

Наступная канферэнцыя HighLoad++ пройдзе 6 і 7 красавіка 2020 гады ў Санкт-Пецярбургу Падрабязнасці і квіткі . HighLoad++ Moscow 2018. Зала «Масква». 9 лістапада, 15:00. Тэзісы і .

* Маніторынг - анлайн і аналітыка.
* Асноўныя абмежаванні платформы ZABBIX.
* Рашэнне для маштабавання сховішчы аналітыкі.
* Аптымізацыя сервера ZABBIX.
* Аптымізацыя UI.
* Вопыт эксплуатацыі сістэмы пры нагрузках больш за 40k NVPS.
* Коратка высновы.
Міхаіл Макураў (далей - ММ): - Усім прывітанне!
Максім Чарняцоў (далей - МЧ): - Добры дзень!
ММ: - Дазвольце мне ўявіць Максіма. Макс - таленавіты інжынер, лепшы сецявік, якога я ведаю. Максім займаецца сеткамі і сэрвісамі, іх развіццём і эксплуатацыяй.

МЧ: – А я б хацеў расказаць пра Міхаіла. Міхаіл - распрацоўшчык на Сі. Ён напісаў некалькі высоканагружаных рашэнняў па апрацоўцы трафіку для нашай кампаніі. Мы жывем і працуем на Ўрале, у горадзе суровых мужыкоў Чэлябінску, у кампаніі «Інтэрсувязь». Наша кампанія - гэта пастаўшчык паслуг інтэрнэту і кабельнага тэлебачання для аднаго мільёна чалавек у 16 гарадах.
ММ: - І варта сказаць, што «Інтэрсувязь» - значна больш, чым проста правайдэр, гэта IT-кампанія. Большасць нашых рашэнняў зроблена сіламі нашага ІТ-аддзела.
А: ад сервераў, якія апрацоўваюць трафік, да кол-цэнтра і мабільнага прыкладання. У IT-аддзеле зараз каля 80 чалавек з вельмі і вельмі разнастайнымі кампетэнцыямі.
Аб Zabbix і яго архітэктуры
МЧ: - А зараз я паспрабую паставіць асабісты рэкорд і за адну хвіліну сказаць, што ж такое Zabbix (далей - «Забікс»).
"Забікс" пазіцыянуе сябе як сістэму маніторынгу "са скрынкі" ўзроўню прадпрыемства. У ім ёсць шмат якія спрашчаюць жыццё функцый: развітыя правілы эскалацыі, API для інтэграцыі, групоўка і аўтавыяўленне хастоў і метрык. У «Забіксе» ёсць так званыя сродкі маштабавання - проксі. «Забікс» - гэта сістэма з адкрытым зыходным кодам.
Коратка аб архітэктуры. Можна сказаць, яна складаецца з трох кампанентаў:
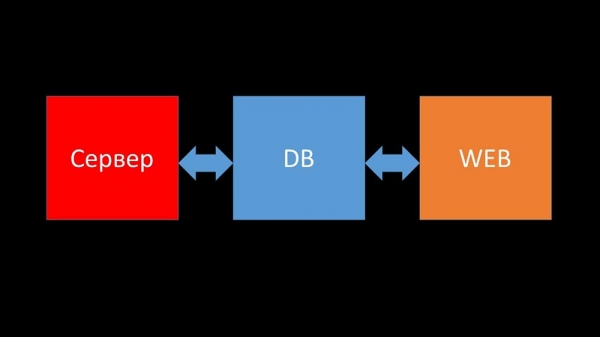
- Сервер. Напісаны на Сі. З дастаткова складанай апрацоўкай і перадачай інфармацыі паміж патокамі. Уся апрацоўка адбываецца ў ім: ад атрымання да захавання ў базу.
- Усе дадзеныя захоўваюцца ў базе. "Забікс" падтрымлівае MySQL, PostreSQL і Oracle.
- Вэб-інтэрфейс напісаны на PHP. У большасці сістэм пастаўляецца з серверам Apache, але больш эфектыўна працуе ў звязку nginx + php.
Сёння мы хацелі б расказаць з жыцця нашай кампаніі адну гісторыю, звязаную з «Забікс»…
Гісторыя з жыцця кампаніі "Інтэрсувязь". Што маем і што трэба?

5 ці 6 месяцаў таму назад.
МЧ: - Міша, прывітанне! Рады, што паспеў цябе злавіць - ёсць размова. У нас зноў былі праблемы з маніторынгам. Падчас буйной аварыі ўсё тармазіла, і не было ніякай інфармацыі аб стане сеткі. Нажаль, гэта паўтараецца ўжо не ў першы раз. Мне патрэбна твая дапамога. Давай зробім так, каб наш маніторынг працаваў пры любых абставінах!
ММ: - Але давай спачатку сінхранізуемся. Я не глядзеў туды ўжо пару гадоў. Наколькі я памятаю, мы адмовіліся Nagios і перайшлі на «Забікс» гадоў 8 таму. І зараз у нас, здаецца, 6 магутных сервераў і каля дзясятка проксі. Я нічога не блытаю?
МЧ: - Амаль. 15 сервераў, частка з якіх віртуальныя машыны. Самае галоўнае, што гэта не ратуе нас у той момант, калі трэба больш за ўсё. Як аварыя - сервера тармозяць і нічога не відаць. Мы спрабавалі аптымізаваць канфігурацыю, але аптымальнага прыросту прадукцыйнасці гэта не дае.
ММ: - Зразумела. Нешта глядзелі, нешта ўжо накапалі з дыягностыкі?
МЧ: - Першае, з чым даводзіцца мець справу - гэта як раз БД. Такім чынам пастаянна нагружаны, захоўваючы новыя метрыкі, а калі "Заббікс" пачынае генераваць кучу падзей - база сыходзіць у сябе літаральна на некалькі гадзін. лінейна гадаваць яго далёка няма сэнсу.
ММ: - Зразумела. Наогул, MySQL - гэта LTP-база. Мабыць, яна больш не падыходзіць для захоўвання архіва метрык нашага памеру. Давай разбірацца.
МЧ: - Давай!
Інтэграцыя Zabbix і Clickhouse як вынік хакатона
Праз некаторы час мы атрымалі цікавыя дадзеныя:

Большая частка месца ў нашай базе была занята архівам метрык і менш за 1% выкарыстоўвалася пад канфігурацыю, шаблоны і наладкі. Да таго моманту мы ўжо больш за год эксплуатавалі рашэнне Big data на базе Clickhouse. Кірунак руху для нас было відавочным. На нашым вясновым «Хакатоне» напісаў інтэграцыю «Забікса» з «Клікхаўсам» для сервера і фронтэнда. На той момант у «Забіксе» ужо была падтрымка ElasticSearch, і мы вырашылі параўнаць іх.

Параўнанне Clickhouse і Elasticsearch
ММ: - Для параўнання мы генеравалі нагрузку такую ж, якую забяспечвае «Заббікс»-сервер і глядзелі, як сябе будуць паводзіць сістэмы. Мы пісалі дадзеныя пачкамі па 1000 радкоў, выкарыстоўвалі CURL. Мы загадзя меркавалі, што "Клікхаус" будзе больш эфектыўным для таго профілю нагрузкі, якую робіць "Забікс". Вынікі нават перасягнулі нашы чаканні:
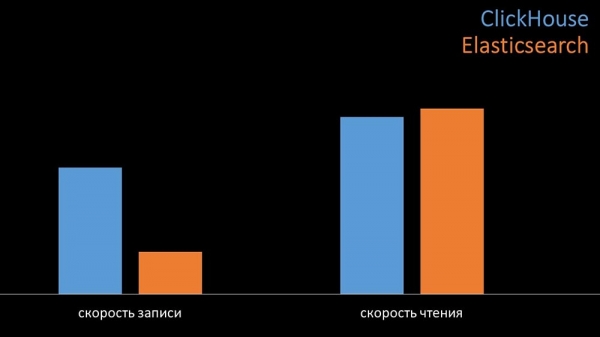
У аднолькавых умовах на тэстах "Клікхаус" пісаў у тры разы больш дадзеных. Пры гэтым абедзве сістэмы вельмі эфектыўна спажывалі (малую колькасць рэсурсаў), чытаючы дадзеныя. Але «Эластыкс» пры запісе патрабавалася вялікая колькасць працэсара:
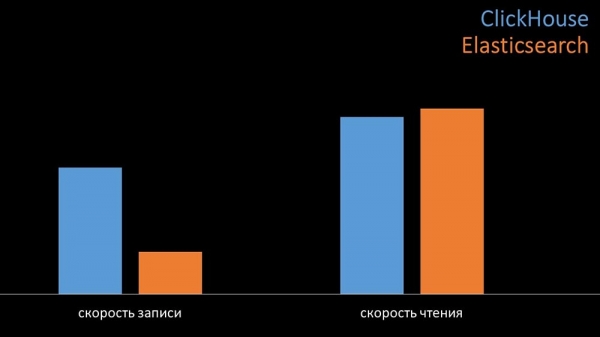
Сумарна "Клікхаус" значна пераўзыходзіў "Эластыкс" па спажыванні працэсара і па хуткасці. Пры гэтым за кошт сціску дадзеных «Клікхаус» выкарыстоўвае ў 11 разоў менш на цвёрдым дыску і робіць прыкладна ў 30 разоў менш дыскавых аперацый:
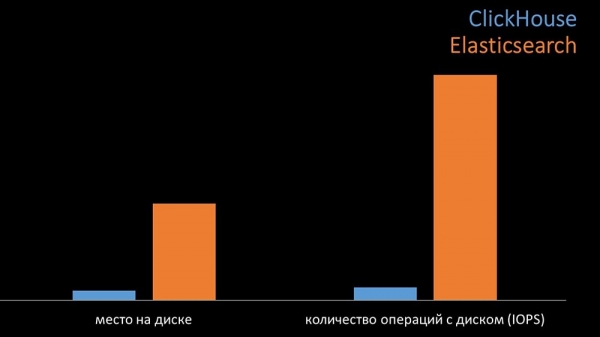
МЧ: - Так, праца з дыскавай падсістэмай у «Клікхауса» рэалізаваная вельмі эфектыўна. Пад базы можна выкарыстоўваць вялізныя SATA-дыскі і атрымліваць хуткасць запісу ў сотні тысяч радкоў у секунду. Сістэма са скрынкі падтрымлівае шардынг, рэплікацыю, вельмі простая ў наладзе. Мы больш за задаволены яе эксплуатацыяй на працягу года.
Для аптымізацыі рэсурсаў можна ўсталяваць "Клікхаус" побач з існуючай асноўнай базай і тым самым захаваць плойму працэсарнага часу і дыскавых аперацый. Мы вынеслі архіў метрык на ўжо наяўныя «Клікхаўс»-кластэры:
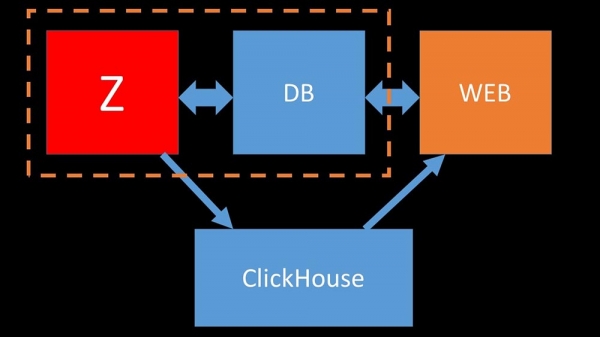
Мы настолькі разгрузілі асноўную MySQL-базу, што маглі аб'яднаць яе на адной машыне з "Забікс"-серверам і адмовіцца ад выдзеленага сервера пад MySQL.
Як уладкованы polling у Zabbix?
4 месяцы таму
ММ: - Ну што, аб праблемах з базай можна забыцца?
МЧ: - Гэта дакладна! Іншая задача, якую нам трэба вырашыць - гэта павольны збор дадзеных.
ММ: - Выдатна. Але раскажы перш, як уладкованы полінг у «Забікс»?
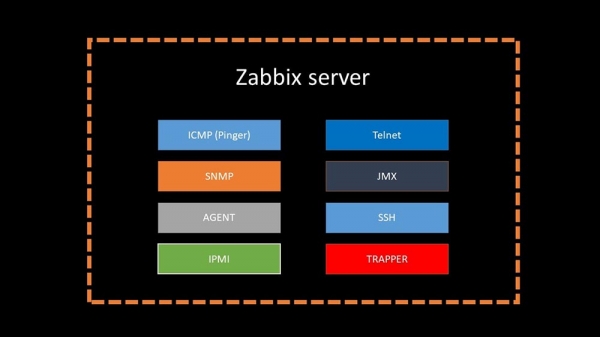
МЧ: - Калі сцісла, то існуе 20 тыпаў метрык і дзясятак спосабаў іх атрымання.

Варта заўважыць, што ў арыгінальным Забіксе гэты спосаб (Trapper) самы хуткі.
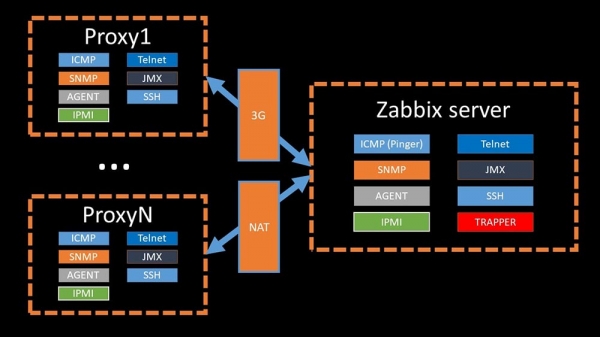
Існуюць проксі-серверы для размеркавання нагрузкі:
Проксі могуць выконваць тыя ж функцыі збору, што і «Забікс»-сервер, атрымліваючы з яго заданні і адсылаючы сабраныя метрыкі якраз праз Трапер-інтэрфейс.
ММ: - З архітэктурай усё зразумела. Трэба глядзець зыходнікі...
Пару дзён праз
Сказ аб тым, як nmap fping перамог
ММ: - Здаецца, я нешта накапаў.
МЧ: - Расказвай!
ММ: - Я выявіў, што пры праверках даступнасці «Забікс» робіць праверку максімум да 128 хастоў адначасова. Я паспрабаваў павялічыць гэтую лічбу да 500 і прыбраў міжпакетны інтэрвал у іх пінгу (ping) - гэта павялічыла прадукцыйнасць разы ў два. Але хацелася б вялікіх лічбаў.
МЧ: - У сваёй практыцы мне часам даводзіцца правяраць даступнасць тысяч хастоў, і нічога хутчэй nmap я для гэтага не сустракаў. Я ўпэўнены, што гэта найхутчэйшы спосаб. Давай яго паспрабуем! Трэба значна павялічыць колькасць хастоў за адну ітэрацыю.
ММ: - Правяраць больш за пяцьсот? 600?
МЧ: - Як мінімум пару тысяч.
ММ: - Окей. Самае галоўнае, што хацеў сказаць: я знайшоў, што большасць поллінга ў «Забіксе» зроблена сінхронна. Мы абавязкова павінныя яго перарабіць на асінхронны рэжым. Тады мы зможам кардынальна павялічыць колькасць метрык, якія збіраюцца палерамі, асабліва калі мы павялічым колькасць метрык за адну ітэрацыю.
МЧ: - Здароў! І калі?
ММ: - Як звычайна, учора.
МЧ: – Мы параўналі абедзве версіі fping і nmap:
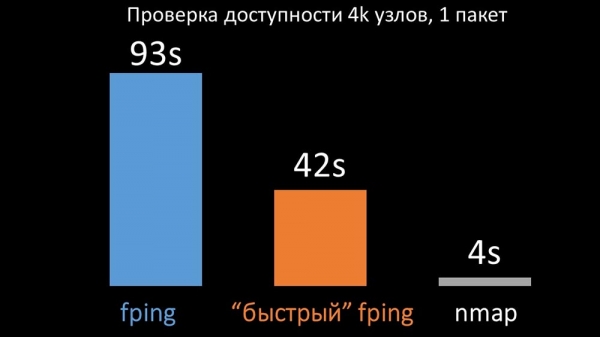
На вялікай колькасці хастоў nmap быў чакана да пяці разоў больш эфектыўна. Так як nmap правярае толькі факт даступнасці і час водгуку, падлік страт мы перанеслі ў трыгеры і значна скарацілі інтэрвалы праверкі даступнасці. Аптымальнай колькасцю хастоў для nmap мы знайшлі ў раёне 4 тысяч за адну ітэрацыю. Nmap дазволіў нам у тры разы знізіць выдаткі ЦПУ на праверкі даступнасці і скараціць інтэрвал з 120 секунд да 10.
Аптымізацыя поллінга
ММ: - Затым мы заняліся палерамі. У асноўным нас цікавіў з'ем SNMP і агенты. У «Забіксе» полінг зроблены сінхронна і прыняты спецыяльныя меры для таго, каб павялічваць эфектыўнасць сістэмы. У сінхронным рэжыме недаступнасць хастоў выклікае значную дэградацыю поллінга. Існуе цэлая сістэма станаў, існуюць спецыяльныя працэсы - так званыя unreachable-полеры, якія працуюць толькі з недаступнымі хастамі:

Гэта каментар, які дэманструе матрыцу станаў, усю складанасць сістэмы пераходаў, якія патрабуюцца для таго, каб сістэме заставацца эфектыўнай. Акрамя таго, сам сінхронны полінг дастаткова павольны:
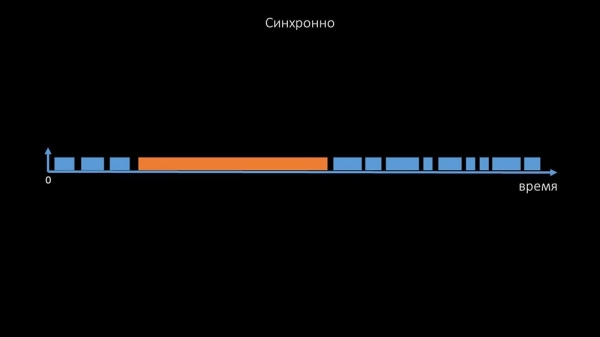
Менавіта таму тысячы патокаў палераў на дзесятцы проксі не маглі сабраць для нас патрэбнай колькасці звестак. Асінхронная рэалізацыя вырашыла не толькі праблемы з колькасцю патокаў, але і значна спрасціла сістэму станаў недаступных хастоў, таму што пры любой колькасці, якія правяраюцца ў адной ітэрацыі поллінга, максімальны час чакання складала 1 тайм-аўт:
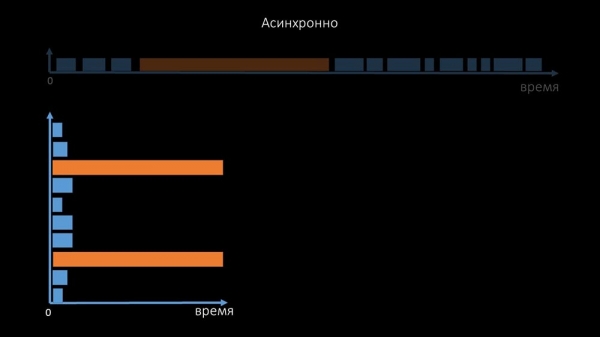
Дадаткова мы мадыфікавалі, дапрацавалі сістэму поллінга для SNMP-запытаў. Справа ў тым, што большасць не могуць адказваць на некалькі SNMP-запытаў адначасова. Таму мы зрабілі гібрыдны рэжым, калі SNMP-поллінг аднаго і таго ж хаста робіць асінхронна:
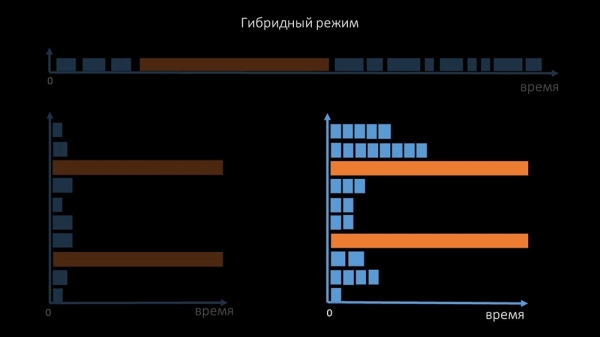
Гэта робіцца для ўсяго пачка хастоў. Такі рэжым у выніку не павольней, чым цалкам асінхронны, бо апытанне паўтары сотняў SNMP-значэнняў усё роўна значна хутчэй, чым 1 тайм-аўт.
Нашы эксперыменты паказалі, што аптымальная колькасць запытаў у адной ітэрацыі - прыкладна 8 тысяч пры SNMP-поллінгу. Сумарна пераход на асінхронны рэжым дазволіў паскорыць прадукцыйнасць поллінга ў 200 разоў, у некалькі сотняў разоў.
МЧ: - Атрыманыя аптымізацыі поллінга паказалі, што мы не толькі можам пазбавіцца ад усіх проксі, але і скараціць інтэрвалы па многіх праверках, а проксі стануць не патрэбны як спосаб падзелу нагрузкі.
Каля трох месяцаў таму
Змяні архітэктуру - павяліч нагрузку!
ММ: - Ну што, Макс, пара ў прадуктыў? Мне патрэбен магутны сервер і добры інжынер.
МЧ: - Добра, заплануем. Даўно пара скрануцца з мёртвай кропкі ў 5 тысяч метрык у секунду.
Раніца пасля апгрэйду
МЧ: – Міша, мы абнавіліся, але пад раніцу адкаціліся назад… Адгадай, якой хуткасці ўдалося дасягнуць?
ММ: - Тысяч 20 максімум.
МЧ: - Ага, 25! Нажаль, мы тамака жа, з чаго пачалі.
ММ: - А што так? Дыягностыку знялі якую-небудзь?
МЧ: - Так, вядома! Вось, напрыклад, цікавы top:
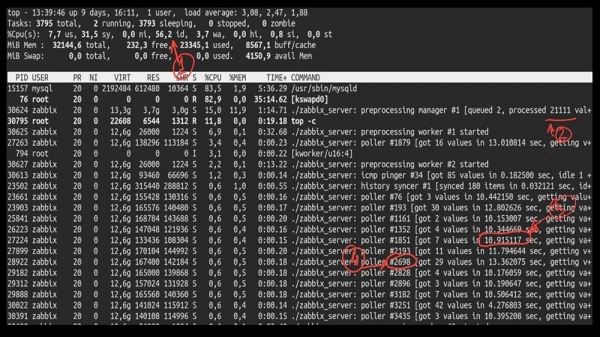
ММ: - Давай паглядзім. Я бачу, што мы спрабавалі вялікую колькасць патокаў поллінга:
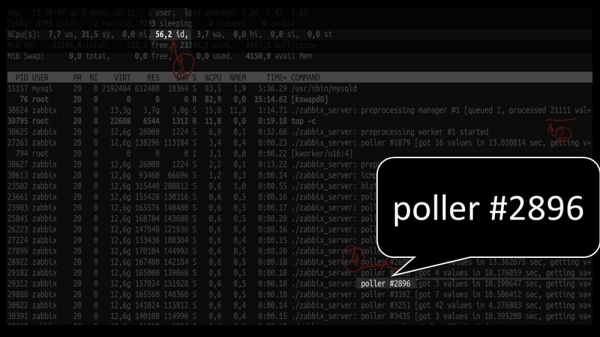
Але пры гэтым не змаглі ўтылізаваць сістэму нават напалову:
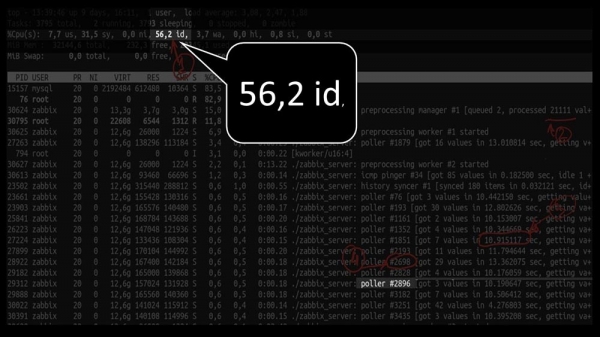
А агульная прадукцыйнасць дастаткова маленькая, каля 4 тысяч метрык у секунду:
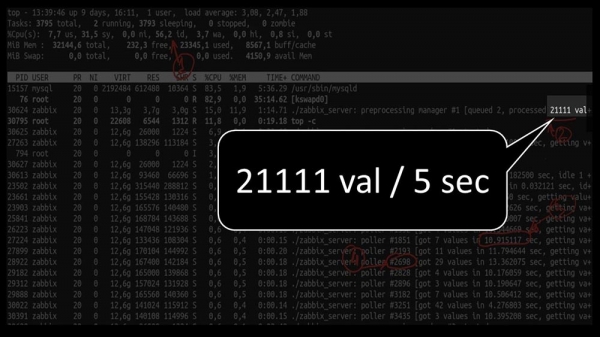
Ёсць што-небудзь яшчэ?
МЧ: – Так, strace аднаго з палераў:
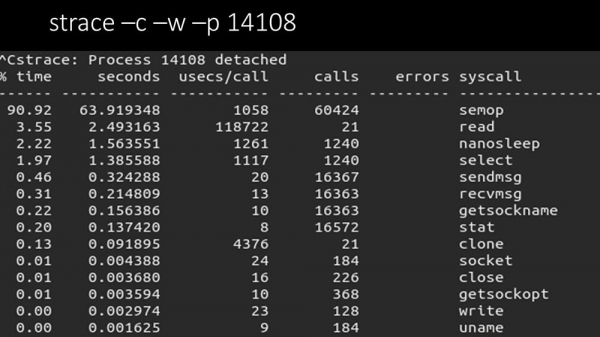
ММ: - Тут выразна відаць, што працэс поллінга чакае "семафораў". Гэта блакіроўкі:
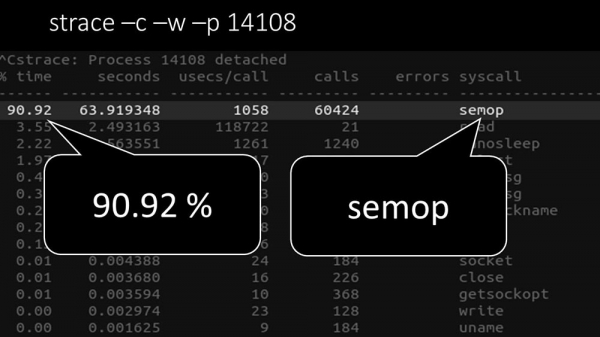
МЧ: - Незразумела.
ММ: - Глядзі, гэта падобна на сітуацыю, калі куча патокаў спрабуе працаваць з рэсурсаў, з якім адначасова можна працаваць толькі аднаму. Тады ўсё, што яны могуць рабіць - падзяляць гэты рэсурс па часе:

І сумарная прадукцыйнасць працы з такім рэсурсам абмяжоўваецца хуткасцю аднаго ядра:
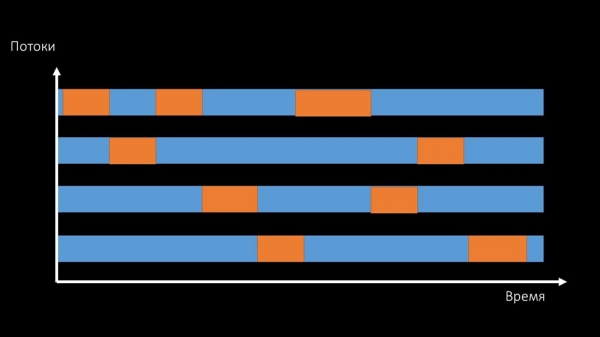
Вырашыць такую праблему можна двума спосабамі.
Апгрэдзіць жалеза машыны, пераходзіць на хутчэйшыя ядры:
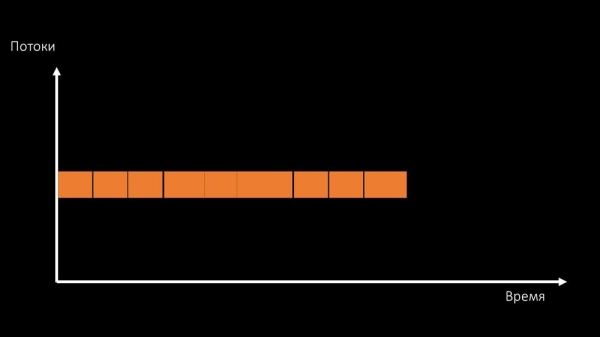
Або мяняць архітэктуру і паралельна - нагрузку:
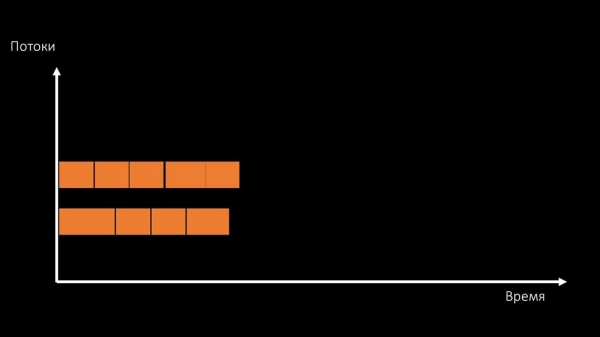
МЧ: - Дарэчы кажучы, на тэставай машыне пусцім меншую колькасць ядраў, чым на баявой, але затое яны разы ў 1,5 хутчэй па частаце на ядро!
ММ: - Ясна? Трэба глядзець код сэрвера.
Шлях дадзеных у сэрвэры Zabbix
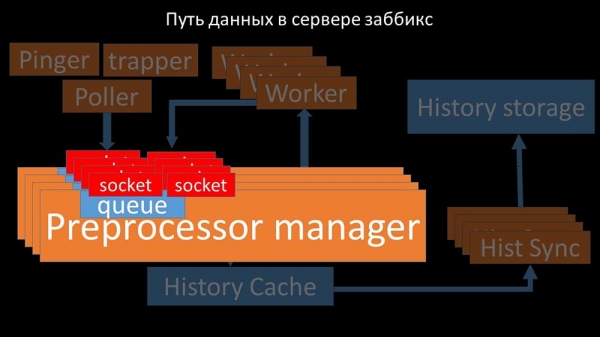
МЧ: - Каб разабрацца, мы сталі аналізаваць, як дадзеныя перадаюцца ўнутры "Забікс"-сервера:
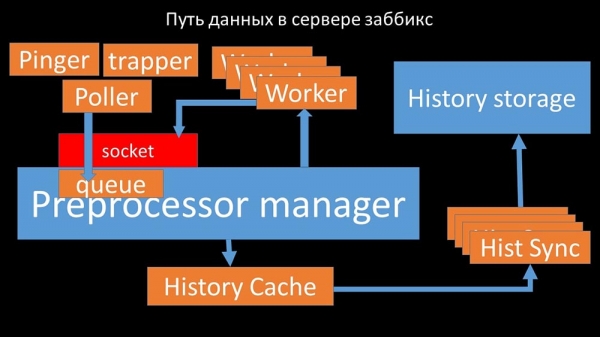
Класная карцінка, праўда? Давайце пройдземся па ёй крок за крокам, каб больш-менш растлумачыць. Ёсць плыні і сэрвісы, адказныя за збор дадзеных:
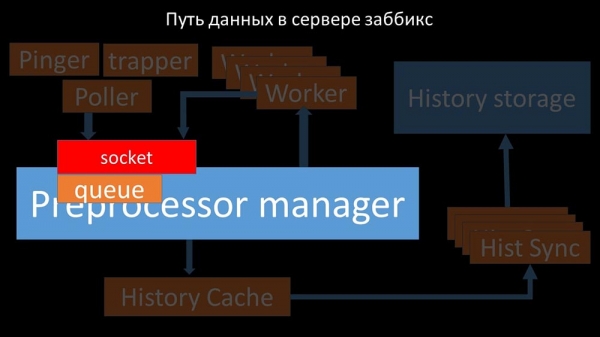
Сабраныя метрыкі яны перадаюць праз сокет у Preprocessor manager, дзе захоўваюцца ў чаргу:
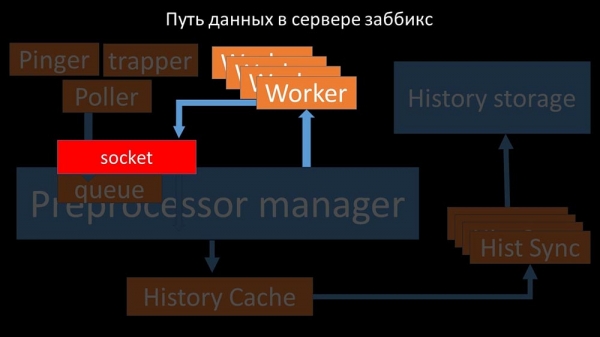
Препроцессор-мэнэджар» перадае дадзеныя сваім воркерам, якія выконваюць інструкцыі перадапрацоўкі і вяртаюць іх зваротна праз той жа сокет:
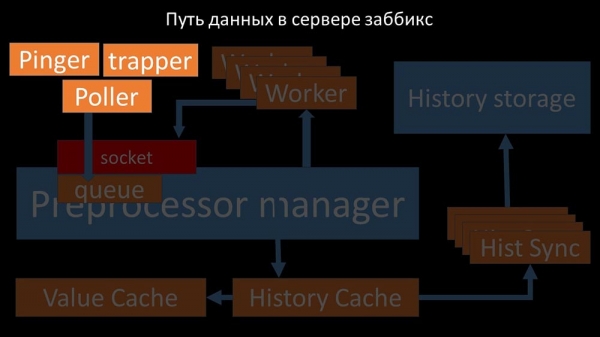
Пасля гэтага прэпрацэсар-мэнэджар захоўвае іх у кэшы гісторыі:
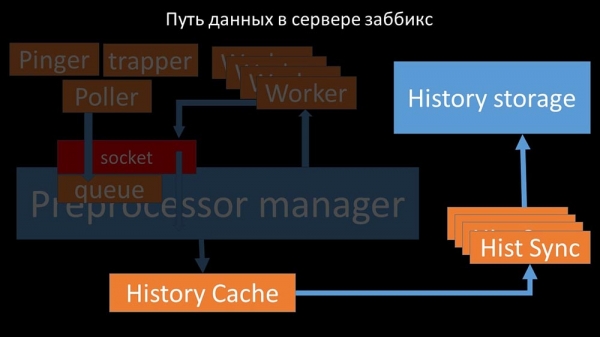
Адтуль іх забіраюць хісторы-сінкеры, якія выконваюць дастаткова шмат функцый: напрыклад, вылічэнне трыгераў, запаўненне кэша значэнняў і, самае галоўнае, захаванне метрык у сховішча гісторыі. Увогуле, працэс складаны і вельмі заблытаны.
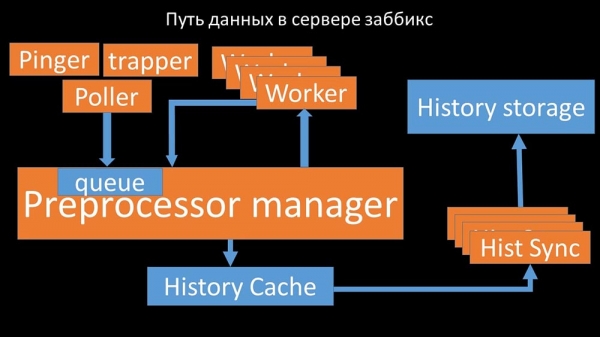
ММ: - Першае, што мы ўбачылі - гэта тое, што большасць патокаў канкуруе за так званы "канфігурацыйны кэш" (вобласць памяці, дзе захоўваюцца ўсе канфігурацыі сервера). Асабліва шмат блакіровак робяць струмені, адказныя за здыманне дадзеных:
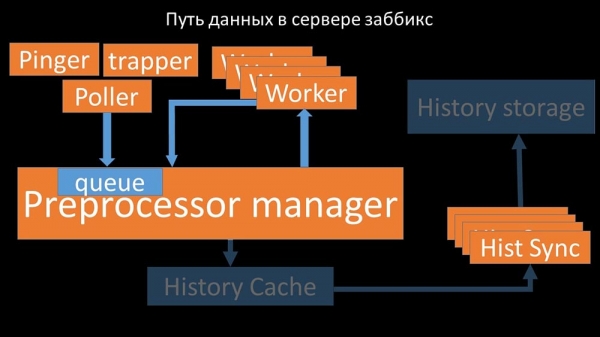
… бо ў канфігурацыі захоўваюцца не толькі метрыкі з іх параметрамі, але і чэргі, з якіх палеры бяруць інфармацыю аб тым, што ім рабіць далей. Калі палераў шмат, і адзін блакуе канфігурацыю, астатнія чакаюць запытаў:
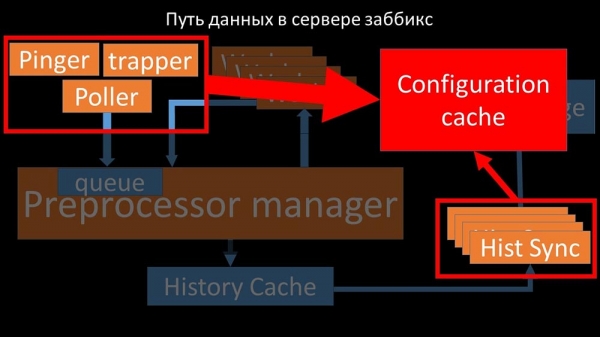
Полеры не павінны канфліктаваць
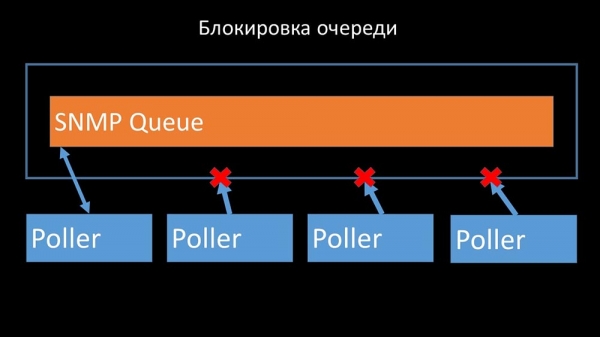
Таму першае, што мы зрабілі - падзялілі чаргу на 4 часткі і дазволілі палерам у бяспечных умовах блакаваць гэтыя чэргі, гэтыя часткі адначасова:
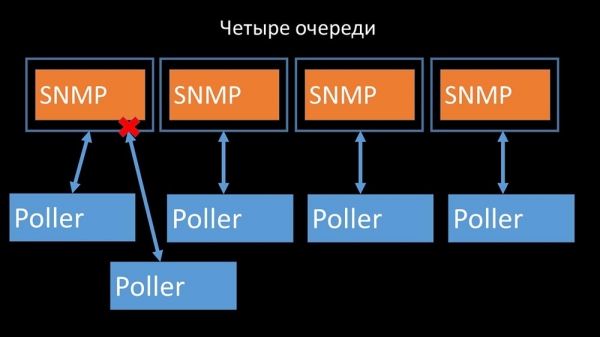
Гэта прыбрала канкурэнцыю за канфігурацыйны кэш, і хуткасць працы палераў значна вырасла. Але затым мы сутыкнуліся з тым, што прэпрацэсар-мэнэджар пачаў збіраць чаргу заданняў:
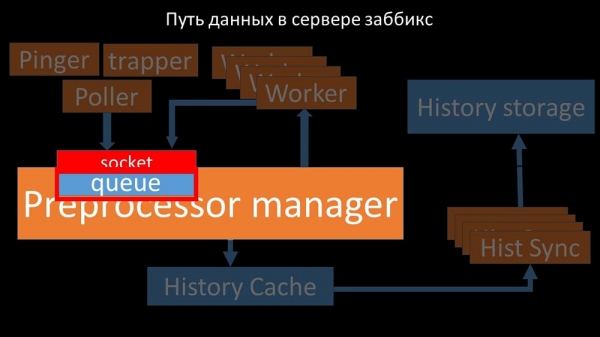
Preprocessor manager павінен умець расставіць прыярытэты
Гэта адбывалася ў выпадках, калі яму не хапала прадукцыйнасці. Тады ўсё, што ён мог рабіць - збіраць запыты ад працэсаў збору дадзеных і складаць іх буфер датуль, пакуль ён не з'ядаў усю памяць і падаў:
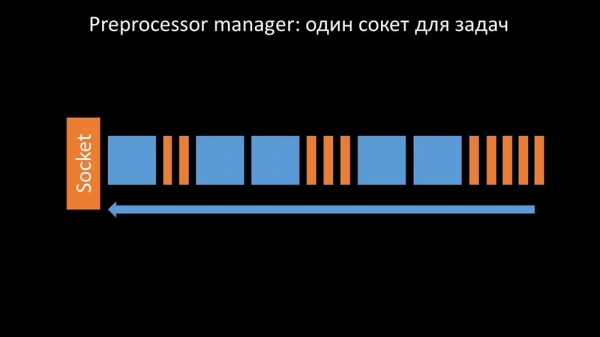
Каб вырашыць гэтую праблему, мы дадалі другі сокет, які быў выдзелены спецыяльна для воркераў:
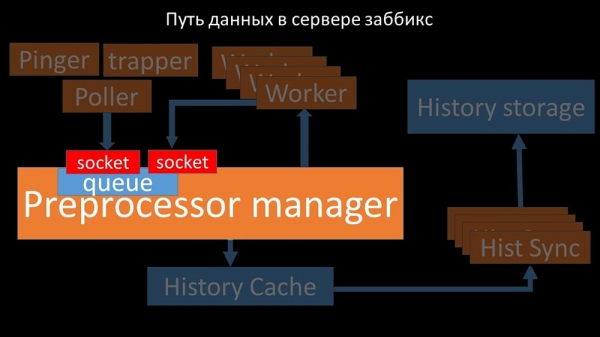
Такім чынам, препроцессор-мэнэджар атрымаў магчымасць прыарытызаваць сваю працу і ў выпадку разрастання буфера задача тармазіць з'ем, даючы воркерам магчымасць гэты буфер забраць:
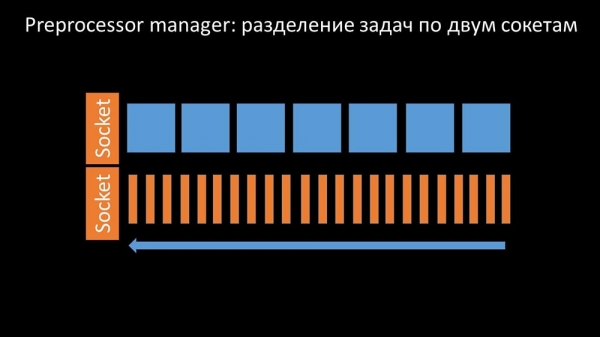
Затым мы выявілі, што адной з прычын тармажэння былі самі воркеры, паколькі яны канкуравалі за зусім не важны для іх працы рэсурс. Гэтую праблему мы аформілі bug-fix'ам, і ў новых версіях «Забікса» яна ўжо вырашана:
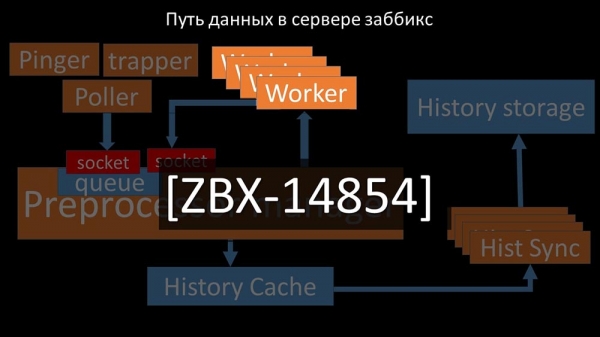
Павялічваем колькасць сокетаў - атрымліваем вынік
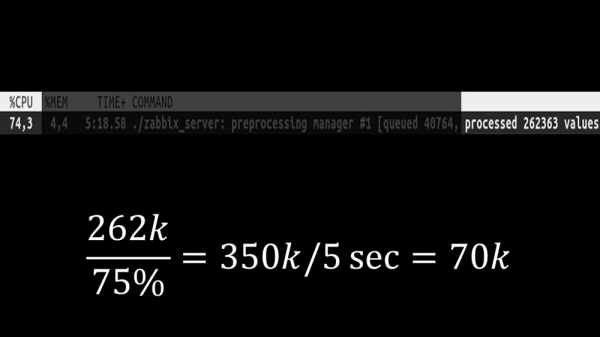
Далей сам прэпрацэсар-мэнэджар стаў вузкім звяном, паколькі гэта - адзін струмень. Ён упіраўся ў хуткасць ядра, даючы максімальную хуткасць прыкладна ў 70 тысяч метрык у секунду:
Таму мы зрабілі чатыры, з чатырма наборамі сокетаў, воркераў:
І гэта дазволіла павялічыць хуткасць прыкладна да 130 тысяч метрык.
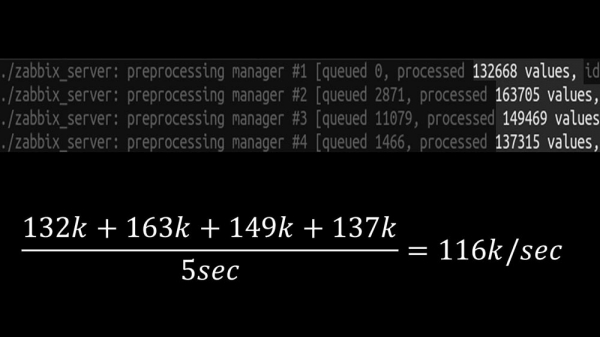
Нелінейнасць росту тлумачыцца тым, што з'явілася канкурэнцыя за кэш гісторыі. За яго канкуравалі 4 прэпрацэсар-мэнэджары і хісторы-сінкеры. Да гэтага моманту мы атрымлівалі на тэставай машыне прыкладна 130 тысяч метрык у секунду, утылізуючы яе прыкладна на 95% па працэсары:
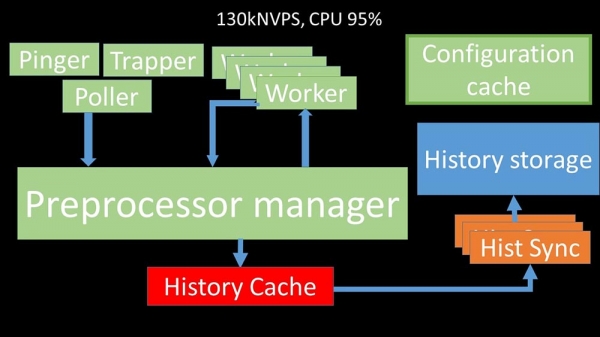
Каля 2,5 месяцаў таму
Адмова ад snmp-community павялічыў NVPs у паўтара разы
ММ: - Макс, мне патрэбна новая тэставая машына! У бягучую мы больш не залазіць.
МЧ: – А што ёсць зараз?
ММ: – Цяпер – 130k NVPs і працэсар «у палку».
МЧ: - Ух ты! Стромка! Пачакай, у мяне два пытанні. Па маіх падліках, наша запатрабаванне - у раёне 15-20 тысяч метрык у секунду. Навошта нам болей?
ММ: - Хочацца дарабіць справу да канца.
МЧ: – Але…
ММ: - Але для бізнесу бескарысна.
МЧ: - Зразумела. І другое пытанне: тое, што ёсць зараз, мы зможам падтрымліваць самастойна, без дапамогі распрацоўшчыка?
ММ: - Я не думаю. Змена працы з канфігурацыйным кэшам - гэта праблема. Яна датычыцца змяненняў у большасці патокаў і дастаткова складана ў падтрымцы. Хутчэй за ўсё, падтрымліваць яе будзе вельмі цяжка.
МЧ: - Тады трэба нейкую альтэрнатыву.
ММ: - Ёсць такі варыянт. Мы можам перайсці на хуткія ядры, пры гэтым адмовіўшыся ад новай сістэмы блакавання. Мы ўсё роўна атрымаем прадукцыйнасць 60-80 тысяч метрык. Пры гэтым мы зможам пакінуць увесь астатні код. "Клікхаус", асінхронны полінг будуць працаваць. І гэта будзе лёгка падтрымліваць.
МЧ: - Выдатна! Прапаную на гэтым спыніцца.
Пасля аптымізацыі сервернай часткі мы нарэшце змаглі запусціць новы код у прадуктыў. Мы адмовіліся ад часткі змен у карысць пераходу на машыну з хуткімі ядрамі і мінімізацыі колькасці змен у кодзе. Мы таксама спрасцілі канфігурацыю і па магчымасці адмовіліся ад макрасаў у элементах дадзеных, паколькі яны з'яўляюцца крыніцай дадатковых блакіровак.

Напрыклад, адмова ад часта сустракаемага ў дакументацыі і прыкладах макраса snmp-community у нашым выпадку дазволіў дадаткова паскорыць NVPs прыкладна ў 1,5 разы.
Пасля двух дзён у прадукты
Прыбіраем усплывальныя вокны гісторыі інцыдэнтаў
МЧ: - Міша, мы два дні карыстаемся сістэмай, і ўсё працуе. Але толькі тады, калі ўсё працуе! У нас былі планавыя працы з пераносам досыць вялікага сегмента сеткі, і мы зноў рукамі правяралі, што паднялося, што - не.
ММ: - Не можа быць! Мы 10 разоў усё праверылі. Сервер апрацоўвае нават поўную недаступнасць сеткі імгненна.
МЧ: – Ды я ўсё разумею: сервер, база, top, austat, логі – усё хутка… Але мы глядзім вэб-інтэрфейс, а там – працэсар «у палку» на серверы і вось гэта:

ММ: - Зразумела. Давай глядзець вэб. Мы выявілі, што ў сітуацыі, калі была вялікая колькасць актыўных інцыдэнтаў, большасць аператыўных віджэтаў пачынала працаваць вельмі марудна:
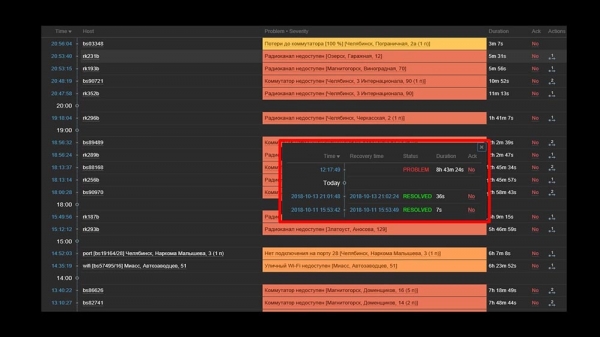
Прычынай гэтаму была генерацыя усплываючых вокнаў з гісторыяй інцыдэнтаў, якія генеруюцца для кожнага элемента ў спісе. Таму мы адмовіліся ад генерацыі гэтых вокнаў (закаментавалі 5 радкоў у кодзе), і гэта вырашыла нашыя праблемы.
Час загрузкі віджэтаў нават пры поўнай недаступнасці скараціўся з некалькіх хвілін да дапушчальных для нас 10-15 секунд, а гісторыю па-ранейшаму можна глядзець пстрычкай па часе:
Пасля працы. 2 месяцы таму
МЧ: - Міша, сыходзіш? Ёсць размова.
ММ: - Не збіраўся. Ізноў нешта з «Забіксам»?
МЧ: - Ды не, паслабся! Я проста хацеў сказаць: усё працуе, дзякуй! З мяне піва.
Zabbix эфектыўны
«Забікс» – дастаткова ўніверсальная і багатая сістэма і функцыя. Яго цалкам можна выкарыстоўваць для невялікіх усталёвак «са скрынкі», але з ростам запатрабаванняў яго даводзіцца аптымізаваць. Для захоўвання вялікага архіва метрык выкарыстоўвайце прыдатнае сховішча:
- можна скарыстацца ўбудаванымі сродкамі ў выглядзе інтэграцыі з "Эластыксёрч" або выгрузкай гісторыі ў тэкставыя файлы (даступна з чацвёртай версіі);
- можна скарыстацца нашым досведам і інтэграцыяй з «Клікхаус».
Для кардынальнага павелічэння хуткасці збору метрык, зьбірайце іх асінхроннымі метадамі і перадавайце праз трапер-інтэрфейс у «Забікс»-сервер; альбо можна скарыстацца патчам для асінхроннасці палераў самога «Забікса».
«Забікс» напісаны на Сі і дастаткова эфектыўны. Рашэнне ж некалькі вузкіх архітэктурных месцаў дазваляе дадаткова павялічыць яго прадукцыйнасць і, па нашым досведзе, атрымліваць больш 100 тысяч метрык на аднапрацэсарнай машыне.

Той самы патч Zabbix
ММ: - Я хачу дадаць пару момантаў. Увесь бягучы даклад, усе тэсты, лічбы прыведзены для той канфігурацыі, якая выкарыстоўваецца ў нас. З яе мы зараз здымаем прыкладна 20 тысяч метрык у секунду. Калі вы спрабуеце зразумець, ці будзе гэта працаваць у вас - можаце параўнаць. Тое, пра што сёння распавялі, выкладзена на GitHub у выглядзе патча:

Патч уключае:
- поўную інтэграцыю з «Клікхаўсам» (як «Забікс»-сервера, так і франтэнда);
- рашэнне праблем з прэпрацэсар-мэнэджарам;
- асінхронны полінг.
Патч сумяшчальны з усёй версіяй 4, у тым ліку з lts. Хутчэй за ўсё, з мінімальнымі зменамі ён будзе працаваць на версіі 3.4.
Дзякуй за ўвагу.
пытанні
Пытанне з аўдыторыі (далей - А): - Добры дзень! Скажыце, калі ласка, ці ёсць у вас планы інтэнсіўнага ўзаемадзеяння з камандай Zabbix ці ў іх з вамі, каб гэта быў не патч, а нармальнымі паводзінамі «Забікса»?
ММ: - Так, частка змен мы абавязкова закамміцім. Нешта будзе, нешта застанецца ў патчы.
А: - Дзякуй вялікі за выдатны даклад! Падкажыце, калі ласка, пасля прымянення патча падтрымка з боку "Забікса" застанецца і як далей абнаўляцца на больш высокія версіі? Ці будзе магчымасць абнавіць "Забікс" пасля вашага патча да 4.2, 5.0?
ММ: - Аб падтрымцы я не магу сказаць. Калі б я быў тэхпадтрымкай «Забікса», то, відаць, сказаў бы не, таму што гэта чужы код. Што да кодавай базы 4.2, то нашая пазіцыя такая: "Мы будзем ісці з часам, і самі будзем абнаўляцца на наступнай версіі". Таму нейкі час мы будзем выкладваць патч на абноўленыя версіі. Я ўжо сказаў у дакладзе: колькасць зменаў з версіямі пакуль дастаткова невялікая. Думаю, пераход з 3.4 на 4 у нас заняло, здаецца, хвілін 15. Там нешта памянялася, але не надта важнае.
А: - Гэта значыць, вы плануеце падтрымліваць свой патч і можна смела яго ставіць на прадакшн, у далейшым атрымліваючы абнаўлення нейкім чынам?
ММ: - Мы катэгарычна рэкамендуем. Нам гэта вырашае шмат праблем.
МЧ: – Яшчэ раз хацелася б завастрыць увагу, што змены, якія не датычацца архітэктуры і не датычацца блакіровак, чэргаў – яны модульныя, яны ў асобных модулях. Нават самастойна пры малаважных зменах іх можна падтрымліваць дастаткова лёгка.
ММ: – Калі цікавыя дэталі, то “Клікхаўс” выкарыстоўвае так званую бібліятэку гісторыі. Яна адвязана - гэта копія падтрымкі «Эластыкса», гэта значыць яна канфігурацыйна змяняная. Поллінг змяняе толькі палеры. Мы лічым, што гэта будзе працаваць доўга.
А: - Дзякуй вялікі. А падкажыце, ці ёсць нейкая дакументацыя ўнесеных змен?

ММ: - Дакументацыя - гэта патч. Відавочна, з увядзеннем "Клікхауса", з увядзеннем новых тыпаў палераў узнікаюць новыя канфігурацыйныя опцыі. Па спасылцы з апошняга слайда ёсць кароткае апісанне, як гэтым карыстацца.
Аб замене fping на nmap
А: – Як вы ў выніку гэта рэалізавалі?Можаце на канкрэтных прыкладах: гэта ў вас страпперы і знешні скрыпт?
ММ: - Стромка. Вельмі правільнае пытанне! Іста такая. Мы мадыфікавалі бібліятэку (ICMP-пінг, складнік «Забікса») для ICMP-праверак, у якіх пазначана колькасць пакетаў – адзінка (1), а код спрабуе выкарыстоўваць nmap. То бок, гэта ўнутраная праца «Забікса», стала ўнутранай працай Пінгера. Адпаведна, ніякай сінхранізацыі ці выкарыстанні траппера не патрабуецца. Гэта было зроблена свядома, каб пакінуць сістэму цэласнай і не займацца сінхранізацыяй дзвюх сістэм баз: што правяраць, заліваць праз полер, а не ці зламалася ў нас заліванне?.. Гэта значна прасцей.
А: - Для проксі таксама працуе?
ММ: - Так, але мы не правяралі. Код поллінга і ў «Забіксе», і ў серверы адзіны. Павінна працаваць. Яшчэ раз акцэнтую: прадукцыйнасць сістэмы такая, што нам проксі не патрэбен.
МЧ: – Правільны адказ на пытанне такі: "А навошта вам пры такой сістэме проксі?" Толькі з-за NAT'а ці маніторыць праз павольны канал нейкі…
А: - А вы выкарыстоўваеце «Забікс» як алертар, калі я правільна зразумеў. Ці графікі (дзе архіўны пласт) у вас з'ехалі ў іншую сістэму, тыпу Grafana?
ММ: - Я яшчэ раз падкрэслю: мы зрабілі поўную інтэграцыю. Мы выліваем history у «Клікхаўс», але пры гэтым змянілі php-франтэнд. Php-франтэнд ходзіць у «Клікхаўс» і ўсе графікі робіць адтуль. Пры гэтым, калі сапраўды, у нас ёсць частка, якая будуе з таго ж «Клікхауса», з тых жа дадзеных «Забікса» дадзеныя ў іншых сістэмах графічнага адлюстравання.
МЧ: – У «Графане» у тым ліку.
Як прымалася рашэнне і аб выдзяленні рэсурсаў?
А: - Падзяліцеся трохі ўнутранай кухняй. Як прымалася рашэнне аб тым, што трэба вылучыць рэсурсы на сур'ёзную перапрацоўку прадукта? Гэта, увогуле, пэўныя рызыкі. І скажыце, калі ласка, у кантэксце таго, што вы збіраецеся падтрымліваць новыя версіі: як апраўдваецца гэтае рашэнне з пункта гледжання кіравання?
ММ: – Мабыць, драму гісторыі мы не вельмі добрае распавялі. Мы апынуліся ў сітуацыі, калі нешта трэба было рабіць, і пайшлі па сутнасці дзвюма паралельнымі камандамі:
- Адна займалася запускам сістэмы маніторынгу на новых метадах: маніторынг як сэрвіс, стандартны набор апенсорсных рашэнняў, якія мы камбінуем і потым спрабуем змяніць бізнес-працэс для таго, каб працаваць з новай сістэмай маніторынгу.
- Паралельна ў нас быў энтузіяст-праграміст, які гэтым займаўся (пра сябе). Так здарылася, што ён перамог.
А: - І які памер каманды?
МЧ: - Яна перад вамі.
А: - Гэта значыць, як заўсёды патрэбен пасіянарый?
ММ: - Я не ведаю, што такое пасіянарый.
А: - У дадзеным выпадку, мабыць, вы. Дзякуй вялікі, вы - стромкія.
ММ: - Дзякуй.
Аб патчах для Zabbix
А: - Для сістэмы, якая выкарыстоўвае проксі (напрыклад, у нейкіх размеркаваных сістэмах), ці магчыма ваша рашэнне адаптаваць і прапатчыць, скажам, полеры, проксі і часткова прэпрацэсар самога «Забікса»; і іх узаемадзеянне? Ці магчыма існуючыя напрацоўкі аптымізаваць пад сістэму з некалькімі проксі?
ММ: - Я ведаю, што «Забікс»-сервер збіраецца з дапамогай проксі (кампілюецца і атрымліваецца код). Мы не правяралі гэта ў прадукты. Я не ўпэўнены ў гэтым, але, па-мойму, прэпрацэсар-мэнэджар не выкарыстоўваецца ў проксі. Задача проксі - гэта ўзяць набор метрык з «Забікса», спаліць іх (ён яшчэ запісвае канфігурацыю, лакальную базу) і аддаць зваротна «Забікс»-серверу. Рабіць прэпрацэсінгу будзе потым сам сервер, калі атрымае.
Цікавасць да проксі зразумелая. Мы праверым гэта. Гэта цікавая тэма.
А: - Ідэя такая была: калі можна патчыць полеры, іх можна патчыць на проксі і патчыць узаемадзеянне з серверам, а прэпрацэсар пад гэтыя мэты адаптаваць толькі на серверы.
ММ: - Думаю, усё нават прасцей. Вы бераце код, накладваеце патч, потым канфігуруеце так, як вам трэба - збіраеце проксі-серверы (напрыклад, з ODBC) і патченный код разносіце па сістэмах. Дзе трэба - збіраеце проксі, дзе трэба - сервер.
А: - Дадаткова патчыць перадачу проксі да сервера не прыйдзецца, хутчэй за ўсё?
МЧ: - Не, яна стандартная.
ММ: - На самай справе не гучала адна з ідэй. Мы заўсёды выконвалі выканаць баланс паміж выбухам ідэй і колькасцю змен, лёгкасцю падтрымкі.

Крыху рэкламы 🙂
Дзякуй, што застаяцеся з намі. Вам падабаюцца нашыя артыкулы? Жадаеце бачыць больш цікавых матэрыялаў? Падтрымайце нас, аформіўшы замову ці парэкамендаваўшы знаёмым, , унікальны аналаг entry-level сервераў, які быў прыдуманы намі для Вас: (даступныя варыянты з RAID1 і RAID10, да 24 ядраў і да 40GB DDR4).
Dell R730xd у 2 разы танней у дата-цэнтры Equinix Tier IV у Амстэрдаме? Толькі ў нас у Нідэрландах! Dell R420 – 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB – ад $99! Чытайце аб тым
Крыніца: habr.com
