

Заўв. перав.: Гэты артыкул, напісаны Galo Navarro, што займае пасаду Principal Software Engineer у еўрапейскай кампаніі Adevinta, - займальнае і павучальнае "расследаванне" ў галіне эксплуатацыі інфраструктуры. Яе арыгінальная назва была крыху дапоўнена ў перакладзе па прычыне, якую тлумачыць аўтар у самым пачатку.
Заўвага ад аўтара: Падобна, гэтая публікацыя значна больш увагі, чым чакалася. Я да гэтага часу атрымліваю гнеўныя каментары аб тым, што назва артыкула ўводзіць у зман і што некаторыя чытачы засмучаныя. Я разумею прычыны таго, што адбываецца, таму, нягледзячы на рызыку сарваць усю інтрыгу, хачу адразу расказаць, пра што гэты артыкул. Пры пераходзе каманд на Kubernetes я назіраю цікавую рэч: кожны раз, калі ўзнікае праблема (напрыклад, рост затрымак пасля міграцыі), перш за ўсё абвінавачваюць Kubernetes, аднак потым аказваецца, што аркестратар, увогуле, не вінаваты. Гэты артыкул апавядае пра адзін з такіх выпадкаў. Яе назва паўтарае вокліч аднаго з нашых распрацоўшчыкаў (потым вы пераканаецеся, што Kubernetes тут зусім ні пры чым). У ёй вы не знойдзеце нечаканых адкрыццяў аб Kubernetes, але можаце разлічваць на пару добрых урокаў аб складаных сістэмах.
Пару тыдняў таму мая каманда займалася міграцыяй аднаго мікрасэрвісу на асноўную платформу, якая ўключае CI/CD, працоўнае асяроддзе на аснове Kubernetes, метрыкі і іншыя карыснасці. Пераезд насіў выпрабавальны характар: мы планавалі ўзяць яго за аснову і перанесці яшчэ прыкладна 150 сэрвісаў у найбліжэйшыя месяцы. Усе яны адказваюць за працу некаторых з найбуйных анлайн-пляцовак Іспаніі (Infojobs, Fotocasa і інш.).
Пасля таго, як мы разгарнулі прыкладанне ў Kubernetes і перанакіравалі на яго частку трафіку, нас чакаў трывожны сюрпрыз. Затрымка (latency) запытаў у Kubernetes была ў 10 разоў вышэй, чым у EC2. Увогуле, было неабходна або шукаць вырашэнне гэтай праблемы, або адмаўляцца ад міграцыі мікрасэрвісу (і, магчыма, ад усяго праекта).
Чаму ў Kubernetes затрымка настолькі вышэйшая, чым у EC2?
Каб знайсці вузкае месца, мы сабралі метрыкі на ўсім шляху запыту. Наша архітэктура простая: API-шлюз (Zuul) праксіруе запыты да экзэмпляраў мікрасэрвісу ў EC2 або Kubernetes. У Kubernetes мы выкарыстоўваем NGINX Ingress Сontroller, а бэкэнды ўяўляюць сабой звычайныя аб'екты тыпу з JVM-дадаткам на платформе Spring.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Здавалася, што праблема злучана з затрымкай на пачатковым этапе працы ў бэкендзе (я пазначыў праблемны ўчастак на графіцы як «хх»). У EC2 адказ дадатку займаў каля 20 мс. У Kubernetes затрымка ўзрастала да 100-200 мс.
Мы хутка адкінулі верагодных падазраваных, звязаных са зменай асяроддзя выканання. Версія JVM засталася ранейшай. Праблемы кантэйнерызацыі таксама былі ні пры чым: прыкладанне ўжо паспяхова працавала ў кантэйнерах у EC2. Загрузка? Але мы назіралі высокія затрымкі нават пры 1 запыце за секунду. Паўзамі на зборку смецця таксама можна было занядбаць.
Адзін з нашых адміністратараў Kubernetes пацікавіўся, ці няма ў дадатку знешніх залежнасцяў, паколькі ў мінулым запыты да DNS выклікалі падобныя праблемы.
Гіпотэза 1: дазвол імёнаў DNS
Пры кожным запыце наша дадатак ад аднаго да трох разоў звяртаецца да асобніка AWS Elasticsearch у дамене накшталт elastic.spain.adevinta.com. Унутры кантэйнераў у нас , таму мы можам праверыць, ці сапраўды пошук дамена займае працяглы час.
DNS-запыты з кантэйнера:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecАналагічныя запыты з аднаго з экзэмпляраў EC2, дзе працуе дадатак:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecУлічваючы, што пошук займае каля 30 мс, стала ясна, што дазвол DNS пры звароце да Elasticsearch сапраўды робіць уклад у ўзрастанне затрымкі.
Аднак гэта было дзіўна па дзвюх прычынах:
- У нас ужо ёсць маса прыкладанняў у Kubernetes, якія ўзаемадзейнічаюць з рэсурсамі AWS, але не пакутуюць ад вялікіх затрымак. Які б ні была прычына, яна мае дачыненьне канкрэтна да гэтага выпадку.
- Мы ведаем, што JVM ажыццяўляе in-memory-кэшаванне DNS. У нашых выявах значэнне TTL прапісана ў
$JAVA_HOME/jre/lib/security/java.securityі ўстаноўлена на 10 секунд:networkaddress.cache.ttl = 10. Іншымі словамі, JVM павінна кэшаваць усе DNS-запыты на 10 секунд.
Каб пацвердзіць першую гіпотэзу, мы вырашылі на час адмовіцца ад зваротаў да DNS і паглядзець, ці знікне праблема. Перш мы вырашылі пераналадзіць прыкладанне, каб яно звязвалася з Elasticsearch напрамую па IP-адрасу, а не праз даменнае імя. Гэта запатрабавала б праўкі кода і новага разгортвання, таму мы проста супаставілі дамен з яго IP-адрасам у /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comЦяпер кантэйнер атрымліваў IP амаль імгненна. Гэта прывяло да некаторага паляпшэння, але мы толькі злёгку наблізіліся да чаканага ўзроўню затрымкі. Хоць дазвол DNS займала шмат часу, сапраўдная прычына па-ранейшаму выслізгвала ад нас.
Дыягностыка з дапамогай сеткі
Мы вырашылі прааналізаваць трафік з кантэйнера з дапамогай tcpdump, каб прасачыць, што менавіта адбываецца ў сетцы:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Затым мы даслалі некалькі запытаў і спампавалі іх capture (kubectl cp my-service:/capture.pcap capture.pcap) для далейшага аналізу ў .
У DNS-запытах не было нічога падазронага (акрамя адной дробязі, пра якую я раскажу пазней). Але былі пэўныя дзівацтвы ў тым, як наш сэрвіс апрацоўваў кожны запыт. Ніжэй прыведзены скрыншот capture'а, які паказвае прыняцце запыту да пачатку адказу:
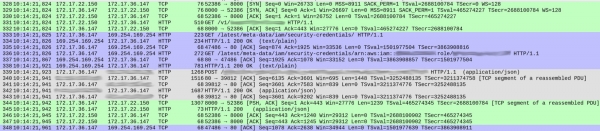
Нумары пакетаў прыведзены ў першым слупку. Для яснасці я вылучыў колерам розныя плыні TCP.
Зялёны струмень, які пачынаецца з 328-го пакета, паказвае, як кліент (172.17.22.150) усталяваў TCP-злучэнне з кантэйнерам (172.17.36.147). Пасля першаснага поціску рукі (328-330), пакет 331 прынёс HTTP GET /v1/.. - уваходны запыт да нашага сэрвісу. Увесь працэс заняў 1 мс.
Шэры струмень (з пакета 339) паказвае, што наш сэрвіс паслаў HTTP-запыт да асобніка Elasticsearch (TCP-поціск рукі адсутнічае, паколькі выкарыстоўваецца ўжо наяўнае злучэнне). На гэта спатрэбілася 18 мс.
Пакуль усё нармальна, і часы прыкладна адпавядаюць чаканым затрымкам (20-30 мс пры замерах з кліента).
Аднак сіняя секцыя займае 86 мс. Што ў ёй адбываецца? З пакетам 333 наш сэрвіс даслаў HTTP GET-запыт на /latest/meta-data/iam/security-credentials, а адразу пасля яго, па тым жа TCP-злучэнні, яшчэ адзін GET-запыт на /latest/meta-data/iam/security-credentials/arn:...
Мы выявілі, што гэта паўтараецца з кожным запытам ва ўсёй трасіроўцы. Дазвол DNS сапраўды крыху павольней у нашых кантэйнерах (тлумачэнне гэтага феномену вельмі цікава, але я зберагу яго для асобнага артыкула). Аказалася, што прычынай вялікіх затрымак з'яўляюцца звароты да сэрвісу AWS Instance Metadata пры кожным запыце.
Гіпотэза 2: лішнія звароты да AWS
Абодва endpoint'а належаць . Наш мікрасэрвіс выкарыстоўвае гэты сэрвіс падчас працы з Elasticsearch. Абодва выкліку з'яўляюцца часткай базавага працэсу аўтарызацыі. Endpoint, да якога адбываецца зварот пры першым запыце, выдае ролю IAM, злучаную з асобнікам.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleДругі запыт звяртаецца да другога endpoint'у за часовымі паўнамоцтвамі для дадзенага асобніка:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Кліент можа карыстацца імі на працягу невялікага перыяду часу і перыядычна павінен атрымліваць новыя сертыфікаты (да іх Expiration). Мадэль простая: AWS праводзіць частую ратацыю часавых ключоў па меркаваннях бяспекі, але кліенты могуць кэшаваць іх на некалькі хвілін, кампенсуючы зніжэнне прадукцыйнасці, звязанае з атрыманнем новых сертыфікатаў.
AWS Java SDK павінен узяць на сябе абавязкі па арганізацыі гэтага працэсу, аднак па нейкай прычыне гэтага не адбываецца.
Правёўшы пошук па issues на GitHub, мы сутыкнуліся з праблемай . Яна дапамагла нам вызначыць напрамак, у якім трэба "капаць" далей.
AWS SDK абнаўляе сертыфікаты пры надыходзе адной з наступных умоў:
- Тэрмін заканчэння іх дзеяння (
Expiration) трапляе ўEXPIRATION_THRESHOLD, жорстка ўсталяваны ў кодзе на 15 хвілін. - З моманту апошняй спробы абнавіць сертыфікаты прайшло больш чакай, чым
REFRESH_THRESHOLD, за'hardcode'ены на 60 хвілін.
Каб паглядзець фактычны тэрмін заканчэння атрыманых намі сертыфікатаў, мы выканалі прыведзеныя вышэй cURL-каманды з кантэйнера і з экзэмпляра EC2. Час дзеяння сертыфіката, атрыманага з кантэйнера, аказалася значна карацей: роўна 15 хвілін.
Цяпер усё стала зразумела: для першага запыту наш сэрвіс атрымліваў часовыя сертыфікаты. Паколькі тэрмін іх дзеяння не перавышаў 15 мінуць, пры наступным запыце AWS SDK вырашаў абнавіць іх. І такое адбывалася з кожным запытам.
Чаму тэрмін дзеяння сертыфікатаў стаў карацейшым?
Сэрвіс AWS Instance Metadata прызначаны для працы з асобнікамі EC2, а не Kubernetes. З іншага боку, нам не хацелася мяняць інтэрфейс прыкладанняў. Для гэтага мы скарысталіся - прыладай, які з дапамогай агентаў на кожным вузле Kubernetes дазваляе карыстачам (інжынерам, якія разгортваюць прыкладанні ў кластар) прысвойваць IAM-ролі кантэйнерам у pod'ах так, нібы яны з'яўляюцца інстансамі EC2. KIAM перахапляе выклікі да сэрвісу AWS Instance Metadata і апрацоўвае іх са свайго кэша, папярэдне атрымаўшы ад AWS. З пункту гледжання прыкладання нічога не мяняецца.
KIAM пастаўляе кароткатэрміновыя сертыфікаты pod'ам. Гэта разумна, калі ўлічыць, што сярэдняя працягласць існавання pod'а менш, чым асобніка EC2. Па змаўчанні тэрмін дзеяння сертыфікатаў .
У выніку, калі накласці абодва значэнні па змаўчанні сябар на сябра, узнікае праблема. Кожны сертыфікат, прадстаўлены з дадаткам, заканчваецца праз 15 хвілін. Пры гэтым AWS Java SDK прымусова абнаўляе любы сертыфікат, да тэрміна заканчэння дзеяння якога застаецца менш за 15 хвілін.
У выніку, часовы сертыфікат прымусова абнаўляецца з кожным запытам, што цягне за сабой пары зваротаў да API AWS і прыводзіць да значнага павелічэння затрымкі. У AWS Java SDK мы выявілі , У якім згадваецца аналагічная праблема.
Рашэнне аказалася простым. Мы проста пераналадзілі KIAM на запыт сертыфікатаў з больш працяглым тэрмінам дзеяння. Як толькі гэта адбылося, запыты сталі праходзіць без удзелу сэрвісу AWS Metadata, а затрымка ўпала нават да ніжэйшага ўзроўню, чым у EC2.
Высновы
Зыходзячы з нашага досведу з міграцыямі можна сказаць, што адна з найболей частых крыніц праблем — гэта не памылкі ў Kubernetes ці іншых элементах платформы. Таксама ён не звязаны з якімі-небудзь фундаментальнымі заганамі ў мікрасэрвісах, якія мы пераносім. Праблемы часта ўзнікаюць проста таму, што мы злучаем разам розныя элементы.
Мы змешваем складаныя сістэмы, якія ніколі раней не ўзаемадзейнічалі сябар з сябрам, чакаючы, што разам яны ўтвораць адзіную, буйнейшую сістэму. Нажаль, чым больш элементаў, тым больш абшар для памылак, тым вышэй энтрапія.
У нашым выпадку высокая затрымка не была вынікам памылак ці дрэнных рашэнняў у Kubernetes, KIAM, AWS Java SDK ці нашым мікрасэрвісе. Яна стала вынікам аб'яднання двух незалежных параметраў, зададзеных па змаўчанні: аднаго ў KIAM, другога - у AWS Java SDK. Паасобку абодва параметры маюць сэнс: і актыўная палітыка абнаўлення сертыфікатаў у AWS Java SDK, і кароткі тэрмін дзеяння сертыфікатаў у KAIM. Але калі сабраць іх разам, вынікі становяцца непрадказальнымі. Два незалежныя і лагічныя рашэнні зусім не абавязаны мець сэнс пры аб'яднанні.
PS ад перакладчыка
Даведацца падрабязней пра архітэктуру ўтыліты KIAM для інтэграцыі AWS IAM з Kubernetes можна ў ад яе стваральнікаў.
А ў нашым блогу таксама чытайце:
- «»;
- «»;
- «»;
- «.
Крыніца: habr.com
