təxmini ilə tamamlanır.
- Əhəmiyyətsiz qıvrımların daha dəqiq aşkarlanması, lakin çox vaxt və resurs tələb edir.
- P "SЂSѓRіReRμ
Hər bir variantın öz həyat qabiliyyəti və həyata keçirilməsi ilə bağlı mülahizələri var. Burada ən aşağı L1 balı olan variantı nəzərdən keçirəcəyik.
YOLOv3 üçün əl prosesi
Orijinal arxitektura qalıq blokları ehtiva edir. Ancaq dərin şəbəkələr üçün nə qədər sərin olsalar da, bir qədər maneədirlər. Çətinlik ondadır ki, biz bu təbəqələrdə fərqli indekslərlə müqayisələri silə bilmərik:
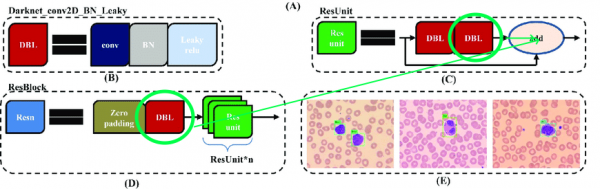
Buna görə də, uzlaşmaları sərbəst silə biləcəyimiz təbəqələri seçək:

İndi bir iş dövrü quraq:
- Boşaltma aktivləşdirmələri
- Nə qədər kəsiləcəyini anlayaq
- Biz kəsdik
- LR=1e-4 ilə 10 epoxanı öyrənirik
- Test
Qıvrımların boşaldılması müəyyən bir addımda nə qədər çıxarıla biləcəyini qiymətləndirmək üçün faydalıdır. Boşaltma nümunələri:
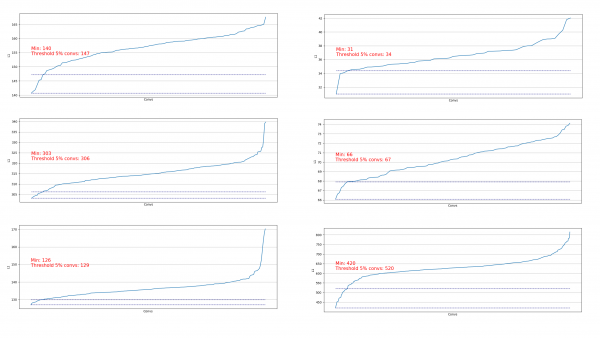
Biz görürük ki, demək olar ki, hər yerdə 5% qıvrımlar çox aşağı L1 normasına malikdir və biz onları aradan qaldıra bilərik. Hər addımda bu boşalma təkrarlanır, hansı təbəqələrin və neçəsinin çıxarılmasının mümkünlüyü barədə qiymətləndirmə aparılırdı.
Bütün proses dörd addım atdı (burada və hər yerdə rəqəmlər RTX 2060 Super üçündir):
| Addım | mAp75 | Parametrlərin sayı, milyon | Şəbəkə ölçüsü, MB | Orijinaldan, % | İş vaxtı, ms | Sünnət vəziyyəti |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | hamısının 5%-i |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | hamısının 5%-i |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 400-dən çox qıvrımlı təbəqələr üçün 15% |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 100-dən çox qıvrımlı təbəqələr üçün 10% |
2-ci addım bir müsbət təsir əlavə etdi: toplu ölçüsü 4 yaddaşa uyğunlaşdı və bu, yenidən hazırlıq prosesini əhəmiyyətli dərəcədə sürətləndirdi.
4-cü addımda proses dayandırıldı, çünki hətta uzunmüddətli əlavə təlim mAp75-i köhnə dəyərlərə qaldırmadı.
Nəticədə biz nəticə çıxarmağı sürətləndirə bildik 15%, ölçüsünü azaldın 35% və dəqiqliyini itirmə.
Daha sadə arxitekturalar üçün avtomatlaşdırma
Daha sadə şəbəkə arxitekturaları üçün (şərti əlavə, birləşdirici və qalıq bloklar olmadan) bütün konvolyusiya qatlarının işlənməsinə diqqət yetirmək və konvolyutsiyaların kəsilməsi prosesini avtomatlaşdırmaq olduqca mümkündür.
Mən bu variantı həyata keçirdim. .
Bu sadədir: sizə lazım olan tək şey itki funksiyası, optimallaşdırıcı və toplu generatorlardır:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)Lazım gələrsə, konfiqurasiya parametrlərini dəyişə bilərsiniz:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}Bundan əlavə, standart sapmaya əsaslanan məhdudiyyət tətbiq edilmişdir. Məqsəd, artıq "kifayət qədər" L1 ölçüləri ilə bükülmələr istisna olmaqla, silinəcək məlumatların bir hissəsini məhdudlaşdırmaqdır:
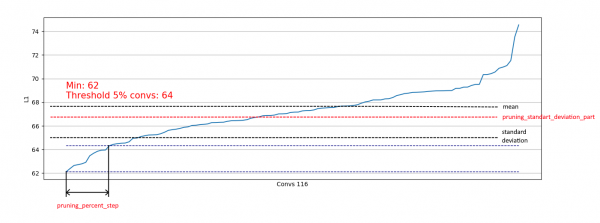
Bu yolla, biz yalnız sağa bənzər paylamalardan zəif konvolusiyaların silinməsinə icazə veririk və soldakı paylamalardan silinməsinə təsir göstərmirik:

Paylanma normallığa yaxınlaşdıqda, budama_standart_sapma_hissəsi əmsalı aşağıdakılardan seçilə bilər:
Mən 2 siqma tolerantlığı tövsiyə edirəm. Alternativ olaraq, siz bu funksiyaya məhəl qoymayaraq dəyəri < 1.0 olaraq tərk edə bilərsiniz.
Çıxış 1.0-a qədər normallaşdırılan bütün test üçün şəbəkə ölçüsünün, itkisinin və şəbəkə işləmə müddətinin qrafikidir. Məsələn, burada şəbəkə ölçüsü keyfiyyət itkisi olmadan demək olar ki, 2 dəfə azaldıldı (100 çəkisi olan kiçik bir konvolyusiya şəbəkəsi):
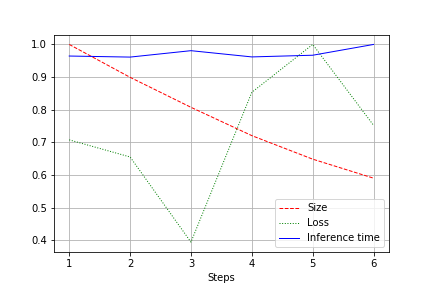
Qaçış sürəti normal dalğalanmalara məruz qalır və demək olar ki, dəyişməz qalıb. Bunun bir izahı var:
- Döngələrin sayı rahatdan (32, 64, 128) video kartlar üçün o qədər də əlverişli olmayanlara dəyişir - 27, 51 və s. Burada səhv edə bilərəm, amma çox güman ki, bunun təsiri var.
- Memarlıq geniş olmasa da, ardıcıldır. Genişliyi azaltmaqla, dərinliyi toxunulmaz buraxırıq. Bu, sürətə təsir etmədən yükü azaldır.
Buna görə də, təkmilləşdirmə qaçış zamanı CUDA yükünün 20-30% azalması ilə nəticələndi, lakin işləmə müddətinin azalması ilə nəticələndi.
Nəticələri
Gəlin əks etdirək. Biz iki budama variantını nəzərdən keçirdik: biri YOLOv3 üçün (əllə işləmə tələb olunur) və digəri daha sadə arxitekturaya malik şəbəkələr üçün. Aydındır ki, hər iki halda şəbəkə ölçüsünü azaltmaq və dəqiqliyi itirmədən sürətləndirməyə nail olmaq olar. Nəticələr:
- Ölçünün azaldılması
- Sürətlənmə qaçışı
- CUDA yükünün azaldılması
- Nəticədə eko-dostluq (Biz hesablama resurslarının gələcəkdə istifadəsini optimallaşdırırıq. Haradasa insan xoşbəxtdir )
əlavə
- Budama addımından sonra siz həmçinin kvantlaşdırmanı da düzəldə bilərsiniz (məsələn, TensorRT ilə)
- Tensorflow üçün imkanlar təmin edir . işləyir.
- Mən inkişaf etmək istəyirəm və kömək almaqdan şad olaram
Mənbə: www.habr.com
