

Як вядома, кампанія SAP прапануе поўны спектр праграмнага забеспячэння, як для вядзення транзакцыйных дадзеных, так і для апрацоўкі гэтых дадзеных у сістэмах аналізу і справаздачнасці. У прыватнасці платформа SAP Business Warehouse (SAP BW) уяўляе сабой інструментарый для захоўвання і аналізу дадзеных, які валодае шырокімі тэхнічнымі магчымасцямі. Пры ўсіх сваіх аб'ектыўных перавагах сістэма SAP BW валодае адным значным недахопам. Гэта высокі кошт захоўвання і апрацоўкі дадзеных, асабліва прыкметная пры выкарыстанні хмарнай SAP BW on Hana.
А што, калі ў якасці сховішча пачаць выкарыстоўваць які-небудзь non-SAP і пажадана OpenSource прадукт? Мы ў Х5 Retail Group спынілі свой выбар на GreenPlum. Гэта, вядома, вырашае пытанне кошту, але пры гэтым адразу з'яўляюцца пытанні, якія пры выкарыстанні SAP BW вырашаліся практычна па змаўчанні.

У прыватнасці, якім чынам забіраць дадзеныя з сістэм крыніц, якія ў большасці сваёй з'яўляюцца рашэннямі SAP?
"HR-метрыкі" стаў першым праектам, у якім неабходна было вырашыць гэтую праблему. Нашай мэтай было стварэнне сховішчы HR-дадзеных і пабудова аналітычнай справаздачнасці па накіраванні працы з супрацоўнікамі. Пры гэтым асноўнай крыніцай даных з'яўляецца транзакцыйная сістэма SAP HCM, у якой вядуцца ўсе кадравыя, арганізацыйныя і зарплатныя мерапрыемствы.
Экстракцыя дадзеных
У SAP BW для SAP-сістэм існуюць стандартныя экстрактары дадзеных. Гэтыя экстрактары могуць аўтаматычна збіраць неабходныя дадзеныя, адсочваць іх цэласнасць, вызначаць дэльты змен. Вось, напрыклад, стандартная крыніца дадзеных па атрыбутах супрацоўніка 0EMPLOYEE_ATTR:
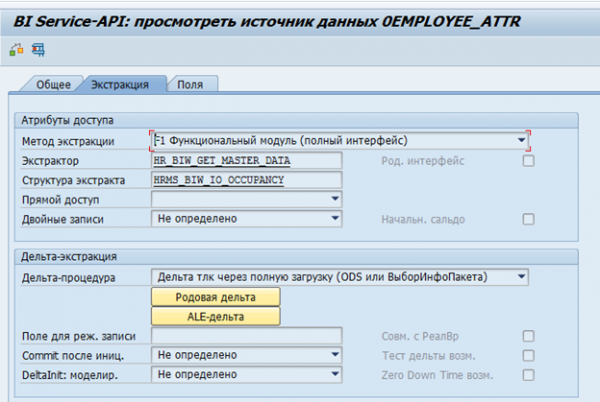
Вынік экстракцыі дадзеных з яго па адным супрацоўніку:
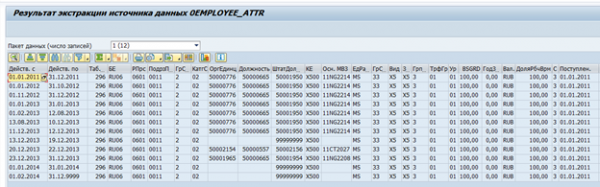
Пры неабходнасці такі экстрактар можа быць мадыфікаваны пад уласныя патрабаванні ці можа быць створаны свой уласны экстрактар.
Першай узнікла ідэя аб магчымасці іх перавыкарыстання. На жаль, гэта аказалася няздзейснай задачай. Вялікая частка логікі рэалізавана на баку SAP BW, і бязбольна аддзяліць экстрактар на крыніцы ад SAP BW не атрымалася.
Стала відавочна, што запатрабуецца распрацоўка ўласнага механізму вымання дадзеных са SAP сістэм.
Структура захоўвання дадзеных у SAP HCM
Для разумення патрабаванняў да такога механізму, першапачаткова трэба вызначыць якія менавіта дадзеныя нам запатрабуюцца.
Большасць дадзеных у SAP HCM захоўваецца ў плоскіх табліцах SQL. На падставе гэтых дадзеных прыкладання SAP візуалізуюць карыстачу аргструктуры, супрацоўнікаў і іншую HR інфармацыю. Напрыклад, вось так у SAP HCM выглядае аргструктура:
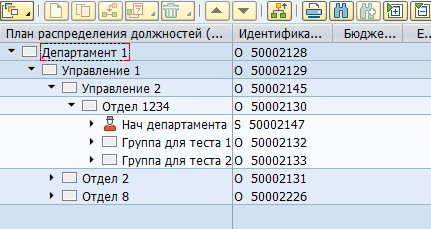
Фізічна такое дрэва захоўваецца ў дзвюх табліцах - у hrp1000 аб'екты і ў hrp1001 сувязі паміж гэтымі аб'ектамі.
Аб'екты «Дэпартамент 1» і «Упраўленне 1»:

Сувязь паміж аб'ектамі:

Як тыпаў аб'ектаў, так і тыпаў сувязі паміж імі можа быць вялізная колькасць. Існуюць як стандартныя сувязі паміж аб'ектамі, так і кастамізаваныя для ўласных спецыфічных патрэб. Напрыклад, стандартная сувязь B012 паміж аргедзініцай і штатнай пасадай паказвае на кіраўніка падраздзялення.
Адлюстраванне кіраўніка ў SAP:
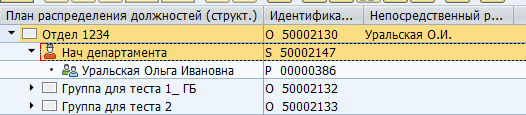
Захоўванне ў табліцы БД:

Дадзеныя па супрацоўніках захоўваюцца ў табліцах pa*. Напрыклад, дадзеныя аб кадравых мерапрыемствах па супрацоўніку захоўваюцца ў табліцы pa0000
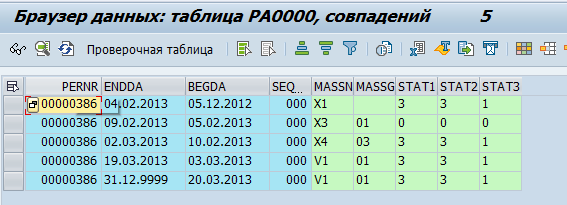
Мы прынялі рашэнне, што GreenPlum будзе забіраць "волкія" дадзеныя, г.зн. проста капіяваць іх з SAP табліц. І ўжо непасрэдна ў GreenPlum яны будуць апрацоўвацца і ператварацца ў фізічныя аб'екты (напрыклад, Аддзел ці Супрацоўнік) і метрыкі (напрыклад, сярэднеспісачная колькасць).
Было вызначана каля 70 табліц, дадзеныя з якіх неабходна перадаваць у GreenPlum. Пасля чаго мы прыступілі да прапрацоўкі спосабу перадачы гэтых дадзеных.
SAP прапануе дастаткова вялікую колькасць механізмаў інтэграцыі. Але самы просты спосаб - прамы доступ да базы дадзеных забаронены з-за ліцэнзійных абмежаванняў. Такім чынам, усе інтэграцыйныя патокі павінны быць рэалізаваны на ўзроўні сервера прыкладання.
Наступнай праблемай была адсутнасць дадзеных аб выдаленых запісах у БД SAP. Пры выдаленні радка ў БД, яна выдаляецца фізічна. Г.зн. фармаванне дэльты змен па часе змены не ўяўлялася магчымым.
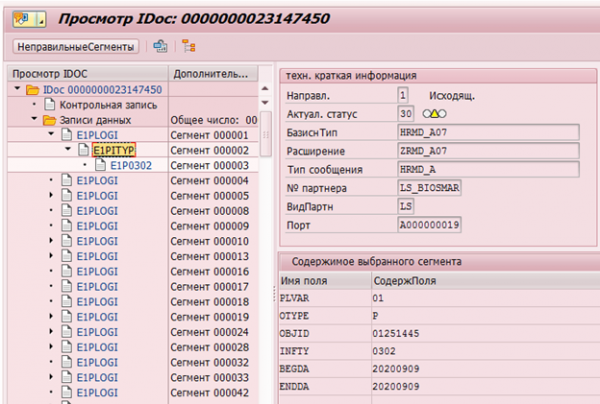
Вядома, у SAP HCM ёсць механізмы фіксацыі змен даных. Напрыклад, для наступнай перадачы ў сістэмы атрымальнікі існуюць паказальнікі змен (change pointer), якія фіксуюць любыя змены і на падставе якіх фармуюцца Idoc (аб'ект для перадачы ў вонкавыя сістэмы).
Прыклад IDoc змены інфатыпа 0302 у супрацоўніка з табельным нумарам 1251445:
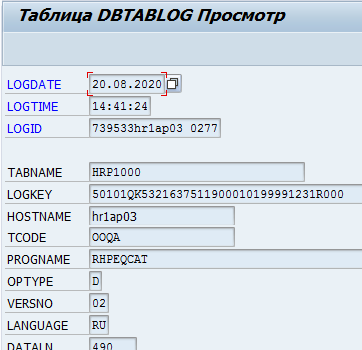
Або вядзенне логаў змен дадзеных у табліцы DBTABLOG.
Прыклад лога выдалення запісу з ключом QK53216375 з табліцы hrp1000:
Але гэтыя механізмы даступныя не для ўсіх неабходных дадзеных і іх апрацоўка на ўзроўні сервера прыкладанняў можа спажываць дастаткова шмат рэсурсаў. Таму масавае ўключэнне лагавання на ўсе неабходныя табліцы можа прывесці да прыкметнай дэградацыі прадукцыйнасці сістэмы.
Наступнай сур'ёзнай праблемай былі кластарныя табліцы. Дадзеныя адзнакі часу і разліку зарплаты ў RDBMS версіі SAP HCM захоўваюцца ў выглядзе набору лагічных табліц па кожным супрацоўніку за кожны разлік. Гэтыя лагічныя табліцы ў выглядзе двайковых дадзеных захоўваюцца ў табліцы pcl2.
Кластар разліку заработнай платы:
Дадзеныя з кластарных табліц немагчыма лічыць SQL камандай, а патрабуецца выкарыстанне макракаманд SAP HCM або спецыяльных функцыянальных модуляў. Адпаведна, хуткасць счытвання такіх табліц будзе дастаткова нізкая. З іншага боку, у такіх кластарах захоўваюцца дадзеныя, якія неабходныя толькі раз у месяц - выніковы разлік заработнай платы і ацэнка часу. Так што хуткасць у гэтым выпадку не гэтак крытычная.
Ацэньваючы варыянты з фармаваннем дэльты змены дадзеных, вырашылі гэтак жа разгледзець варыянт з поўнай выгрузкай. Варыянт кожны дзень перадаваць гігабайты нязменных дадзеных паміж сістэмамі не можа выглядаць прыгожа. Аднак ён мае і шэраг пераваг - няма неабходнасці як рэалізацыі дэльты на баку крыніцы, так і рэалізацыя ўбудавання гэтай дэльты на баку прымача. Адпаведна, памяншаецца кошт і тэрміны рэалізацыі, і павялічваецца надзейнасць інтэграцыі. Пры гэтым было вызначана, што практычна ўсе змены ў SAP HR адбываюцца ў гарызонце трох месяцаў да бягучай даты. Такім чынам, было прынятае рашэнне спыніцца на штодзённай поўнай выгрузцы дадзеных з SAP HR за N месяцаў да бягучай даты і на штомесячнай поўнай выгрузцы. Параметр N залежыць ад канкрэтнай табліцы
і вагаецца ад 1 да 15.
Для экстракцыі дадзеных была прапанавана наступная схема:

Вонкавая сістэма фармуе запыт і адпраўляе яго ў SAP HCM, тамака гэты запыт правяраецца на паўнату дадзеных і паўнамоцтвы на доступ да табліц. У выпадку паспяховай праверкі, у SAP HCM адпрацоўвае праграма, якая збірае неабходныя дадзеныя і перадае іх у інтэграцыйнае рашэнне Fuse. Fuse вызначае неабходны топік у Kafka і перадае дадзеныя туды. Далей дадзеныя з Kafka перадаюцца ў Stage Area GP.
Нас у дадзеным ланцужку цікавіць пытанне вымання дадзеных з SAP HCM. Спынімся на ім падрабязней.
Схема ўзаемадзеяння SAP HCM-FUSE.
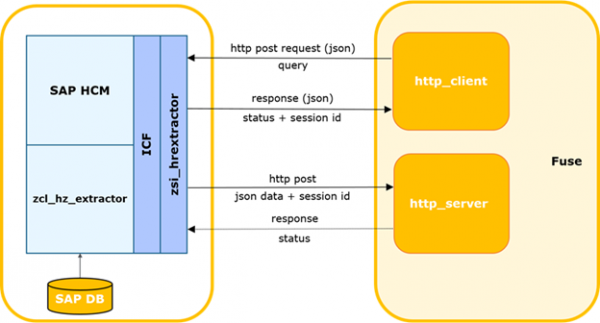
Вонкавая сістэма вызначае час апошняга паспяховага запыту ў SAP.
Працэс можа быць запушчаны па таймеры ці іншай падзеі, у тым ліку можа быць усталяваны таймаўт чакання адказу з дадзенымі ад SAP і ініцыяцыя паўторнага запыту. Пасля чаго фармуе запыт дэльты і адпраўляе яго ў SAP.
Дадзеныя запыты перадаюцца ў body у фармаце json.
Метад http:POST.
Прыклад запыту:

Сэрвіс SAP выконвае кантроль запыту на паўнату, адпаведнасць бягучай структуры SAP, наяўнасць дазволу доступу да запытанай табліцы.
У выпадку памылак сервіс вяртае адказ з адпаведным кодам і апісаннем. У выпадку паспяховага кантролю ён стварае фонавы працэс для фармавання выбаркі, генеруе і сінхронна вяртае ўнікальны id сесіі.
Вонкавая сістэма ў выпадку памылкі рэгіструе яе ў часопісе. У выпадку паспяховага адказу перадае id сесіі і імя табліцы па якой быў зроблены запыт.
Знешняя сістэма рэгіструе сесію як адкрытую. Калі ёсць іншыя сесіі па дадзенай табліцы, яны зачыняюцца з рэгістрацыяй папярэджання ў часопісе.
Фонавае заданне SAP фармуе курсор па зададзеных параметрах і пакет дадзеных зададзенага памеру. Памер пакета - максімальная колькасць запісаў, якія працэс чытае з БД. Па змаўчанні прымаецца роўным 2000. Калі ў выбарцы БД больш запісаў, чым выкарыстоўваны памер пакета пасля перадачы першага пакета фармуецца наступны блок з які адпавядае offset і інкрыментаваным нумарам пакета. Нумары інкрыментуюцца на 1 і адпраўляюцца строга паслядоўна.
Далей SAP перадае пакет на ўваход web-сэрвісу знешняй сістэмы. А яна сістэма выконвае кантролі ўваходнага пакета. У сістэме павінна быць зарэгістраваная сесія з атрыманым id і яна павінна знаходзіцца ў адкрытым статуце. Калі нумар пакета > 1 у сістэме павінна быць зарэгістравана паспяховае атрыманне папярэдняга пакета (package_id-1).
У выпадку паспяховага кантролю знешняя сістэма парсіт і захоўвае дадзеныя табліцы.
Дадаткова, калі ў пакеце прысутнічае сцяг final і серыялізацыя прайшла паспяхова, адбываецца апавяшчэнне модуля інтэграцыі аб паспяховым завяршэнні апрацоўкі сесіі і модуль абнаўляе статут сесіі.
У выпадку памылкі кантролю/разбору памылка лагуецца і пакеты па дадзенай сесіі будуць адхіляцца знешняй сістэмай.
Гэтак жа і ў зваротным выпадку, калі знешняя сістэма вяртае памылку, яна лагіруецца і спыняецца перадача пакетаў.
Для запыту даных на баку SAP HСM быў рэалізаваны інтэграцыйны сэрвіс. Сэрвіс рэалізаваны на фрэймворку ICF (SAP Internet Communication Framework ). Ён дазваляе праводзіць запыт дадзеных з сістэмы SAP HCM па вызначаных табліцах. Пры фарміраванні запыту даных ёсць магчымасць задаваць пералік канкрэтных палёў і параметры фільтрацыі з мэтай атрымання неабходных даных. Пры гэтым рэалізацыя сэрвісу не мяркуе які-небудзь бізнэс-логікі. Алгарытмы разліку дэльты, параметраў запыту, кантролю цэласнасці, і інш. таксама рэалізуюцца на баку знешняй сістэмы.
Гэты механізм дазваляе збіраць і перадаваць усе неабходныя дадзеныя за некалькі гадзін. Такая хуткасць знаходзіцца на грані прымальнай, таму гэтае рашэнне разглядаецца намі як часавае, якое дазволіла зачыніць запатрабаванне ў прыладзе экстракцыі на праекце.
У мэтавай карціне для рашэння задачы экстракцыі дадзеных прапрацоўваюцца варыянты выкарыстання CDC сістэм тыпу Oracle Golden Gate ці ETL прылад тыпу SAP DS.
Крыніца: habr.com
