

Məqalədə sadə (cüt) reqressiya xəttinin riyazi tənliyini təyin etməyin bir neçə yolu müzakirə olunur.
Burada nəzərdən keçirilən tənliyin həllinin bütün üsulları ən kiçik kvadratlar üsuluna əsaslanır. Metodları aşağıdakı kimi qeyd edirik:
- Analitik həll
- gradient eniş
- Stokastik Qradient Eniş
Düz xəttin tənliyini həll etmək yollarının hər biri üçün məqalədə əsasən kitabxanadan istifadə etmədən yazılanlara bölünən müxtəlif funksiyalar təqdim olunur. saysız və hesablamalar üçün istifadə olunanlar saysız. Məharətlə istifadə edildiyinə inanılır saysız hesablama xərclərini azaldacaq.
Bu məqalədəki bütün kodlar burada yazılmışdır piton 2.7 istifadə edərək Jupyter noutbuku. Mənbə kodu və nümunə məlumat faylı burada mövcuddur
Məqalə daha çox həm yeni başlayanlara, həm də süni intellektin çox geniş bölməsini – maşın öyrənməsini öyrənməyə tədricən yiyələnməyə başlayanlara yönəlib.
Materialı təsvir etmək üçün çox sadə bir nümunədən istifadə edək.
Nümunə şərtləri
Asılılığı xarakterizə edən beş dəyərimiz var Y etibarən X (Cədvəl №1):
Cədvəl №1 "Nümunənin şərtləri"

Biz bu dəyərləri fərz edəcəyik  ilin ayıdır və
ilin ayıdır və  - bu ay qazanc. Başqa sözlə, gəlir ilin ayından asılıdır və
- bu ay qazanc. Başqa sözlə, gəlir ilin ayından asılıdır və  - gəlirin asılı olduğu yeganə əlamət.
- gəlirin asılı olduğu yeganə əlamət.
Məsələn, həm ilin ayından gəlirin şərti asılılığı, həm də dəyərlərin sayı baxımından belədir - onlardan çox azdır. Bununla belə, belə bir sadələşdirmə, barmaqlarda deyildiyi kimi, yeni başlayanlar tərəfindən mənimsənilən materialı həmişə asanlıqla deyil, izah etməyə imkan verəcəkdir. Həm də rəqəmlərin sadəliyi nümunəni "kağızda" əhəmiyyətli əmək xərcləri olmadan həll etmək istəyənlərə imkan verəcəkdir.
Tutaq ki, misalda verilmiş asılılıq formanın sadə (cüt) reqressiyası xəttinin riyazi tənliyi ilə kifayət qədər yaxşı yaxınlaşdırıla bilər:

hara  gəlirlərin alındığı aydır,
gəlirlərin alındığı aydır,  - aya uyğun gəlir;
- aya uyğun gəlir;  и
и  təxmin edilən xəttin reqressiya əmsallarıdır.
təxmin edilən xəttin reqressiya əmsallarıdır.
Qeyd edək ki, əmsal  tez-tez təxmin edilən xəttin yamacı və ya qradiyenti kimi istinad edilir; olan məbləğdir
tez-tez təxmin edilən xəttin yamacı və ya qradiyenti kimi istinad edilir; olan məbləğdir  dəyişəndə
dəyişəndə  .
.
Aydındır ki, nümunədəki vəzifəmiz tənlikdə belə əmsalları seçməkdir  и
и  , bu zaman təxmin edilən gəlir dəyərlərinin aylar üzrə doğru cavablardan sapması, yəni. nümunədə təqdim olunan dəyərlər minimal olacaqdır.
, bu zaman təxmin edilən gəlir dəyərlərinin aylar üzrə doğru cavablardan sapması, yəni. nümunədə təqdim olunan dəyərlər minimal olacaqdır.
Ən kiçik kvadrat üsulu
Ən kiçik kvadratlar metoduna görə, kənarlaşma onu kvadratlaşdırmaqla hesablanmalıdır. Belə bir texnika, əks əlamətlər olduqda, sapmaların qarşılıqlı ödənilməsinin qarşısını almağa imkan verir. Məsələn, əgər bir halda, sapma +5 (beş əlavə) və digərində -5 (mənfi beş), onda sapmaların cəmi qarşılıqlı olaraq ləğv ediləcək və 0 (sıfır) olacaqdır. Sapmanın kvadratı deyil, modul xüsusiyyətindən istifadə etmək olar və sonra bütün kənarlaşmalar müsbət olacaq və yığılacaq. Bu nöqtədə ətraflı dayanmayacağıq, sadəcə olaraq qeyd edirik ki, hesablamaların rahatlığı üçün sapmanın kvadratına qoyulması adətdir.
Formula belə görünür, onun köməyi ilə kvadrat sapmaların (səhvlərin) ən kiçik cəmini təyin edəcəyik:

hara  doğru cavabların yaxınlaşması funksiyasıdır (yəni bizim hesabladığımız gəlir),
doğru cavabların yaxınlaşması funksiyasıdır (yəni bizim hesabladığımız gəlir),
 doğru cavablardır (nümunədə təqdim olunan gəlir),
doğru cavablardır (nümunədə təqdim olunan gəlir),
 nümunənin indeksidir (sapmanın müəyyən edildiyi ayın sayı)
nümunənin indeksidir (sapmanın müəyyən edildiyi ayın sayı)
Gəlin funksiyanı diferensiallayaq, qismən diferensial tənlikləri təyin edək və analitik həllə keçməyə hazır olaq. Ancaq əvvəlcə diferensiasiyanın nə olduğu haqqında qısa bir araşdırma aparaq və törəmənin həndəsi mənasını xatırlayaq.
Fərqləndirmə
Diferensiasiya funksiyanın törəməsinin tapılması əməliyyatıdır.
Törəmə nə üçündür? Funksiyanın törəməsi funksiyanın dəyişmə sürətini xarakterizə edir və bizə onun istiqamətini göstərir. Verilmiş nöqtədəki törəmə müsbət olarsa, funksiya artır, əks halda funksiya azalır. Modul törəməsinin dəyəri nə qədər böyükdürsə, funksiya qiymətlərinin dəyişmə sürəti də bir o qədər yüksəkdir, həmçinin funksiya qrafikinin yamacı da bir o qədər yüksəkdir.
Məsələn, Dekart koordinat sisteminin şərtlərində törəmənin M(0,0) nöqtəsindəki qiyməti bərabərdir. + 25 müəyyən bir nöqtədə, dəyərin dəyişdirildiyi zaman deməkdir  şərti vahid, dəyər ilə sağa
şərti vahid, dəyər ilə sağa  25 şərti vahid artır. Qrafikdə bu, dəyərlərdə kifayət qədər dik yüksəliş bucağı kimi görünür
25 şərti vahid artır. Qrafikdə bu, dəyərlərdə kifayət qədər dik yüksəliş bucağı kimi görünür  müəyyən bir nöqtədən.
müəyyən bir nöqtədən.
Başqa bir misal. Törəmənin dəyəri 0,1- dəyişdirildikdə deməkdir  bir şərti vahid üçün dəyər
bir şərti vahid üçün dəyər  yalnız 0,1 şərti vahid azalır. Eyni zamanda, funksiyanın qrafikində biz demək olar ki, nəzərəçarpacaq dərəcədə aşağı eniş müşahidə edə bilərik. Bir dağla bənzətmə apararaq, sanki çox sıldırım zirvələri götürməli olduğumuz əvvəlki nümunədən fərqli olaraq, dağdan yumşaq bir yamacla çox yavaş enirik :)
yalnız 0,1 şərti vahid azalır. Eyni zamanda, funksiyanın qrafikində biz demək olar ki, nəzərəçarpacaq dərəcədə aşağı eniş müşahidə edə bilərik. Bir dağla bənzətmə apararaq, sanki çox sıldırım zirvələri götürməli olduğumuz əvvəlki nümunədən fərqli olaraq, dağdan yumşaq bir yamacla çox yavaş enirik :)
Beləliklə, funksiyanı fərqləndirdikdən sonra  ehtimalla
ehtimalla  и
и  , 1-ci dərəcəli qismən törəmələrin tənliklərini təyin edirik. Tənlikləri təyin etdikdən sonra iki tənlik sistemi alacağıq, həll edərkən əmsalların bu cür dəyərlərini seçə bilərik.
, 1-ci dərəcəli qismən törəmələrin tənliklərini təyin edirik. Tənlikləri təyin etdikdən sonra iki tənlik sistemi alacağıq, həll edərkən əmsalların bu cür dəyərlərini seçə bilərik.  и
и  , bu zaman verilmiş nöqtələrdə müvafiq törəmələrin dəyərləri çox, çox az miqdarda dəyişir və analitik həll vəziyyətində heç dəyişmir. Başqa sözlə, tapılan əmsallarda səhv funksiyası minimuma çatacaq, çünki bu nöqtələrdə qismən törəmələrin dəyərləri sıfıra bərabər olacaqdır.
, bu zaman verilmiş nöqtələrdə müvafiq törəmələrin dəyərləri çox, çox az miqdarda dəyişir və analitik həll vəziyyətində heç dəyişmir. Başqa sözlə, tapılan əmsallarda səhv funksiyası minimuma çatacaq, çünki bu nöqtələrdə qismən törəmələrin dəyərləri sıfıra bərabər olacaqdır.
Beləliklə, diferensiasiya qaydalarına görə, əmsala nisbətən 1-ci dərəcəli qismən törəmənin tənliyi  forma alacaq:
forma alacaq:

ilə bağlı 1-ci dərəcəli qismən törəmə tənlik  forma alacaq:
forma alacaq:

Nəticədə kifayət qədər sadə analitik həlli olan tənliklər sistemi əldə etdik:
başlanğıc{tənlik*}
başlamaq{hallar}
na + bsumlimits_{i=1}^nx_i - sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i - sumlimits_{i=1}^ny_i) = 0
son{hallar}
son{tənlik*}
Tənliyi həll etməzdən əvvəl əvvəlcədən yükləyək, yüklənmənin düzgünlüyünü yoxlayaq və verilənləri formatlayaq.
Məlumatların yüklənməsi və formatlanması
Qeyd etmək lazımdır ki, analitik həll üçün və gələcəkdə gradient və stoxastik gradient enişi üçün kodu iki variasiyada istifadə edəcəyik: kitabxanadan istifadə etməklə. saysız və ondan istifadə etmədən, onda müvafiq məlumat formatına ehtiyacımız var (koda bax).
Məlumat yükləmə və emal kodu
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Vizualizasiya
İndi biz, birincisi, məlumatları yüklədikdən, ikincisi, yükləmənin düzgünlüyünü yoxladıqdan və nəhayət məlumatları formatlaşdırdıqdan sonra ilk vizuallaşdırmanı həyata keçirəcəyik. Çox vaxt bu üsuldan istifadə olunur cüt süjet kitabxanalar Dəniz doğulmuş. Bizim nümunəmizdə sayların məhdudluğu səbəbindən kitabxanadan istifadə etməyin mənası yoxdur Dəniz doğulmuş. Adi kitabxanadan istifadə edəcəyik matplotlib və yalnız səpələnmə xəttinə baxın.
Scatter Plot Kodu
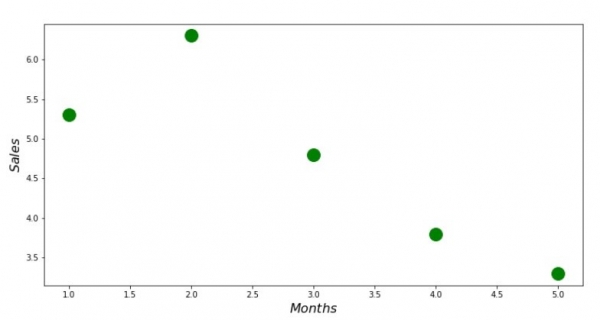
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Qrafik No1 “Gəlirin ilin ayından asılılığı”
Analitik həll
Ən çox yayılmış vasitələrdən istifadə edirik python və tənliklər sistemini həll edin:
başlanğıc{tənlik*}
başlamaq{hallar}
na + bsumlimits_{i=1}^nx_i - sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i - sumlimits_{i=1}^ny_i) = 0
son{hallar}
son{tənlik*}
Kramerin qaydasına görə ümumi determinantı, həmçinin müəyyənediciləri tapın  və
və  , bundan sonra müəyyənedicinin bölünməsi
, bundan sonra müəyyənedicinin bölünməsi  ümumi təyinediciyə - əmsalı tapın
ümumi təyinediciyə - əmsalı tapın  , eynilə əmsalı tapırıq
, eynilə əmsalı tapırıq  .
.
Analitik həll kodu
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Əldə etdiyimiz budur:

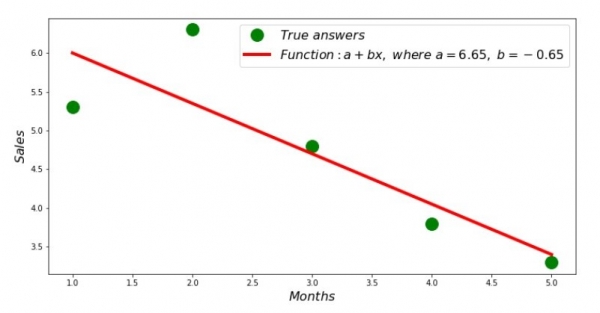
Beləliklə, əmsalların dəyərləri tapılır, kvadrat sapmaların cəmi müəyyən edilir. Tapılmış əmsallara uyğun olaraq səpilmə histoqramı üzərində düz xətt çəkək.
Reqressiya xətti kodu
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Diaqram №2 "Düzgün və hesablanmış cavablar"
Hər ay üçün sapmaların qrafikinə baxa bilərsiniz. Bizim vəziyyətimizdə ondan heç bir əhəmiyyətli praktiki dəyər əldə etməyəcəyik, lakin sadə xətti reqressiya tənliyinin gəlirin ilin ayından asılılığını nə dərəcədə yaxşı xarakterizə etdiyinə dair maraqları təmin edəcəyik.
Sapma qrafiki kodu
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Diaqram № 3 "Sayma,%"
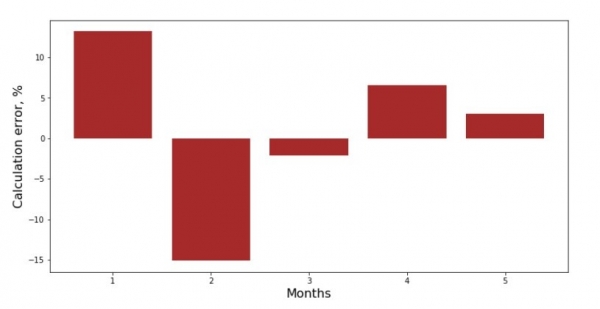
Mükəmməl deyil, amma işimizi gördük.
Bir funksiya yazaq ki, əmsalları təyin edək  и
и  kitabxanadan istifadə edir saysız, daha dəqiq desək, iki funksiya yazacağıq: biri psevdo-ters matrisdən istifadə etməklə (proses hesablama baxımından mürəkkəb və qeyri-sabit olduğundan praktikada tövsiyə edilmir), digəri isə matris tənliyindən istifadə etməklə.
kitabxanadan istifadə edir saysız, daha dəqiq desək, iki funksiya yazacağıq: biri psevdo-ters matrisdən istifadə etməklə (proses hesablama baxımından mürəkkəb və qeyri-sabit olduğundan praktikada tövsiyə edilmir), digəri isə matris tənliyindən istifadə etməklə.
Analitik Həll Kodu (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npƏmsalları müəyyən etmək üçün sərf olunan vaxtı müqayisə edin  и
и  , təqdim olunan 3 üsula görə.
, təqdim olunan 3 üsula görə.
Hesablama vaxtının hesablanması üçün kod
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Kiçik bir məlumat miqdarında, Cramer metodundan istifadə edərək əmsalları tapan "öz-özünə yazılmış" funksiya irəli gəlir.
İndi əmsalları tapmaq üçün başqa yollara keçə bilərsiniz  и
и  .
.
gradient eniş
Əvvəlcə gradientin nə olduğunu müəyyən edək. Sadə şəkildə desək, gradient funksiyanın maksimum artım istiqamətini göstərən seqmentdir. Qradiyentin göründüyü yerdə yoxuşa dırmaşmağa bənzətməklə, dağın zirvəsinə ən dik qalxma var. Dağ nümunəsini inkişaf etdirərək, unutmayın ki, mümkün qədər tez aşağıya, yəni minimuma - funksiyanın artmadığı və azalmadığı yerə çatmaq üçün həqiqətən ən dik eniş lazımdır. Bu zaman törəmə sıfır olacaq. Ona görə də bizə qradiyent yox, antiqradient lazımdır. Antiqradienti tapmaq üçün sadəcə qradiyenti vurmaq lazımdır -1 (mənfi bir).
Diqqət edək ki, bir funksiyanın bir neçə minimumu ola bilər və aşağıda təklif olunan alqoritmə uyğun olaraq onlardan birinə enərək, tapılandan aşağı ola biləcək başqa bir minimum tapa bilməyəcəyik. Rahatlayın, təhlükədə deyilik! Bizim vəziyyətimizdə funksiyamızdan bəri vahid minimumla məşğul oluruq  qrafikdə adi paraboladır. Və hamımızın məktəb riyaziyyat kursundan çox yaxşı bildiyimiz kimi, parabolanın yalnız bir minimumu var.
qrafikdə adi paraboladır. Və hamımızın məktəb riyaziyyat kursundan çox yaxşı bildiyimiz kimi, parabolanın yalnız bir minimumu var.
Qradiyentin nə üçün lazım olduğunu və qradiyentin seqment olduğunu, yəni eyni əmsalları olan verilmiş koordinatları olan bir vektor olduğunu anladıqdan sonra  и
и  gradient enişini həyata keçirə bilərik.
gradient enişini həyata keçirə bilərik.
Başlamazdan əvvəl enmə alqoritmi haqqında bir neçə cümlə oxumağı təklif edirəm:
- Əmsalların koordinatlarını psevdo-təsadüfi olaraq təyin edirik
 и . Nümunəmizdə sıfıra yaxın əmsalları təyin edəcəyik. Bu ümumi bir təcrübədir, lakin hər bir işin öz təcrübəsi ola bilər.
и . Nümunəmizdə sıfıra yaxın əmsalları təyin edəcəyik. Bu ümumi bir təcrübədir, lakin hər bir işin öz təcrübəsi ola bilər. - Koordinatdan nöqtədə 1-ci dərəcəli qismən törəmənin qiymətini çıxarın . Deməli, törəmə müsbətdirsə, funksiya artır. Buna görə də, törəmənin dəyərini çıxararaq, böyümənin əks istiqamətində, yəni enmə istiqamətində hərəkət edəcəyik. Törəmə mənfi olarsa, bu nöqtədə funksiya azalır və törəmənin dəyərini çıxarır, biz enişə doğru irəliləyirik.
- Bənzər bir əməliyyatı koordinatla həyata keçiririk : nöqtədə qismən törəmənin qiymətini çıxarın .
- Minimumdan tullanmamaq və dərin kosmosa uçmamaq üçün addım ölçüsünü enmə istiqamətində təyin etmək lazımdır. Ümumiyyətlə, hesablamaların dəyərini azaltmaq üçün addımı necə düzgün qurmaq və eniş zamanı onu necə dəyişdirmək barədə bütöv bir məqalə yazmaq olar. Ancaq indi bir az fərqli vəzifəmiz var və addım ölçüsünü elmi "poke" üsulu ilə və ya sadə insanlarda deyildiyi kimi, empirik olaraq təyin edəcəyik.
- Verilmiş koordinatlardan çıxdıqdan sonra и törəmələrin dəyərlərini çıxarsaq, yeni koordinatlar alırıq и . Artıq hesablanmış koordinatlardan növbəti addımı (çıxma) edirik. Və beləliklə, tələb olunan yaxınlaşma əldə olunana qədər dövr təkrar-təkrar başlayır.
 и
и  . Nümunəmizdə sıfıra yaxın əmsalları təyin edəcəyik. Bu ümumi bir təcrübədir, lakin hər bir işin öz təcrübəsi ola bilər.
. Nümunəmizdə sıfıra yaxın əmsalları təyin edəcəyik. Bu ümumi bir təcrübədir, lakin hər bir işin öz təcrübəsi ola bilər. nöqtədə 1-ci dərəcəli qismən törəmənin qiymətini çıxarın
nöqtədə 1-ci dərəcəli qismən törəmənin qiymətini çıxarın  . Deməli, törəmə müsbətdirsə, funksiya artır. Buna görə də, törəmənin dəyərini çıxararaq, böyümənin əks istiqamətində, yəni enmə istiqamətində hərəkət edəcəyik. Törəmə mənfi olarsa, bu nöqtədə funksiya azalır və törəmənin dəyərini çıxarır, biz enişə doğru irəliləyirik.
. Deməli, törəmə müsbətdirsə, funksiya artır. Buna görə də, törəmənin dəyərini çıxararaq, böyümənin əks istiqamətində, yəni enmə istiqamətində hərəkət edəcəyik. Törəmə mənfi olarsa, bu nöqtədə funksiya azalır və törəmənin dəyərini çıxarır, biz enişə doğru irəliləyirik.  : nöqtədə qismən törəmənin qiymətini çıxarın
: nöqtədə qismən törəmənin qiymətini çıxarın  .
. и
и  törəmələrin dəyərlərini çıxarsaq, yeni koordinatlar alırıq
törəmələrin dəyərlərini çıxarsaq, yeni koordinatlar alırıq  и
и  . Artıq hesablanmış koordinatlardan növbəti addımı (çıxma) edirik. Və beləliklə, tələb olunan yaxınlaşma əldə olunana qədər dövr təkrar-təkrar başlayır.
. Artıq hesablanmış koordinatlardan növbəti addımı (çıxma) edirik. Və beləliklə, tələb olunan yaxınlaşma əldə olunana qədər dövr təkrar-təkrar başlayır.Hamısı! İndi biz Mariana xəndəyinin ən dərin dərəsini axtarmağa hazırıq. Gəlin başlayaq.
Gradient eniş kodu
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Mariana xəndəyinin ən dibinə endik və orada əmsalların eyni dəyərlərini tapdıq  и
и  əslində gözlənilən bir şeydir.
əslində gözlənilən bir şeydir.
Gəlin başqa bir dalış edək, yalnız bu dəfə, bizim dərin dəniz vasitəmizin doldurulması başqa texnologiyalar olacaq, yəni kitabxana saysız.
Qradient Eniş Kodu (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Əmsal dəyərləri  и
и  dəyişməzdirlər.
dəyişməzdirlər.
Qradiyentin enişi zamanı xətanın necə dəyişdiyinə, yəni hər addımda kvadrat kənara çıxanların cəminin necə dəyişdiyinə baxaq.
Cəmi Kvadrat Sapma Plotunun kodu
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
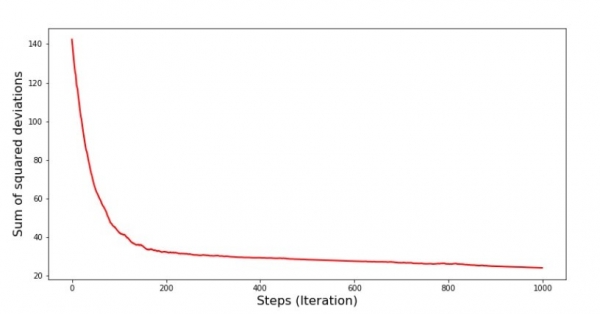
plt.show()Diaqram №4 "Qradient enişində kvadrat sapmaların cəmi"
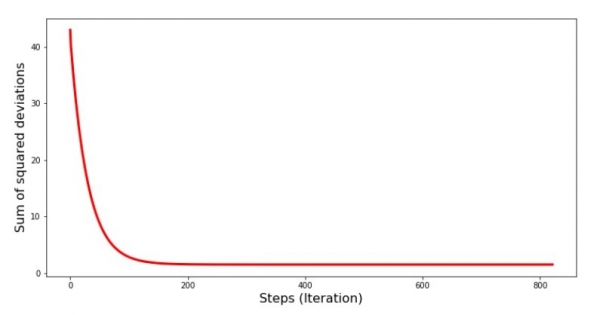
Qrafikdə səhvin hər addımda azaldığını görürük və müəyyən sayda təkrarlamadan sonra demək olar ki, üfüqi xətt müşahidə edirik.
Nəhayət, kodun icra müddətindəki fərqi qiymətləndirək:
Zamanlama qradiyenti enişinin hesablanması üçün kod
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Bəlkə də biz səhv edirik, amma yenə də kitabxanadan istifadə etməyən sadə "öz-özünə yazılmış" funksiya saysız kitabxanadan istifadə edərək funksiyanın hesablama vaxtından əvvəl saysız.
Ancaq biz hələ də dayanmırıq, lakin sadə xətti reqressiya tənliyini həll etmək üçün başqa bir maraqlı üsul öyrənməyə doğru irəliləyirik. Tanış!
Stokastik Qradient Eniş
Stokastik qradiyentin necə işlədiyini tez başa düşmək üçün onun adi gradient enişindən fərqlərini müəyyən etmək daha yaxşıdır. Biz, qradient enmə vəziyyətində, törəmələrinin tənliklərində  и
и  nümunədə mövcud olan bütün xüsusiyyətlərin və doğru cavabların dəyərlərinin cəmindən istifadə etdi (yəni bütün bunların cəmi
nümunədə mövcud olan bütün xüsusiyyətlərin və doğru cavabların dəyərlərinin cəmindən istifadə etdi (yəni bütün bunların cəmi  и
и  ). Stokastik gradient enişində biz nümunədəki bütün dəyərlərdən istifadə etməyəcəyik, bunun əvəzinə psevdo-təsadüfi olaraq sözdə nümunə indeksini seçəcəyik və onun dəyərlərindən istifadə edəcəyik.
). Stokastik gradient enişində biz nümunədəki bütün dəyərlərdən istifadə etməyəcəyik, bunun əvəzinə psevdo-təsadüfi olaraq sözdə nümunə indeksini seçəcəyik və onun dəyərlərindən istifadə edəcəyik.
Məsələn, indeks 3 (üç) rəqəmi kimi müəyyən edilirsə, biz dəyərləri götürürük  и
и  , sonra dəyərləri törəmələrin tənliklərində əvəz edirik və yeni koordinatları təyin edirik. Sonra koordinatları təyin etdikdən sonra nümunə indeksini yenidən psevdo-təsadüfi şəkildə müəyyənləşdiririk, indeksə uyğun olan dəyərləri qismən diferensial tənliklərə əvəz edirik və koordinatları yeni bir şəkildə təyin edirik.
, sonra dəyərləri törəmələrin tənliklərində əvəz edirik və yeni koordinatları təyin edirik. Sonra koordinatları təyin etdikdən sonra nümunə indeksini yenidən psevdo-təsadüfi şəkildə müəyyənləşdiririk, indeksə uyğun olan dəyərləri qismən diferensial tənliklərə əvəz edirik və koordinatları yeni bir şəkildə təyin edirik.  и
и  və s. yaşıl konvergensiyaya qədər. İlk baxışdan, ümumiyyətlə işləyə biləcəyi kimi görünə bilər, amma işləyir. Düzdür, qeyd etmək lazımdır ki, səhv hər addımda azalmır, amma əlbəttə ki, bir tendensiya var.
və s. yaşıl konvergensiyaya qədər. İlk baxışdan, ümumiyyətlə işləyə biləcəyi kimi görünə bilər, amma işləyir. Düzdür, qeyd etmək lazımdır ki, səhv hər addımda azalmır, amma əlbəttə ki, bir tendensiya var.
Stokastik qradiyentin adi enmə ilə müqayisədə üstünlükləri hansılardır? Nümunəmizin ölçüsü çox böyükdürsə və on minlərlə dəyərlə ölçülürsə, deməli, onların təsadüfi minini emal etmək bütün nümunədən daha asandır. Bu, stokastik gradient enişinin başladığı yerdir. Bizim vəziyyətimizdə, əlbəttə ki, böyük bir fərq görməyəcəyik.
Koda baxaq.
Stokastik Qradient Eniş kodu
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Biz əmsallara diqqətlə baxırıq və özümüzü “Necə?” sualına tuturuq. Əmsalların digər dəyərlərini də aldıq  и
и  . Bəlkə stoxastik gradient eniş tənlik üçün daha optimal parametrlər tapıb? Təəssüf ki, heç bir. Kvadrat sapmaların cəminə baxmaq və əmsalların yeni dəyərləri ilə səhvin daha böyük olduğunu görmək kifayətdir. Ümidsizliyə tələsmirik. Gəlin xətanın dəyişmə qrafikini yaradaq.
. Bəlkə stoxastik gradient eniş tənlik üçün daha optimal parametrlər tapıb? Təəssüf ki, heç bir. Kvadrat sapmaların cəminə baxmaq və əmsalların yeni dəyərləri ilə səhvin daha böyük olduğunu görmək kifayətdir. Ümidsizliyə tələsmirik. Gəlin xətanın dəyişmə qrafikini yaradaq.
Stokastik qradiyent enişdə kvadrat sapmaların cəminin qrafiki üçün kod
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
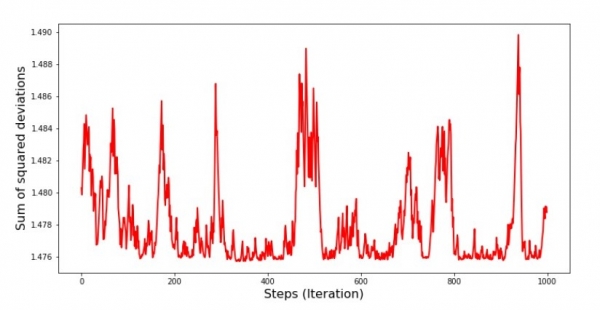
plt.show()Diaqram №5 "Stokastik Qradient Enişdə Kvadrat Sapmaların Cəmi"
Cədvələ baxdıqdan sonra hər şey öz yerinə düşür və indi hər şeyi düzəldəcəyik.
Bəs nə baş verdi? Aşağıdakılar baş verdi. Təsadüfi olaraq bir ayı seçdiyimiz zaman, alqoritmimiz gəlirin hesablanmasında səhvi azaltmağa çalışır ki, seçilmiş ay üçün. Sonra başqa bir ayı seçib hesablamağı təkrarlayırıq, lakin ikinci seçilmiş ay üçün səhvi azaldırıq. İndi xatırlayaq ki, ilk iki ayda sadə xətti reqressiya tənliyinin xəttindən əhəmiyyətli dərəcədə yayınırıq. Bu o deməkdir ki, bu iki aydan biri seçildikdə, onların hər birinin xətasını azaltmaqla, alqoritmimiz bütün nümunə üzrə xətanı ciddi şəkildə artırır. Bəs nə etməli? Cavab sadədir: enmə addımını azaltmaq lazımdır. Həqiqətən, enmə addımını azaltmaqla, xəta həm də yuxarı və ya aşağı “atlamağı” dayandıracaq. Daha doğrusu, “atlama” xətası dayanmayacaq, amma o qədər də tez etməyəcək :) Gəlin yoxlayaq.
SGD-ni daha kiçik bir addımla idarə etmək üçün kod
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Diaqram №6 "Stokastik qradiyent eniş üçün kvadrat sapmaların cəmi (80k addım)"
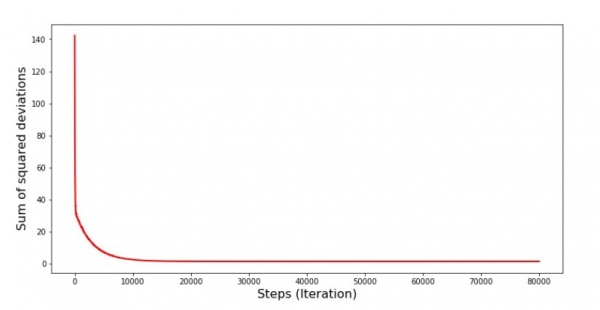
Şanslar yaxşılaşdı, lakin hələ də ideal deyil. Hipotetik olaraq, bu, bu şəkildə düzəldilə bilər. Məsələn, son 1000 iterasiyada minimum səhvin edildiyi əmsalların dəyərlərini seçirik. Düzdür, bunun üçün əmsalların dəyərlərini özləri yazmalıyıq. Biz bunu etməyəcəyik, əksinə, cədvələ diqqət yetirəcəyik. Hamar görünür və səhv bərabər şəkildə azalır. Əslində elə deyil. Gəlin ilk 1000 iterasiyaya baxaq və onları sonuncularla müqayisə edək.
SGD diaqramı üçün kod (ilk 1000 addım)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
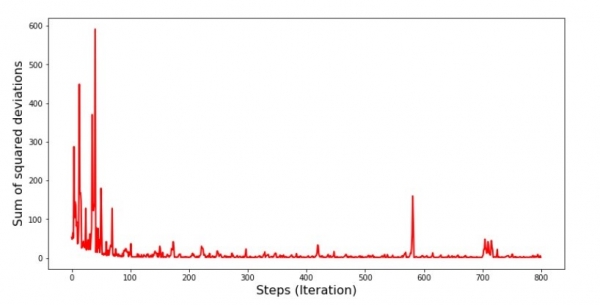
plt.show()Qrafik № 7 "SGD-nin kvadrat sapmalarının cəmi (ilk 1000 addım)"
Diaqram №8 "SGD-nin kvadrat sapmalarının cəmi (son 1000 addım)"
Enişin ən əvvəlində səhvdə kifayət qədər vahid və kəskin azalma müşahidə edirik. Son təkrarlamalarda görürük ki, xəta 1,475 dəyərinin ətrafında və ətrafında gedir və bəzi məqamlarda hətta bu optimal dəyərə bərabər olur, lakin sonra yenə də yüksəlir... Yenə deyirəm, dəyərləri yaza bilərsiniz. əmsallar  и
и  , və sonra xətanın minimal olduğuları seçin. Bununla belə, daha böyük problemimiz var idi: optimala yaxın dəyərlər əldə etmək üçün 80 min addım atmalı olduq (koda baxın). Və bu, gradient enişlə əlaqədar stoxastik qradiyent enişdə hesablama vaxtına qənaət etmək ideyasına artıq ziddir. Nə düzəldilə və yaxşılaşdırıla bilər? Görmək çətin deyil ki, ilk iterasiyalarda davamlı olaraq aşağı düşürük və buna görə də, ilk təkrarlarda böyük bir addım buraxmalı və irəlilədikcə addımı azaltmalıyıq. Bu məqalədə bunu etməyəcəyik - artıq süründürülmüşdür. Arzu edənlər bunu necə edəcəyini özü fikirləşə bilər, çətin deyil 🙂
, və sonra xətanın minimal olduğuları seçin. Bununla belə, daha böyük problemimiz var idi: optimala yaxın dəyərlər əldə etmək üçün 80 min addım atmalı olduq (koda baxın). Və bu, gradient enişlə əlaqədar stoxastik qradiyent enişdə hesablama vaxtına qənaət etmək ideyasına artıq ziddir. Nə düzəldilə və yaxşılaşdırıla bilər? Görmək çətin deyil ki, ilk iterasiyalarda davamlı olaraq aşağı düşürük və buna görə də, ilk təkrarlarda böyük bir addım buraxmalı və irəlilədikcə addımı azaltmalıyıq. Bu məqalədə bunu etməyəcəyik - artıq süründürülmüşdür. Arzu edənlər bunu necə edəcəyini özü fikirləşə bilər, çətin deyil 🙂
İndi kitabxanadan istifadə edərək stoxastik gradient enişini həyata keçirək saysız (və əvvəllər müəyyən etdiyimiz qayaların üstündən keçməyək)
Stokastik Qradient Eniş Kodu (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Dəyərlər istifadə etmədən enərkən demək olar ki, eyni olduğu ortaya çıxdı saysız. Bununla belə, bu məntiqlidir.
Stokastik gradient enişlərinin bizə nə qədər vaxt sərf etdiyini öyrənək.
SGD hesablama vaxtını təyin etmək üçün kod (80k addım)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Meşə nə qədər uzaqlaşsa, buludlar bir o qədər qaranlıq olur: yenə də "öz-özünə yazılmış" düstur ən yaxşı nəticəni göstərir. Bütün bunlar onu göstərir ki, kitabxanadan istifadənin daha incə üsulları olmalıdır. saysız, həqiqətən hesablama əməliyyatlarını sürətləndirir. Bu yazıda biz onlar haqqında öyrənməyəcəyik. Boş vaxtınızda düşünməli bir şey :)
Biz yekunlaşdırırıq
Xülasə etməzdən əvvəl çox güman ki, əziz oxucumuzdan yaranan bir suala cavab vermək istərdim. Nəyə görə, əslində, enişlərlə bu cür “əzablar”, əlimizdə belə güclü və sadə bir cihaz varsa, dağdan aşağı-yuxarı (əsasən aşağı) gəzib (əsasən aşağı) xəzinəni tapmaq lazımdır. bizi dərhal doğru yerə teleport edən analitik həll?
Bu sualın cavabı səthdə yatır. İndi biz əsl cavabın olduğu çox sadə bir nümunəni təhlil etdik  bir xüsusiyyətdən asılıdır
bir xüsusiyyətdən asılıdır  . Bunu həyatda tez-tez görmürsən, ona görə də təsəvvür edək ki, bizdə 2, 30, 50 və ya daha çox əlamət var. Buna hər bir xüsusiyyət üçün minlərlə, hətta on minlərlə dəyər əlavə edin. Bu halda, analitik həll testdən keçə və uğursuz ola bilər. Öz növbəsində, gradient enmə və onun dəyişmələri yavaş-yavaş, lakin şübhəsiz ki, bizi məqsədə - funksiyanın minimumuna yaxınlaşdıracaq. Sürətdən narahat olmayın - yəqin ki, biz hələ də addım uzunluğunu (yəni sürəti) təyin etməyə və tənzimləməyə imkan verəcək yolları təhlil edəcəyik.
. Bunu həyatda tez-tez görmürsən, ona görə də təsəvvür edək ki, bizdə 2, 30, 50 və ya daha çox əlamət var. Buna hər bir xüsusiyyət üçün minlərlə, hətta on minlərlə dəyər əlavə edin. Bu halda, analitik həll testdən keçə və uğursuz ola bilər. Öz növbəsində, gradient enmə və onun dəyişmələri yavaş-yavaş, lakin şübhəsiz ki, bizi məqsədə - funksiyanın minimumuna yaxınlaşdıracaq. Sürətdən narahat olmayın - yəqin ki, biz hələ də addım uzunluğunu (yəni sürəti) təyin etməyə və tənzimləməyə imkan verəcək yolları təhlil edəcəyik.
İndi isə qısa xülasə üçün.
Birincisi, ümid edirəm ki, məqalədə təqdim olunan material yeni başlayan "məlumat alimlərinə" sadə (və təkcə deyil) xətti reqressiya tənliklərini necə həll etməyi başa düşməyə kömək edəcəkdir.
İkincisi, tənliyi həll etməyin bir neçə yoluna baxdıq. İndi vəziyyətdən asılı olaraq, tapşırığa ən uyğun olanı seçə bilərik.
Üçüncüsü, biz əlavə parametrlərin gücünü, yəni gradient enişinin addım uzunluğunu gördük. Bu parametrə laqeyd yanaşmaq olmaz. Yuxarıda qeyd edildiyi kimi, hesablama xərclərini azaltmaq üçün enmə zamanı addım uzunluğu dəyişdirilməlidir.
Dördüncüsü, bizim vəziyyətimizdə "öz-özünə yazılmış" funksiyalar hesablamaların ən yaxşı vaxt nəticəsini göstərdi. Bu, yəqin ki, kitabxananın imkanlarından ən peşəkar şəkildə istifadə edilməməsi ilə bağlıdır. saysız. Ancaq nə olursa olsun, nəticə özünü aşağıdakı kimi göstərir. Bir tərəfdən, bəzən müəyyən edilmiş fikirləri sorğulamağa dəyər, digər tərəfdən, həmişə hər şeyi çətinləşdirməyə dəyməz - əksinə, bəzən problemi həll etməyin daha sadə yolu daha təsirli olur. Məqsədimiz sadə xətti reqressiya tənliyini həll etmək üçün üç yanaşmanı təhlil etmək olduğundan, "öz-özünə yazılmış" funksiyaların istifadəsi bizim üçün kifayət idi.
Ədəbiyyat (və ya buna bənzər bir şey)
1. Xətti reqressiya
2. Ən kiçik kvadratlar üsulu
3. Törəmə
4. Gradient
5. Qradient eniş
6. NumPy Kitabxanası
Mənbə: www.habr.com
