

Я ведаю шматлікіх Data Scientist-ов – ды і мабыць сам да іх стаўлюся – якія працуюць на машынах з GPU, лакальных ці віртуальных, размешчаных у воблаку, альбо праз Jupyter Notebook, альбо праз нейкае асяроддзе распрацоўкі Python. Працуючы на працягу 2 гадоў экспертам-распрацоўшчыкам па AI/ML я рабіў менавіта так, пры гэтым падрыхтоўваў дадзеныя на звычайным серверы або працоўнай станцыі, а запускаў навучанне на віртуалцы з GPU у Azure.
Вядома, мы ўсё чулі пра - адмысловую хмарную платформу для машыннага навучання. Аднак пасля першага ж погляду на , ствараецца ўражанне, што Azure ML створыць вам больш праблем, чым вырашыць. Напрыклад, у згаданым вышэй навучальным прыкладзе навучанне на Azure ML запускаецца з Jupyter Notebook, пры гэтым сам навучальны скрыпт прапануецца ствараць і рэдагаваць як тэкставы файл у адной з вочак – пры гэтым не выкарыстоўваючы аўтададатак, падсвятленне сінтаксісу і іншыя перавагі звычайнага асяроддзя распрацоўкі. Па гэтай прычыне мы доўгі час сур'ёзна не выкарыстоўвалі Azure ML у сваёй працы.
Аднак нядаўна я выявіў спосаб, як пачаць эфектыўна выкарыстоўваць Azure ML у сваёй працы! Цікавыя падрабязнасці?

Асноўны сакрэт - гэта . Яно дазваляе вам распрацоўваць навучальныя скрыпты прама ў VS Code, выкарыстаючы ўсе перавагі асяроддзя - пры гэтым вы можаце нават запускаць скрыпт лакальна, а затым проста ўзяць і адправіць яго на навучанне ў кластары Azure ML некалькімі пстрычкамі мышы. Зручна, ці не праўда?
Пры гэтым вы атрымліваеце наступныя перавагі ад выкарыстання Azure ML:
- Можна працаваць большую частку часу лакальна на сваёй машыне ў зручным IDE, і выкарыстоўваць GPU толькі для навучання мадэлі. Пры гэтым пул навучалых рэсурсаў можа аўтаматычна падладжвацца пад патрабаваную нагрузку, і ўсталяваўшы мінімальную колькасць вузлоў у 0 вы зможаце аўтаматычна запускаць віртуалку "па патрабаванні" пры наяўнасці навучалых заданняў.
- Вы можаце захоўваць усе вынікі навучання ў адным месцы, уключаючы дасягнутыя метрыкі і атрыманыя мадэлі - няма неабходнасці самому прыдумляць нейкую сістэму або парадак для захоўвання ўсіх вынікаў.
- Пры гэтым над адным праектам могуць працаваць некалькі чалавек - Яны могуць выкарыстоўваць адзін і той жа вылічальны кластар, усе эксперыменты будуць пры гэтым выбудоўвацца ў чаргу, а таксама яны могуць бачыць вынікі эксперыментаў адзін аднаго. Адным з такіх сцэнарыяў з'яўляецца выкарыстанне Azure ML у выкладанні Deep Learning, Калі замест таго, каб даваць кожнаму студэнту віртуальную машыну з GPU, вы можаце стварыць адзін кластар, які будзе выкарыстоўвацца ўсімі цэнтралізавана. Акрамя таго, агульная табліца вынікаў з дакладнасцю мадэлі можа служыць добрым элементам спаборніцтва.
- З дапамогай Azure ML можна лёгка праводзіць серыі эксперыментаў, напрыклад, для аптымізацыі гіперпараметраў - гэта можна рабіць некалькімі радкамі кода, няма неабходнасці праводзіць серыі эксперыментаў уручную.
Спадзяюся, я пераканаў вас паспрабаваць Azure ML! Вось як можна пачаць:
- Пераканайцеся, што ў вас ўстаноўлена , а таксама пашырэння и
- Клануйце рэпазітар — ён утрымлівае некаторы дэманстрацыйны код для трэніроўкі мадэлі распазнання рукапісных лічбаў на датасеце MNIST.
- Адкрыйце кланаваны рэпазітар у Visual Studio Code.
- Чытайце далей!
Azure ML Workspace і Azure ML Portal
Azure ML арганізаваны вакол канцэпцыі працоўнай вобласці - Workspace. У працоўнай вобласці могуць захоўвацца дадзеныя, у яе адпраўляюць эксперыменты для навучання, тамака жа захоўваюцца вынікі навучання - атрыманыя метрыкі і мадэлі. Паглядзець, што знаходзіцца ўнутры працоўнай вобласці, можна праз - і адтуль жа можна здзяйсняць мноства аперацый, пачынальна ад загрузкі дадзеных і сканчаючы маніторынгам эксперыментаў і разгортваннем мадэляў.
Стварыць працоўную вобласць можна праз вэб-інтэрфейс (гл. ), або з выкарыстаннем каманднага радка Azure CLI ():
az extension add -n azure-cli-ml
az group create -n myazml -l northeurope
az ml workspace create -w myworkspace -g myazmlЗ працоўнай вобласцю звязаны таксама некаторыя вылічальныя рэсурсы (Вылічыць). Стварыўшы скрыпт для навучання мадэлі, вы можаце паслаць эксперымент на выкананне у працоўную вобласць, і паказаць compute target - Пры гэтым скрыпт будзе спакаваны, запушчаны ў патрэбным вылічальным асяроддзі, а затым усе вынікі эксперыменту будуць захаваны ў працоўнай вобласці для далейшага аналізу і выкарыстанні.
Навучальны скрыпт для MNIST
Разгледзім класічную задачу з выкарыстаннем набору даных MNIST. Аналагічна ў далейшым вы зможаце выконваць любыя свае навучальныя скрыпты.
У нашым рэпазітары ёсць скрыпт train_local.py, які навучае найпростую мадэль лінейнай рэгрэсіі з выкарыстаннем бібліятэкі SkLearn. Вядома, я разумею, што гэта не самы лепшы спосаб вырашыць задачу - мы выкарыстоўваем яго для прыкладу, як самы просты.
Скрыпт спачатку спампоўвае дадзеныя MNIST з OpenML, а затым выкарыстоўвае клас. LogisticRegression для навучання мадэлі, і затым друкуе атрыманую дакладнасць:
mnist = fetch_openml('mnist_784')
mnist['target'] = np.array([int(x) for x in mnist['target']])
shuffle_index = np.random.permutation(len(mist['data']))
X, y = mnist['data'][shuffle_index], mnist['target'][shuffle_index]
X_train, X_test, y_train, y_test =
train_test_split(X, y, test_size = 0.3, random_state = 42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_hat = lr.predict(X_test)
acc = np.average(np.int32(y_hat == y_test))
print('Overall accuracy:', acc)Вы можаце запусціць скрыпт на сваім кампутары і праз пару секунд атрымаеце вынік.
Запускаем скрыпт у Azure ML
Калі ж мы будзем запускаць скрыпт на навучанне праз Azure ML, у нас будзе дзве асноўныя перавагі:
- Запуск навучання на адвольным вылічальным рэсурсе, які, як правіла, больш прадукцыйны, чым лакальны кампутар. Пры гэтым Azure ML сам паклапоціцца аб тым, каб спакаваць наш скрыпт з усімі файламі з бягучай дырэкторыі ў docker-кантэйнер, усталяваць патрабаваныя залежнасці, і адправіць яго на выкананне.
- Запіс вынікаў у адзіны рэестр ўнутры працоўнай вобласці Azure ML. Каб скарыстацца гэтай магчымасцю, нам трэба дадаць пару радкоў кода да нашага скрыпту для запісу выніковай дакладнасці:
from azureml.core.run import Run
...
try:
run = Run.get_submitted_run()
run.log('accuracy', acc)
except:
passАдпаведная версія скрыпту называецца train_universal.py (яна крыху больш хітра ўладкованая, чым напісана вышэй, але не моцна). Гэты скрыпт можна запускаць як лакальна, так і на выдаленым вылічальным рэсурсе.
Каб запусціць яго ў Azure ML з VS Code, трэба прарабіць наступнае:
Пераканайцеся, што Azure Extension падключана да вашай падпіскі. Абярыце абразок Azure у меню злева. Калі вы не падлучаныя, у правым ніжнім куце з'явіцца апавяшчэнне (), націснуўшы на якое вы зможаце ўвайсці праз браўзэр. Можна таксама націснуць Ctrl-Shift-P для выкліку каманднага радка VS Code, і набраць Azure Sign In.
Пасля гэтага, у падзеле Azure (іконка злева) знайдзіце секцыю НАВУЧАННЕ НА МАШЫНЕ:
Тут вы павінны бачыць розныя групы аб'ектаў усярэдзіне працоўнай вобласці: вылічальныя рэсурсы, эксперыменты і г.д.
- Перайдзіце да спісу файлаў, націсніце правай кнопкай на скрыпце
train_universal.pyі абярыце Azure ML: Run as experiment in Azure.
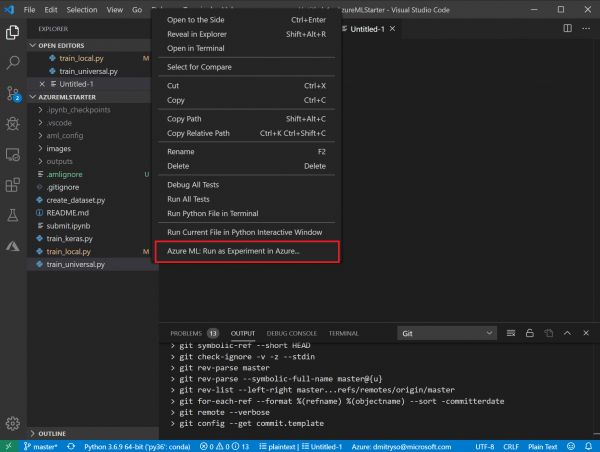
- Пасля гэтага рушыць услед серыя дыялогаў у вобласці каманднага радка VS Code: пацвердзіце выкарыстоўваную падпіску і працоўную вобласць Azure ML, а таксама абярыце Create new experiment:



Абярыце стварэнне новага вылічальнага рэсурсу Create New Compute:
- Вылічыць вызначае вылічальны рэсурс, на якім будзе адбывацца навучанне. Вы можаце выбраць лакальны кампутар, ці хмарны кластар AmlCompute. Я рэкамендую стварыць які маштабуецца кластар машын
STANDARD_DS3_v2, з мінімальным лікам машын 0 (а максімальнае можа быць 1 ці больш, у залежнасці ад вашых апетытаў). Гэта можна зрабіць праз інтэрфейс VS Code, ці папярэдне праз .

- Вылічыць вызначае вылічальны рэсурс, на якім будзе адбывацца навучанне. Вы можаце выбраць лакальны кампутар, ці хмарны кластар AmlCompute. Я рэкамендую стварыць які маштабуецца кластар машын
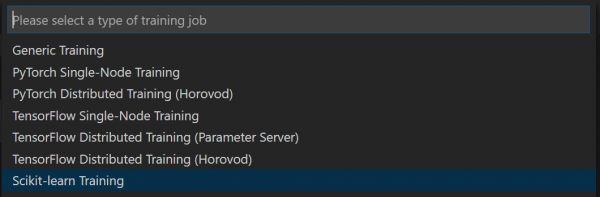
Далей неабходна абраць канфігурацыю Compute Configuration, якая вызначае параметры ствараемага для навучання кантэйнера, у прыватнасці, усе неабходныя бібліятэкі. У нашым выпадку, паколькі мы выкарыстоўваем Scikit Learn, выбіраемы SkLearn, і затым проста пацвярджаем прапанаваны спіс бібліятэк націскам Enter. Калі вы выкарыстоўваеце нейкія дадатковыя бібліятэкі - іх неабходна тут паказаць.


Пасля гэтага адкрыецца акно з JSON-файлам, які апісвае эксперымент. У ім можна выправіць некаторыя параметры - напрыклад, імя эксперыменту. Пасля гэтага націсніце на спасылку Submit Experiment прама ўнутры гэтага файла:


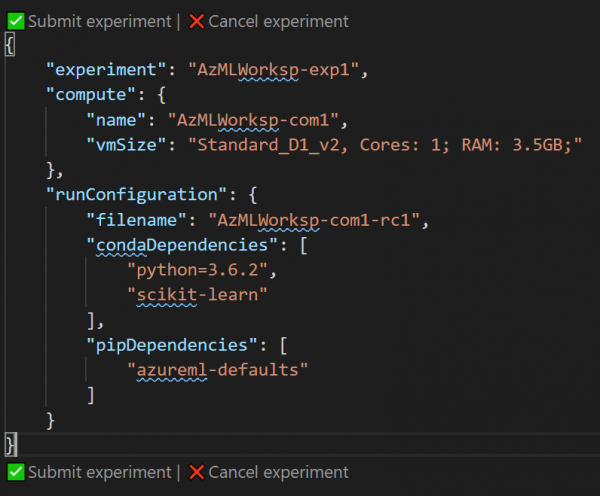
- Пасля паспяховай падачы эксперыменту праз VS Code, справа ў галіне апавяшчэнняў вы ўбачыце спасылку на , На якой зможаце адсочваць статус і вынікі эксперыменту.
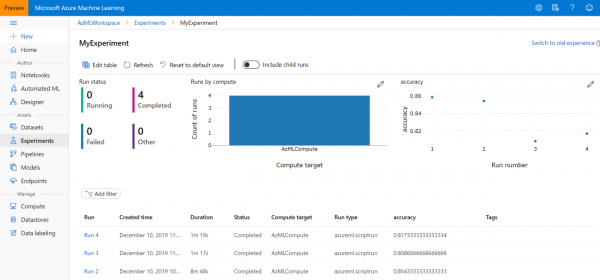
Пасля вы заўсёды зможаце знайсці яго ў раздзеле Эксперыменты , або ў раздзеле Мазутнае навучанне Azure у спісе эксперыментаў:
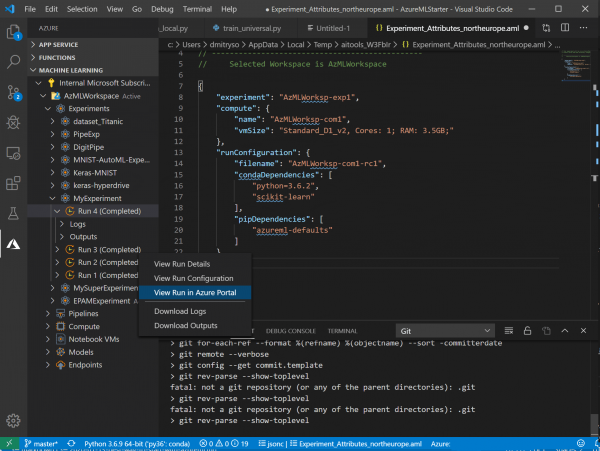
- Калі вы пасля гэтага ўнеслі ў код нейкія выпраўленні або змянілі параметры - паўторны запуск эксперыменту будзе нашмат хутчэй і прасцей. Націснуўшы правай кнопкай на файл, вы ўбачыце новы пункт меню Repeat last run - проста абярыце яго, і эксперымент будзе адразу ж запушчаны:
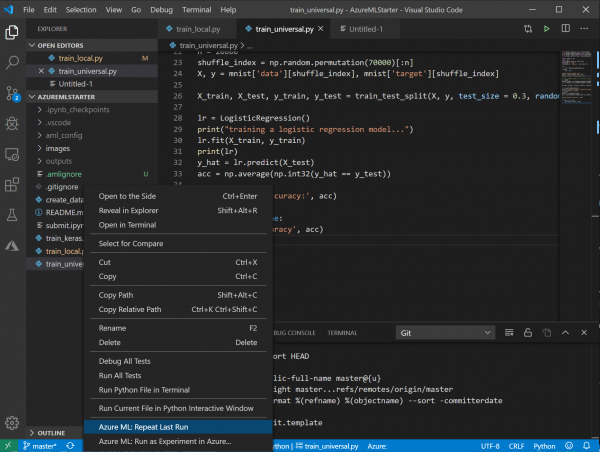
Вынікі метрык ад усіх запускаў вы заўсёды зможаце знайсці на Azure ML Portal, няма неабходнасці іх запісваць.
Цяпер вы ведаеце, што запускаць эксперыменты з дапамогай Azure ML - гэта проста і бязбольна, і пры гэтым вы атрымліваеце шэраг прыемных пераваг.
Але вы маглі заўважыць і недахопы. Напрыклад, для запуску скрыпту спатрэбілася значна больш часу. Вядома, для пакавання скрыпту ў кантэйнер і разгортванні яго на серверы патрабуецца час. Калі пры гэтым кластар быў зрэзаны да памеру ў 0 вузлоў - запатрабуецца яшчэ больш чакай для запуску віртуальнай машыны, і ўсё гэта вельмі прыкметна, калі мы эксперыментуем на простых задачах тыпу MNIST, якія вырашаюцца за некалькі секунд. Аднак, у рэальным жыцці, калі навучанне доўжыцца некалькі гадзін, а то і дзён ці тыдняў, гэты дадатковы час становіцца неістотным, асабліва на фоне моцна больш высокай прадукцыйнасці, якую можа даць вылічальны кластар.
Што далей?
Я спадзяюся, што пасля прачытання гэтага артыкула вы зможаце і будзеце выкарыстоўваць Azure ML у сваёй працы для запуску скрыптоў, кіравання вылічальнымі рэсурсамі і цэнтралізаванага захоўвання вынікаў. Аднак Azure ML можа даць вам яшчэ больш пераваг!
Усярэдзіне працоўнай вобласці можна захоўваць дадзеныя, тым самым ствараючы цэнтралізаванае сховішча для ўсіх сваіх задач, да якога лёгка звяртацца. Акрамя таго, вы можаце запускаць эксперыменты не з Visual Studio Code, а з выкарыстаннем API - гэта можа быць асабліва карысна, калі вам трэба здзейсніць аптымізацыю гіперпараметраў, і трэба запусціць скрыпт шмат разоў з рознымі параметрамі. Больш за тое, у Azure ML убудавана спецыяльная тэхналогія , Якая дазваляе рабіць больш хітры пошук і аптымізацыю гіперпараметраў. Пра гэтыя магчымасці я раскажу ў сваёй наступнай нататцы.
карысныя рэсурсы
Для больш падрабязнага вывучэння Azure ML, вам могуць спатрэбіцца наступныя курсы Microsoft Learn:
Крыніца: habr.com
