

Такім чынам, вы збіраеце метрыкі. Як і мы. Мы таксама збіраем метрыкі. Вядома ж, патрэбны для бізнэсу. Сёння мы раскажам аб самым першым звяне сістэмы нашага маніторынгу — statsd-сумяшчальным серверы агрэгацыі. , навошта мы яго напісалі і чаму адмовіліся ад brubeck.
З папярэдніх нашых артыкулаў (, ) можна даведацца, што да некаторага часу пазнакі мы збіралі пры дапамозе . Ён напісаны на C. З пункту гледжання кода - просты як корак (гэта важна, калі вы хочаце контрибьютить) і, самае галоўнае, без асаблівых праблем спраўляецца з нашымі аб'ёмамі ў 2 млн. метрык у секунду (MPS) у піку. Дакументацыя заяўляе падтрымку 4 млн. MPS са зорачкай. Гэта азначае, што заяўленую лічбу вы атрымаеце, калі правільна наладзіце сетку на Linux. (Колькі MPS можна атрымаць, калі пакінуць сетку як ёсць, нам невядома). Нягледзячы на гэтыя перавагі, да brubeck у нас было некалькі сур'ёзных прэтэнзій.
Прэтэнзія 1. Github - распрацоўшчык праекта - перастаў яго падтрымліваць: публікаваць патчы і фіксы, прымаць нашы і (не толькі нашы) PR. , Што можа стаць сур'ёзнай перашкодай для ўкаранення новых магчымасцяў.
Прэтэнзія 2. Дакладнасць вылічэнняў. Brubeck збірае для агрэгацыі за ўсё 65536 значэнняў.
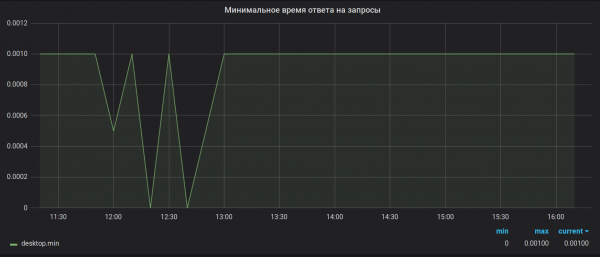
як было
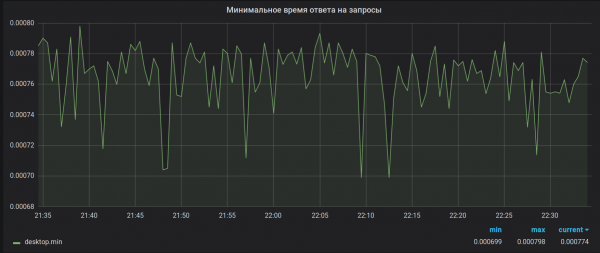
Як павінна было быць
Па той жа прычыне сумы ўвогуле лічацца некарэктна. Дадайце сюды баг з перапаўненнем 32-бітнага float, якое наогул адпраўляе сервер у segfault пры атрыманні з выгляду нявіннай метрыкі, і становіцца наогул выдатна. Баг, дарэчы, так і не выпраўлены.
І, нарэшце, Прэтэнзія X. На момант напісання артыкула мы гатовы прад'явіць яго ўсім 14 больш-менш працуючым рэалізацыям statsd, якія нам удалося знайсці. Давайце ўявім, што некаторая асобна ўзятая інфраструктура вырасла настолькі, што прымаць 4 млн MPS ужо недастаткова. Ці хай яшчэ не вырасла, але метрыкі для вас ужо важныя настолькі, што нават кароткія, 2-3 хвілінныя правалы на графіках ужо могуць стаць крытычнымі і выклікаць прыступы непераадольнай дэпрэсіі ў мэнэджараў. Так як лячэнне дэпрэсіі - справа няўдзячная, неабходны тэхнічныя рашэнні.
Па-першае, адмоваўстойлівасць, каб раптоўная праблема на серверы не задаволіла ў офісе псіхіятрычны зомбі апакаліпсіс. Па-другое, маштабаванне, каб атрымаць магчымасць прымаць больш за 4 млн MPS, пры гэтым не капаць углыб сеткавага стэка Linux і спакойна расці "ўшыркі" да патрэбных памераў.
Паколькі па маштабаванні запас у нас быў, мы вырашылі пачаць з адмоваўстойлівасці. «О! Адмаўстойлівасць! Гэта проста, гэта мы ўмеем», - падумалі мы і запусцілі 2 сервера, падняўшы на кожным копію brubeck. Для гэтага нам прыйшлося капіяваць трафік з метрыкамі на абодва сервера і нават напісаць для гэтага . Праблему адмоваўстойлівасці мы гэтым вырашылі, але… не вельмі добра. Спачатку ўсё было быццам бы выдатна: кожны brubeck збірае свой варыянт агрэгацыі, піша дадзеныя ў Graphite раз у 30 секунд, перазапісваючы стары інтэрвал (гэта робіцца на баку Graphite). Калі раптам адзін сервер адмовіць, у нас заўсёды ёсць другі з уласнай копіяй агрэгаваных дадзеных. Але вось праблема: калі сервер адмаўляе, на графіках узнікае "піла". Звязана гэта з тым, што 30-секундныя інтэрвалы ў brubeck не сінхранізаваны, і ў момант падзення адзін з іх не перазапісваецца. У момант запуску другога сервера адбываецца тое ж самае. Цалкам памяркоўна, але жадаецца лепш! Праблема маштабаванасці таксама нікуды не падзелася. Усе метрыкі па-ранейшаму "ляцяць" на адзіночны сервер, і таму мы абмежаваныя тымі ж самымі 2-4 млн MPS у залежнасці ад прапампоўкі сеткі.
Калі трохі падумаць аб праблеме і адначасова пакапаць лапатай снег, то ў галаву можа прыйсці такая відавочная ідэя: патрэбен statsd, які ўмее працаваць у размеркаваным рэжыме. па розных statsd ( на момант 11.12.2017), мы не знайшлі роўным лікам нічога. Мабыць, ні распрацоўшчыкі, ні карыстальнікі гэтых рашэнняў з ТАКІМ колькасцю метрык пакуль яшчэ не сутыкаліся, інакш яны б абавязкова што-небудзь прыдумалі.
І тут мы ўспомнілі пра «цацачны» statsd – bioyino, які пісалі на хакатоне just for fun (назва праекту згенераваў скрыпт перад пачаткам хакатона) і зразумелі, што нам тэрмінова патрэбен уласны statsd. Навошта?
- таму што ў свеце занадта мала клонаў statsd,
- таму што можна забяспечыць жаданую або блізкую да жаданай адмоваўстойлівасць і маштабаванасць (у тым ліку сінхранізаваць агрэгаваныя метрыкі паміж серверамі і вырашыць праблему канфліктаў пры адпраўцы),
- таму што можна лічыць метрыкі дакладней, чым гэта робіць brubeck,
- таму што можна самім збіраць больш дэталёвую статыстыку, якую brubeck нам практычна не падаваў,
- таму што прадаставіўся шанец запраграмаваць свой уласны хайперформансдыстрыб'ютэдскейлаблаплікейшэн, які не будзе цалкам паўтараць архітэктуру іншага такога ж хайперфор… нувыпонели.
На чым пісаць? Вядома ж, на Rust. Чаму?
- таму што ўжо быў прататып рашэння,
- таму што аўтар артыкула на той момант ужо ведаў Rust і імкнуўся напісаць на ім што-небудзь для прадакшэна з магчымасцю выкласці гэта ў open-source,
- таму што мовы з GC нам не падыходзяць у сілу прыроды атрымоўванага трафіку (практычна realtime) і GC-паўзы практычна недапушчальныя,
- таму што патрэбна максімальная прадукцыйнасць, параўнальная з C
- таму што Rust дае нам fearless concurrency, а пачаўшы пісаць гэта на C/C++, мы б агрэблі яшчэ больш, чым у brubeck, уразлівасцяў, перапаўненняў буфера, race conditions і іншых страшных слоў.
Быў і аргумент супраць Rust. У кампаніі не было досведу стварэння праектаў на Rust, і цяпер мы таксама не плануем выкарыстоўваць яго ў асноўным праекце. Таму былі сур'ёзныя асцярогі, што нічога не атрымаецца, але мы вырашылі рызыкнуць і паспрабавалі.
Ішоў час…
Нарэшце, пасля некалькіх няўдалых спроб, першая якая працуе версія была гатова. Што атрымалася? Атрымалася вось такое.
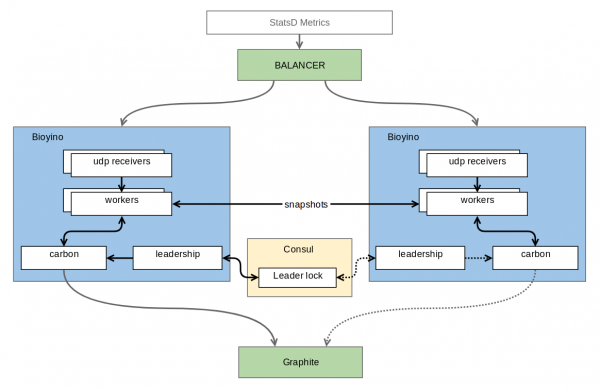
Кожная нода атрымлівае свой уласны набор метрык і назапашвае іх у сябе, прычым не агрэгуе метрыкі для тых тыпаў, дзе для фінальнай агрэгацыі запатрабуецца іх поўны набор. Ноды злучаныя паміж сабой некаторым пратаколам размеркаванай блакавання (distributed lock), які дазваляе абраць сярод іх тую адзіную (тут мы плакалі), якая варта адпраўляць метрыкі Вялікаму. У дадзены момант гэтая праблема вырашаецца сродкамі. , але ў будучыні амбіцыі аўтара распасціраюцца да Raft, дзе той самай годнай будзе, вядома ж, нода-лідэр кансэнсусу. Акрамя кансэнсусу, ноды дастаткова часта (па змаўчанні адзін раз у секунду) дасылаюць сваім суседзям тыя часткі перадагрэгаваных метрык, якія ўдалося за гэтую секунду набраць. Атрымліваецца, што маштабаванне і адмоваўстойлівасць захоўваюцца - кожная з нод па-ранейшаму трымае ў сябе поўны набор метрык, але метрыкі пры гэтым адпраўляюцца ўжо агрэгаванымі, па TCP і з кадаваннем у бінарны пратакол, таму выдаткі на дубліраванне ў параўнанні з UDP значна зніжаюцца. Нягледзячы на даволі вялікую колькасць уваходных метрык, назапашванне патрабуе зусім трохі памяці і яшчэ менш CPU. Для нашых добра сцісканых мерцікаў гэта ўсяго толькі некалькі дзясяткаў мегабайт дадзеных. Дадатковым бонусам атрымліваем адсутнасць лішніх перазапісаў даных у Graphite, як гэта было ў выпадку з burbeck.
UDP-пакеты з метрыкамі разбалансаваць паміж нодамі на сеткавым абсталяванні праз просты Round Robin. Само сабой, сеткавая жалязяка не разбірае змесціва пакетаў і таму можа пацягнуць значна больш, чым 4M пакетаў у секунду, не кажучы ўжо пра метрыкі, пра якія яна наогул нічога не ведае. Калі ўлічыць, што метрыкі прыходзяць не па адной у кожным пакеце, то праблем з прадукцыйнасцю ў гэтым месцы мы не прадбачым. У выпадку падзення сервера сеткавая прылада хутка (на працягу 1-2 секунд) выяўляе гэты факт і прыбірае які ўпаў сервер з ратацыі. У выніку гэтага пасіўныя (г.зн. не якія з'яўляюцца лідэрам) ноды можна ўключаць і выключаць практычна не заўважаючы прасадак на графіках. Максімум, што мы губляем - гэта частка метрык, якія прыйшлі за апошнюю секунду. Раптоўная страта/выключэнне/пераключэнне лідэра па-ранейшаму намалюе нязначную анамалію (30-секундны інтэрвал па-ранейшаму рассінхранізаваны), але пры наяўнасці сувязі паміж нодамі можна звесці да мінімуму і гэтыя праблемы, напрыклад, шляхам рассылання сінхранізуючых пакетаў.
Трохі аб унутранай прыладзе. Прыкладанне, вядома ж, шматструменнае, але архітэктура патокаў адрозніваецца ад той, што выкарыстана ў brubeck. Струмені ў brubeck - аднолькавыя - кожны з іх адказвае адначасова і за збор інфармацыі, і за агрэгацыю. У bioyino працоўныя струмені (workers) падзеленыя на дзве групы: адказныя за сетку і адказныя за агрэгацыю. Такое падзел дазваляе больш гнутка кіраваць дадаткам у залежнасці ад тыпу метрык: там дзе патрабуецца інтэнсіўная агрэгацыя, можна дадаць агрэгатараў, там дзе шмат сеткавага трафіку - дадаць колькасць сеткавых патокаў. У дадзены момант на нашых серверах мы працуем у 8 сеткавых і 4 якія агрэгуюць струменя.
Якая лічыць (адказная за агрэгацыю) частка досыць сумная. Запоўненыя сеткавымі струменямі буферы размяркоўваюцца паміж якія лічаць патокамі, дзе ў далейшым парсяцца і агрэгуюцца. Па запыце метрыкі аддаюцца для адпраўкі на іншыя ноды. Усё гэта, уключаючы перасыланне дадзеных паміж нодамі і працу з Consul, выконваецца асінхронна, працуе на фрэймворку .
Значна больш праблем пры распрацоўцы выклікала сеткавая частка, адказная за прыём метрык. Асноўнай задачай вылучэння сеткавых патокаў у асобныя сутнасці было імкненне паменшыць час, які паток затрачвае ня на чытанне дадзеных з сокета. Варыянты з выкарыстаннем асінхроннага UDP і звычайнага recvmsg хутка адпалі: першы есць занадта шмат user-space CPU на апрацоўку падзей, другі - занадта шмат пераключэнняў кантэксту. Таму зараз выкарыстоўваецца з вялікімі буферамі (а буфера, спадары афіцэры, гэта вам не абы што!). Падтрымка звычайнага UDP пакінутая для ненагружаных выпадкаў, калі ў recvmmsg няма неабходнасці. У рэжыме multimessage атрымоўваецца дасягнуць галоўнага: пераважная большасць часу сеткавы струмень разграбае чаргу АС – вычытвае дадзеныя з сокета і перакладае іх у userspace-буфер, толькі зрэдку перамыкаючыся на тое, каб аддаць запоўнены буфер агрэгатарам. Чарга ў сокеце практычна не назапашваецца, колькасць адкінутых пакетаў практычна не расце.
Заўвага
У наладах па змаўчанні памер буфера выстаўлены дастаткова вялікім. Калі вы раптам вырашыце апрабаваць сервер самастойна, то, магчыма, сутыкнецеся з тым, што пасля адпраўкі маленькай колькасці метрык, яны не прыляцяць у Graphite, застаўшыся ў буферы сеткавага струменя. Для працы з невялікай колькасцю метрык трэба выставіць у канфігу bufsize і task-queue-size значэння паменш.
Напрыканцы - трохі графікаў для аматараў графікаў.
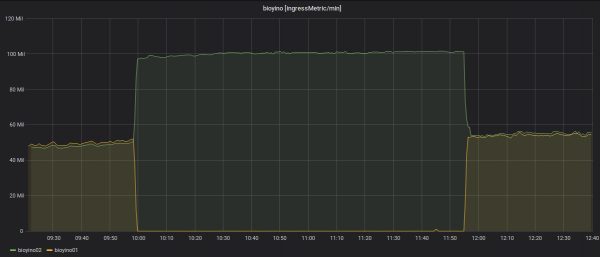
Статыстыка колькасці ўваходзяць метрык па кожным серверы: больш за 2 млн MPS.
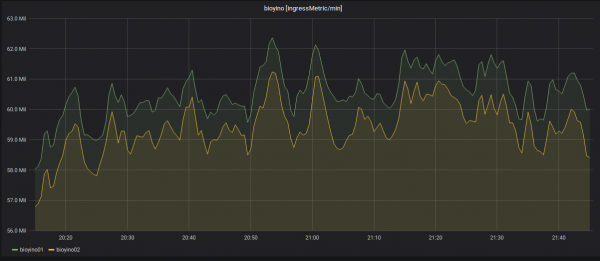
Адключэнне адной з нод і пераразмеркаванне ўваходзячых метрык.
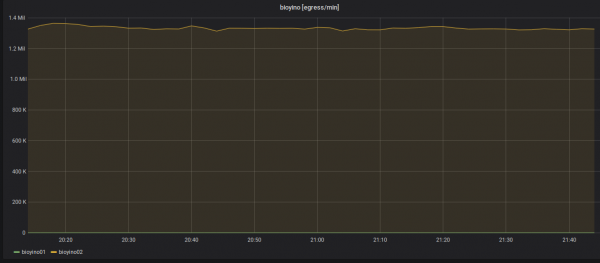
Статыстыка па выходных метрыках: адпраўляе заўсёды толькі адна нода - рэйдбос.
Статыстыка працы кожнай ноды з улікам памылак у розных модулях сістэмы.
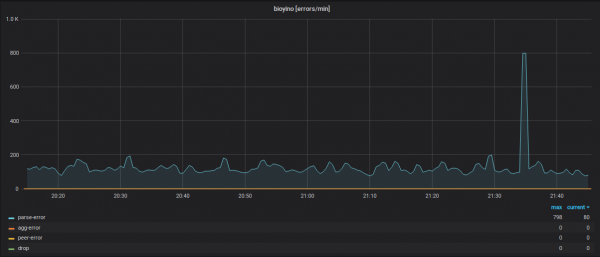
Дэталізацыя ўваходзяць метрык (імёны метрык схаваны).
Што мы плануем з гэтым усім рабіць далей? Вядома ж пісаць код, бл…! Праект першапачаткова планаваўся як open-source і застанецца такім усё яго жыццё. У бліжэйшых планах – пераход на ўласную версію Raft, змена peer-пратакола на больш пераносны, унясенне дадатковай унутранай статыстыкі, новых тыпаў метрык, выпраўленне памылак і іншыя паляпшэнні.
Вядома ж, вітаюцца ўсе ахвочыя дапамагаць у развіцці праекта: стварайце PR, Issues, па магчымасці будзем адказваць, дапрацоўваць і г.д.
На гэтым, як той казаў, that's all folks, купляйце нашых сланоў!

Крыніца: habr.com
