

Мы разгледзім працу Zabbix з базай дадзеных TimescaleDB у якасці backend. Пакажам, як запусціць з нуля і як міграваць з PostgreSQL. Таксама прывядзем параўнальныя тэсты прадукцыйнасці двух канфігурацый.

HighLoad++ Siberia 2019. Зала "Томск". 24 чэрвеня, 16:00. Тэзісы і . Наступная канферэнцыя HighLoad++ пройдзе 6 і 7 красавіка 2020 гады ў Санкт-Пецярбургу. Падрабязнасці і білеты .
Андрэй Гушчын (далей - АГ): - Я - інжынер тэхнічнай падтрымкі ZABBIX (далей - «Забікс»), трэнер. Працую больш за 6 гадоў у тэхнічнай падтрымцы і напрамую сутыкаўся з прадукцыйнасцю. Сёння я буду распавядаць аб прадукцыйнасці, якую можа даць TimescaleDB, пры параўнанні са звычайным PostgreSQL 10. Таксама некаторая ўступная частка - аб тым, як наогул працуе.
Галоўныя выклікі прадукцыйнасці: ад збору да ачысткі дадзеных
Пачнём з таго, што ёсць пэўныя выклікі прадукцыйнасці, з якімі сустракаецца кожная сістэма маніторынгу. Першы выклік прадукцыйнасці - гэта хуткі збор і апрацоўка дадзеных.

Добрая сістэма маніторынгу павінна аператыўна, своечасова атрымліваць усе дадзеныя, апрацоўваць іх паводле трыгерных выразаў, гэта значыць апрацоўваць па нейкіх крытэрах (у розных сістэмах гэта па-рознаму) і захоўваць у базу дадзеных, каб у далейшым гэтыя дадзеныя выкарыстоўваць.

Другі выклік прадукцыйнасці - гэта захоўванне гісторыі. Захоўваць у базе даных часта і мець хуткі і зручны доступ да гэтых метрыкаў, якія былі сабраны за нейкі перыяд часу. Самае галоўнае, каб гэтыя дадзеныя было зручна атрымаць, выкарыстоўваць іх у справаздачах, графіках, трыгерах, у нейкіх парогавых значэннях, для абвестак і г.д.

Трэці выклік прадукцыйнасці - гэта ачыстка гісторыі, гэта значыць калі ў вас надыходзіць такі дзень, што вам не трэба захоўваць нейкія падрабязныя метрыкі, якія былі сабраны за 5 гадоў (нават месяцы ці два месяцы). Нейкія вузлы сеткі былі выдаленыя, альбо нейкія хасты, метрыкі ўжо не патрэбны таму, што яны ўжо састарэлі і перасталі збірацца. Гэта ўсё трэба вычышчаць, каб у вас база дадзеных не разраслася да вялікага памеру. І наогул, ачыстка гісторыі часцей за ўсё з'яўляецца сур'ёзным выпрабаваннем для сховішча - вельмі моцна часцяком уплывае на прадукцыйнасць.
Як вырашыць праблемы кэшавання?
Я зараз буду казаць канкрэтна пра «Забікс». У «Забіксе» першы і другі выклікі вырашаны з дапамогай кэшавання.

Збор і апрацоўка дадзеных - мы выкарыстоўваем аператыўную памяць для захоўвання ўсіх гэтых дадзеных. Цяпер аб гэтых дадзеных будзе падрабязней расказана.
Таксама на баку базы дадзеных ёсць пэўнае кэшаванне для асноўных выбарак - для графікаў, іншых рэчаў.
Кэшаванне на боку самога Zabbix-сервера: у нас прысутнічаюць ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Што гэта такое?

ConfigurationCache - гэта асноўны кэш, у якім мы захоўваем метрыкі, хасты, элементы дадзеных, трыгеры; усё, што трэба для апрацоўкі прэпрацэсінгу, збору дадзеных, з якіх хастоў збіраць, з якой частатой. Усё гэта захоўваецца ў ConfigurationCache, каб не хадзіць у базу даных, не ствараць лішніх запытаў. Пасля старту сервера мы абнаўляем гэты кэш (ствараем) і абнаўляем перыядычна (у залежнасці ад налад канфігурацыі).
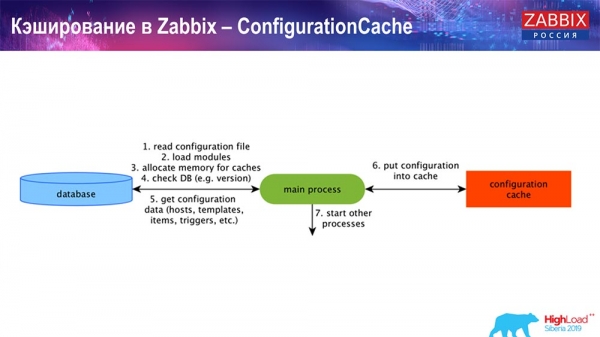
Кэшаванне ў Zabbix. Збор дадзеных
Тут схема дастаткова вялікая:
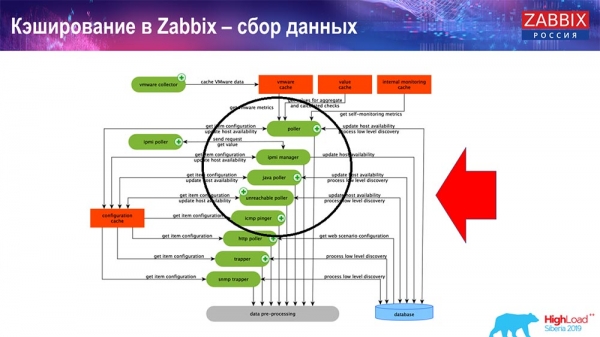
Асноўныя ў схеме - вось гэтыя зборшчыкі:
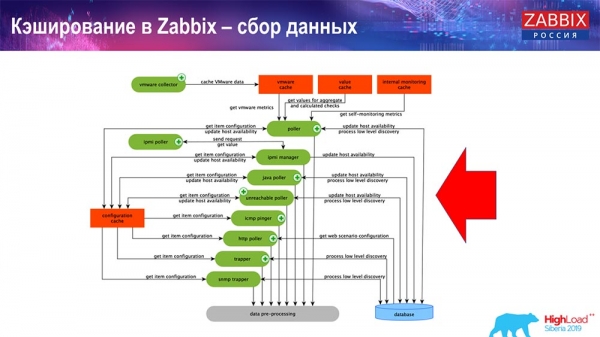
Гэта самі працэсы зборкі, розныя "полеры", якія адказваюць за розныя віды зборак. Яны збіраюць дадзеныя па icmp, ipmi, па розных пратаколах і перадаюць гэта ўсё на прэпрацэсінг.
PreProcessing HistoryCache
Таксама, калі ў нас ёсць вылічаныя элементы дадзеных (хто знаёмы з «Забікс» - ведае), гэта значыць вылічаныя, агрэгацыйныя элементы дадзеных, - мы іх забіраем напрамую з ValueCache. Пра тое, як ён напаўняецца, я раскажу пазней. Усе гэтыя зборшчыкі выкарыстоўваюць ConfigurationCache для атрымання сваіх заданняў і далей перадаюць на прэпрацэсінг.
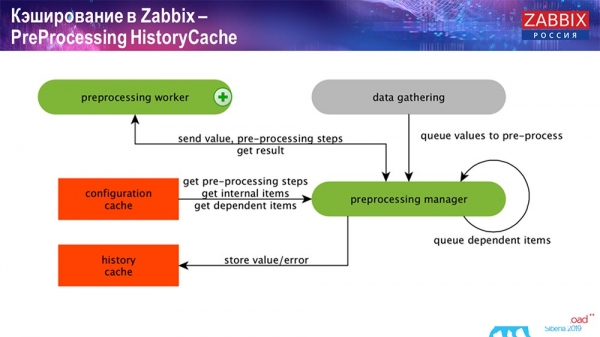
Прэпрацэсінгу таксама выкарыстоўвае ConfigurationCache для атрымання крокаў прэпрацэсінгу, апрацоўвае гэтыя дадзеныя розным спосабам. Пачынаючы з версіі 4.2, ён у нас вынесены на проксі. Гэта вельмі зручна, таму што сам прэпрацэсінг - даволі цяжкая аперацыя. І калі ў вас вельмі вялікі «Забікс», з вялікай колькасцю элементаў дадзеных і высокай частатой збору, тое гэта моцна палягчае працу.
Адпаведна, пасля таго як мы апрацавалі гэтыя дадзеныя якія-небудзь выявай з дапамогай препроцессинга, захоўваем іх у HistoryCache для таго, каб іх далей апрацаваць. На гэтым заканчваецца збор звестак. Мы пераходзім да галоўнага працэсу.
Праца History syncer
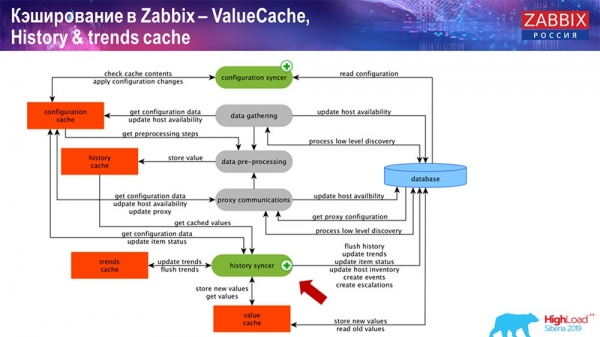
Галоўны ў «Забікс» працэс (бо гэта маналітная архітэктура) – History syncer. Гэта галоўны працэс, які займаецца менавіта атамарнай апрацоўкай кожнага элемента дадзеных, гэта значыць кожнага значэння:
- прыходзіць значэнне (ён яго бярэ з HistoryCache);
- правярае ў Configuration syncer: ці ёсць нейкія трыгеры для вылічэння - вылічае іх;
калі ёсць - стварае падзеі, стварае эскалацыю для таго, каб стварыць апавяшчэнне, калі гэта неабходна па канфігурацыі; - запісвае трыгеры для наступнай апрацоўкі, агрэгацыі; калі вы агрэгуеце за апошнюю гадзіну і гэтак далей, гэта значэнне запамінае ValueCache, каб не звяртацца ў табліцу гісторыі; такім чынам, ValueCache напаўняецца патрэбнымі дадзенымі, якія неабходны для вылічэння трыгераў, якія вылічаюцца элементаў і т. д.;
- далей History syncer запісвае ўсе дадзеныя ў базу дадзеных;
- база дадзеных запісвае іх на дыск - на гэтым працэс апрацоўкі заканчваецца.
Базы даных. Кэшаванне
На баку БД, калі вы хочаце паглядзець графікі ці нейкія справаздачы па падзеях, ёсць розныя кэшы. Але ў рамках гэтага дакладу я не буду пра іх расказваць.
Для MySQL ёсць Innodb_buffer_pool, яшчэ куча розных кэшаў, якія таксама можна наладзіць.
Але гэта - асноўныя:
- shared_buffers;
- effective_cache_size;
- shared_pool.

Я для ўсіх баз дадзеных прывёў, што ёсць пэўныя кэшы, якія дазваляюць трымаць у аператыўнай памяці тыя дадзеныя, якія часта неабходны для запытаў. Тамака ў іх свае тэхналогіі для гэтага.
Аб прадукцыйнасці базы дадзеных
Адпаведна, ёсць канкурэнтнае асяроддзе, гэта значыць "Забікс"-сервер збірае дадзеныя і запісвае іх. Пры перазапуску ён таксама чытае з гісторыі для напаўнення ValueCache і гэтак далей. Тут жа ў вас могуць быць скрыпты і справаздачы, якія выкарыстоўваюць "Заббікс"-API, які на базе вэб-інтэрфейсу пабудаваны. "Заббікс"-API уваходзіць у БД і атрымлівае неабходныя дадзеныя для атрымання графікаў, справаздач або нейкага спісу падзей, апошніх праблем.
Таксама вельмі папулярнае рашэнне для візуалізацыі - гэта Grafana, якое выкарыстоўваюць нашы карыстальнікі. Умее напрамую ўваходзіць як праз "Заббікс"-API, так і праз БД. Яно таксама стварае пэўную канкурэнцыю для атрымання дадзеных: патрэбна больш тонкая, добрая настройка БД, каб адпавядаць хуткай выдачы вынікаў і тэсціравання.

Ачыстка гісторыі. У Zabbix ёсць Housekeeper
Трэці выклік, які выкарыстоўваецца ў «Забікс» - гэта ачыстка гісторыі з дапамогай Housekeeper. "Хаўскіпер" выконвае ўсе налады, гэта значыць у нас у элементах дадзеных паказана, колькі захоўваць (у днях), колькі захоўваць трэнды, дынаміку змен.
Я не распавёў пра ТрендКэш, які мы вылічваем на лета: паступаюць дадзеныя, мы іх агрэгуем за адну гадзіну (у асноўным гэта лікі за апошнюю гадзіну), колькасць сярэднюю / мінімальную і запісваем гэта раз у гадзіну ў табліцу дынамікі змен («Трэндс») . "Хаўскіпер" запускаецца і выдаляе звычайнымі селектамі дадзеныя з БД, што не заўсёды эфектыўна.
Як зразумець, што гэта неэфектыўна? Вы можаце на графіках прадукцыйнасці ўнутраных працэсаў бачыць такую карціну:
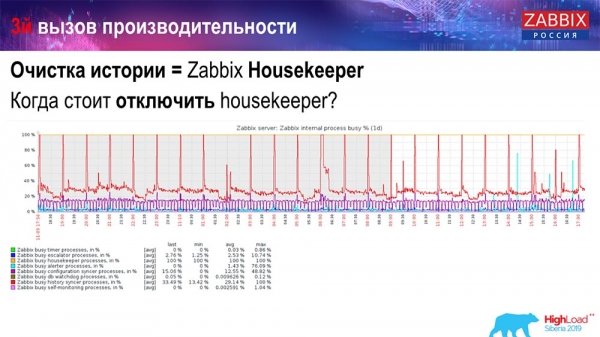
У вас History syncer стала заняты (чырвоны графік). І «руды» графік, які паверсе ідзе. Гэта "Хаўскіпер", які запускаецца і чакае ад БД, калі яна выдаліць усе радкі, якія ён задаў.
Возьмем які-небудзь Item ID: трэба выдаліць апошнія 5 тысяч; вядома, па азначніках. Але звычайна датасет досыць вялікі - база дадзеных усё роўна гэта счытвае з дыска і паднімае ў кэш, а гэта вельмі дарагая аперацыя для БД. У залежнасці ад яе памераў, гэта можа прыводзіць да пэўных праблем прадукцыйнасці.
Адключыць «Хаўскіпер» можна простым спосабам - у нас ёсць усім знаёмы вэб-інтэрфейс. Настройка ў Administration general (наладкі для «Хаўскіпера») мы адключаем унутраны housekeeping для ўнутранай гісторыі і трэндаў. Адпаведна, "Хаўскіпер" больш не кіруе гэтым:

Што можна рабіць далей? Вы адключылі, у вас графікі выраўняліся… Якія ў гэтым выпадку могуць быць далей за праблемы? Што дапаможа?
Партыцыянаванне (секцыянаванне)
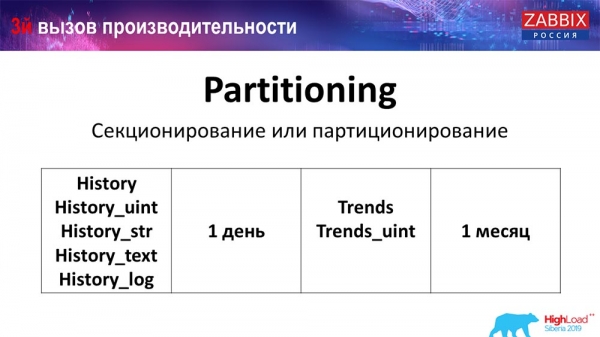
Звычайна гэта наладжваецца на кожнай рэляцыйнай базе дадзеных, якія я пералічыў, розным спосабам. На MySQL свая тэхналогія. Але ў цэлым яны вельмі падобныя, калі казаць аб PostgreSQL 10 і MySQL. Вядома, там вельмі шмат унутраных адрозненняў, як гэта ўсё рэалізавана і як гэта ўсё ўплывае на прадукцыйнасць. Але ў цэлым стварэнне новай партыцыі часта таксама прыводзіць да пэўных праблем.

У залежнасці ад вашага setup'а (наколькі шмат у вас ствараецца дадзеных за адзін дзень), звычайна выстаўляюць самы мінімальны - гэта 1 дзень/партыцыя, а для "трэндаў", дынамікі змен - 1 месяц / новая партыцыя. Гэта можа мяняцца, калі ў вас вельмі вялікі setup.
Адразу давайце скажу аб памерах setup'а: да 5 тысяч новых значэнняў у секунду (nvps так званы) - гэта будзе лічыцца малы "сетап". Сярэдні - ад 5 да 25 тысяч значэнняў у секунду. Усё, што звыш - гэта ўжо вялікія і вельмі вялікія інсталяцыі, якія патрабуюць вельмі дбайнай наладкі менавіта базы дадзеных.
На вельмі вялікіх усталёўках 1 дзень гэта можа быць не аптымальна. Я асабіста бачыў на MySQL партыцыі па 40 гігабайт у дзень (і больш могуць быць). Гэта вельмі вялікі аб'ём дадзеных, які можа прыводзіць да нейкіх праблем. Яго трэба змяншаць.
Навошта трэба партыцыянаванне?
Што дае Partitioning, я думаю, усе ведаюць - гэта секцыянаванне табліц. Часцяком гэта асобныя файлы на дыску і спан-запытаў. Ён больш аптымальна выбірае адну партыцыю, калі гэта ўваходзіць у звычайнае партыцыянаванне.
Для «Забікса», у прыватнасці, выкарыстоўваецца па рэнджу, па дыяпазоне, гэта значыць мы выкарыстоўваем таймстамп (колькасць звычайнае, час з пачатку эпохі). Вы задаеце пачатак дня / канец дня, і гэта з'яўляецца партыцыяй. Адпаведна, калі вы звяртаецеся за дадзенымі двухдзённай даўнасці, гэта ўсё выбіраецца з базы дадзеных хутчэй, таму што трэба ўсяго адзін файл загрузіць у кэш і выдаць (а не вялікую табліцу).

Многія БД таксама паскарае insert (устаўка ў адну child-табліцу). Пакуль я кажу абстрактна, але гэта таксама магчыма. Partitoning часта дапамагае.
Elasticsearch для NoSQL
Нядаўна, у 3.4, мы ўкаранілі рашэнне для NoSQL. Дадалі магчымасць пісаць у Elasticsearch. Вы можаце пісаць асобныя нейкія тыпы: выбіраеце - альбо лікі пішыце, альбо нейкія знакі; у нас ёсць стрынг-тэкст, логі можаце пісаць у Elasticsearch… Адпаведна, вэб-інтэрфейс ужо таксама будзе звяртацца да Elasticsearch. Гэта выдатна ў нейкіх выпадках працуе, але ў дадзены момант гэта можна выкарыстоўваць.

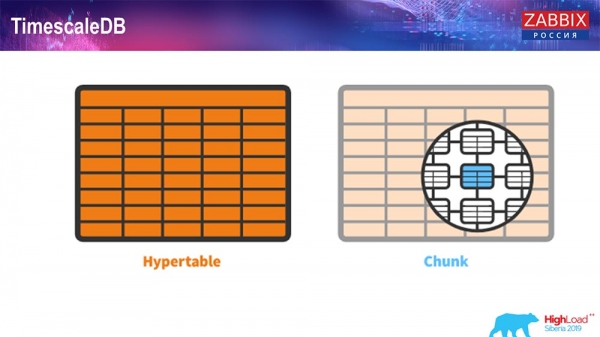
TimescaleDB. Гіпертабліцы
Для 4.4.2 мы звярнулі ўвагу на адну рэч, як TimescaleDB. Што гэта такое? Гэта пашырэнне для "Постгрэс", гэта значыць яно мае натыўны інтэрфейс PostgreSQL. Плюс, гэтае пашырэнне дазваляе нашмат больш эфектыўна працаваць з timeseries-дадзенымі і мець аўтаматычнае партыцыраванне. Як гэта выглядае:

Гэта hypertable ёсць такое паняцце ў Timescale. Гэта гіпертабліца, якую вы ствараеце, і ў ёй знаходзяцца чанкі (chunk). Чанкі - гэта партіціі, гэта чайлд-табліцы, калі не памыляюся. Гэта сапраўды эфэктыўна.
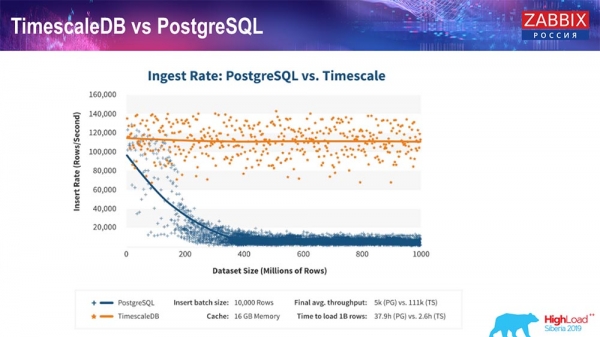
TimescaleDB і PostgreSQL
Як запэўніваюць вытворцы TimescaleDB, яны выкарыстоўваюць больш правільны алгарытм апрацоўкі запытаў, у прыватнасці insert'аў, які дазваляе мець прыкладна сталую прадукцыйнасць пры які павялічваецца памеры датасет-устаўкі. Гэта значыць пасля 200 мільёнаў радкоў "Постгрэс" звычайны пачынае вельмі моцна прасядаць і губляе прадукцыйнасць літаральна да нуля, у той час як "Таймскейл" дазваляе ўстаўляць інсерты як мага больш эфектыўна пры любой колькасці дадзеных.
Як усталяваць TimescaleDB? Усё проста!
Ёсць у яго ў дакументацыі, апісана - можна паставіць з пакетаў для любых ... Ён залежыць ад афіцыйных пакетаў "Постгрэса". Можна скампіляваць уручную. Так атрымалася, што мне прыйшлося кампіляваць для БД.
На «Забікс» мы проста актывуем Extention. Я думаю, што тыя, хто карыстаўся ў «Постгрэсе» Extention… Вы проста актывуеце Extention, ствараеце яго для БД «Забікс», якую карыстаецеся.
І апошні крок…
TimescaleDB. Міграцыя табліц гісторыі
Вы павінны стварыць hypertable. Для гэтага ёсць спецыяльная функцыя - Create hypertable. У ёй першым параметрам паказваеце табліцу, якая ў гэтай БД патрэбна (для якой трэба стварыць гіпертабліцу).

Поле, па якім трэба стварыць, і chunk_time_interval (гэта інтэрвал чанкаў (партыцый, якія трэба выкарыстоўваць). 86 - гэта адзін дзень.
Параметр migrate_data: калі вы ўстаўляеце ў true, тое гэта пераносіць усе бягучыя дадзеныя ў загадзя створаныя чанкі.
Я сам выкарыстоўваў migrate_data - гэта займае прыстойны час, у залежнасці ад таго, якіх памераў у вас БД. У мяне было больш тэрабайта - стварэнне заняло больш за гадзіну. У нейкіх выпадках пры тэставанні я выдаляў гістарычныя дадзеныя для тэксту (history_text) і стрынгу (history_str), каб не пераносіць - яны мне насамрэч былі не цікавыя.
І апошні апдэйт мы робім у нашым db_extention: мы ставім timescaledb, каб БД і, у прыватнасці, наш «Забікс» разумеў, што ёсць db_extention. Ён яго актывуе і выкарыстоўвае правільна сінтаксіс і запыты да БД, выкарыстоўваючы ўжо тыя "фічы", якія неабходныя для TimescaleDB.
Канфігурацыя сервера
Я выкарыстаў два серверы. Першы сервер - гэта віртуальная машына досыць маленькая, 20 працэсараў, 16 гігабайт аператыўнай памяці. Наладзіў на ёй «Постгрэс» 10.8:

Аперацыйная сістэма была Debian, файлавая сістэма - xfs. Зрабіў мінімальныя настройкі, каб выкарыстоўваць менавіта гэтую базу дадзеных, за вылікам таго, што будзе выкарыстоўваць сам «Забікс». На гэтай жа машыне стаяў "Забікс"-сервер, PostgreSQL і нагрузачныя агенты.

Я выкарыстоўваў 50 актыўных агентаў, якія выкарыстоўваюць LoadableModule, каб хутка генераваць розныя вынікі. Гэта яны згенеравалі радкі, лікі і гэтак далей. Я забіваў БД вялікай колькасцю дадзеных. Першапачаткова канфігурацыя ўтрымоўвала 5 тысяч элементаў дадзеных на кожны хост, і прыкладна кожны элемент дадзеных утрымоўваў трыгер - для таго, каб гэта быў рэальны setup. Часам для выкарыстання нават патрабуецца больш за адзін трыгер.

Інтэрвал абнаўлення, саму нагрузку я рэгуляваў тым, што не толькі 50 агентаў выкарыстаў (дадаваў яшчэ), але і з дапамогай дынамічных элементаў дадзеных і змяншаў апдэйт-інтэрвал да 4 секунд.
Тэст прадукцыйнасці. PostgreSQL: 36 тысяч NVPs
Першы запуск, першы setup у мяне быў на чыстым PostreSQL 10 на гэтым жалезе (35 значэнняў у секунду). У цэлым, як відаць на экране, устаўка дадзеных займае фракцыі секунды - усё добра і хутка, SSD-дыскі (200 гігабайт). Адзінае, што 20 ГБ дастаткова хутка запаўняюцца.
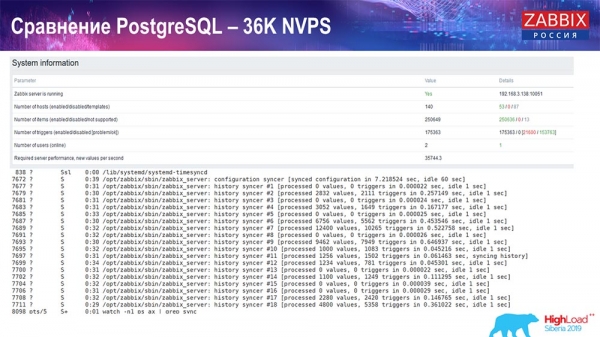
Будзе далей дастаткова шмат такіх графікаў. Гэта стандартны dashboard прадукцыйнасці "Забікс"-сервера.
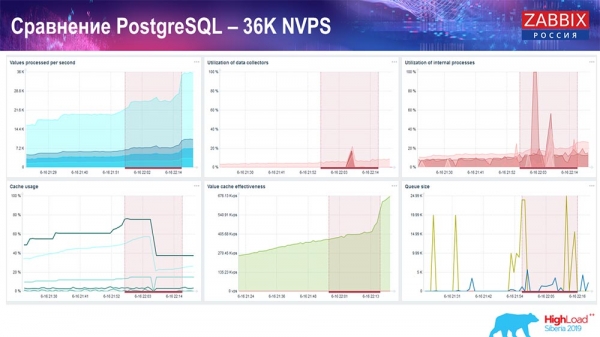
Першы графік - колькасць значэнняў у секунду (блакітны, наверсе злева), 35 тысяч значэнняў у дадзеным выпадку. Гэта (наверсе ў цэнтры) загрузка працэсаў зборкі, а гэта (наверсе справа) - загрузка менавіта ўнутраных працэсаў: history syncers і housekeeper, які тут (унізе ў цэнтры) выконваўся дастатковы час.
Гэты графік (унізе ў цэнтры) паказвае выкарыстанне ValueCache - колькі хітоў ValueCache для трыгераў (некалькі тысяч значэнняў у секунду). Яшчэ важны графік - чацвёрты (унізе злева), які паказвае выкарыстанне HistoryCache, пра які я распавёў, які з'яўляецца буферам перад устаўкай у БД.
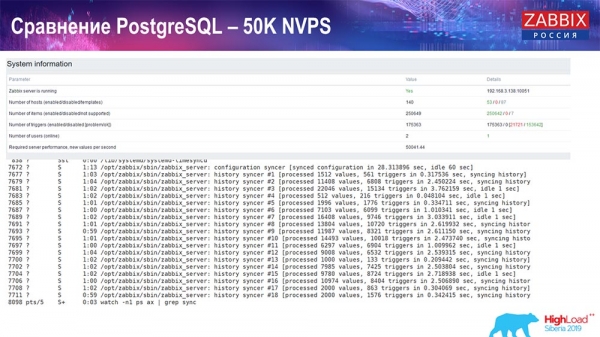
Тэст прадукцыйнасці. PostgreSQL: 50 тысяч NVPs
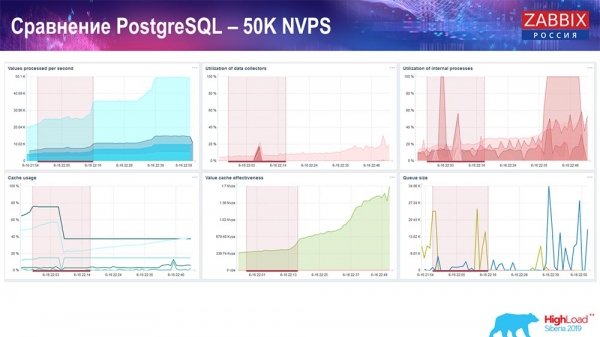
Далей я павялічыў нагрузку да 50 тысяч значэнняў за секунду на гэтым жа жалезе. Пры загрузцы «Хаўскіперам» 10 тысяч значэнняў запісвалася ўжо ў 2-3 секунды з вылічэннем. Што, уласна, паказана на наступным скрыншоце:
"Хаўскіпер" ужо пачынае замінаць працы, але ў цэлым загрузка трапераў хісторы-сінкераў пакуль яшчэ знаходзіцца на ўзроўні 60% (трэці графік, уверсе справа). HistoryCache ужо падчас працы "Хаўскіпера" пачынае актыўна запаўняцца (унізе злева). Ён быў каля паўгігабайта, запаўняўся на 20%.
Тэст прадукцыйнасці. PostgreSQL: 80 тысяч NVPs
Далей павялічыў да 80 тысяч значэнняў за секунду:
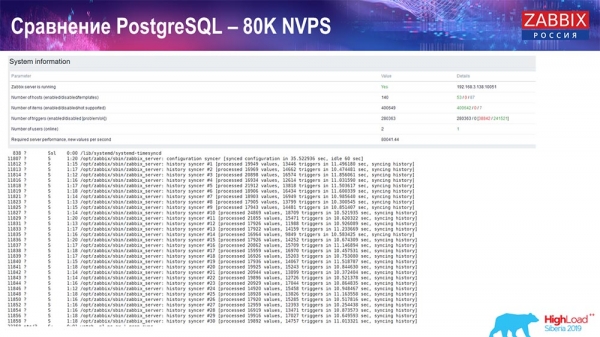
Гэта было прыкладна 400 тысяч элементаў звестак, 280 тысяч трыгераў. Устаўка, як бачыце, па загрузцы хісторы-сінкераў (іх было 30 штук) была ўжо дастаткова высокая. Далей я павялічваў розныя параметры: гісторы-сінкеры, кэш…
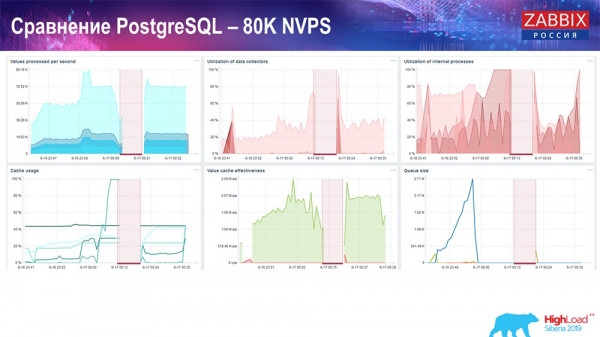
Увесь гэты час я назіраў за ўсімі параметрамі сістэмы (як працэсар выкарыстоўваецца, аператыўная памяць) і выявіў, што ўтылізацыя дыскаў была максімальнай - я дамогся максімальнай магчымасці гэтага дыска на гэтым жалезе, на гэтай віртуальнай машыне. «Постгрэс» пачаў пры такой інтэнсіўнасці скідаць дадзеныя дастаткова актыўна, і дыск ужо не паспяваў на запіс, чытанне…
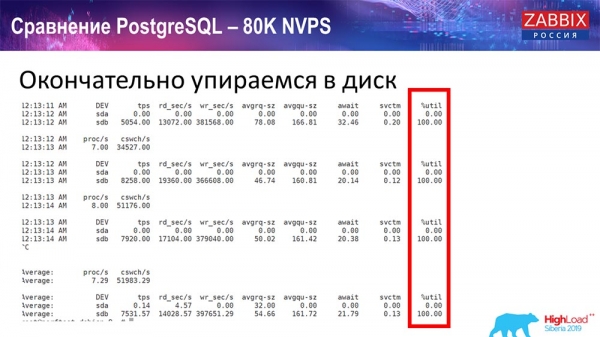
Я ўзяў іншы сервер, які ўжо меў 48 працэсараў 128 гігабайт аператыўнай памяці:
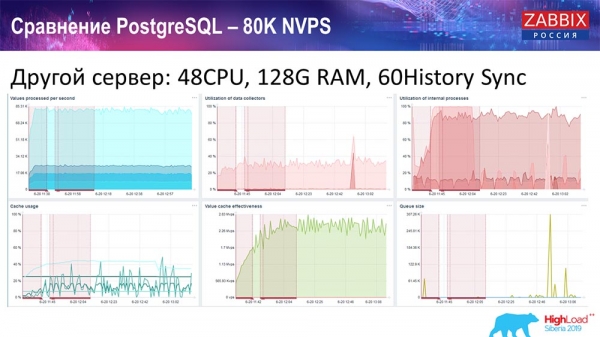
Таксама я яго зацюніў паставіў History syncer (60 штук) і дамогся прымальнай хуткадзейнасці. Фактычна мы не "ў паліцы", але гэта ўжо, напэўна, мяжа прадукцыйнасці, дзе ўжо неабходна нешта з гэтым рабіць.
Тэст прадукцыйнасці. TimescaleDB: 80 тысяч NVPs
У мяне была галоўная задача - выкарыстоўваць TimescaleDB. На кожным графіку бачны правал:
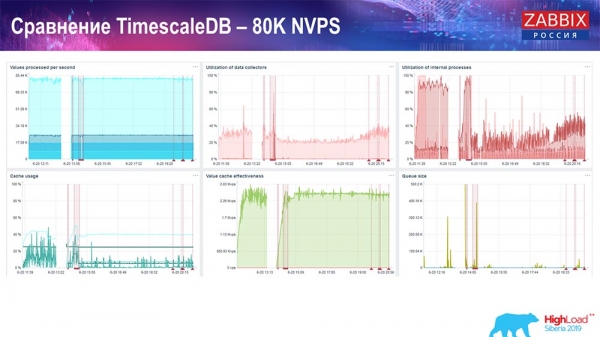
Гэтыя правалы - як раз міграцыя дадзеных. Пасля гэтага ў «Забікс»-серверы профіль загрузкі хісторы-сінкераў, як вы бачыце, вельмі моцна змяніўся. Ён практычна ў 3 разы хутчэй дазваляе ўстаўляць дадзеныя і выкарыстоўваць менш HistoryCache - адпаведна, у вас своечасова будуць пастаўляцца дадзеныя. Ізноў жа, 80 тысяч значэнняў у секунду - гэта досыць высокі rate (вядома, не для «Яндэкса»). У цэлым гэта дастаткова вялікі setup, з адным серверам.
Тэст прадукцыйнасці PostgreSQL: 120 тысяч NVPs
Далей я павялічыў значэнне колькасці элементаў дадзеных да паўмільёна і атрымаў разліковае значэнне 125 тысяч у секунду:
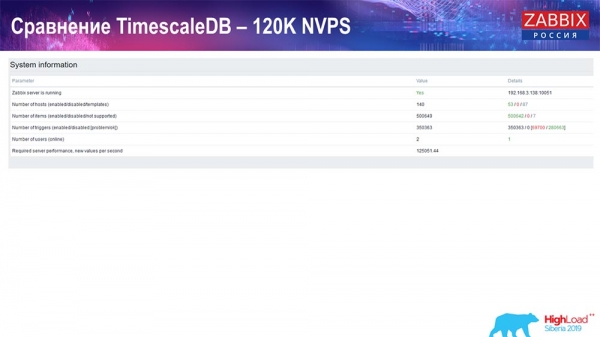
І атрымаў такія графікі:
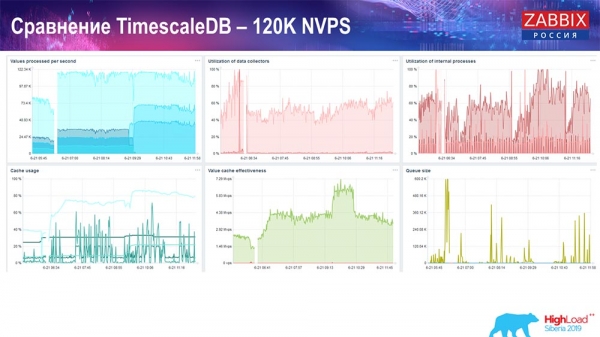
У прынцыпе гэта працоўны setup, ён можа дастаткова працяглы час працаваць. Але бо ў мяне быў дыск усяго на 1,5 тэрабайта, то я яго расходаваў за пару дзён. Самае важнае, што ў той жа час ствараліся новыя партіціна TimescaleDB, і гэта для прадукцыйнасці праходзіла зусім незаўважна, чаго не скажаш аб MySQL.
Звычайна партіціі ствараюцца ўначы, таму што гэта блакуе наогул устаўку і працу з табліцамі, можа прыводзіць да дэградацыі сэрвісу. У дадзеным выпадку гэтага няма! Галоўная задача была - праверыць магчымасці TimescaleDB. Атрымалася такая лічба: 120 тысяч значэнняў за секунду.
Таксама ёсць у «кам'юніці» прыклады:
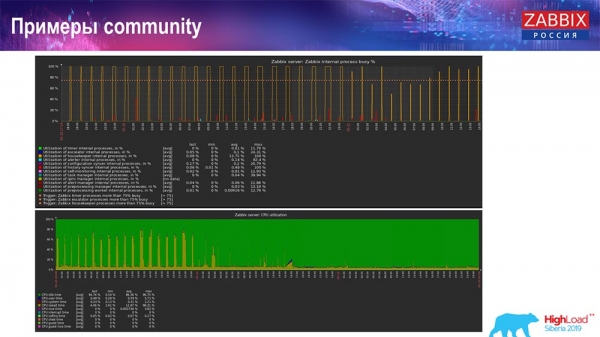
Чалавек таксама ўключыў TimescaleDB і загрузка па выкарыстанні io.weight звалілася на працэсары; і выкарыстанне элементаў унутраных працэсаў таксама знізілася дзякуючы ўключэнню TimescaleDB. Прычым гэта звычайныя блінные дыскі, гэта значыць звычайная віртуалка на звычайных дысках (не SSD)!
Для нейкіх маленькіх setup'аў, якія ўпіраюцца ў прадукцыйнасць дыска, TimescaleDB, як мне здаецца, вельмі добрае рашэнне. Яно нядрэнна дазволіць працягваць працаваць да таго, як міграваць на хутчэйшае жалеза для базы дадзеных.
Запрашаю ўсіх вас на нашы мерапрыемствы: Conference - у Маскве, Summit - у Рызе. Выкарыстоўвайце нашы каналы - "Тэлеграм", форум, IRC. Калі ў вас ёсць нейкія пытанні - прыходзьце да нас на стойку, можам пагаварыць пра ўсё.
Пытанні аўдыторыі
Пытанне з аўдыторыі (далей – А): – Калі TimescaleDB так проста ў наладзе, і ён дае такі прырост прадукцыйнасці, то, магчыма, гэта варта выкарыстоўваць як лепшую практыку налады «Забікса» з «Постгрэсам»? І ці ёсць нейкія падводныя камяні і мінусы гэтага рашэння, ці ўсё ж такі, калі я вырашыў сабе рабіць «Забікс», я магу спакойна браць «Постгрэс», ставіць туды «Таймскейл» адразу, карыстацца і не думаць ні пра якія праблемы ?

АГ: - Так, я сказаў бы, што гэта добрая рэкамендацыя: выкарыстоўваць "Постгрэс" адразу з пашырэннем TimescaleDB. Як я ўжо казаў, мноства добрых водгукаў, нягледзячы на тое, што гэтая фіча эксперыментальная. Але на самой справе тэсты паказваюць, што гэта выдатнае рашэнне (з TimescaleDB), і я думаю, што яно будзе развівацца! Мы сочым за тым, як гэтае пашырэнне развіваецца і будзем кіраваць тое, што трэба.
Мы нават падчас распрацоўкі абапіраліся на адну іх вядомую «фічу»: там можна было з чанкамі крыху па-іншаму працаваць. Але потым яны гэта ў наступным рэлізе выпілавалі, і нам прыйшлося ўжо не абапірацца на гэты код. Я б рэкамендаваў выкарыстоўваць гэтае рашэнне на шматлікіх setup'ах. Калі вы карыстаецеся MySQL… Для сярэдніх setup'аў любое рашэнне нядрэнна працуе.
А: – На апошніх графіках, якія ад community, быў графік з «Хаўскіперам»:
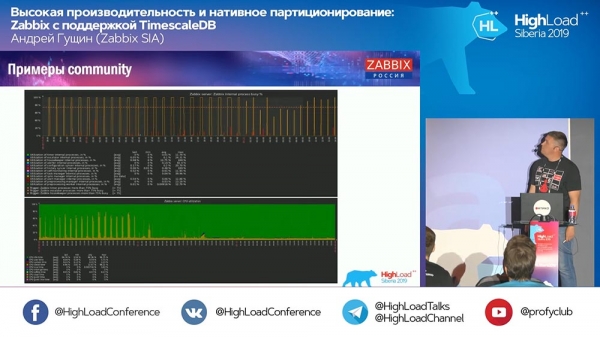
Ён працягнуў працаваць. Што «Хаўскіпер» робіць у выпадку з TimescaleDB?
АГ: - Цяпер не магу дакладна сказаць - пагляджу код і скажу больш падрабязна. Ён выкарыстоўвае запыты менавіта TimescaleDB не для выдалення чанкаў, а неяк агрэгуе. Пакуль я не гатовы адказаць на гэтае тэхнічнае пытанне. На стэндзе сёння ці заўтра ўдакладнім.
А: - У мяне падобнае пытанне - аб прадукцыйнасці аперацыі выдалення ў «Таймскейл».
А (адказ з аўдыторыі): - Калі вы выдаляеце дадзеныя з табліцы, калі вы гэта робіце праз delete, то вам трэба прайсціся па табліцы - выдаліць, пачысціць, пазначыць усё на будучы вакуум. У «Таймскейл», бо вы маеце чанкі, вы можаце драпаць. Грубіянска кажучы, вы проста кажаце файлу, які ляжыць у big data: «Выдаліць!»
"Таймскейл" проста разумее, што такога чанка больш няма. І бо ён інтэгруецца ў планавальнік запыту, ён на хуках ловіць вашы ўмовы ў select'е ці ў іншых аперацыях і адразу разумее, што гэтага чанка больш няма - "Я туды больш не пайду!" (дадзеныя адсутнічаюць). Вось і ўсё! Гэта значыць, скан табліцы замяняецца на выдаленне бінарнага файла, таму гэта хутка.
А: - Ужо закраналі тэму не SQL. Наколькі я разумею, «Забікс» не вельмі трэба мадыфікаваць дадзеныя, а ўсё гэта - нешта накшталт лога. Ці можна выкарыстоўваць спецыялізаваныя БД, якія не могуць мяняць свае дадзеныя, але пры гэтым значна хутчэй захоўваюць, назапашваюць, аддаюць - Clickhouse, дапусцім, што-небудзь кафка-вобразнае?.. Kafka - гэта ж таксама лог! Ці можна іх неяк інтэграваць?
АГ: - Выгрузку можна зрабіць. У нас ёсць пэўная "фіча" з версіі 3.4: вы можаце пісаць у файлы ўсе гістарычныя файлы, івэнты, усё іншае; і далей нейкім апрацоўшчыкам адсылаць у любую іншую БД. Насамрэч шмат хто перарабляе і піша напрамую ў БД. На лёце гісторы-сінкеры ўсё гэта пішуць у файлы, ратыруюць гэтыя файлы і гэтак далей, і гэта вы можаце перакідаць у «Клікхаўс». Не магу сказаць аб планах, але, магчыма, далейшая падтрымка NoSQL-рашэнняў (такіх, як "Клікхаус") будзе працягвацца.
А: - Наогул, атрымліваецца, можна цалкам пазбавіцца ад постгрэсу?
АГ: - Вядома, самая складаная частка ў «Забікс» - гэта гістарычныя табліцы, якія ствараюць больш за ўсё праблем, і падзеі. У тым выпадку, калі вы не будзеце доўга захоўваць падзеі і будзеце захоўваць гісторыю з трэндамі ў нейкім іншым хуткім сховішчы, то ў цэлым ніякіх праблем, думаю, не будзе.
А: - Можаце ацаніць, наколькі хутчэй усё будзе працаваць, калі перайсці на «Клікхаус», дапусцім?
АГ: - Я не тэставаў. Думаю, што як мінімум тых жа лічбаў можна будзе дасягнуць дастаткова проста, улічваючы, што «Клікхаус» мае свой інтэрфейс, але не магу сказаць адназначна. Лепш пратэставаць. Усё залежыць ад канфігурацыі: колькі ў вас хастоў і гэтак далей. Устаўка - гэта адно, але трэба яшчэ забіраць гэтыя дадзеныя - Grafana ці яшчэ чымсьці.
А: - Гэта значыць гаворка ідзе аб роўнай барацьбе, а не аб вялікай перавазе гэтых хуткіх БД?
АГ: - Думаю, калі інтэгруемся, будуць больш дакладныя тэсты.
А: - А куды падзеўся стары добры RRD? Што прымусіла перайсці на базы дадзеных SQL? Першапачаткова ж на RRD усе метрыкі збіраліся.
АГ: - У Zabbix RRD, можа быць, у вельмі старажытнай версіі быў. Заўсёды былі SQL-ныя базы - класічны падыход. Класічны падыход - гэта MySQL, PostgreSQL (вельмі даўно ўжо існуюць). У нас агульны інтэрфейс для баз дадзеных SQL і RRD мы практычна ніколі не выкарыстоўвалі.


Крыху рэкламы 🙂
Дзякуй, што застаяцеся з намі. Вам падабаюцца нашыя артыкулы? Жадаеце бачыць больш цікавых матэрыялаў? Падтрымайце нас, аформіўшы замову ці парэкамендаваўшы знаёмым, , унікальны аналаг entry-level сервераў, які быў прыдуманы намі для Вас: (даступныя варыянты з RAID1 і RAID10, да 24 ядраў і да 40GB DDR4).
Dell R730xd у 2 разы танней у дата-цэнтры Equinix Tier IV у Амстэрдаме? Толькі ў нас у Нідэрландах! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – ад $99! Чытайце аб тым
Крыніца: habr.com
