


Прывітанне, Хабр! Я Арцём Карамышаў, кіраўнік каманды сістэмнага адміністравання За апошні год у нас было шмат запускаў новых прадуктаў. Мы хацелі дамагчыся, каб API-сэрвісы лёгка маштабаваліся, былі адмоваўстойлівымі і гатовымі да хуткага росту карыстацкай нагрузкі. таксама развівае прадукты на OpenStack.
Агульная адмоваўстойлівасць платформы складаецца з устойлівасці яе кампанентаў. Так што мы паступова пройдзем праз усе ўзроўні, на якіх мы выявілі рызыкі і закрылі іх.
Відэаверсію гэтай гісторыі, першакрыніцай якой стаў даклад на канферэнцыі Uptime day 4, арганізаванай , можна паглядзець .
Адмоўаўстойлівасць фізічнай архітэктуры
Публічная частка аблокі MCS зараз грунтуецца ў двух дата-цэнтрах ўзроўню Tier III, паміж імі ёсць уласнае цёмнае валакно, зарэзерваванае фізічна рознымі трасамі, з прапускной здольнасцю 200 Гбіт / c. Узровень Tier III забяспечвае неабходны ўзровень адмоваўстойлівасці фізічнай інфраструктуры.
Цёмнае валакно зарэзервавана як на фізічным, так і на лагічным узроўні. Працэс рэзервавання каналаў быў ітэратыўны, узнікалі праблемы, і мы ўвесь час удасканальваем сувязь паміж дата-цэнтрамі.
Напрыклад, не так даўно пры працах у студні побач з адным з дата-цэнтраў экскаватарам прабілі трубу, усярэдзіне гэтай трубы апынуўся як асноўны, так і рэзервовы аптычны кабель. праклалі дадатковую оптыку па суседняй студні.
У дата-цэнтрах ёсць кропкі прысутнасці правайдэраў сувязі, якім мы транслюем свае прэфіксы па BGP.
У выпадку адмовы ў працы правайдэра мы ў аўтаматычным рэжыме перамыкаемся на наступнага.
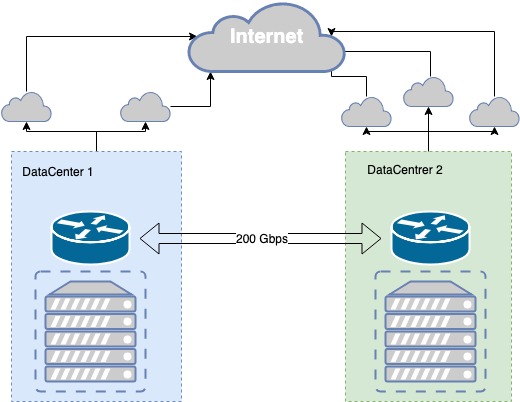
Адмоўаўстойлівасць фізічнай інфраструктуры
Што мы выкарыстоўваем для адмоваўстойлівасці на ўзроўні прыкладанняў
Наш сэрвіс пабудаваны на шэрагу opensource-кампанентаў.
ExaBGP — сэрвіс, які рэалізуе шэраг функцый з выкарыстаннем пратаколу дынамічнай маршрутызацыі на базе BGP.
HAProxy — высоканагружаны балансавальнік, які дазваляе наладжваць вельмі гнуткія правілы балансавання трафіку на розных узроўнях мадэлі OSI.
API application — web-дадатак, напісаны на python, з дапамогай якога карыстач кіруе сваёй інфраструктурай, сваім сэрвісам.
Worker application (далей проста worker) - у сэрвісах OpenStack гэта інфраструктурны дэман, які дазваляе трансляваць API-каманды на інфраструктуру. Напрыклад, стварэнне дыска адбываецца менавіта ў worker, а запыт на стварэнне - у API application.
Стандартная архітэктура OpenStack Application
Большасць сэрвісаў, якія распрацоўваюцца пад OpenStack, спрабуюць прытрымлівацца адзінай парадыгме. Сэрвіс звычайна складаецца з 2 частак: API і worker'ы (выканаўцы бэкенда). і перадае далейшыя інструкцыі на выкананне з дадаткам worker application. Перадача адбываецца з дапамогай брокера паведамленняў, як правіла гэта RabbitMQ, астатнія падтрымліваюцца дрэнна. Калі паведамленні трапляюць у брокер, іх у выпадку неабходнасці вяртаюць адказ.
Гэта парадыгма мае на ўвазе ізаляваныя агульныя кропкі адмовы: RabbitMQ і базу дадзеных. Затое RabbitMQ ізаляваны ў рамках аднаго сэрвісу і па ідэі можа быць індывідуальным для кожнага сэрвісу. кропках ламаецца не ўвесь сэрвіс, а толькі яго частка.
Колькасць worker application нічым не абмежавана, таму API можа лёгка маштабавацца гарызантальна за балансавальнікамі ў мэтах павелічэння прадукцыйнасці і адмоваўстойлівасці.
У некаторых сэрвісах неабходная каардынацыя ўсярэдзіне сэрвісу — калі адбываюцца складаныя паслядоўныя аперацыі паміж API і worker'амі. воркеры актыўна мае зносіны з базай дадзеных, піша і чытае адтуль інфармацыю.
Такі класічны адзіночны сэрвіс арганізаваны агульнапрынятым для OpenStack чынам. Яго можна разглядаць як замкнёную сістэму, для якой досыць відавочныя спосабы маштабавання і адмоваўстойлівасці.
Слабым месцам ва ўсёй схеме з'яўляюцца RabbitMQ і MariaDB. Іх архітэктура заслугоўвае асобнага артыкула.
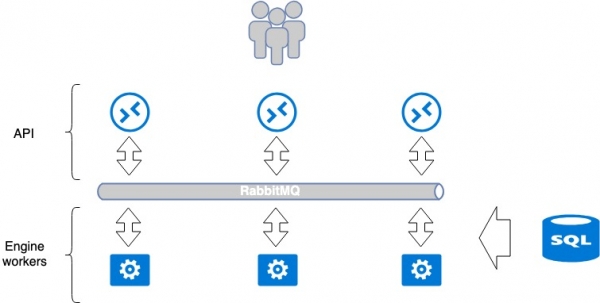
Архітэктура Openstack Application.
Які робіцца балансавальнік HAProxy адмоваўстойлівасцю з дапамогай ExaBGP
Каб нашы API былі маштабуюцца, хуткія і адмоваўстойлівасць, мы паставілі перад імі балансавальнік. Мы абралі HAProxy.
Першая праблема, якую неабходна было вырашыць, – адмоваўстойлівасць самога балансавальніка.
ExaBGP дазваляе рэалізаваць механізм праверкі стану сэрвісу. Мы выкарыстоўвалі гэты механізм для таго, каб правяраць працаздольнасць HAProxy і ў выпадку праблем выключаць сэрвіс HAProxy з BGP.
Схема ExaBGP+HAProxy
- Усталеўваны на тры сервера неабходны софт, ExaBGP і HAProxy.
- На кожным з сервераў ствараем loopback-інтэрфейс.
- На ўсіх трох серверах прапісваем на гэты інтэрфейс адзін і той жа белы IP-адрас.
- Белы IP-адрас анансуецца ў інтэрнэт праз ExaBGP.
Адмаўстойлівасць дасягаецца шляхам анонсу аднаго і таго ж IP-адрасы з усіх трох сервераў. З пункту гледжання сеткі адзін і той жа адрас, даступны з трох розных next хопаў.
У выпадку праблем з працай HAProxy або выхаду сервера са строю, ExaBGP перастае анонсаваць маршрут, і трафік плаўна перамыкаецца на іншы сервер.
Такім чынам мы дабіліся адмоваўстойлівасці балансавальніка.
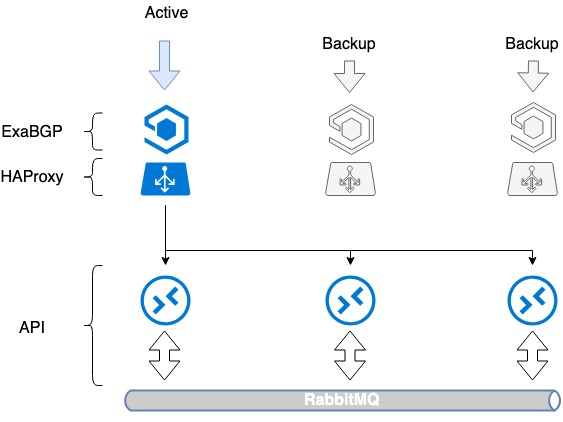
Адмаўстойлівасць балансавальнікаў HAProxy
Схема атрымалася неідэальнай: мы навучыліся рэзерваваць HAProxy, але не навучыліся размяркоўваць нагрузку ўсярэдзіне сэрвісаў. Таму мы гэтую схему трохі пашырылі: перайшлі да балансавання паміж некалькімі белымі IP-адрасамі.
Балансіроўка на базе DNS плюс BGP
Застаўся не вырашана пытанне балансавання нагрузкі перад нашымі HAProxy.
Для балансавання трох сервераў спатрэбіцца 3 белых IP-адрасы і стары добры DNS. Кожны з гэтых адрасоў вызначаецца на loopback-інтэрфейс кожнага HAProxy і анансуецца ў інтэрнэт.
У OpenStack для кіравання рэсурсамі выкарыстоўваецца каталог сэрвісаў, у якім задаецца endpoint API таго ці іншага сэрвісу.
Але бо пры анансаванні белых IP-адрасоў мы не кіруем прыярытэтамі выбару сервера, пакуль гэта не балансаванне. Як правіла, будзе выбірацца толькі адзін сервер па старшынстве IP-адрасы, а два іншых будуць прастойваць, паколькі не паказаныя ніякія метрыкі ў BGP.
Мы пачалі аддаваць маршруты праз ExaBGP з рознай метрыкай. Кожны балансавальнік анансуе ўсе тры белых IP-адрасы, але адзін з іх, галоўны для дадзенага балансавальніка, анансуецца з мінімальнай метрыкай. трэці.
Што адбываецца ў той момант, калі адзін з балансавальнікаў падае? Пры адмове любога балансавальніка яго асновай усё яшчэ анансуецца з двух іншых, трафік паміж імі пераразмяркоўваецца. губляем адмоваўстойлівасць.
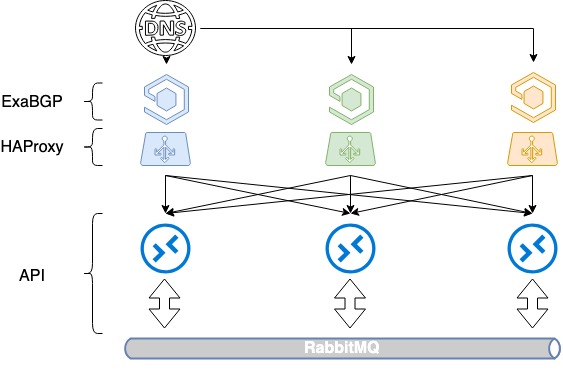
Балансіроўка HAProxy на базе DNS + BGP
Узаемадзеянне паміж ExaBGP і HAProxy
Такім чынам, мы рэалізавалі адмоваўстойлівасць на выпадак сыходу сервера, на аснове спынення анонсу маршрутаў.
Таму, пашыраючы папярэднюю схему, мы рэалізавалі heartbeat паміж ExaBGP і HAProxy.
Для гэтага ў канфізе ExaBGP неабходна наладзіць health checker, які зможа правяраць статут HAProxy. У нашым выпадку мы наладзілі health backend у HAProxy, а са боку ExaBGP правяраем простым GET запытам.
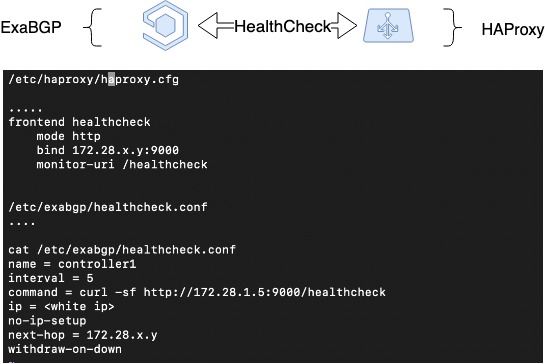
HAProxy Health Check
HAProxy Peers: сінхранізацыя сесій
Наступнае, што неабходна было зрабіць, – сінхранізаваць сесіі. Пры працы праз размеркаваныя балансавальнікі складана арганізаваць захаванне інфармацыі аб сесіях кліентаў.
Існуюць розныя метады балансавання: простыя, такія як , І пашыраныя, калі запамінаецца сесія кліента, і ён кожны раз пападае на той жа сервер, што і раней.
У HAProxy для захавання сесій кліента гэтага механізму выкарыстоўваецца stick-tables. Яны захоўваюць зыходны IP-адрас кліента, абраны таргет-адрас (бэкэнд) і некаторую службовую інфармацыю. балансавальнік, напрыклад - у рэжыме балансавання RoundRobin.
Калі stick-табліцу навучыць перамяшчацца паміж рознымі працэсамі HAProxy (паміж якімі адбываецца балансаванне), нашы балансавальнікі змогуць працаваць з адным пулам stick-табліц. Гэта дасць магчымасць бясшвоўнага пераключэння сеткі кліента пры падзенні аднаго з балансавальнікаў, праца з сесіямі кліентаў працягнецца на тых жа бэк.
Для правільнай працы павінна быць вырашана праблема source IP-адрасы балансавальніка, з якога ўсталяваная сесія.
Правільная праца peers дасягаецца толькі ў вызначаных умовах. Гэта значыць, TCP-таймаўты павінны быць досыць вялікімі ці пераключэнне павінна быць досыць хуткае, каб TCP-сесія не паспела абарвацца.
У нас у IaaS ёсць сэрвіс, пабудаваны па такой жа тэхналогіі. , які называецца Octavia. Ён заснаваны на базе двух працэсаў HAProxy, у ім першапачаткова закладзена падтрымка peers.
На малюнку схематычна намалявана перасоўванне peers-табліц паміж трыма інстансамі HAProxy, прапанаваны канфіг, як гэта можна наладзіць:
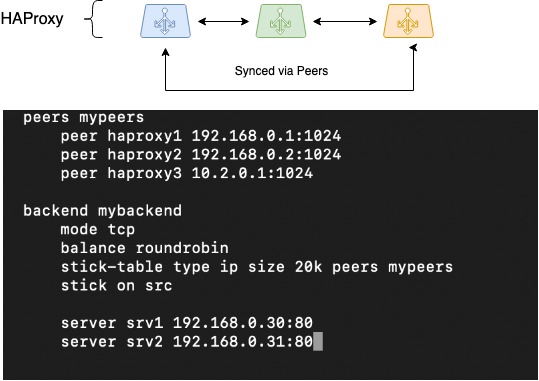
HAProxy Peers (сінхранізацыя сесій)
Калі вы будзеце рэалізоўваць такую ж схему, яе працу трэба ўважліва тэсціраваць. Не факт, што гэта спрацуе ў такім жа выглядзе ў 100% выпадкаў.
Абмежаванне колькасці адначасовых запытаў з аднаго і таго ж кліента
Любыя сэрвісы змешчаныя ў адчыненым доступе, у тым ліку і нашы API, могуць быць схільныя лавінам запытаў.
Так ці інакш неабходна прадугледзець дадатковую абарону. Відавочным рашэннем становіцца абмяжоўваць колькасць запытаў да API і не марнаваць працэсарны час на апрацоўку шкоднасных запытаў.
Для рэалізацыі падобных абмежаванняў мы ўжываем rate limits, арганізаваныя на базе HAProxy, з дапамогай тых жа stick-табліц. Наладжваюцца ліміты досыць проста і дазваляюць абмежаваць карыстача па колькасці запытаў да API. у кожнага сэрвісу і ўсталявалі ліміт - у 10 разоў больш гэтага значэння.
Як гэта выглядае на практыцы?У нас ёсць кліенты, якія ўвесь час карыстаюцца нашымі API для аўтамаштабавання.
Такія перакідванні задач выклікаюць досыць вялікую нагрузку. Мы гэтую нагрузку ацанілі, сабралі дзённыя пікі, павялічылі іх у дзесяць разоў, і гэта стала нашым rate-лімітам.
Як абнаўляць кодавую базу неўзаметку для карыстальнікаў
Мы рэалізуем адмоваўстойлівасць таксама і на ўзроўні працэсаў дэплою кода. Пры выкатках бываюць збоі, але іх уплыў на даступнасць сэрвісаў можна мінімізаваць.
Мы ўвесь час абнаўляем свае сэрвісы і павінны забяспечваць працэс абнаўлення кодавай базы без эфекту для карыстачоў.
Для рашэння гэтай задачы трэба было забяспечыць кіраванне балансавальнікам і «правільнае» выключэнне сэрвісаў:
- У выпадку з HAProxy кіраванне вырабляецца праз stats-файл, які ў сутнасці з'яўляецца сокетам і вызначаецца ў канфігу HAProxy. Але перадаваць яму каманды можна праз stdio.
- Большая частка нашых сэрвісаў API і Engine падтрымліваюць тэхналогіі graceful shutdown: пры выключэнні яны чакаюць поўнага завяршэння бягучай задачы, няхай гэта будзе http-запыт або якая-небудзь службовая задача.
Дзякуючы гэтым двум момантам, бяспечны алгарытм нашага дэплою выглядае наступным чынам.
- Распрацоўнік збірае новы пакет кода (у нас гэта RPM), тэстуе ў dev-асяроддзі, тэстуе ў stage, і пакідае ў stage-рэпазітары.
- Распрацоўнік ставіць задачу на дэплой з максімальна падрабязным апісаннем "артэфактаў": версія новага пакета, апісанне новага функцыяналу і іншыя падрабязнасці аб дэплоі ў выпадку неабходнасці.
- Сістэмны адміністратар пачынае абнаўленне. Запускае плэйбук Ansible, які ў сваю чаргу робіць наступнае:
- Бярэ пакет з stage-рэпазітара, па ім абнаўляе версію пакета ў прадуктовым рэпазітары.
- Складае спіс бэкэндаў які абнаўляецца сэрвісу.
- Выключае першы які абнаўляецца сэрвіс у HAProxy і чакае канчаткі працы яго працэсаў. Дзякуючы graceful shutdown мы ўпэўненыя, што ўсе бягучыя запыты кліентаў завершацца паспяхова.
- Пасля поўнага прыпынку API, worker'ов, выключэнні HAProxy, адбываецца абнаўленне кода.
- Ansible запускае сэрвісы.
- Для кожнага сэрвісу тузае пэўныя "ручкі", якія робяць unit-тэставанне па шэрагу загадзя вызначаных ключавых тэстаў.
- Калі на папярэднім кроку не было выяўлена памылак, то бэкэнд актывуецца.
- Пераходзім да наступнага бэкэнду.
- Пасля абнаўлення ўсіх бэкэндаў, запускаюцца функцыянальныя тэсты. Калі іх не хапае, то распрацоўшчык глядзіць любую новую функцыянальнасць, якую ён рабіў.
На гэтым дэплой завершаны.
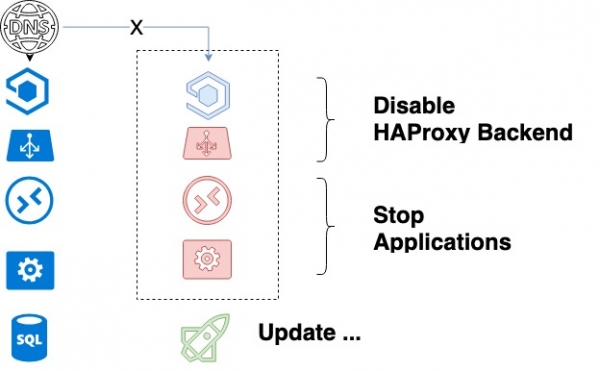
Цыкл абнаўлення сэрвісу
Гэтая схема не была б працоўнай, калі б у нас не было аднаго правіла. Мы падтрымліваем на баі адначасова старую і новую версіі.
Заключэнне
Дзелячыся ўласнымі думкамі наконт абароненай ад збояў WEB-архітэктуры, хачу яшчэ раз адзначыць яе ключавыя моманты:
- фізічная адмоваўстойлівасць;
- сеткавая адмоваўстойлівасць (балансавальнікі, BGP);
- адмоваўстойлівасць выкарыстоўванага і распрацоўванага софту.
Усім стабільнага uptime!
Крыніца: habr.com
