

Сёння размова пойдзе аб цікавай тэхналогіі, рэалізаванай у СГД Unity/Unity XT, – FAST VP. Калі вы ўпершыню пачулі аб Unity, то па спасылцы ў канцы артыкула можна азнаёміцца з характарыстыкамі сістэмы. У праектнай камандзе Dell EMC я працаваў над FAST VP больш за год. Сёння хачу расказаць аб гэтай тэхналогіі больш падрабязна і раскрыць некаторыя дэталі яе рэалізацыі. Зразумела, толькі тыя, якія можна раскрыць. Калі вы цікавіцеся пытаннямі эфектыўнага захоўвання дадзеных ці проста не да канца разабраліся з дакументацыяй, то гэты артыкул напэўна будзе карысны і цікавы.

Адразу скажу аб тым, чаго ў матэрыяле не будзе. Ня будзе пошуку канкурэнтаў і параўнання з імі. Таксама не планую расказваць аб падобных тэхналогіях з open source, таму што цікаўны чытач і так пра іх ведае. І, канешне, я не збіраюся нічога рэкламаваць.
Storage Tiering. Мэты і задачы FAST VP
FAST VP расшыфроўваецца як Fully Automated Storage Tiering for Virtual Pool. Складнавата? Нічога, зараз разбярэмся. Tiering - гэта спосаб арганізацыі захоўвання дадзеных, пры якім ёсць некалькі ўзроўняў (tiers), дзе гэтыя дадзеныя захоўваюцца. Кожны валодае сваімі характарыстыкамі. Найважнейшыя: прадукцыйнасць, аб'ём і кошт захоўвання адзінкі інфармацыі. Зразумела, паміж імі ёсць узаемасувязь.
Важная асаблівасць tiering складаецца ў тым, што доступ да дадзеных падаецца аднастайна па-за залежнасцю ад таго, на якім узроўні захоўвання ў дадзены момант яны знаходзяцца, а памер пула роўны суме памераў рэсурсаў, якія ўваходзяць у яго. Тут крыюцца адрозненні ад кэша: памер кэша не дадаецца да агульнага аб'ёму рэсурсу (пула ў дадзеным выпадку), а дадзеныя кэша дублююць які-небудзь фрагмент дадзеных асноўнага носьбіта (ці будуць дубляваць, калі дадзеныя з кэша яшчэ не запісаны). Таксама размеркаванне дадзеных па ўзроўнях утоена ад карыстача. То бок, ён не бачыць якія менавіта дадзеныя размешчаныя на кожным узроўні, хоць і можа ўплываць на гэта апасродкавана, шляхам задання палітык (пра іх пазней).
Цяпер паглядзім на асаблівасці рэалізацыі storage tiering'а ў Unity. У Unity вылучаюць 3 узроўня, ці tier'а:
- Extreme performance (SSDs)
- Performance (SAS HDD 10k/15k RPM)
- Capacity (NL-SAS HDD 7200 RPM)
Яны прадстаўлены ў парадку змяншэння прадукцыйнасці і кошты. У Extreme performance уваходзяць выключна цвёрдацельныя назапашвальнікі (SSD). У два іншых tier'а - назапашвальнікі на магнітных дысках, якія адрозніваюцца хуткасцю кручэння і, адпаведна, прадукцыйнасцю.
Носьбіты інфармацыі з аднаго ўзроўню і аднаго памеру аб'ядноўваюцца ў RAID-масіў, утвараючы RAID-групу (RAID group, скарочана - RG); пра даступныя і рэкамендуемыя ўзроўні RAID можна прачытаць у афіцыйнай дакументацыі. З RAID-груп з аднаго або некалькіх узроўняў фармуюцца пулы захоўвання дадзеных (Storage pool), з якіх потым і размяркоўваецца вольнае месца. А ўжо з пула выдзяляецца месца пад файлавыя сістэмы і LUN'ы.

А навошта мне Tiering?
Калі сцісла і абстрактна: каб дасягнуць большага выніку, выкарыстоўваючы мінімум рэсурсаў. Калі больш канкрэтна, то пад вынікам звычайна разумеюць сукупнасць характарыстык СГД - хуткасць і час доступу, кошт захоўвання і іншых. Пад мінімумам рэсурсаў маюцца на ўвазе найменшыя выдаткі: грошай, энергіі і гэтак далей. FAST VP рэалізуе механізмы пераразмеркавання дадзеных па розных узроўнях у СХД Unity / Unity XT. Калі вы мне верыце, то можна прапусціць наступны абзац. Для астатніх раскажу крыху падрабязней.
Правільнае размеркаванне дадзеных па ўзроўнях захоўвання дазваляе зэканоміць на агульным кошце СХД, ахвяраваўшы хуткасцю доступу да некаторай рэдка выкарыстоўванай інфармацыі, і падвысіць прадукцыйнасць, перамяшчаючы часта выкарыстоўваныя дадзеныя на хутчэйшыя носьбіты. Тут хтосьці можа запярэчыць, што і без tiering'а нармальны адмін ведае, куды якія дадзеныя змясціць, якія пажаданыя характарыстыкі СГД пад яго задачу і да т.п. Несумненна, гэта так, але размеркаванне дадзеных "уручную" мае свае недахопы:
- патрабуе часу і ўвагі адміністратара;
- не заўсёды ўдаецца «перакроіць» рэсурсы СГД пад змененыя ўмовы;
- знікае важная перавага: уніфікаваны доступ да рэсурсаў, якія знаходзяцца на розных узроўнях захоўвання.
Каб storage-адміны менш турбаваліся аб job security, дадам, што пісьменнае планаванне рэсурсаў і тут неабходна. Цяпер, калі задачы tiering'а коратка абмаляваныя, давайце паглядзім, чаго можна чакаць ад FAST VP. Тут самы час вярнуцца да вызначэння. Першыя два словы Fully Automated даслоўна перакладаюцца як цалкам аўтаматызаваны і азначаюць, што размеркаванне па ўзроўнях адбываецца аўтаматычна. Ну а Virtual Pool - гэта пул дадзеных, у які ўваходзяць рэсурсы з розных узроўняў захоўвання. Вось як гэта выглядае:

Забягаючы наперад, скажу, што FAST VP перамяшчае дадзеныя толькі ўсярэдзіне аднаго пула, а не паміж некалькімі пуламі.
Задачы, якія вырашаюцца FAST VP
Спачатку пагаворым абстрактна. У нас ёсць пул і нейкі механізм, які можа пераразмяркоўваць дадзеныя ўнутры гэтага пула. Памятаючы, што наша задача - дасягненне максімальнай прадукцыйнасці, задамося пытаннем: якімі спосабамі яе можна дасягнуць? Іх можа быць некалькі, і тут FAST VP ёсць што прапанаваць карыстачу, бо тэхналогія ўяўляе з сябе нешта большае, чым проста storage tiering. Вось якімі спосабамі FAST VP можа павялічыць прадукцыйнасць пула:
- Размеркаванне дадзеных па розных тыпах дыскаў, узроўням
- Размеркаванне дадзеных сярод дыскаў аднаго тыпу
- Размеркаванне дадзеных пры пашырэнні пула
Перш чым разбіраць тое, як гэтыя задачы вырашаюцца, нам трэба ведаць некаторыя неабходныя факты аб рабоце FAST VP. FAST VP аперуе блокамі вызначанага памеру - 256 мегабайт. Гэта мінімальны бесперапынны "кавалак" дадзеных, які можа быць перамешчаны. У дакументацыі яго так і завуць: slice. З пункту гледжання FAST VP усе RAID-групы складаюцца з набору такіх "кавалкаў". Адпаведна, уся статыстыка ўводу-вываду назапашваецца для такіх блокаў дадзеных. Чаму абраны менавіта такі памер блока і ці будзе ён зменшаны? Блок дастаткова буйны, але гэта кампраміс паміж гранулярнасцю дадзеных (менш памер блока - дакладней размеркаванне) і наяўнымі вылічальнымі рэсурсамі: пры існуючых жорсткіх абмежаваннях на аператыўную памяць і вялікай колькасці блокаў дадзеныя статыстык могуць займаць занадта шмат, і колькасць разлікаў вырасце прапарцыйна.
Як FAST VP размяшчае дадзеныя ў пуле. Палітыкі
Каб кіраваць размяшчэннем дадзеных у пуле з уключаным FAST VP існуюць такія палітыкі:
- Highest Available Tier
- Auto-Tier
- Start High then Auto-Tier (па змаўчанні)
- Lowest Available Tier
Яны ўплываюць як на першапачатковае размяшчэнне блока (дадзеныя ўпершыню запісаны), так і на наступнае пераразмеркаванне. Калі ж дадзеныя ўжо размешчаны на дысках, пераразмеркаванне будзе ініцыявана па раскладзе або ўручную.
Highest Available Tier спрабуе размясціць новы блок на найболей прадукцыйным узроўні. Пры недахопе месца на ім - на наступным па прадукцыйнасці, але потым дадзеныя могуць быць перамешчаныя на больш прадукцыйны ўзровень (пры наяўнасці месца або выцесніўшы іншыя дадзеныя). Auto-Tier размяшчае новыя дадзеныя на розных узроўнях у залежнасці ад памеру даступнай прасторы, а пераразмяркоўваюцца яны ў залежнасці ад запатрабаванасці і вольнага месца. Start High then Auto-Tier - палітыка па змаўчанні і таксама рэкамендуемая. Пры першапачатковым размяшчэнні працуе як Highest Available Tier, а далей адбываецца перамяшчэнне даных у залежнасці ад іх статыстыкі выкарыстання. Палітыка Lowest Available Tier імкнецца размясціць дадзеныя на найменш прадукцыйным узроўні.
Перанос дадзеных ідзе з нізкім прыярытэтам каб не перашкаджаць карыснай працы СГД, аднак ёсць настройка "Data relocation rate", якая мяняе прыярытэт. Тут ёсць асаблівасць: не ўсе блокі даных маюць аднолькавую чарговасць пераразмеркавання. Напрыклад, блокі, пазначаныя як метададзеныя, будуць перамешчаныя на хутчэйшы ўзровень у першую чаргу. Метададзеныя - гэта, калі можна так выказацца, "дадзеныя аб дадзеных", нейкая дадатковая інфармацыя, якая не з'яўляецца карыстацкімі дадзенымі, але захоўвае іх апісанне. Напрыклад, інфармацыя ў файлавай сістэме аб тым, у якім блоку знаходзіцца пэўны файл. Значыць, хуткасць доступу да дадзеных залежыць ад хуткасці доступу да метададзеных. Улічваючы, што метададзеныя звычайна значна меншыя па памеры, выйгрыш ад іх перамяшчэння на больш прадукцыйныя дыскі чакаецца больш.
Крытэрыі, якія Fast VP выкарыстоўвае ў працы
Асноўны крытэр для кожнага блока, калі вельмі грубіянска, - характарыстыка "запатрабаванасці" дадзеных, якая залежыць ад колькасці аперацый чытання і запісы фрагмента дадзеных. Гэтая характарыстыка ў нас называецца "Тэмпература". Ёсць запатрабаваныя (hot) дадзеныя, якія «гарачае» незапатрабаваных. Вылічаецца яна перыядычна, па змаўчанні з інтэрвалам у адну гадзіну.
Функцыя вылічэння тэмпературы валодае такімі ўласцівасцямі:
- Пры адсутнасці ўводу-вываду дадзеныя з часам "астываюць".
- Пры больш-менш аднолькавай у часе нагрузцы тэмпература спачатку ўзрастае і затым стабілізуецца ў вызначаным дыяпазоне.
Далей улічваюцца палітыкі, апісаныя вышэй, і вольнае месца на кожным tier'е. Для навочнасці прывяду карцінку з дакументацыі. Тут чырвоным, жоўтым і сінім колерамі пазначаны блокі з высокай, сярэдняй і нізкай тэмпературай адпаведна.
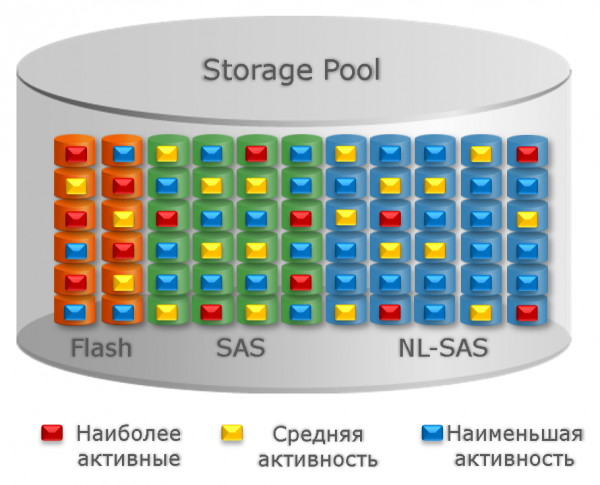
Але вернемся да задач. Такім чынам, можна прыступаць да разбору таго, што робіцца для рашэння задач FAST VP.
А. Размеркаванне дадзеных па розных тыпах дыскаў, узроўням
Уласна, гэта асноўная задача FAST VP. Астатнія, у нейкім сэнсе, з'яўляюцца вытворнымі ад яе. У залежнасці ад абранай палітыкі дадзеныя будуць размяркоўвацца па розных узроўнях захоўвання. Першым чынам улічваецца палітыка месцавання, затым тэмпература блокаў і памер/хуткасць RAID-груп.
Для палітык Highest/Lowest Available Tier усё дастаткова проста. Для астатніх двух справа ідзе так. Па розных узроўнях дадзеныя размяркоўваюцца з улікам памеру і прадукцыйнасці RAID-груп: так, каб стаўленне сумарнай "тэмпературы" блокаў да "умоўнай максімальнай прадукцыйнасці" кожнай RAID-групы было прыкладна аднолькавым. Такім чынам, нагрузка размяркоўваецца больш-менш раўнамерна. Больш запатрабаваныя дадзеныя перамяшчаюцца на хуткія носьбіты, рэдка выкарыстоўваныя - на павальнейшыя. У ідэале размеркаванне павінна атрымацца прыкладна такім:
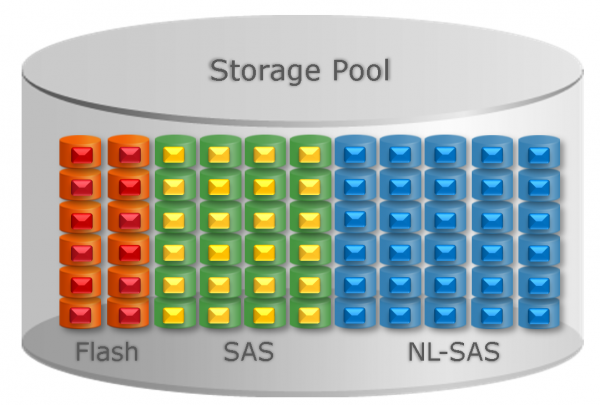
Б. Размеркаванне дадзеных сярод дыскаў аднаго тыпу
Памятайце, у пачатку я пісаў, што носьбіты інфармацыі з аднаго або некалькіх узроўняў аб'ядноўваюцца ў адзін пул? У выпадку з адзіным узроўнем для FAST VP таксама ёсць праца. Каб прадукцыйнасць якога-небудзь узроўня была максімальнай, пажадана размеркаваць дадзеныя раўнамерна паміж кружэлкамі. Гэта дазволіць (у тэорыі) атрымаць максімальную колькасць IOPS. Дадзеныя ўсярэдзіне RAID-групы можна лічыць размеркаванымі раўнамерна па дысках, а вось паміж RAID-групамі гэта далёка не заўсёды так. У выпадку дысбалансу FAST VP будзе перамяшчаць дадзеныя паміж RAID-групамі прапарцыйна іх аб'ёму і "умоўнай прадукцыйнасці" (у лікавым выразе). Для нагляднасці пакажу схему рэбалансавання сярод трох RAID-груп.
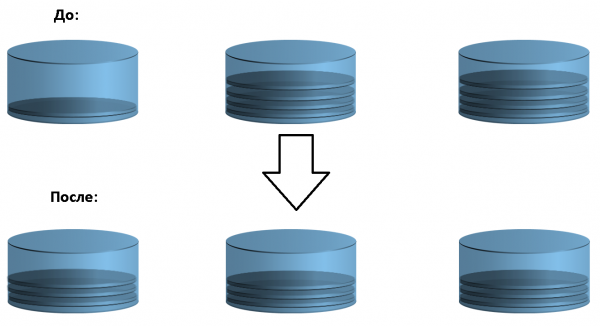
В. Размеркаванне дадзеных пры пашырэнні пула
Гэтая задача з'яўляецца прыватным выпадкам папярэдняй і выконваецца, калі ў пул дадаюць RAID-групу. Каб ізноў дададзеная RAID-група не прастойвала, частка дадзеных будзе перанесена на яе, а значыць і нагрузка на ўсе RAID-групы пераразмяркуецца.
Выраўноўванне зносу SSD
З дапамогай выраўноўвання зносу FAST VP можа падоўжыць жыццё SSD, хоць гэтая функцыя і не ставіцца напроста да Storage Tiering. Бо дадзеныя аб тэмпературы ўжо ёсць, колькасць аперацый запісу таксама ўлічваецца, блокі дадзеных мы перамяшчаць умеем, тое лагічна было б для FAST VP вырашыць і гэтую задачу.
У выпадку, калі колькасць запісаў у адну RAID-групу значна пераўзыходзіць колькасць запісаў у іншую, то FAST VP пераразмяркуе дадзеныя ў адпаведнасці з колькасцю аперацый запісу. З аднаго боку, гэта здымае нагрузку і захоўвае рэсурс адных кружэлак, з іншага боку, дадае "працы" для меней нагружаных, падвышаючы агульную прадукцыйнасць.
Такім чынам, FAST VP бярэ на сябе традыцыйныя задачы Storage Tiering і робіць яшчэ крыху звыш таго. Усё гэта дазваляе дастаткова эфектыўна захоўваць дадзеныя ў СГД сямейства Unity.
некалькі саветаў
- Не грэбуйце чытаннем дакументацыі. Ёсць лепшыя practices, і яны працуюць даволі добра. Калі ім прытрымлівацца, то сур'ёзных праблем, як правіла, не ўзнікае. Астатнія парады ў асноўным паўтараюць або дапаўняюць іх.
- Калі вы наладзілі і ўключылі FAST VP, то лепш пакіньце уключаным. Няхай размяркоўвае дадзеныя ў адведзены для яго час і патроху, чым раз у год і аказваючы сур'ёзны ўплыў на прадукцыйнасць іншых задач. У такіх выпадках пераразмеркаванне дадзеных можа зацягнуцца надоўга.
- Уважліва паставіцца да выбару акна рэлакацыі. Хоць гэта і відавочна, але паспрабуйце абраць час з найменшай нагрузкай на Unity і вылучыце дастатковы прамежак часу.
- Плануйце пашырэнне СГД, рабіце гэта своечасова. Гэта агульная рэкамендацыя, якая важная і для FAST VP таксама. Калі аб'ём вольнага месца вельмі малы, то і перасоўванне дадзеных замарудзіцца ці стане немагчымым. Асабліва, калі вы занядбалі пунктам 2.
- Пашыраючы пул з уключаным FAST VP, не варта пачынаць з самых павольных дыскаў. Гэта значыць альбо дадаем усе запланаваныя RAID-групы адразу, альбо спачатку дадаем самыя хуткія дыскі. У гэтым выпадку пераразмеркаванне дадзеных на новыя "хуткія" дыскі падніме агульную хуткасць пула. У адваротным выпадку, пачаўшы з "павольных" дыскаў, можна атрымаць вельмі непрыемную сітуацыю. Спачатку адбудзецца перанос дадзеных на новыя, адносна павольныя дыскі, а пасля, пры даданні хутчэйшых, у зваротным кірунку. Тут ёсць нюансы, злучаныя з рознымі палітыкамі FAST VP, але ў агульным выпадку падобная сітуацыя магчымая.
Калі Вы прыглядаецеся да дадзенага прадукта, то паспрабаваць Unity у справе можна і бясплатна, запампаваўшы Unity VSA virtual appliance.

У завяршэнні матэрыялу дзялюся некалькімі карыснымі спасылкамі:
- Старонка
- – кароткае апісанне функцыі
- , фармат pdf
Заключэнне
Хочацца напісаць шмат аб чым, але я разумею, што не ўсе падрабязнасці будуць цікавыя чытачу. Напрыклад, можна падрабязней распавесці пра крытэры, па якіх FAST VP прымае рашэнне аб пераносе дадзеных, аб працэсах аналізу статыстыкі ўводу-высновы. Таксама зусім не закранута тэма ўзаемадзеяння з , а гэта цягне на асобны артыкул. Можна нават пафантазіраваць на тэму развіцця гэтай тэхналогіі. Спадзяюся, было не сумна, і я вас не стаміў. Да новых сустрэч!
Крыніца: habr.com
