

Па матывах дыскусіі ў чаце
У апошні час разгараюцца сапраўдныя бітвы на прадмет азначэння паняцця DevOps і SRE.
Нягледзячы на тое, што ўжо шмат у чым дыскусіі на гэтую тэму ўжо набілі аскому, у тым ліку і мне, вырашыў вынесці на суд хабра-супольнасці і свой погляд на гэтую тэму. Тым, каму цікава, сардэчна запрашаем пад кат. І хай пачнецца ўсё па новай!
перадгісторыя
Такім чынам, у старадаўнія часы жыла асобна каманда распрацоўшчыкаў ПЗ і адміністратараў сервераў. Першыя шчасна пісалі код, другія, ужываючы розныя цёплыя ласкавыя словы ў адрас першых, наладжвалі сервера, перыядычна прыходзячы да распрацоўнікаў і атрымліваючы ў адказ вычарпальнае на маёй машыне ўсё працуе . Бізнес чакаў праграмнае забеспячэнне, усё прастойвала, перыядычна ламалася, усё нерваваліся. Асабліва той, хто за ўвесь гэты бардак плаціў. Слаўная лямпавая эпоха. Ну ды вы і так у курсе, адкуль растуць ногі ў DevOps.
Нараджэнне DevOps практык
Затым прыйшлі сур'ёзныя дзядзькі і сказалі - гэта не індустрыя, так працаваць нельга. І прыцягнулі мадэлі жыццёвага цыкла. Вось, напрыклад, V-мадэль.
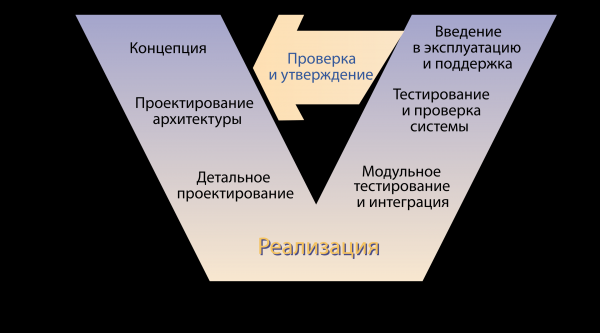
Такім чынам, што мы бачым? Бізнес прыходзіць з канцэпцыяй, архітэктары праектуюць рашэнні, распрацоўшчыкі пішуць код, далей - правал. Нехта неяк тэстуе прадукт, нехта неяк яго дастаўляе канчатковаму карыстальніку і недзе на выхадзе гэтай цуда-мадэлі сядзіць самотны бізнес-заказчык і чакае абяцанага ля мора надвор'я. Прыйшлі да высновы - патрэбны метады, якія дазволяць гэты працэс наладзіць. І вырашылі стварыць практыкі, якія б іх рэалізоўвалі.
Лірычны адступ на прадмет, што такое практыка
Пад практыкай я разумею звязак тэхналогіі і дысцыпліны. Прыклад - практыка апісання інфраструктуры кодам на terraform. Дысцыпліна - гэта тое, як апісваць кодам інфраструктуру, яна ў распрацоўніка ў галаве, а тэхналогія - гэта ўласна terraform.
І вырашылі яны назваць іх DevOps практыкамі – думаю мелі на ўвазе from Development to Operations. Прыдумалі розныя мудрагелістыя штукі – CI/CD практыкі, практыкі, якія засноўваюцца на IaC прынцыпе, тысячы іх. І панеслася, распрацоўнікі пішуць код, DevOps інжынеры трансфармуюць апісанне сістэмы ў выглядзе кода ў якія працуюць сістэмы (так, код гэта нажаль, усяго толькі апісанне, але ніяк не ўвасабленне сістэмы), дастаўка круціцца, ну і гэтак далей. Учорашнія адміністратары, асвоіўшы новыя практыкі, ганарліва перакваліфікаваліся ў DevOps інжынераў, і ўсё панеслася. І быў вечар, і была раніца… прабачце, не адтуль.
Усё зноў не дзякуй богу
Толькі ўсё ўляглося, і розныя хітрыя «метадолагі» пачалі пісаць таўшчэзныя кнігі па DevOps практыкам, ціха разгараліся спрэчкі, хто ж такі ўсё ж такі праславуты DevOps інжынер і што DevOps – гэта культура вытворчасці, зноў наспела незадаволенасць. Раптам выявілася, што дастаўка ПЗ - абсалютна нетрывіяльная задача. У кожнай інфраструктуры распрацоўкі свой стэк, дзесьці збіраць трэба, дзесьці разгортваць environment, тут патрэбен tomcat, тут патрэбен яшчэ хітравымучаны спосаб запуску – увогуле, галава трашчыць. А яшчэ праблема, як ні дзіўна, апынулася ў першую чаргу ў арганізацыі працэсаў - вось гэтая функцыя дастаўкі, як бутэлькавае рыльца, стала блакаваць працэсы. Да таго ж эксплуатацыю (Operations) ніхто не адмяняў. Яе ў V-мадэлі не відаць, а тамака яшчэ ўвесь жыццёвы цыкл справа. Па выніку трэба і неяк інфраструктуру падтрымліваць, і ў маніторынг глядзець, і інцыдэнты разрульваць, ды яшчэ і дастаўкай займацца. Г.зн. сядзець адной нагой і ў распрацоўцы, і ў эксплуатацыі - і раптам атрымаўся такі Development & Operations. А тут яшчэ і павальны хайп на мікрасэрвісы пад'ехаў. А з імі яшчэ і распрацоўка з лакальных машын пачала ў клаўд пераязджаць – паспрабуй нешта адладзіць лакальна, калі мікрасэрвісаў дзясяткі і сотні, тут ужо сталая дастаўка становіцца сродкам выжывання. Для "маленькай сціплай кампаніі" яшчэ куды ні ішло, але ўсё ж? А Google?
SRE ад Google
Прыйшоў Google, з'еў самыя буйныя кактусы і вырашыў - нам такое не трэба, нам надзейнасць патрэбна. А надзейнасцю трэба кіраваць. І вырашыў - нам патрэбны спецыялісты, якія будуць кіраваць надзейнасцю. Назваў іх SR-інжынерамі і сказаў, вось вам усё, зрабіце, як звычайна, добра. Вось вам SLI, вось вам SLO, вось вам маніторынг. І тыцнуў носам у operations. І назваў свой "надзейны DevOps" SRE. Накшталт бы ўсё добра, але ёсць адзін брудны хак, які Google мог сабе дазволіць – на пазіцыі SR інжынераў наймаць людзей, якія мелі кваліфікацыю распрацоўнікаў і яшчэ крыху шылі на хаце разбіраліся ў функцыянаванні якія працуюць сістэм. Прычым з наймам такіх людзей і ў самога Google праблемы – галоўным чынам таму, што тут ён сам з сабой канкуруе – трэба ж і бізнэс-логіку камусьці апісваць. Дастаўку развесіў на рэліз-інжынераў, SR – інжынеры кіруюць надзейнасцю (ясная справа, не наўпрост, а ўплываючы на інфраструктуру, змяняючы архітэктуру, адсочваючы змены і паказчыкі, разбіраючыся з інцыдэнтамі). Прыгожа, можна . А што рабіць, калі вы не Google, а надзейнасць усё ж неяк непакоіць?
Развіццё ідэй DevOps
Тут як раз падаспеў Docker, які вырас з lxc, а затым і розныя сістэмы аркестрацыі тыпу Docker Swarm і Kubernetes, і DevOps інжынеры выдыхнулі – уніфікацыя практык спрасціла дастаўку. Спрасціла да такой ступені, што стала магчымым нават аддаць дастаўку распрацоўшчыкам - што там deployment.yaml. Кантэйнерызацыя праблему вырашае. Ды і сталасць сістэм CI/CD ужо на ўзроўні адзін файл напісаў і ўсё панеслася – распрацоўнікі самі зладзяцца. І тут мы пачынаем казаць, як нам зрабіць свой SRE, з… ды хоць з кім-небудзь.
SRE не ў Google
Ну ок, дастаўку мы падалі, накшталт бы можам выдыхнуць, вярнуцца да старых добрых часоў, калі адміны глядзелі загрузку працэсараў, цюнілі сістэмы і ціха пацягвалі з кубкаў нешта незразумелае ў цішыні і спакоі… Стоп. Мы не дзеля гэтага ўсё ладзілі (а шкада!). Раптам аказваецца, што ў падыходзе Google мы цалкам можам узяць выдатныя практыкі – не загрузка працэсараў важная, і не тое, наколькі часта мы дыскі там мяняем, ці там у клаўдзе кошт аптымізуем, а бізнес-метрыкі – усё тыя ж праславутыя SLx. І кіраванне інфраструктурай з іх ніхто не здымаў, і інцыдэнты разрульваць трэба, і дзяжурыць на пасадзе перыядычна, і ўвогуле ў тэме бізнес-працэсаў быць. І хлопцы, пачынайце ўжо патроху праграмаваць на добрым узроўні, вас Google ужо зачакаўся.
Рэзюмуючы. Раптам, але вы ўжо стаміліся чытаць і вам не церпіцца плюнуць напісаць аўтару ў каментары да артыкула. DevOps як практыкі дастаўкі, быў ёсць і будзе. І нікуды не падзенецца. SRE як набор практык эксплуатацыі робіць гэтую самую дастаўку паспяховай.
Крыніца: habr.com
