

Мяне клічуць Віктар Ягофараў, і я займаюся развіццём Kubernetes-платформы ў кампаніі ДомКлік на пасадзе тэхнічнага кіраўніка распрацоўкі ў камандзе Ops (эксплуатацыя). Я жадаў бы распавесці аб прыладзе нашых працэсаў Dev <-> Ops, аб асаблівасцях эксплуатацыі аднаго з самых вялікіх k8s-кластараў у Расіі, а таксама аб DevOps/SRE-практыках, якія ўжывае наша каманда.

Каманда Ops
У камандзе Ops на дадзены момант працуе 15 чалавек. Трое з іх адказваюць за офіс, двое працуюць у іншым часавым поясе і даступныя, у тым ліку, і ўначы. Такім чынам, заўсёды нехта з Ops знаходзіцца ў манітора і гатовы зрэагаваць на інцыдэнт любой складанасці. Начных дзяжурстваў у нас няма, што захоўвае нашу псіхіку і дае магчымасць усім высыпацца і бавіць вольны час не толькі за кампутарам.
Кампетэнцыі ва ўсіх розныя: сецявікі, DBA, спецыялісты па стэку ELK, Kubernetes-адміны / распрацоўшчыкі, спецыялісты па маніторынгу, віртуалізацыі, жалезу і г.д. Аб'ядноўвае ўсіх адно - кожны можа замяніць у нейкай ступені любога з нас: напрыклад, увесці новыя ноды ў кластар k8s, абнавіць PostgreSQL, напісаць pipeline CI/CD + Ansible, аўтаматызаваць што-небудзь на Python/Bash/Go, падлучыць жалязяку ў ЦАД. Моцныя кампетэнцыі ў якой-небудзь вобласці не перашкаджаюць змяніць напрамак дзейнасці і пачаць прапампоўвацца ў якой-небудзь іншай вобласці. Напрыклад, я ўладкоўваўся ў кампанію як спецыяліст па PostgreSQL, а цяпер мая галоўная зона адказнасці - кластары Kubernetes. У камандзе любы рост толькі вітаецца і вельмі развіта пачуццё пляча.
Дарэчы, мы хантым. Патрабаванні да кандыдатаў даволі стандартныя. Асабіста для мяне важна, каб чалавек упісваўся ў калектыў, быў неканфліктным, але таксама ўмеў адстойваць свой пункт погляду, жадаў развівацца і не баяўся рабіць нешта новае, прапаноўваў свае ідэі. Таксама, абавязковыя навыкі праграмавання на скрыптавых мовах, веданне асноў Linux і англійскай мовы. Англійская патрэбна проста для таго, каб чалавек у выпадку факапа мог загугліць вырашэнне праблемы за 10 секунд, а не за 10 хвілін. Са спецыялістамі з глыбокімі ведамі Linux зараз вельмі складана: смешна, але два кандыдаты з трох не могуць адказаць на пытанне «Што такое Load Average? З чаго ён складаецца?», а пытанне «Як сабраць core dump з сішнай праграмы» лічаць чымсьці са свету звышлюдзей… ці дыназаўраў. З гэтым даводзіцца мірыцца, бо звычайна ў людзей моцна развіты іншыя кампетэнцыі, а "лінуксу" мы навучым. Адказ на пытанне "навошта гэта ўсё трэба ведаць DevOps-інжынеру ў сучасным свеце аблокаў" давядзецца пакінуць за рамкамі артыкула, але калі трыма словамі: усё гэта трэба.
Каманда Tools
Немалую ролю ў аўтаматызацыі гуляе каманда Tools. Іх асноўная задача - стварэнне зручных графічных і CLI-інструментаў для распрацоўшчыкаў. Напрыклад, наша ўнутраная распрацоўка Confer дазваляе літаральна некалькімі зграямі мышы выкаціць прыкладанне ў Kubernetes, наладзіць яму рэсурсы, ключы з vault і г.д. Раней быў Jenkins + Helm 2, але прыйшлося распрацаваць уласны інструмент, каб выключыць копі-пасту і прыўнесці аднастайнасць у жыццёвы цыкл ПЗ.
Каманда Ops не піша пайплайны за распрацоўшчыкаў, але можа пракансультаваць па любых пытаннях у іх напісанні (у кагосьці яшчэ застаўся Helm 3).
DevOps
Што да DevOps, то мы бачым яго такім:
Каманды Dev пішуць код, выкочваюць яго праз Confer у dev -> qa/stage -> prod. Адказнасць за тое, каб код не тармазіў і не сыпаў памылкамі, ляжыць на камандах Dev і Ops. У дзённы час рэагаваць на інцыдэнт са сваім дадаткам павінен, у першую чаргу, дзяжурны ад каманды Ops, а ў вячэрні і начны час дзяжурны адмін (Ops) павінен абудзіць дзяжурнага распрацоўніка, калі ён сапраўды ведае, што праблема не ў інфраструктуры. Усе метрыкі і алерты ў маніторынгу з'яўляюцца аўтаматычна ці паўаўтаматычна.
Зона адказнасці Ops пачынаецца з моманту выкаткі прыкладанні ў прод, але і адказнасць Dev на гэтым не сканчаецца — мы робім адну справу і знаходзімся ў адной лодцы.
Распрацоўнікі кансультуюць адмінаў, калі патрэбна дапамога ў напісанні адмінскага мікрасэрвісу (напрыклад, Go backend + HTML5), а адміны кансультуюць распрацоўнікаў па любых інфраструктурных пытаннях, ці пытаннях, злучаным з k8s.
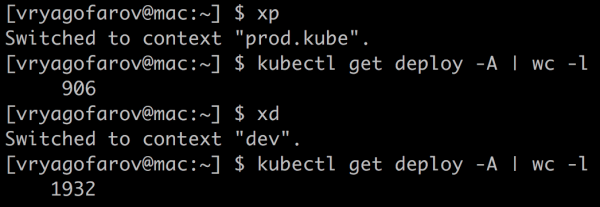
Дарэчы, у нас увогуле няма маналіта, толькі мікрасэрвісы. Іх колькасць пакуль што вагаецца паміж 900 і 1000 у prod k8s-кластары, калі вымяраць па колькасці разгортвання. Колькасць подаў вагаецца паміж 1700 і 2000. Подаў у prod-кластары зараз каля 2000.
Дакладныя лікі назваць не магу, бо мы сочым за непатрэбнымі мікрасэрвісамі і выпілоўваем іх у паўаўтаматычным рэжыме. Сачыць за непатрэбнымі сутнасцямі ў k8s нам дапамагае , што выдатна эканоміць рэсурсы і грошы.
Кіраванне рэсурсамі
Маніторынг
Краевугольным каменем у эксплуатацыі вялікага кластара становіцца пісьменна выбудаваны і інфарматыўны маніторынг. Мы пакуль не знайшлі ўніверсальнага рашэння, якое пакрыла б 100% усіх «хацелак» па маніторынгу, таму перыядычна клепаем розныя кастамныя рашэнні ў гэтым асяроддзі.
- Zabbix. Стары добры маніторынг, які прызначаны, у першую чаргу, для адсочвання агульнага стану інфраструктуры. Ён кажа нам, калі нода памірае па працы, памяці, дысках, сетцы і гэтак далей. Нічога звышнатуральнага, але таксама ў нас ёсць асобны DaemonSet з агентаў, з дапамогай якіх, напрыклад, мы маніторым стан DNS у кластары: шукаем туплівыя поды coredns, правяраем даступнасць вонкавых хастоў. Здавалася б, навошта дзеля гэтага затлумляцца, але на вялікіх аб'ёмах трафіку гэты кампанент з'яўляецца сур'ёзнай кропкай адмовы. Раней я ўжо , як змагаўся з прадукцыйнасцю DNS у кластары.
- Prometheus Operator. Набор розных экспарцёраў дае вялікі агляд усіх кампанентаў кластара. Далей візуалізуем усё гэта на вялікіх дашбордах у Grafana, а для абвестак выкарыстоўваем alertmanager.
Яшчэ адным карысным інструментам для нас стаў . Мы напісалі яго пасля таго, як некалькі разоў сутыкнуліся з сітуацыяй, калі адна каманда перакрывае сваімі шляхамі Ingress іншай каманды, з-за чаго ўзнікалі памылкі 50x. Цяпер перад дэплоем на прад распрацоўшчыкі правяраюць, што нікога не закрануць, а для маёй каманды гэта добрая прылада для першаснай дыягностыкі праблем з Ingress'амі. Пацешна, што спачатку яго напісалі для адмінаў і выглядаў ён даволі "сякерна", але пасля таго, як прылада пакахаўся dev-камандам, ён моцна змяніўся і стаў выглядаць не як "адмін зрабіў вэб-пысу для адмінаў". Хутка мы адмовімся ад гэтай прылады і падобныя сітуацыі будуць валідзіравацца яшчэ да выкаткі пайплайна.
Рэсурсы каманд у «Кубе»
Перш чым прыступіць да прыкладаў, варта растлумачыць, як у нас працуе выдзяленне рэсурсаў для мікрасэрвісаў.
Каб разумець, якія каманды і ў якіх колькасцях выкарыстоўваюць свае рэсурсы (працэсар, памяць, лакальны SSD), мы вылучаем на кожную каманду свой прастора імёнаў у «Кубе» і абмяжоўваем яго максімальныя магчымасці па працэсары, памяці і дыску, папярэдне абгаварыўшы патрэбы каманд. Адпаведна, адна каманда, у агульным выпадку, не заблакуе для дэплоя ўвесь кластар, вылучыўшы сабе тысячы ядраў і тэрабайты памяці. Доступы ў namespace выдаюцца праз AD (мы выкарыстоўваем RBAC). Namespace'ы і іх ліміты дадаюцца праз пул-рэквест у GIT-рэпазітар, а далей праз Ansible-пайплайн усё аўтаматычна раскочваецца.
Прыклад выдзялення рэсурсаў на каманду:
namespaces:
chat-team:
pods: 23
limits:
cpu: 11
memory: 20Gi
requests:
cpu: 11
memory: 20Gi
Рэквесты і ліміты
У «Кубе» Запыт - Гэта колькасць гарантавана зарэзерваваных рэсурсаў пад струк (адзін або больш докер-кантэйнераў) у кластары. Limit - гэта негарантаваны максімум. Часта можна ўбачыць на графіках, як нейкая каманда выставіла сабе занадта шмат рэквестаў для ўсіх сваіх прыкладанняў і не можа задэплоіць дадатак у «Куб», бо пад іх namespace ўсе request'ы ўжо «выдаткаваныя».
Правільнае выйсце з такой сітуацыі: глядзець рэальнае спажыванне рэсурсаў і параўноўваць з запатрабаванай колькасцю (Request).
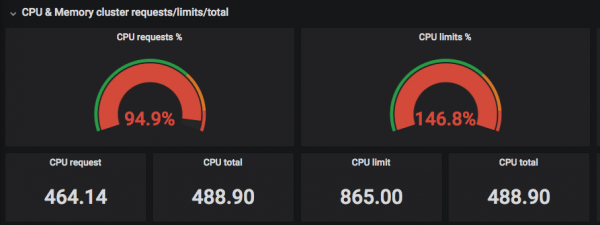
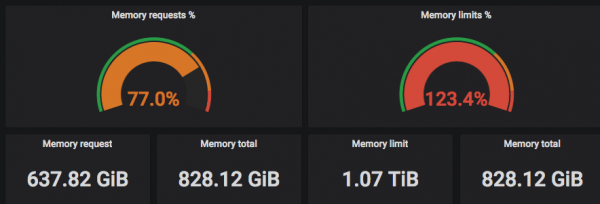
На скрыншотах вышэй відаць, што "запытаныя" (Requested) CPU падбіраюцца да рэальнай колькасці патокаў, а Limits могуць перавышаць рэальнае колькасць патокаў цэнтральных працэсараў =)
Зараз падрабязна разбяром які-небудзь namespace (я абраў namespace kube-system - сістэмны namespace для кампанентаў самога «Куба») і паглядзім суадносіны рэальна выкарыстанага працэсарнага часу і памяці да запытанага:
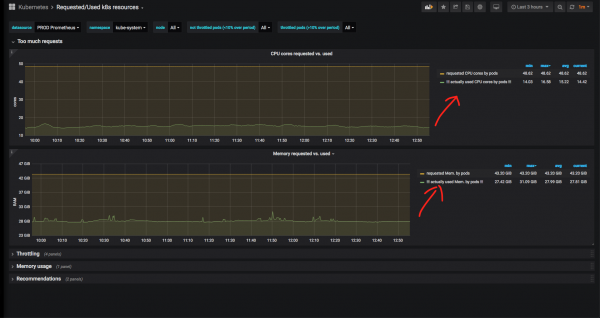
Відавочна, што памяці і ЦПУ зарэзервавана пад сістэмныя службы нашмат больш, чым выкарыстоўваецца рэальна. У выпадку з kube-system гэта апраўдана: хаджала, што nginx ingress controller або nodelocaldns у піку ўпіраліся ў CPU і ад'ядалі вельмі шмат RAM, таму тут такі запас апраўданы. Да таго ж, мы не можам спадзявацца на графікі за апошнія 3 гадзіны: пажадана бачыць гістарычныя метрыкі за вялікі перыяд часу.
Была распрацавана сістэма "рэкамендацый". Напрыклад, тут можна ўбачыць, якім рэсурсам лепш бы падняць "ліміты" (верхняя дазволеная планка), каб не адбывалася "тротлінга" (throttling): моманту, калі пад ужо выдаткаваў CPU або памяць за адведзены яму квант часу і знаходзіцца ў чаканні, пакуль яго «размарозяць»:
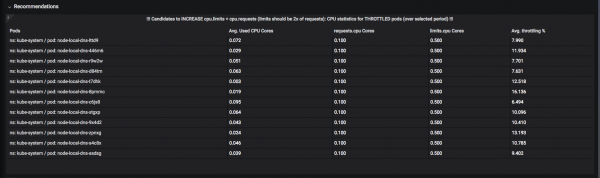
А вось поды, якім варта было б прыцішыць апетыты:
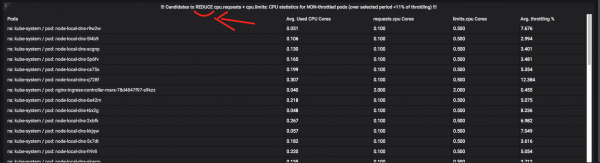
Пра тротлінг + маніторынг рэсурсаў можна напісаць не адзін артыкул, таму задавайце пытанні ў каментарах. У некалькіх словах магу сказаць, што задача аўтаматызацыі падобных метрык вельмі няпростая і патрабуе шмат часу і эквілібрыстыкі з «аконнымі» функцыямі і «CTE» Prometheus / VictoriaMetrics (гэтыя тэрміны ўзяты ў двукоссі, бо ў PromQL амаль што няма нічога падобнага, і даводзіцца гарадзіць страшныя запыты на некалькі экранаў тэксту і займацца іх аптымізацыяй).
У выніку, у распрацоўнікаў ёсць прылады для маніторынгу сваіх namespaces у "Кубе", і яны здольныя самі выбіраць, дзе і ў які час у якіх прыкладанняў можна "падразаць" рэсурсы, а якім падам можна на ўсю ноч аддаць увесь CPU.
Метадалогіі
У кампаніі, як зараз модна, мы прытрымліваемся DevOps- і SRE-практык. Калі ў кампаніі 1000 мікрасэрвісаў, каля 350 распрацоўшчыкаў і 15 адмінаў на ўсю інфраструктуру, прыходзіцца «быць модным»: за ўсімі гэтымі «базордамі» хаваецца вострая неабходнасць у аўтаматызацыі ўсяго і ўся, а адміны не павінны быць бутэлькавым рыльцам у працэсах.
Як Ops, мы даем розныя метрыкі і дашборды для распрацоўшчыкаў, звязаныя з хуткасцю адказу сэрвісаў і іх памылкамі.
Мы выкарыстоўваем такія метадалогіі, як: , и , камбінуючы іх разам. Імкнемся мінімізаваць колькасць дашбордаў так, каб з аднаго погляду было зразумела, які сэрвіс зараз дэградуе (напрыклад, коды адказаў у секунду, час адказу па 99-перцэнтылю), і гэтак далей. Як толькі становяцца патрэбныя нейкія новыя метрыкі для агульных дашбордаў, мы тут жа іх малюем і дадаем.
Я не маляваў графікі ўжо месяц. Мусіць, гэта добры знак: значыць большасць «хацелак» ужо рэалізаваны. Бывала, што за тыдзень я хаця б раз на дзень маляваў які-небудзь новы графік.
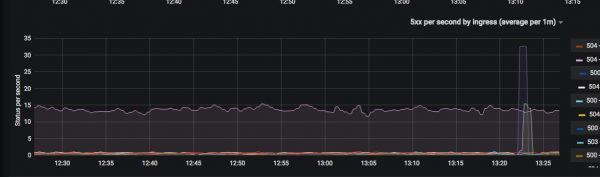
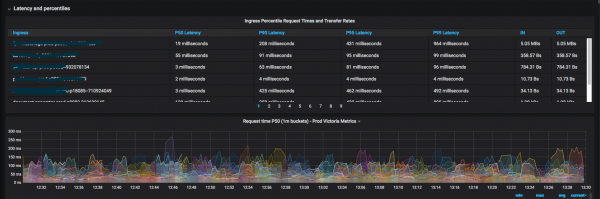
Атрыманы вынік каштоўны тым, што зараз распрацоўшчыкі даволі рэдка ходзяць да адмінаў з пытаннямі "дзе паглядзець нейкую метрыку".
укараненне Сэрвісная сетка не за гарамі і павінна моцна палегчыць усім жыццё, калегі з Tools ужо блізкія да ўкаранення абстрактнага "Istio здаровага чалавека": жыццёвы цыкл кожнага HTTP(s)-запыту будзе бачны ў маніторынгу, і заўсёды можна будзе зразумець "на якім этапе ўсё зламалася" пры міжсэрвісным (і не толькі) узаемадзеянні. Падпісвайцеся на навіны хаба кампаніі ДомКлік. =)
Падтрымка інфраструктуры Kubernetes
Гістарычна склалася так, што мы выкарыстоўваем патчаную версію Kubespray - Ansible-роля для разгортвання, пашырэння і абнаўлення Kubernetes. У нейкі момант з асноўнай галіны была выпілаваная падтрымка non-kubeadm усталёвак, а працэс пераходу на kubeadm прапанаваны не быў. У выніку, кампанія Southbridge зрабіла свой форк (з падтрымкай kubeadm і хуткім фіксам крытычных праблем).
Працэс абнаўлення ўсіх кластараў k8s выглядае так:
- бярэм Kubespray ад Southbridge, звяраем з нашай галінкай, мерджым.
- Выкочваем абнаўленне ў Стрэс-«Куб».
- Выкочваем абнаўленне па адной нодзе (у Ansible гэта "serial: 1") у DEV-«Куб».
- Абнаўляем Штуршок у суботу ўвечар па адной нодзе.
У будучыні ёсць планы замяніць Kubespray на што-небудзь хутчэйшае і перайсці на кубеадм.
Усяго ў нас тры Куба: Stress, Dev і Prod. Плануем запусціць яшчэ адзін (hot standby) Prod-«Куб» у другім ЦАД. Стрэс и DEV жывуць у "віртуалка" (oVirt для Stress і VMWare cloud для Dev). Штуршок-«Куб» жыве на «галым жалезе» (bare metal): гэта аднолькавыя ноды з 32 CPU threads, 64-128 Гб памяці і 300 Гб SSD RAID 10 – усяго іх 50 штук. Тры «тонкія» ноды выдзелены пад «майстры» Штуршок-«Куба»: 16 Гб памяці, 12 CPU threads.
Для продаем аддаем перавагу выкарыстоўваць «голае жалеза» і пазбягаем лішніх праслоек накшталт OpenStack: нам не патрэбныя «шумныя суседзі» і CPU steal time. Ды і складанасць адміністравання ўзрастае прыкладна ўдвая ў выпадку in-house OpenStack.
Для CI/CD "Кубавых" і іншых інфраструктурных кампанентаў выкарыстоўваны асобны GIT-сервер, Helm 3 (перайшлі даволі балюча з Helm 2, але вельмі рады опцыі атамная), Jenkins, Ansible і Docker. Любім feature-бранч і дэплой ў розныя асяроддзя з аднаго рэпазітара.
Заключэнне

Вось так, у агульных рысах, у кампаніі ДомКлік выглядае працэс DevOps са боку інжынера эксплуатацыі. Артыкул атрымаўся менш тэхнічным, чым я чакаў: таму, сочыце за навінамі ДомКлік на Хабры: будуць больш «хардкорныя» артыкулы пра Kubernetes і не толькі.
Крыніца: habr.com
